MEGAZONEブログ

Building distributed data processing workloads with AWS Step Functions
AWS Step Functionsによる分散データ処理ワークロードの構築
Pulisher : Cloud Technology Center キム・ジホ
Description : AWS Step FunctionsやAWS Lambdaのようなサーバーレステクノロジーがどのように管理と拡張を簡素化し、分散データ処理を進めるかを紹介するワークショップセッション
はじめに
企業がビジネス目標を達成し、新たな価値を生み出すために大規模なデータを処理する必要性がますます高まっている中、分散データ処理ワークロードを構築するAWS Step FunctionsやAWS Lambdaなどのサーバーレステクノロジーが、管理とスケーリングを簡素化し、並列処理を効果的に処理するためにどのように役立つのか、また、どのように管理とスケーリングを簡素化するのかについて理解を深めるために、このセッションを選択しました。
セッションの概要紹介
今日の企業は、ビジネス目標を達成し、新たな価値を生み出すために、大規模なデータを処理する必要性がますます高まっています。分散型データ処理は、処理速度を向上させるための費用対効果の高い方法を提供しますが、サーバーベースの環境では、同時性の管理は開発者に課題をもたらします。本ワークショップでは、AWS Step FunctionsやAWS Lambdaなどのサーバーレステクノロジーがどのように管理とスケーリングを簡素化し、差別化されていないタスクを軽減し、分散データ処理の課題に対処するのに役立つかを学びます。 また、データ処理の旅を加速するためのユースケース、最適な方法、およびリソースについて学びます。
AWS Step FunctionsとLambdaを使用して分散型データ処理アプリケーションを構築するセッション

ワークショップの基本情報

使用されるAWSサービス

主な流れ
大きく3つのモジュールで構成されています。
Module 1) Distribution mapsの紹介
>>Intro
Distributed Mapは、データセットの複数の項目に対して10,000の同時性で同じ処理ステップを実行するマップの状態です。 これは、実行、ワーカー、データを並列化する方法を心配することなく、大規模な並列データ処理ワークロードを実行できることを意味します。Distributed Mapは、Amazon S3に保存された.csvまたはjsonファイル内のログ、画像、レコードなど、数百万以上のオブジェクトを反復処理することができます。データを処理するために、最大10,000個の並列サブワークフローを起動することができます。サブワークフローには、AWS Lambda関数、Amazon ECSジョブ、AWS SDK呼び出しなどのAWSサービスの組み合わせを含めることができます。
