MEGAZONEブログ

Deploy gen Al apps efficiently at scale with serverless containers
サーバーレス・コンテナで大規模なGen Alアプリを効率的にデプロイする
Pulisher : Managed & Support Center ビンナリ
Description : Generative AIのエコシステムとその開発と展開を加速するための主要な考慮事項、およびベストプラクティスとガイドラインを紹介するセッション。
はじめに
今回の2023re:Inventで特にGenerative AI関連のサービスや機能がたくさんリリースされたような印象を受けました。 これは、Generative AIが最新のトレンドであることを意味します。そのため、Generatvie AIの概念とどのような段階で構成されるのか、関連AWSサービスは何があるのかなど、このセッションを聞くことになりました。
セッションの概要紹介
本セッションでは、Generative AI(生成的人工知能)のエコシステムについての紹介と、その開発と展開を加速するための主な考慮事項、そしてベストプラクティスとガイドラインについて知ることができるセッションです。 また、顧客事例を通じて、実務での適用可能性と効果についての情報も得ることができます。

AI(人工知能)のパラダイムを代表するGenerative AI(生成型人工知能)は、既存の膨大なデータセットから学習し、構造とパターンを識別して新しいコンテンツを想像し、革新し、生成する能力を意味します。
Generative AIアプリケーションを開発・展開するための技術スタックは、データ層、モデリング層、展開・応用層で構成されています。各レイヤーは相互に通信し、開発およびデプロイメントパイプラインを活性化します。
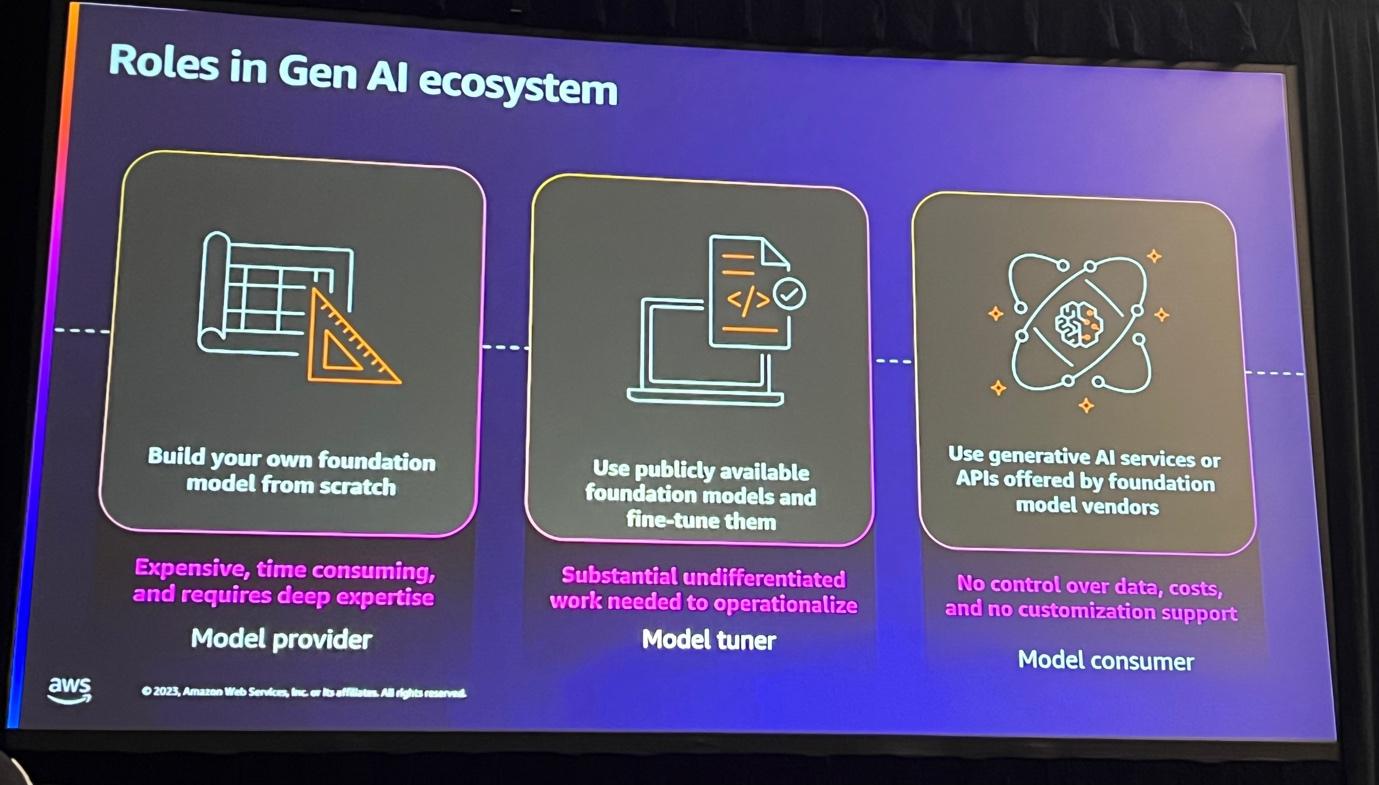
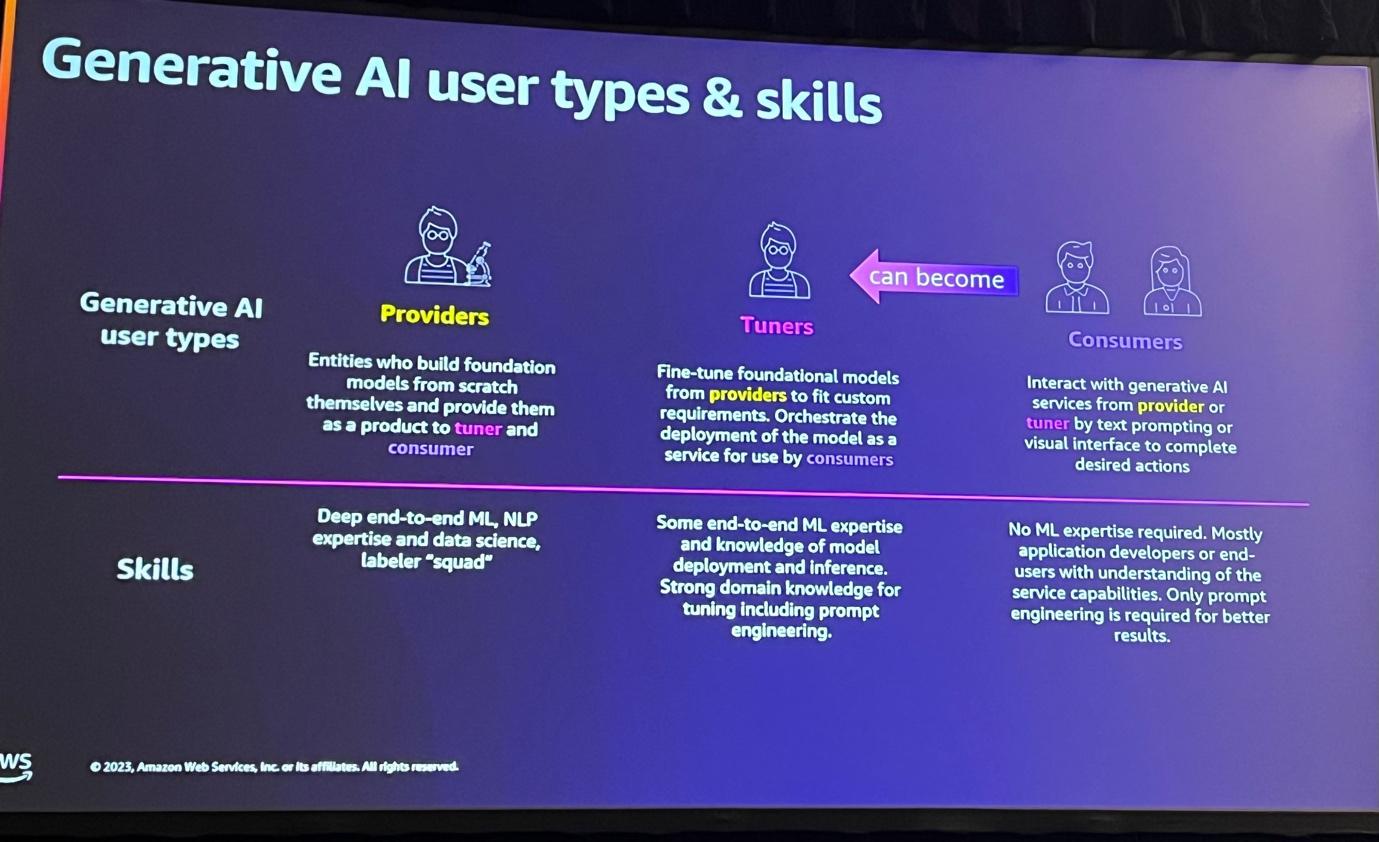
Generative AIエコシステムにおける主な役割は、モデルプロバイダー、チューナー、コンシューマーに分けることができ、それぞれの役割は特定の技術スキルを必要とします。
・モデルプロバイダーは、FM(Foundation Model)を設計、訓練、提供する役割を担います。
・チューナーは、モデルの最適化と微調整による性能向上を担当します。
・コンシューマーは、実際にモデルをアプリケーションに統合する役割を果たします。
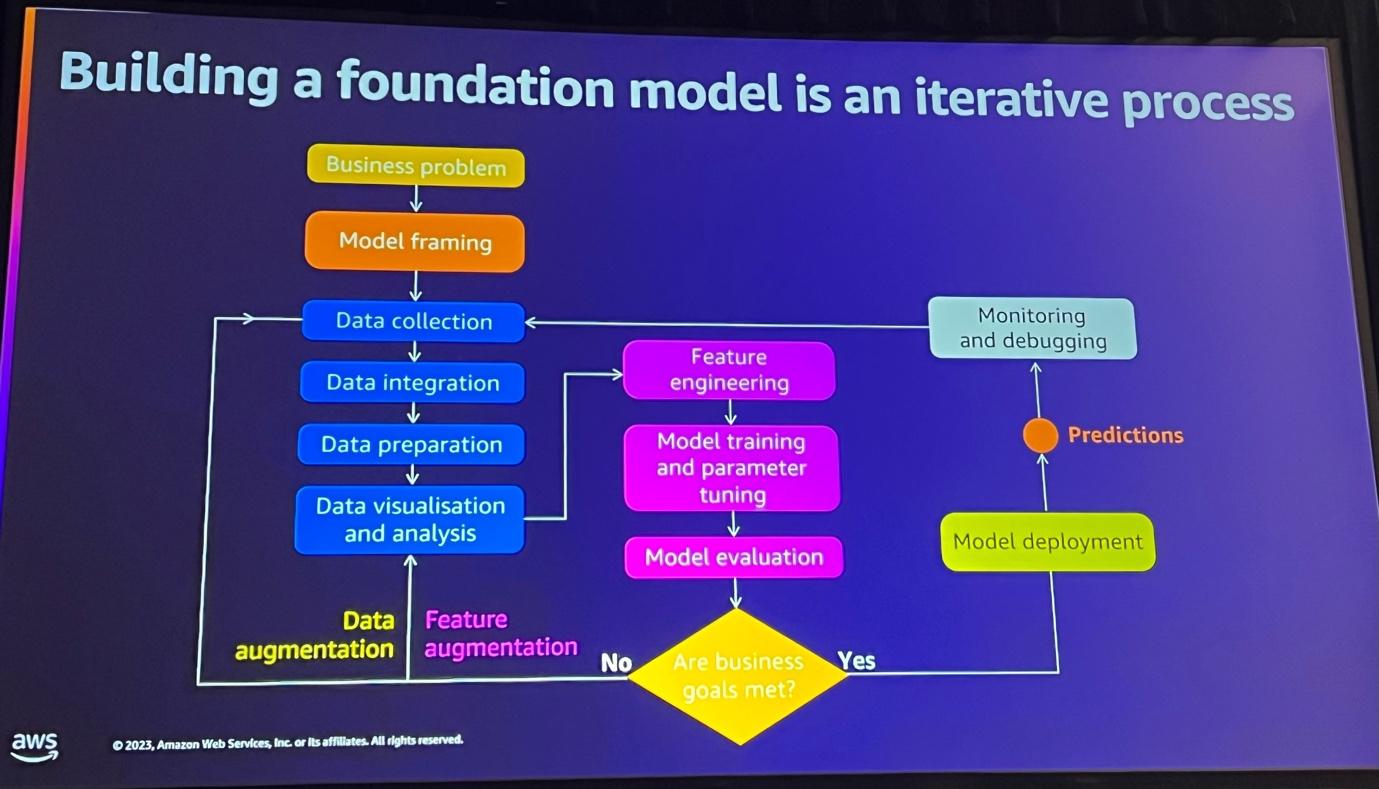
Foundation Model(FM)は、様々なサブタスクのための大規模な事前訓練された人工知能モデルを意味します。 このようなFMの構築は以下のような反復的なプロセスです。
まず、ビジネス問題を解決するためのミッション学習プロセスを開始します。この段階では、様々なソースからデータを収集し、統合、精製、分析します。 その後、モデルチューニングを通じてモデルの性能を最適化します。
性能評価後、モデルがうまく動作する場合、モデルをデプロイし、プロダクション環境でモデルをモニタリングします。ミッション学習モデルは、トレーニング時点から時間が経つにつれて予測能力が低下するため、新しいデータでモデルを再トレーニングし、適応させることが重要です。
最後に、モデルをワークフロー全体に統合します。

AWSのAmazon Code WhisperとAmazon Titan Foundationモデルを使用すると、生成型AIアプリケーションを迅速かつ安全に構築することができます。
Amazon Code Whisperは、検出が難しい脆弱性を見つけ、解決策を提案するためのセキュリティスキャン機能を備えています。
また、Amazon Titan Foundationは、テキストの要約、生成、分類、情報抽出のための2つの新しいLLMで構成されており、ユーザーが提供したデータから有害なコンテンツを検出して除去し、適切でないコンテンツをフィルタリングする機能も提供し、安全なアプリケーション構築を支援します。
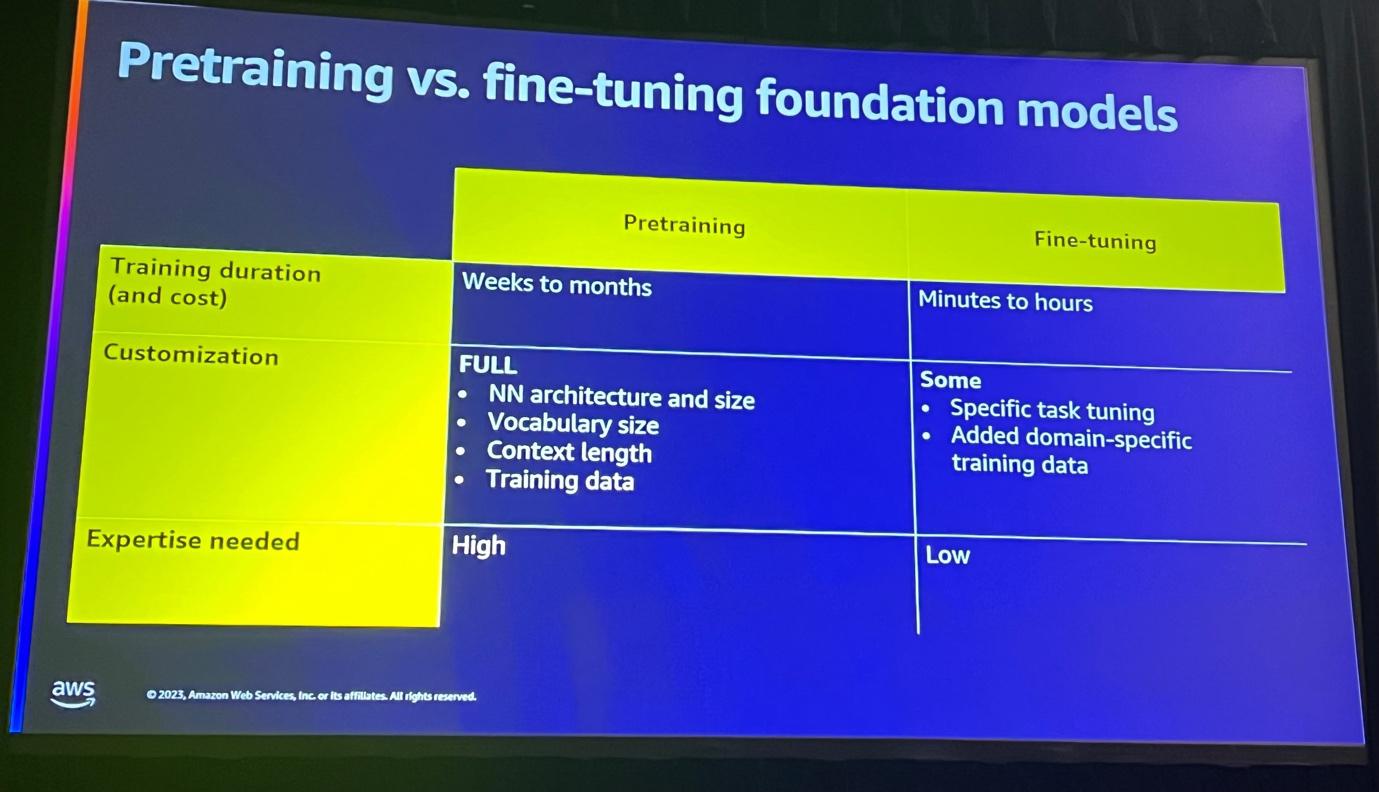
機械学習モデルを開発するには、Pre training(大規模なデータセットで一般的なタスクに対するモデルを学習する過程)とfine tuning(事前訓練されたモデルを取得して特定のタスクに対して調整する)という二つのアプローチがあります。
大規模なデータセットが利用でき、リソースと時間が多い場合はPre-trainingが有用であり、作業に必要なデータが少なく、特定のドメインに特化した場合、また、比較的データが少なく、時間が不足している場合はFine-tuningがより効果的な場合があります。
データの量、作業の特性、使用可能なリソースと時間、そしてモデルの目的などによって、Pre-trainingとFine-tuningのどちらの方法を選択するかを決定する必要があります。
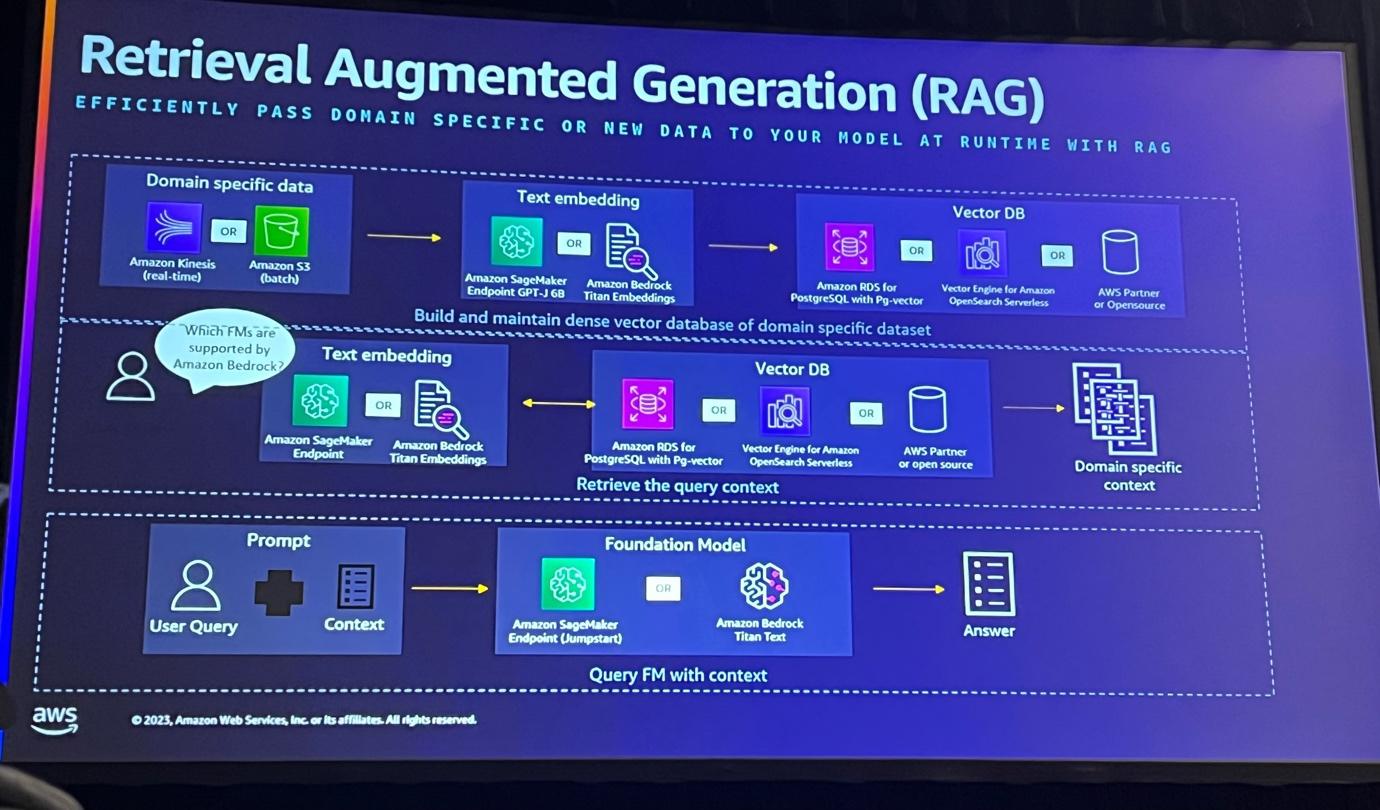
FMが最新のデータや特定のデータセットを持っていないことは重要な問題であり、これを解決するための技術としてRAG(Retrieval Augmented Generation)があります。
この技術は、ランタイムで正確な情報を検索し、モデルがより正確に質問に答えられるようにするものです。 そのために、データセットをテキストからエンベデッドに変換し、ベクトルデータベースに保存します。顧客の要求が来ると、そのデータベースから必要な情報を取り出し、モデルに伝え、質問に答えるのに役立ちます。このようにして、モデルは特定の質問に対してより正確なコンテキストを得ることができます。

Generative AIアプリケーションをサーバーレス環境でデプロイする場合、デプロイを加速することができ、このようなサーバーレス環境の2つのオプションは、Amazon ECSとAWS Lambdaがあります。
Lambdaの場合、関数実行に15分の制限と、最大10GBのストレージスペースしか提供しませんが、ECSにはこのような制限はありません。 継続的なトラフィック処理が必要な場合は、Amazon ECSを使用することをお勧めします。

ECSでGen AIモデルをデプロイする場合、モデルをアプリケーションにどのようにロードするかを考慮する必要があります。
Gen AIモデルのサイズは非常に多様であり、アプリケーションとモデルが可能な限り迅速に実行され、リクエストに応答できるように、モデルを迅速にロードする必要があります。
これには3つの方法があり、完全に管理可能でスケーラブルなファイルシステムであるEFSを使用してモデルをホストするか、S3にホストし、S3 APIを利用してランタイムにモデルを取得することができます。 また、モデルをコンテナイメージ自体にバンドルして、大規模な展開可能なイメージを作成することもできます。

結論として、Generative AI基盤モデルは様々な応用分野に活用することができ、このようなFoundationモデルは後日、フォローアップ作業に活用することができます。
Generative AI Applicationと、モデルの効果的な統合が重要であり、プロンプトエンジニアリングとRAG(検索強化生成)の使用が重要です。
モデルサーブにはAmazon Bedrockを使用し、アプリケーションサーバーとしてAmazon EcsとAWS Fargateを使用することをお勧めします。Amazon ECSは、EC2とFargateの実行タイプにより、アクセラレーションとサーバーレスオプションを提供し、セルフホスティングのための豊富な機能を提供します。
セッションを終えて
このセッションを通じてGenerative AIの概念と開発、デプロイメントに関する詳細とFoundation modelに関して多くのことを学ぶことができました。 また、AWSサービスを活用してGenerative AI Applicationをより簡単、迅速、効率的に生成することができるという点も感じることができ、AWSでも最近Generative AI関連サービスをたくさんローンチしていることから、やはりGenerative AIが最新トレンドであることを実感することができました。既存の経験があるテーマではなく、やや理解しにくい点が多かったですが、テーマがとても興味深く、有益な時間でした。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner