MEGAZONEブログ

Rocket science:Process, store, and analyze engine test data on AWS
ロケットサイエンス:AWSでエンジン試験データを処理、保存、分析
Pulisher : Cloud Technology Center イ・ヨンジン
Description : Rocket scienceでAWSが活用されている事例や、製造業分野で活用できるBest Practice Architectureを紹介したセッション。
はじめに
MegazoneCloudのAerospace & Satellite TFに所属し、Aerospace & Satelliteのお客様にAWSでサポートできるサービスや方法などを広めたいと思い、本セッションを申し込みました。 特に、ロケット科学分野ではAWSがどのように活用されているのか気になり、申し込みました。
セッションの概要紹介
発表者は、AWSのAerospace & Satelliteチームからご登壇下さいました。
全体的な話と、実際の現場で起きている話と、それをAWS上でarchitectingする部分を詳しく教えていただきました。

Rocket scienceではどのようにAWSが活用されているのか、製造業分野で活用できるBest Practice Architectureを紹介しました。
目次としては、ロケットに使われるエンジンをテストする際、センサーデータについて、AWS上でどのようにIngest / Store / Processing / Serveに分けるかが主な内容でした。

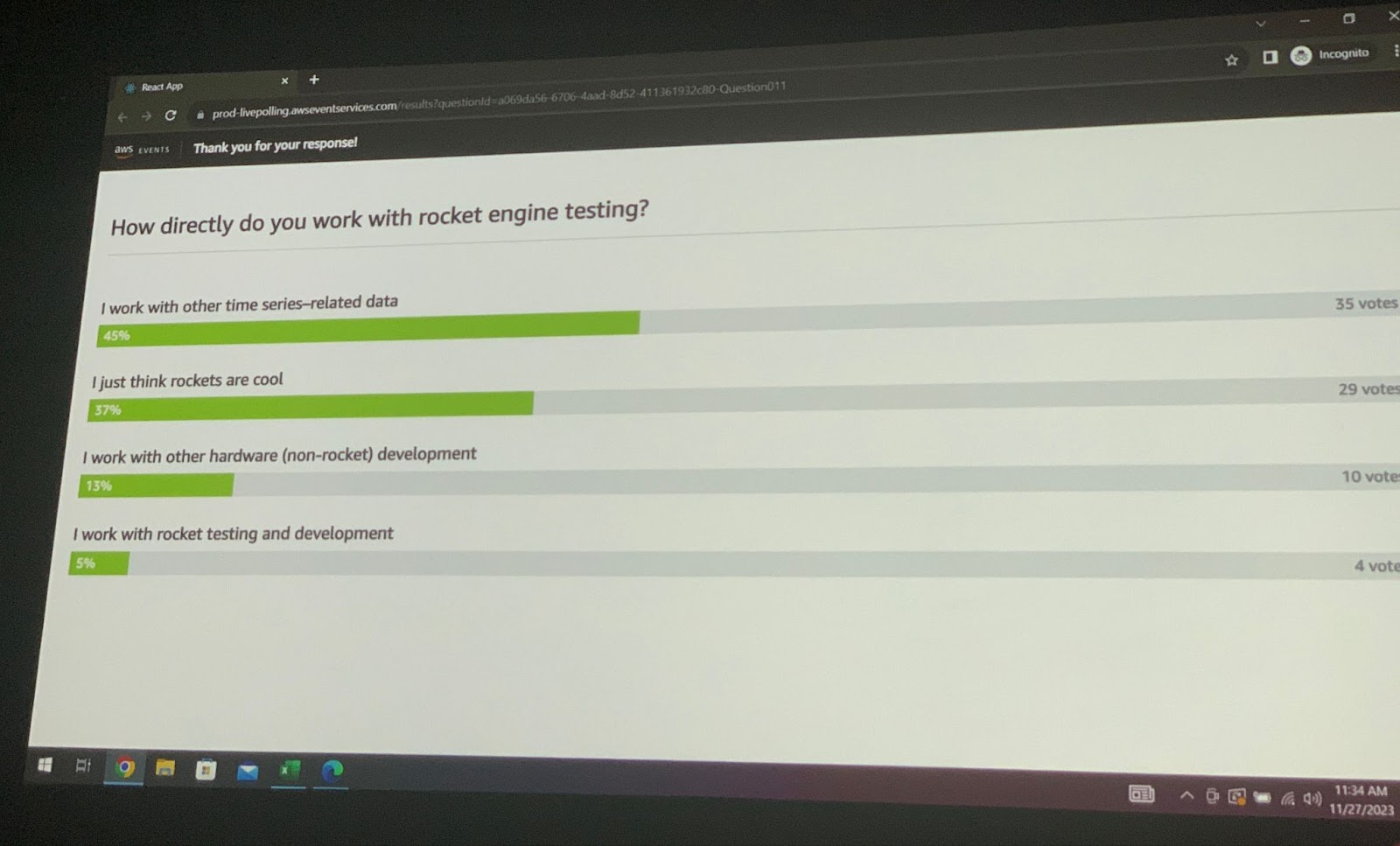
ちなみに、本格的な内容開始に先立ち、リアルタイムでアンケートを取ったのですが、参加者の中では、時系列データ処理の関係者が多く、次にrocket scienceはかっこよくて参加された方が次いで多かったです。 実際にrocket産業に従事されている方は5%でした。
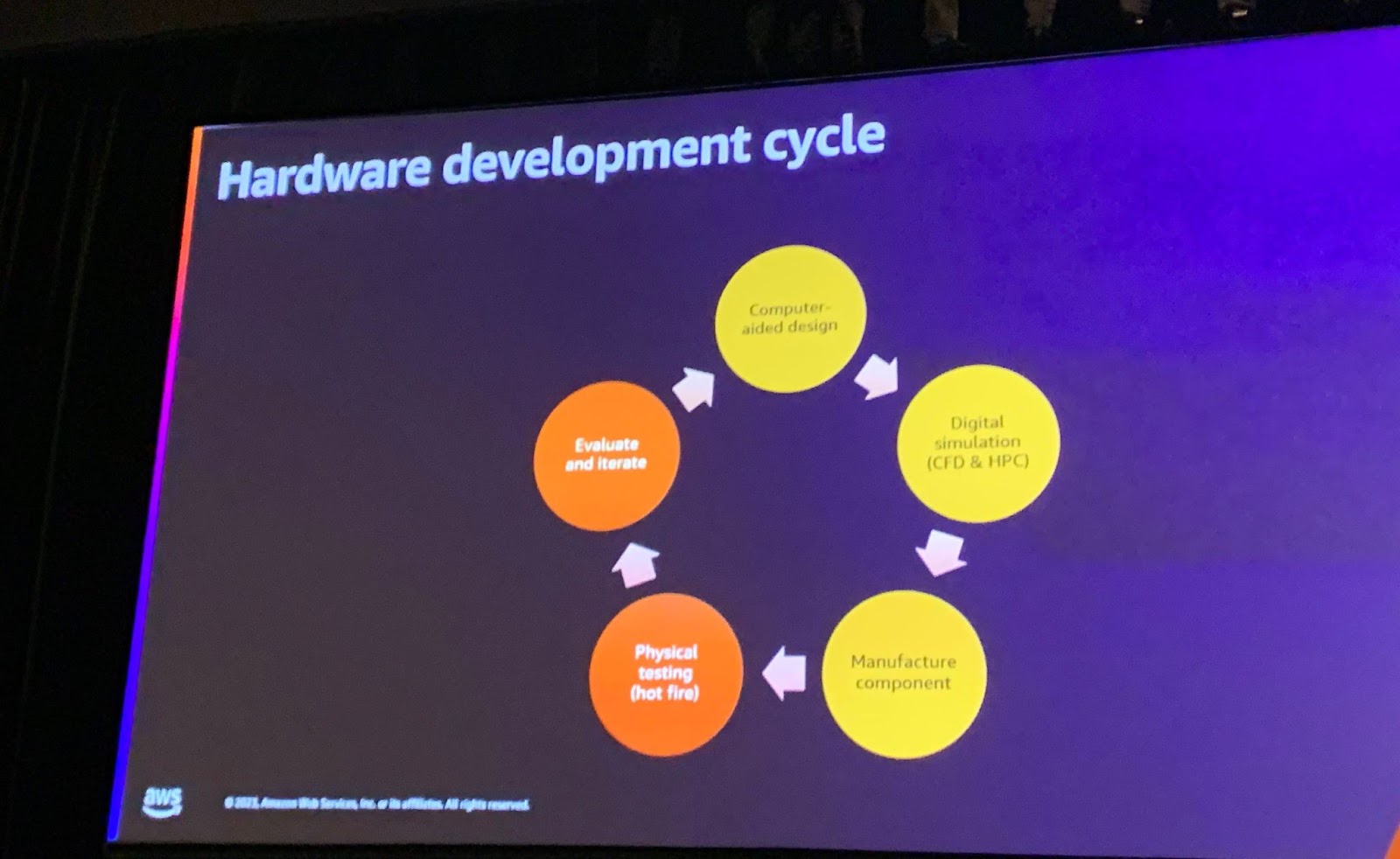
Rocketも他のハードウェア技術と同様に、次のような順序で進行することを確認しました。
・Computer aided-design
・Digital simulation (CFD & HPC)
・Manufacture components
・Physical testing (hot-fire)
・Evaluate & iterate
実際にengineテストでdataを取得する部分は、圧力、温度、振動、電磁干渉などを測定するそうです。 これは他のハードウェア設計後に測定する部分とあまり変わりませんでした。

エンジンが作成されると、確認のためにhot-fire testingを行います。この時、上記の項目のデータをリアルタイムで収集します。

センサーデータが収集されたら、次はそのデータを分析する作業に移ります。

ここで、このデータ処理過程で顧客が要求する項目は以下の通りです。
・Faster time to results : 結果までの迅速な処理
・Scalable and cost-effective storage : 拡張が容易で費用対効果の高いストレージ
・Improved data governance : センサーデータであってもrocket scienceに関しては産業機密に含まれるため、外部流出と管理に非常に敏感です
・Extract more value from data : データから多くの指標を見ることができ、洞察できる情報を獲得することができます。

結局、AWSの観点から見ると、下記のような処理過程になります。 つまり、下記の過程に必要なAWSサービスを繋げればいいわけです。
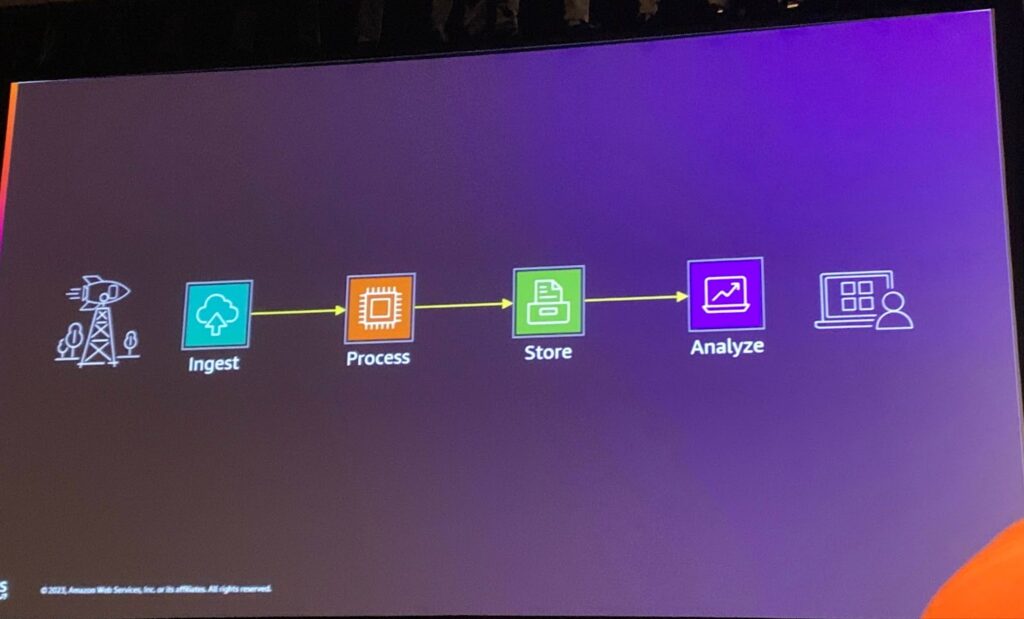
ここで一つの選択が必要です。Databaseなどを利用してリアルタイム処理方式で行くのか、それともS3などにデータを置いておいてバッチ処理するのかです。
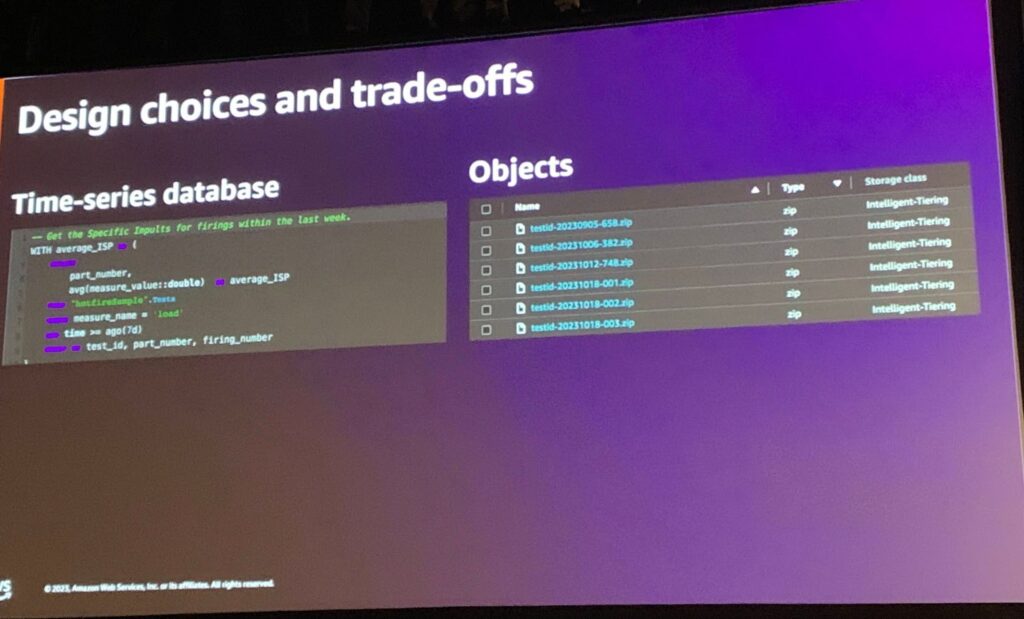
リアルタイム処理とバッチ処理はそれぞれ長所と短所が存在します。リアルタイム処理は、データパイプラインの確保から高性能プロセッサを要求するので、価格が高い分、すぐに確認でき、修正と反映が容易ということです。
バッチ処理はリアルタイムではありませんが、費用対効果が高く、リアルタイム性を要求しない限り、問題ない方法です。

Batch基準で処理するarchitectureです。データ入力から始まり、データを処理して結果を出すまでの全プロセスが含まれています。このarchitectureはrocket scienceだけでなく、ほぼ全てのメーカーで活用できるでしょう。
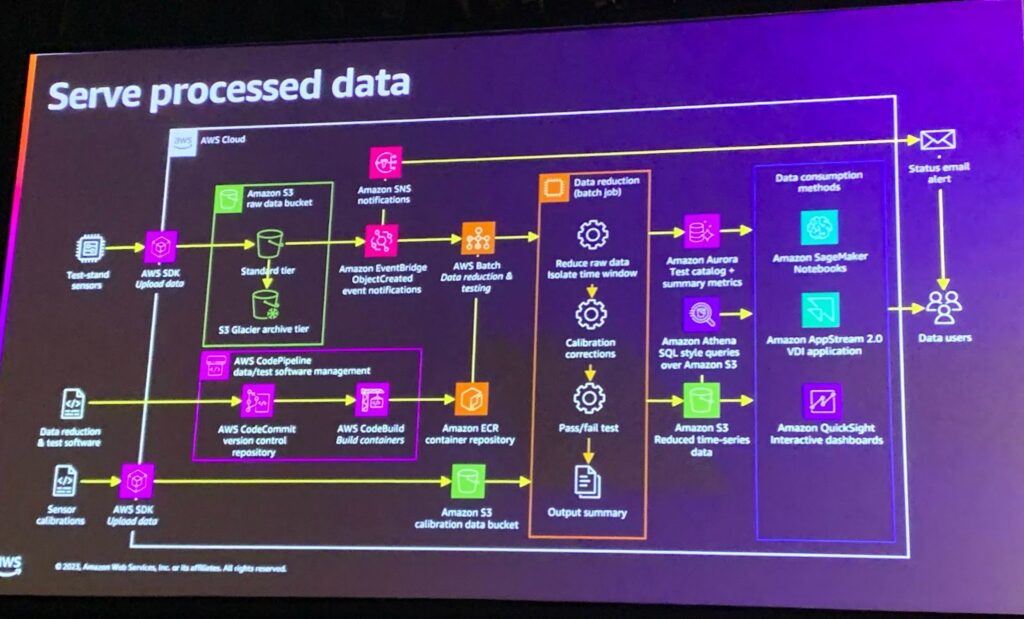
上記のプロセスを一つずつ見てみると、次のような順番になります。
- Ingest raw data : 実際のsensor dataを、AWS SDKを利用してAWS infra.にアップロードします。
- Archive raw data : 入力されたデータを保存します。多くのデータは高い保存コストが発生するため、すぐに処理に必要なデータはS3 standard tierに保存し、過去のデータはS3 Glacier archive tierを活用します。
- Manage calibration data and parameters : 入力されたセンサーデータはエラーを含んでいる可能性があるため、標準値を導出できるように校正データも別途受け取ります。
- Run data processing task : リアルタイム性ではなく、バッチ処理のためにAmazon EventBridge、AWS Batch、そしてAWS Batchに使用される分析アプリケーション開発管理のためにCI/CD pipelineと結合されたAmazon ECRサービスが活用されます。処理されるデータが準備されたら、Amazon SNS를活用してユーザーにalertをemailで送信するのもいいですね。
- What’s going on in that container?! : 分析 application (container) では時間別のデータ整理作業を行い、補正データを活用した数値修正、補正による実効値の検証、そして結果を導き出すことになります。
- Store processed data : 処理されたデータを別のS3に保存します。データの容量は、初期にインプットされたセンサーデータと比較して大幅に減った状態です。これをAmazon Athenaを利用したSQLで抽出したデータをAmazon Auroraに保存します。
- Manage processing software : 分析アプリケーションメンテナンスのためにCodePipelineと連携して、アプリケーションソースコードや開発も一緒に行います。
- Serve processed data : 加工と処理が完了したデータに対してAmazon SageMakerを活用してAI/ML処理も可能です。 もし、データ流出を考慮しなければならない場合は、Amazon AppStream 2.0を活用したVDI形式で顧客に納品することができます。データ表現のためのdashboardはAmazon QuickSightを利用して反応型dashboardを作ることもできます。
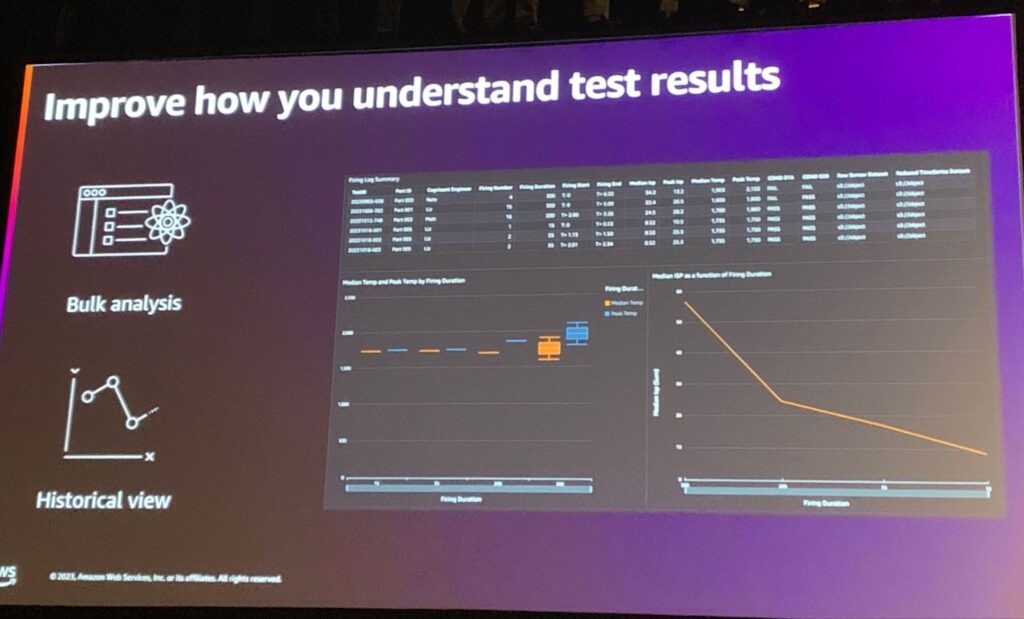
データが準備されたので、それをどのように表現するかを考えます。 様々な指標を通じて、最初は見えなかった情報と洞察を得ることができます。

セッションを終えて
Rocket engineの製作など、非常に特殊なハードウェア製造分野でもAWSは様々なところで活用されています。全く似合わないようなコラボレーションですが、Space Xをはじめ、すでに多くのロケット企業がAWSを導入しています。
それでは、実際の開発や生産においてAWSのサービスがどのように活用されているのか、事例を通してみて、一般的に共通して活用できるBest Practice Architectureも見てみました。
過去の伝統的なハードウェア製造では、クラウドサービスを活用することに違和感がありましたが、データの取り込みから始まり、保存、処理と結果値の閲覧、そして関連アプリケーション開発まで全てAWS上で行うことができることを示しました。
市場の変化と市場の要求事項を満足させ、これを加速させることができる答えはAWSにあるようです。