Distributed Mapは、Step Functionsで利用可能な2種類のマップに新たに追加されたものです。 インラインマップとDistributed Mapの主な違いは以下の通りです:
1.Distributed Mapは、インラインマップの40個の同時性と比較して、より高い同時性を持ちます。
2.Distributed Mapは、Amazon S3のデータを直接反復することができます。
3.Distributed Mapの各サブワークフローは、Step Functionsの25,000実行履歴制限を回避する個別のサブワークフローとして実行されます。
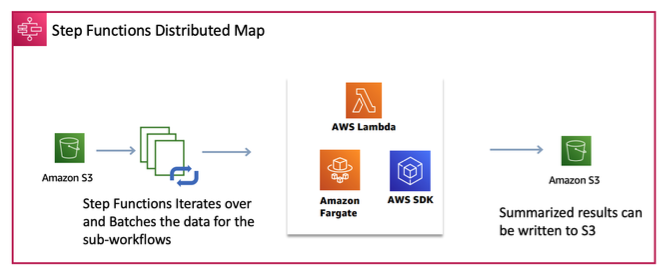
このモジュールでは、分散マップを使用して事前に生成されたワークフローを確認します。使用されたデータは1,292,954個のレコードを含む83MBのCSVファイルで、以下のような形式で構成されています。
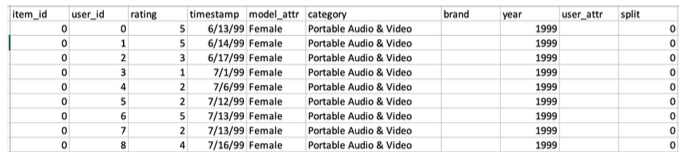
このワークフローは、電子製品レビューデータを反復し、評価の高いレビューをフィルタリングします。データをS3にダウンロードし、ワークフローを実行し、結果を確認します。この過程で、簡単な分散マップワークフローを自分で構築し、実行する方法を学びます。
ワークフローの確認
1.Step Functionsコンソールを開き、「HelloDmap」を含むステータスマシンを選択します。
2.Workflow Studioでワークフローを編集するには、「編集」を選択します。
3.ページの右側にある「定義の切り替え」を選択して、定義を確認します。
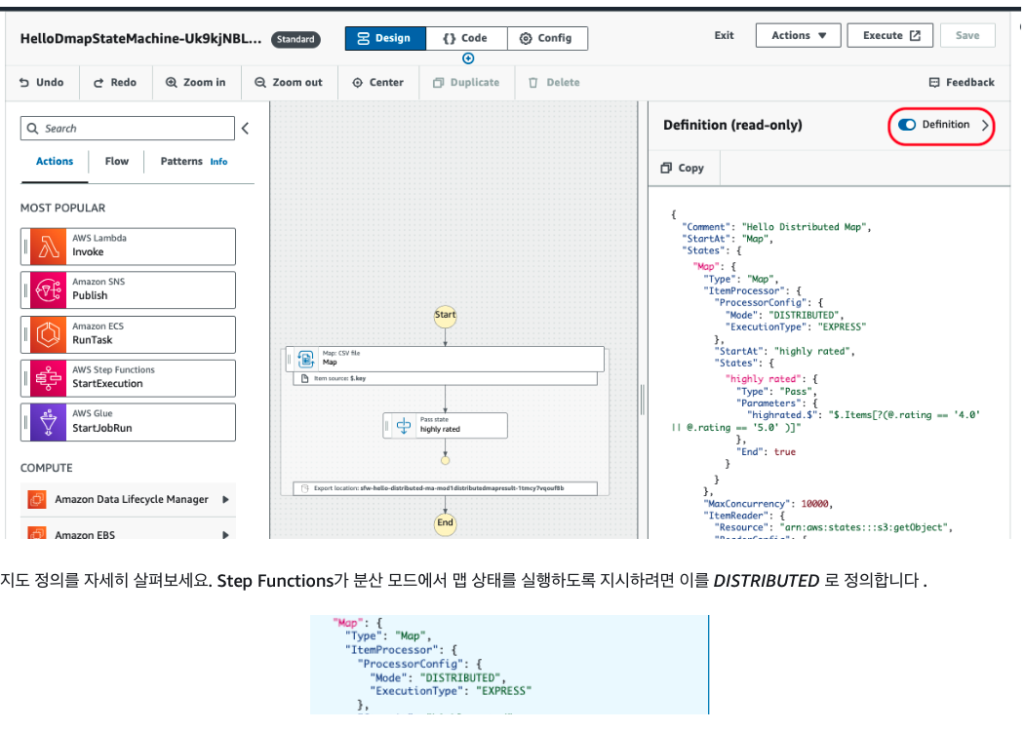
4.デザインの各状態を選択して定義を確認します。
5.マップの定義を詳しく確認します。Step Functionsが分散モードでマップ状態を実行するように指示するには、「DISTRIBUTED」と定義します。

6.定義でItemReaderを確認してください。 これは分散マップにcsvまたはJSONファイルを処理するように指示する方法です。リーダーはs3.getObject APIを使用してオブジェクトを読み取ります。
7.csvファイルの内容を読み取り、データを一括してサブワークフローに配布し、同時実行速度は10,000です!設定を確認して、さらにいくつかの設定を確認します。

8.バッチ処理(Batching)を行うことができます。MaxItemsPerBatchが1000に設定されており、10,000(10K)個のワークフローを実行しながら、データを各ワークフローに一括処理することができます。
9.分散マップの出力またはサブワークフローの実行結果を集約された方法でS3位置に書き込むことができます。
10.失敗許容を設定することができます。これは、データ品質を考慮して、失敗として許容できる項目の割合や数を設定することができます。これにより、ワークフローが効率的に処理され、時間とコストを節約できます。

11.次に、分散された地図の内部に何があるかを確認することができます。この紹介モジュールでは、レコードを処理するためにLambdaのようなコンピューティングサービスを使用します。
分散マップ内部の状態は、個別のサブワークフローで実行されます。サブワークフローの数は、同時性の設定と処理するレコードの量によって異なります。例えば、同時性を1000に設定し、バッチサイズを100に設定しても、ファイルの総レコード数が20,000しかない場合、Step Functionsは200個のサブワークフローしか必要としません(20,000 / 100 = 200)。
一方、ファイルに200,000個のレコードがある場合、Step Functionsは最大同時性に到達するために1000個のサブワークフローを起動し、サブワークフローが完了すると、Step Functionsはすべての2000個のサブワークフロー(200,000 / 100 = 2000)が完了するまでサブワークフローを起動します。完了しました。
ワークフローの実行
1.Step Functionsコンソールを開き、名前に「HelloDmapStateMachine」が含まれる状態マシンを選択して開きます。
2.右上の「実行開始」を選択します。
3.ポップアップで必要な情報を入力します。分散マップの結果を保存するファイル名とS3プレフィックスを入力します。
4.「実行開始」をクリックします。
5.数秒後に実行が開始されるのが確認できます。処理が完了するまで数分程度かかる場合があります。
ワークフローの結果を見る
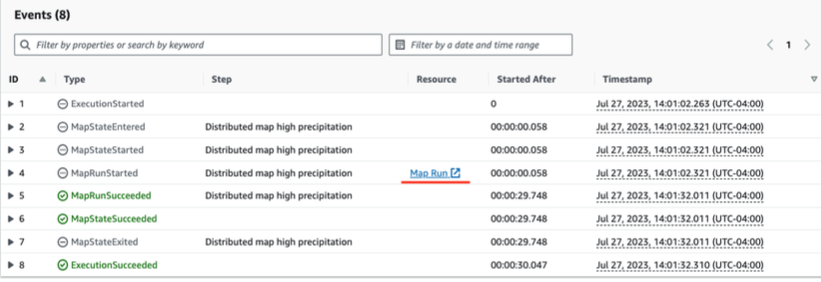
1.ワークフロー実行ページの下部に移動し、「Map Run」をクリックします。
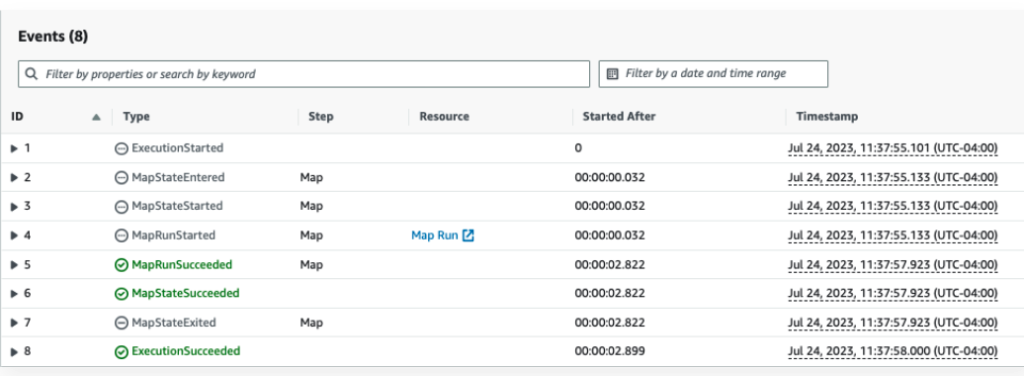
2.項目処理ステータスカードで分散プロセスのステータスを確認することができます。処理されたレコード数と期間を表示します。90秒以内に1,292,954件のレコードを処理します!ページ下部には、すべてのサブワークフロー実行へのリンクが表示されます。
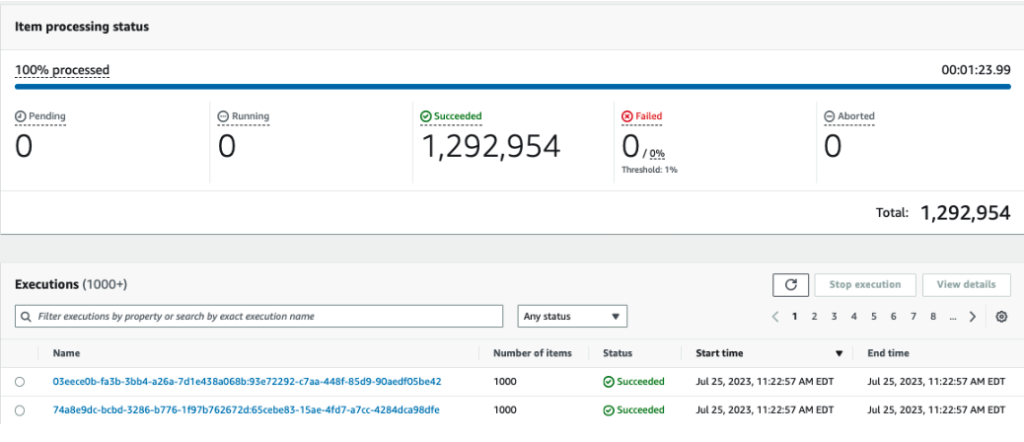
3.サブワークフローの一つを開き、実行入出力を確認します。出力ウィンドウで、通過ステータスがグレード4以上のレコードをフィルタリングしたことが確認できます。
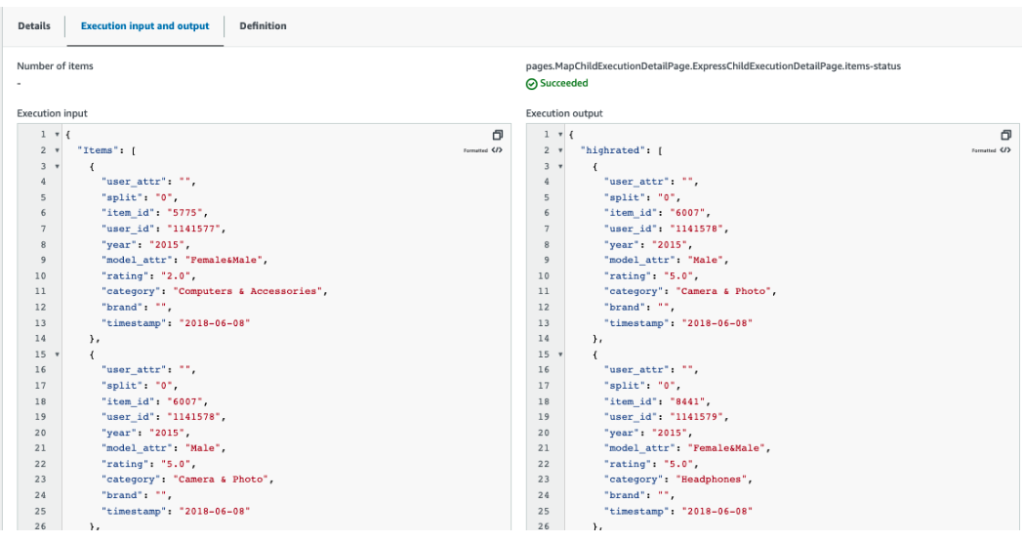
4.ワークフローの結果もS3バケットに保存されます。
このモジュールでは、分散マップを使用してデータ処理ワークフローを構築し、S3オブジェクトを複数のサブワークフローに分散して並列処理するようにStep Functionsを構成しました。
Distributed Mapを使用してS3で多数のオブジェクトを処理する場合、そのオブジェクトを一覧表示するためのいくつかのオプションがあります: S3 listObjectsV2 と S3 Inventory Listです。 S3 listObjectsV2 を使用すると、S3 listObjectsV2 API 呼び出しを Step Functions がユーザーに代わって実行し、Distributed Map の実行に必要なすべてのアイテムを取得します。 listObjectsV2 への各呼び出しは、最大 1000 個の S3 オブジェクトのみを返すことができます。これは、処理するオブジェクトが2,000,000,000個ある場合、Step Functionsは最低2,000回のAPI呼び出しを実行する必要があることを意味します。このAPIは高速で時間がかかりませんが、処理する必要があるすべてのオブジェクトがリストされているS3インベントリファイルがある場合は、それを入力として使用することができます。
大量のファイルを処理する場合、S3インベントリファイルをDistributed Mapの入力として使用する方がS3 listObjectsV2よりも高速です。これは、S3 Inventory ItemReaderの場合、マニフェストファイルを取得するための単一のS3 getObject呼び出しと、各インベントリファイルに対する呼び出しがあるためです。 Distributed Mapが設定されたスケジュールに従って実行されることがわかっている場合は、S3インベントリを事前に生成するようにスケジュールすることができます。
Module 2)
>>Intro
既存の事前作成されたStep Functionsワークフローを使用して、分散マップの一部の属性とフィールドを調整し、変更がパフォーマンスとコストに及ぼす影響を理解します。
ワークフローの選択
Step Functionsは、StandardとExpressの2種類のワークフローを提供しています。標準ワークフローは長期間実行するワークフローに最適で、365日間実行することができます。一方、Expressワークフローは5分間しか実行できません。 もう一つの重要な違いは、価格設定方法です。標準ワークフローは状態遷移に応じた価格設定ですが、Expressワークフローはリクエストの数と期間に応じた価格設定です。
分散マップを使用すると、ステップファンクションはサブワークフローを実行し、分散マップ内の状態を実行します。実行するサブワークフローの数は、処理するオブジェクトやレコードの数、バッチサイズ、同時性によって異なります。ユースケースに応じて、サブワークフローを標準またはExpressで実行するように定義することができます。
次のセクションでは、分散マップサブワークフローのワークフローのタイプを変更する方法、エクスプレスワークフローがユースケースに適しているかどうかを確認するためのテクニックを試す方法、および標準実行とエクスプレス実行のコストの影響について説明します。
1.Step Functionsコンソールに移動し、右側のメニューから「State Machine」を選択します。
2.OptimizationStateMachineで始まるワークフローを選択します。
3.ワークフロースタジオでワークフローを編集するには、「編集」ボタンを選択します。
4.右側で定義を有効にして、ワークフロースタジオで定義を確認します。
5.ワークフローグラフィックで、分散マップの「高降水量」ステップを強調表示します。
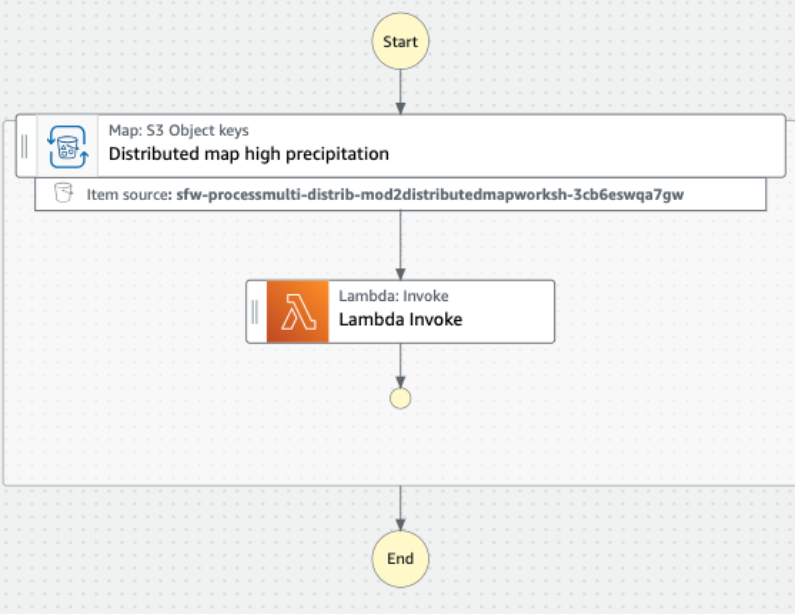
6.サブワークフロー「ExecutionType」を確認してください。STANDARDに設定されています。

7.バッチ設定も見てみましょう。 各サブワークフローは100個のオブジェクトのバッチ処理を行います。
8.サブワークフローはSTANDARDまたはEXPRESSで実行することができます。Expressワークフローは通常、Standardワークフローよりも低コストで高速に実行されます。
9.ワークフローが5分以内に実行されるかどうかわからない場合があります。このセクションでは、少数の項目でデータをテストできる分散マップ機能を使用します。
構成を編集するには、定義ボタンを切り替えてください。
1.追加構成を展開し、項目数制限を選択します。
2.最大項目テキストボックスに1と入力します。
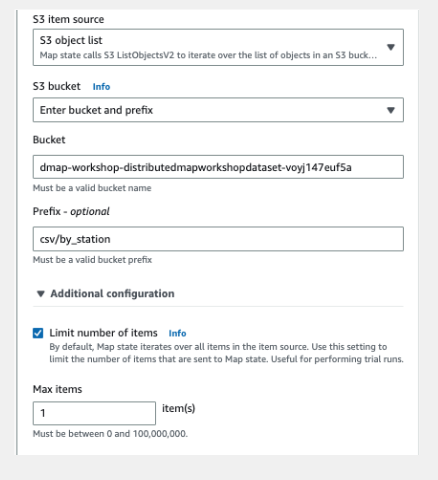
3.追加構成を展開し、項目数制限を選択します。
4.最大項目テキストボックスに1と入力します。
5.単一アイテムの持続時間を観察してください。約3秒です。
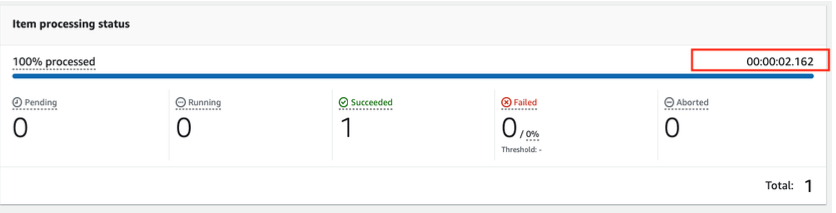
6.100項目について上記の手順を繰り返します。
7.Map Runページを閲覧して、100項目の期間を確認します。30秒未満です。
これで、1つの項目を実行するのに3秒、100個の項目を実行するのに26秒かかります。1つのサブワークフローで1000個のアイテムを1つの同時性で実行することも可能です。 ただし、この方法では、プロセスを高速化する並列処理を利用することはできません。 ワークフロースタジオに戻り、ワークフロータイプをEXPRESSに変更します。 この簡単なテストは、適切なバッチサイズを見つけ、データセット全体を実行せずにワークフロータイプを選択するのに役立ちます。
コスト検討
500K個のオブジェクトを処理し、バッチサイズを500に設定したと仮定した場合、
1.バッチを有効化(サブワークフローごとに6つの状態遷移):
a. サブワークフロー数: 1000(500Kオブジェクト/ワークフローあたり500オブジェクト)
b. サブワークフローあたりの総状態遷移: 6 (ワークフロー開始+ラムダ関数)
c. サブワークフローあたりの総コスト: (6 * 1000) x $0.000025 = $0.15
2.シナリオ1(サブワークフロー内の5つのステップ):
a. サブワークフローあたりの総状態遷移数: 6
b. サブワークフローあたりの総コスト: (6 * 1000) x $0.000025 = $0.15
3.シナリオ2(サブワークフロー内の2つのステップ、バッチ処理なし):
a. サブワークフロー数 500K
b. サブワークフローあたりの総状態遷移数: 3
c. 総コスト: (3 * 500K) x $0.000025 = $37.4
高速ワークフロー(express workflow)の場合、
4.エクスプレスワークフローコスト(平均持続時間100秒):
a. エクスプレスリクエスト費用:1リクエストあたり$0.000001
b. 持続時間コスト: (100,000 MS / 100) * $0.0000001042 = $0.0001042
c. ワークフローコスト: (エクスプレスリクエストコスト + 持続時間コスト) x リクエスト数 = ($0.000001 + $0.0001042) x 1000 = $0.10
5.エクスプレスサブワークフロー(ワークフローごとに1つの状態遷移):
a. 総状態遷移数: (1 * 1000) x $0.000025 = $0.025
b. 総費用: $0.10 + $0.025 = $0.125
高速ワークフローの計算を30秒間繰り返すと、総コストは0.057 USDとなります。
バッチ処理を利用できず、1秒間実行される個々のオブジェクトに対してエクスプレスワークフローの計算を繰り返すと、総コストは13.42ドルになります。
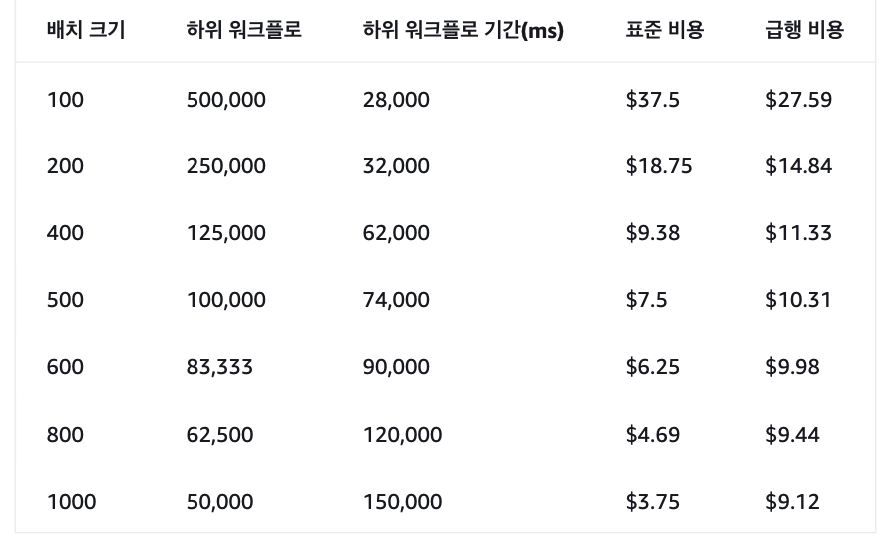
セッションを終えて
分散マップを活用してデータ処理ワークフローを構成することで、効率的かつ費用対効果の高い大量のオブジェクトを並列に処理することができ、特にエクスプレスワークフローを利用することで、短時間かつ低コストで迅速な実行が可能であることを学ぶことができました。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner