MEGAZONEブログ

Deep dive into the latest Amazon RDS for Oracle innovations
最新のAmazon RDS for Oracleイノベーションを深く掘り下げる
Pulisher : Mass Migration & DR Center ムン・ボンギ
Description : Amazon Auroraの紹介と、データベースやアプリケーションの実行にどのようなメリットがあるかを知るセッション
はじめに
Amazon Auroraのイノベーションについて学び、Auroraがどのように機能するのか、どのような利点があり、実務でどのように適用できるのかを確認したいと思い、このセッションを申し込みました。
セッションの概要紹介
Amazon Auroraについて詳しく学び、どのように動作するのか、データベースやアプリケーションの実行にどのようなメリットがあるのかを理解するセッションです。
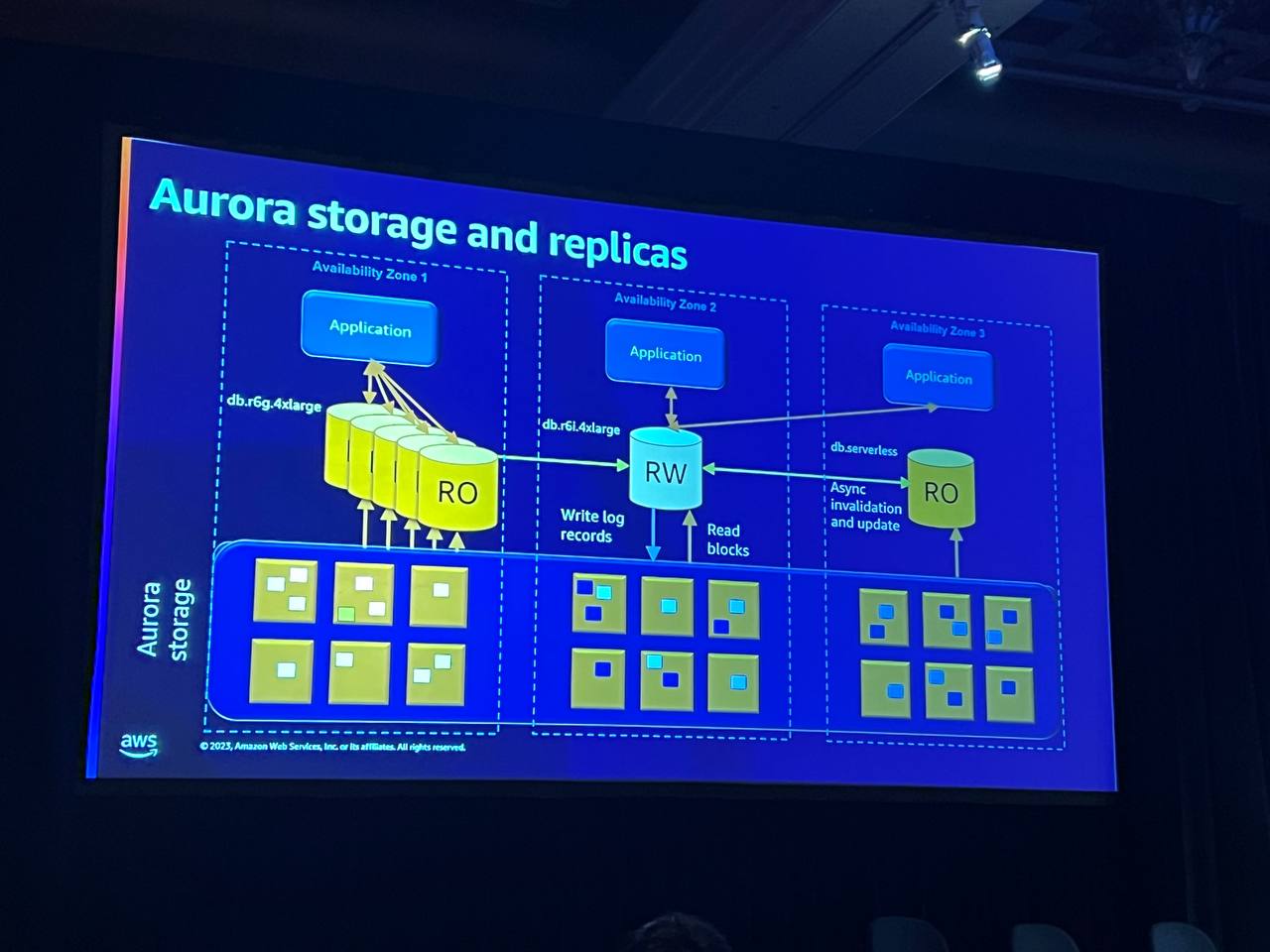

Storage
Auroraは、3つの利用可能な領域に分散して耐久性を提供します。黄色のボックスはストレージサーバーで、数千台のサーバーで構成されたマルチテナントシステムです。セグメントごとに6箇所に書き込みを行い、4つの6クォーラムが完了しなければ書き込みが認められません。障害が発生しても、システムは継続的に耐久性を提供し、他のストレージノードの障害にも耐久性を維持します。セグメントが失われた場合でも、Peer-to-Peerレプリケーションを通じてコピーを取得することができます。
Replica
Auroraでは、読み取り用に追加のコピーを作成することなく、共有ストレージに接続することができます。 ただし、データの変更をデータベースに通知するために、読み書きノードから読み取り専用ノードにメッセージを転送します。トランザクション状況は非同期的に処理され、読み取り専用アプリケーションに適しています。最大15個の読み取り専用ノードを複数の利用可能領域に配置することができ、サイズとタイプを自由に組み合わせることができます。ストレージは必要に応じて自動的に拡張・縮小され、使用した容量分だけ課金されます。可用性ゾーンまたはインスタンスに障害が発生した場合、読み取り専用ノードにフェイルオーバーし、DNSシステムを介して新しい接続を確立するのに時間がかかります。
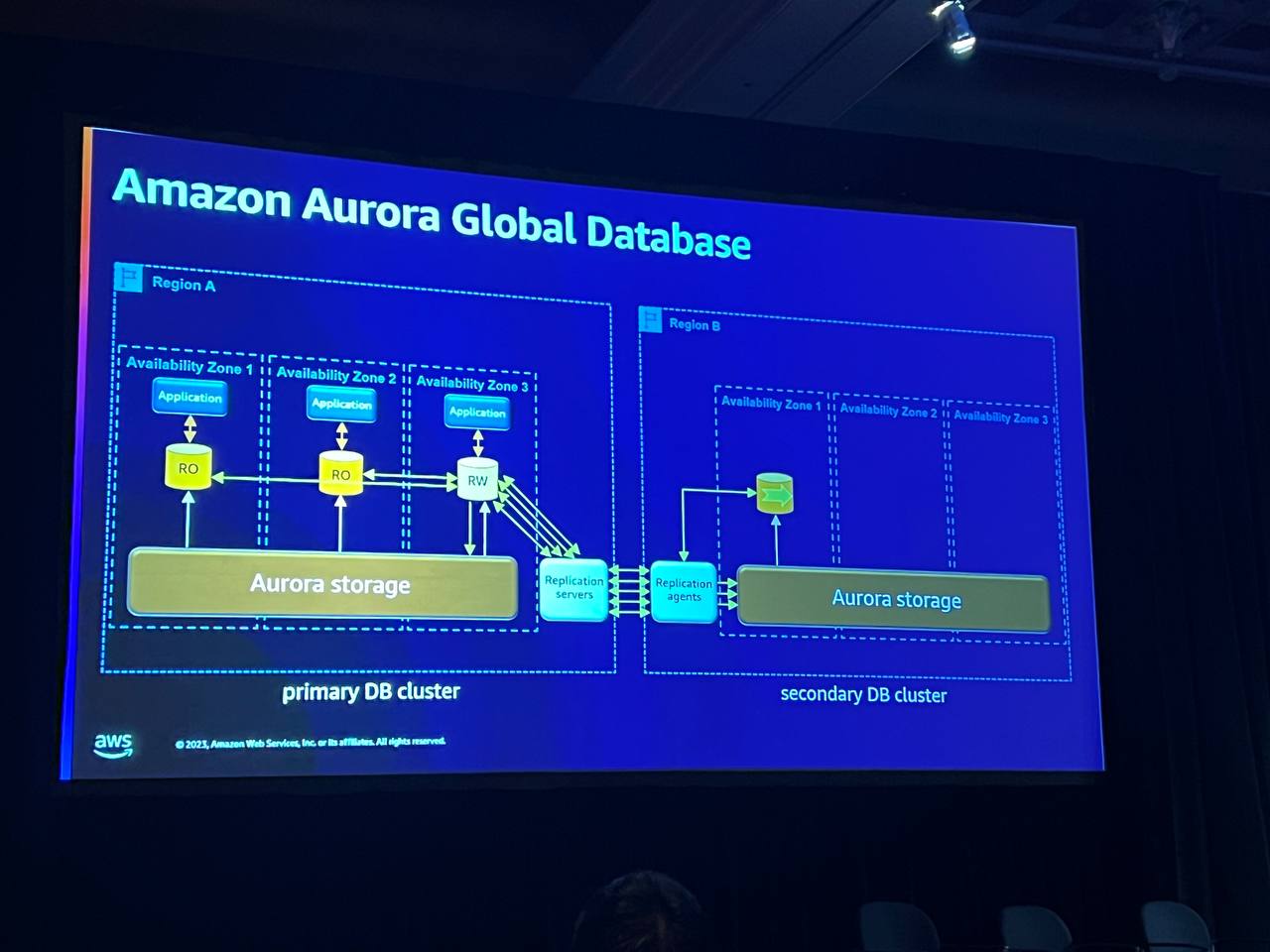
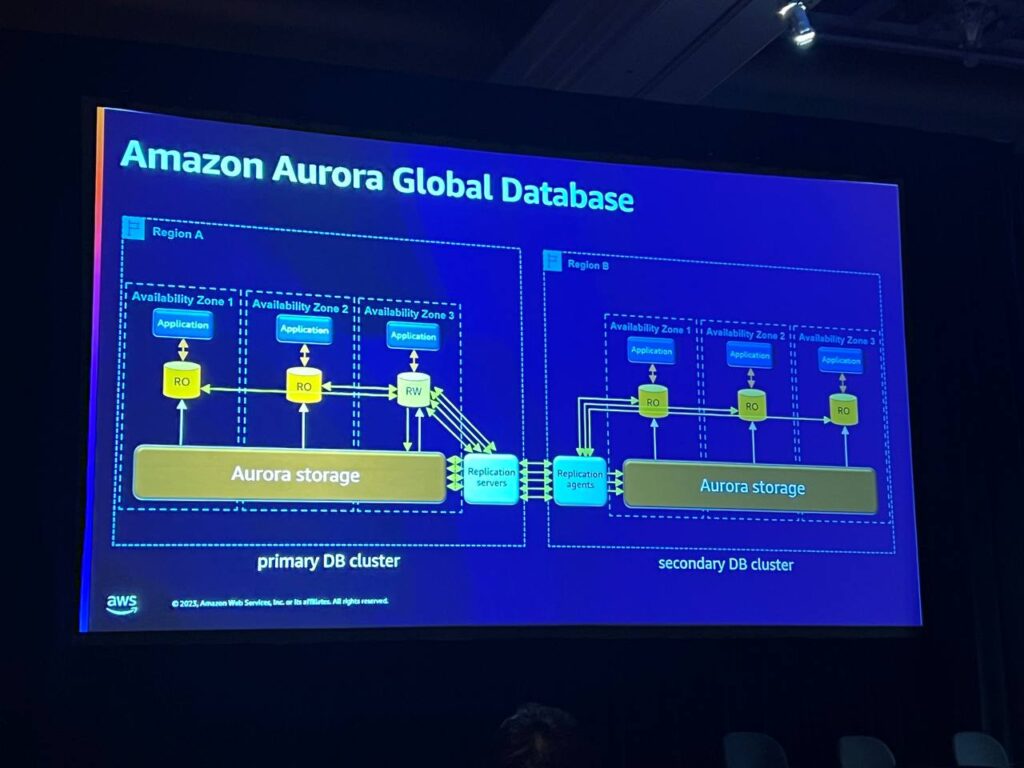
Global Databaseは迅速な障害克服を提供します。例えば、地域Aでグローバル復元力が必要な場合、グローバルデータベースを有効にすることができます。これにより、別途の管理なしに他の地域からデータベースを取得することができ、レプリケーションサービスエージェントがこれを処理します。セグメントベースのアーキテクチャの利点は、すべての作業を並列に実行できることです。
これにより、グローバルな回復力が保証されますが、同時に読み取り専用ノードを追加して、ローカルリージョンで読み取り作業を行うことができます。データの複製と検証はエージェントを通じて非同期的に行われ、複数の読み取り専用ノードを追加して読み取りタスクを実行することができます。
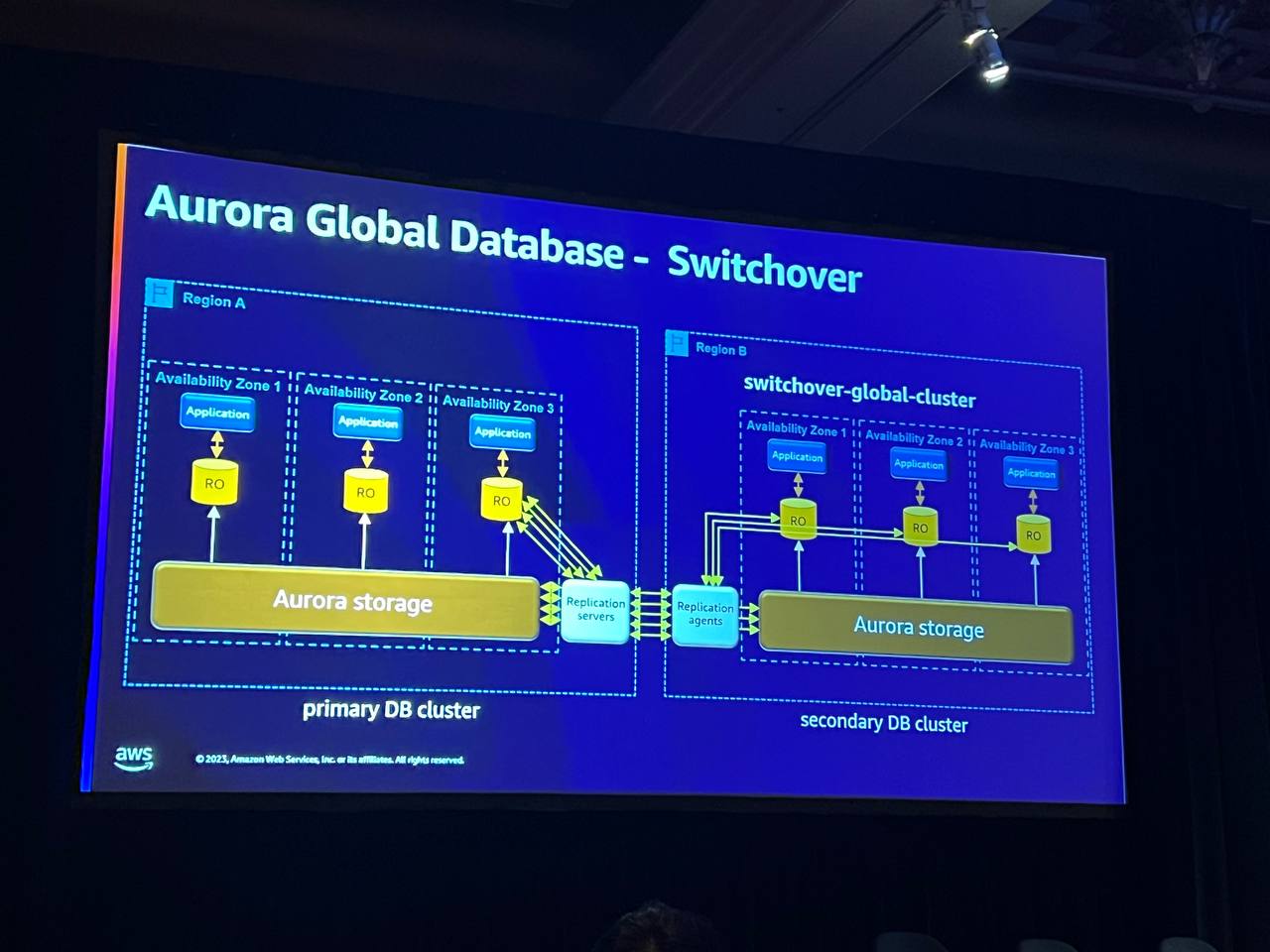
Switchoverコマンドを実行すると、まずリージョンAを読み取り専用に変更し、レプリケーションがシステムから出るようにし、ボリュームが一致していることを確認します。 次にリージョンBを有効にして機能を切り替え、リージョンAで起こっていることを除いてすべてが対称的で正しいことを確認します。
このプロセスは非常に迅速に行われ、必要に応じて繰り返しテストしたり、リージョンを移動したりすることができます。グローバルデータベースは障害対応に使用される主な理由であり、スイッチオーバー機能はこれをサポートします。

フェイルオーバーは、そのリージョンに問題がある場合、Bリージョンにフェイルオーバーを実行し、このコマンドは以前のクラスタで使用できますが、アプリケーションという追加フラグがあり、移動中の少量のデータがリージョンに転送されない場合があります。フェイルオーバー作業は1~2分程度の時間、フェイルオーバーが行われます。
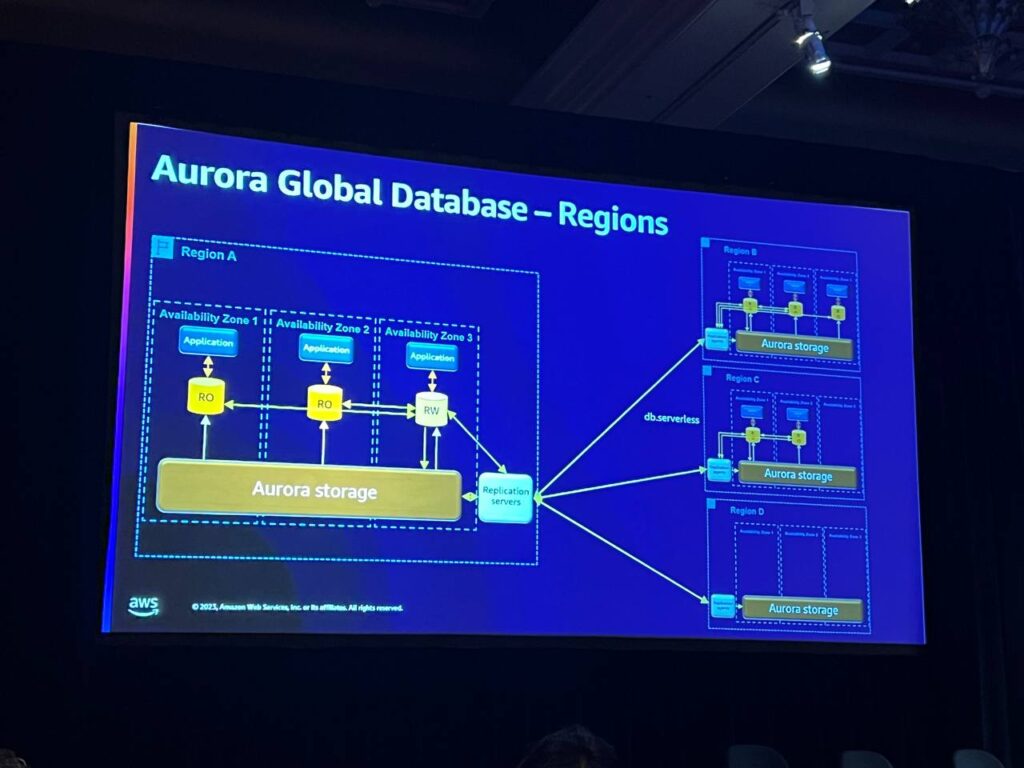
Aurora Global Databaseは、最大5つのターゲットリージョンを設定できます。リージョンBとCはサーバーレスノードを使用し、リージョンDは単にストレージのみを使用することができます。 つまり、構成を混合して一致させることができます。多くの場合、マルチリージョンを使用して、顧客により近いリージョンにローカルコピーを配置することで、アプリケーションの読み取り待ち時間を改善します。
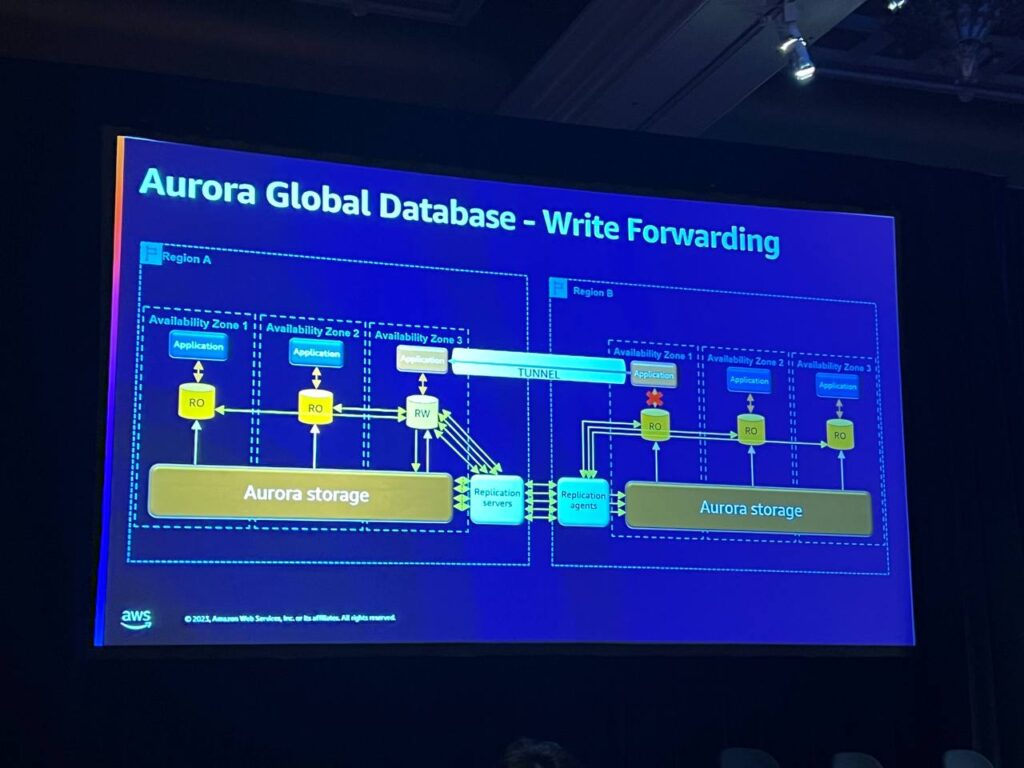
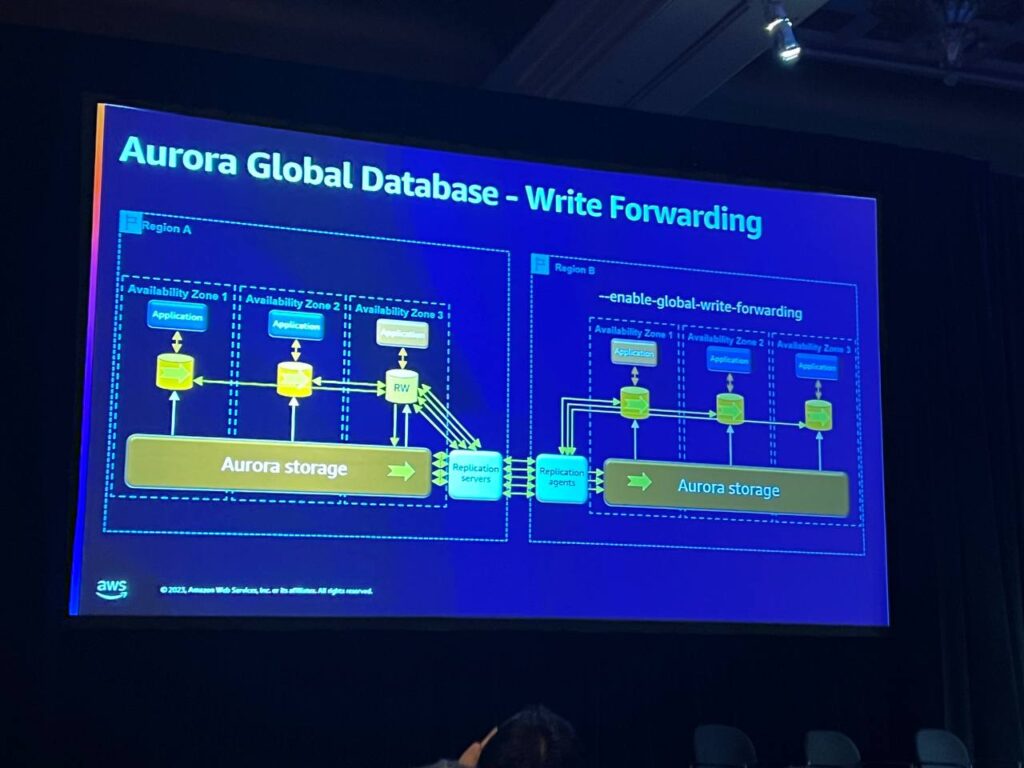
インスタンスでWrite Forwardingを有効にすると、書き込み操作がRegion Aの読み書きノードに転送されます。これにより、書き込みは他のクライアントから来たように見えます。一般的な書き込みが行われるすべての場所(自分自身を含む)に流れ、デフォルトモードでは、書き込み後の読み取り一貫性が得られます。セッションレベルの待ち時間が発生し、選択したデータが正常に戻るまで待ちます。
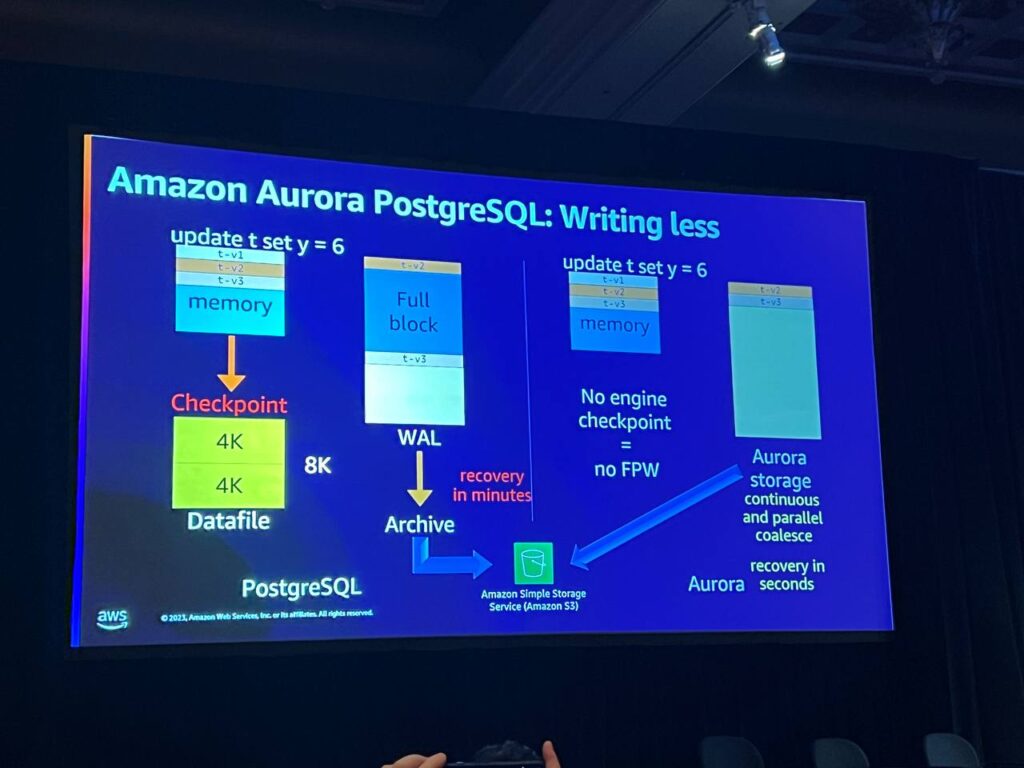
Auroraで同じ更新を行うと、ストレージに送られるのはログベクトルだけです。それが最初のタプルか、2番目のタプルか、3番目のタプルかは関係ありません。 常に同じです。実際にはチェックポイントを実行せず、ページ全体の書き込みも行いません。
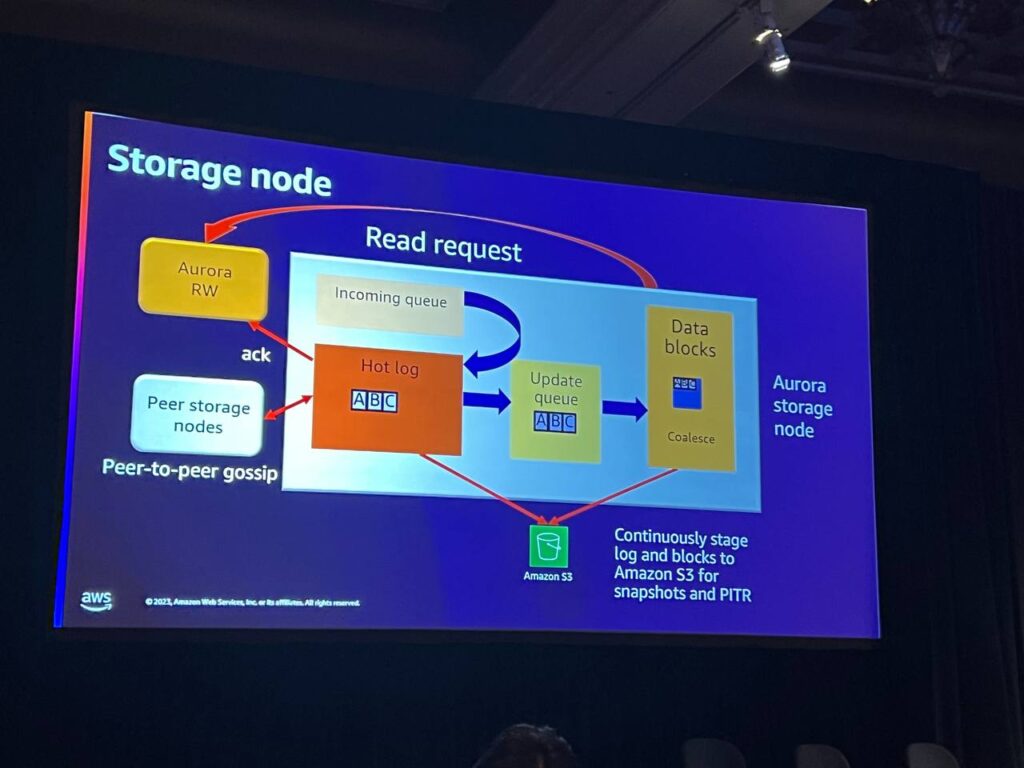
ストレージノードでは、読み書きノードが変更を送信し、それをインメモリキューに送信します。ホットログに到達するまでは耐久性がなく、確認されません。 変更はシーケンス番号を使用して追跡され、不足している部分は仲間のノードに確認されます。確認された変更は更新キューに移動し、ブロックにマージされて保存されます。
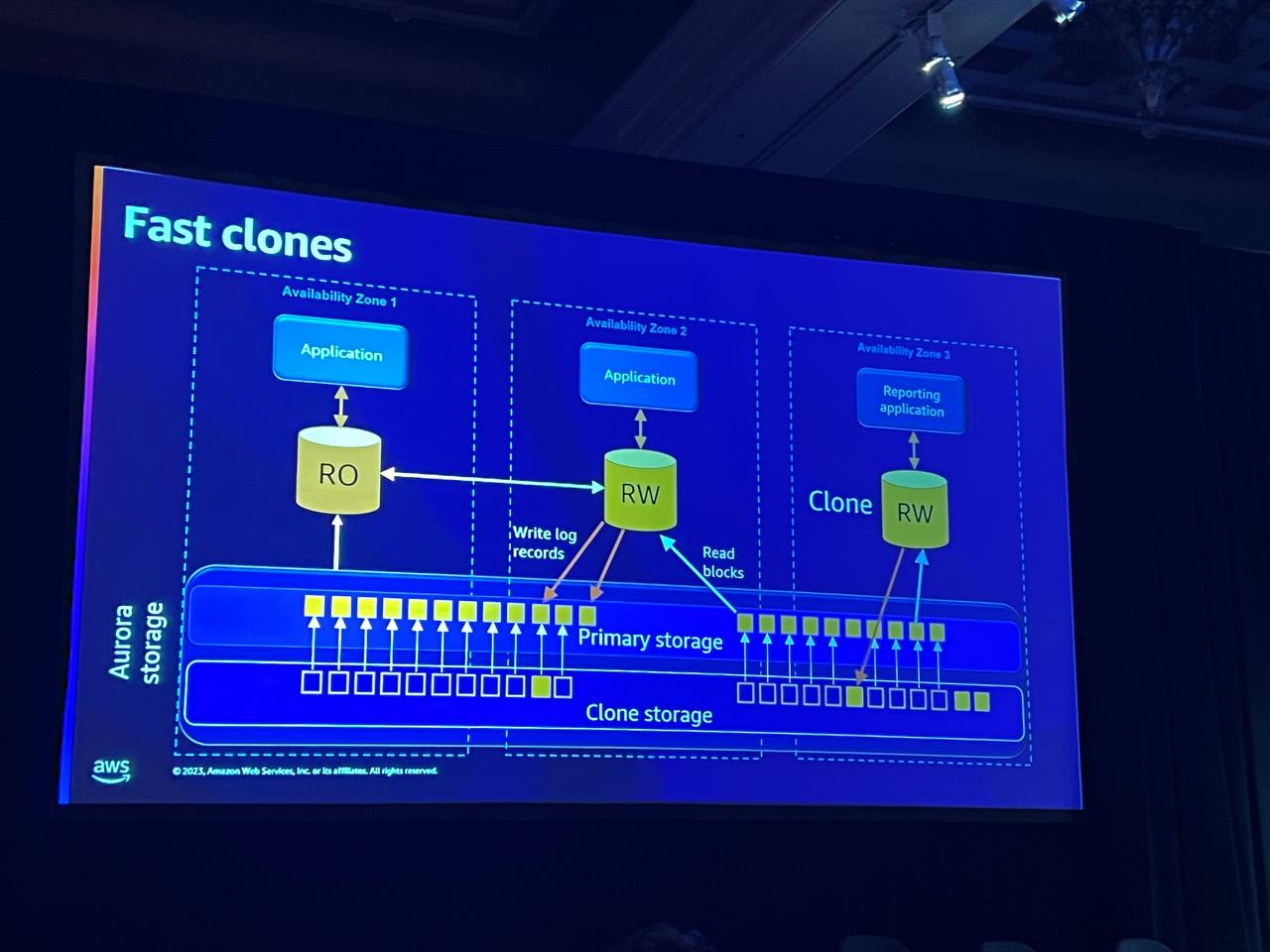
たとえば、アプリケーションを実行するために新しいデータベースが必要な場合があります。スナップショットを復元することはできますが、これが10TBのデータベースの場合、10TBを復元する必要があります。 この作業を行う間、10TBを数時間支払う必要があります。代わりに、クローンをリクエストしてクローンを作成し、そのインスタンスを接続することができます。このインスタンスは基本的にクローンストレージを見ていますが、これは最初は実際のメインストレージへのポインタに過ぎません。 この場合、書き込みまたは読み取りを実行すると、ポインタは元のストレージにリダイレクトされ、即座に行われます。クローンを実行する場合、変更に対して3つのブロックのコストしかかからないため、非常に費用対効果の高い方法です。

Aurora MySQLのアップデート
・3.0.5 (8.0.32 compatibility)
・インスタンスタイプr7gのサポート
・MySQL 8の物理的なマイグレーションのためのPercona Xtrabackupのサポート
・Local Write Forwardingのサポート
・Parallel Export to S3 をサポート
・改善されたbinlog

Aurora PostgreSQL updates
・Support for PostgreSQL 15 – 新しい拡張機能のサポート
・インスタンスタイプr7gのサポート
・マイナーバージョンとパッチのアップグレードタイムの一貫性の向上
・read replicaの可用性の向上
・QPM on replicasのサポート
・Logical Replication cacheの追加
・pgvector と pgactive 拡張機能のサポート
・PostgreSQL 16 Previewのサポート

PG vectorはオープンソースで、ベクターをサポートするリポジトリを追加することを目的としています。現在、2つの異なるインデックスタイプがあり、それらを使用してデータをインデックス化します。
これにより、生成型AIのケースをサポートするために必要なすべての機能が追加されます。これにより、PostgreSQLデータベースでビジネスにおける生成型AIの新たなニーズをサポートすることができます。

Aurora Serverlessは動的に拡張される機能で、一般的なサーバーレスの概念をデータベースに適用したものです。
パフォーマンスの問題を解決するために、Aurora Serverlessは1秒あたりの使用量ベースの支払い方式を導入しており、予期せぬクエリの実行で発生するパフォーマンス低下をリアルタイムで検出し、Serverlessでは動的にリソースを拡張して遅延時間を最小化する効果的な方法を示しています。

Buffer pool resizingは、需要に応じてバッファプールのサイズを動的に調整する方法の一つです。バッファプールは通常、プロビジョニングとサーバーレスの両方で75%のRAMがデフォルトで設定されています。 これが開始点であり、読み取りが行われるとバッファプールが開き、ブロックが読み込まれます。より多くの読み取りが発生すると、バッファプールは拡張され、ブロックで満たされます。
バッファプールが必要な場所に設定され、作業負荷が発生している間はすべてがスムーズに行われます。作業負荷が停止すると、そのメモリはページを削除することで素早く縮小することができます。これは、ジョブセットのサイズが正確にわからない場合に非常に効果的に機能し、Serverlessのもう一つの利点の一つです。
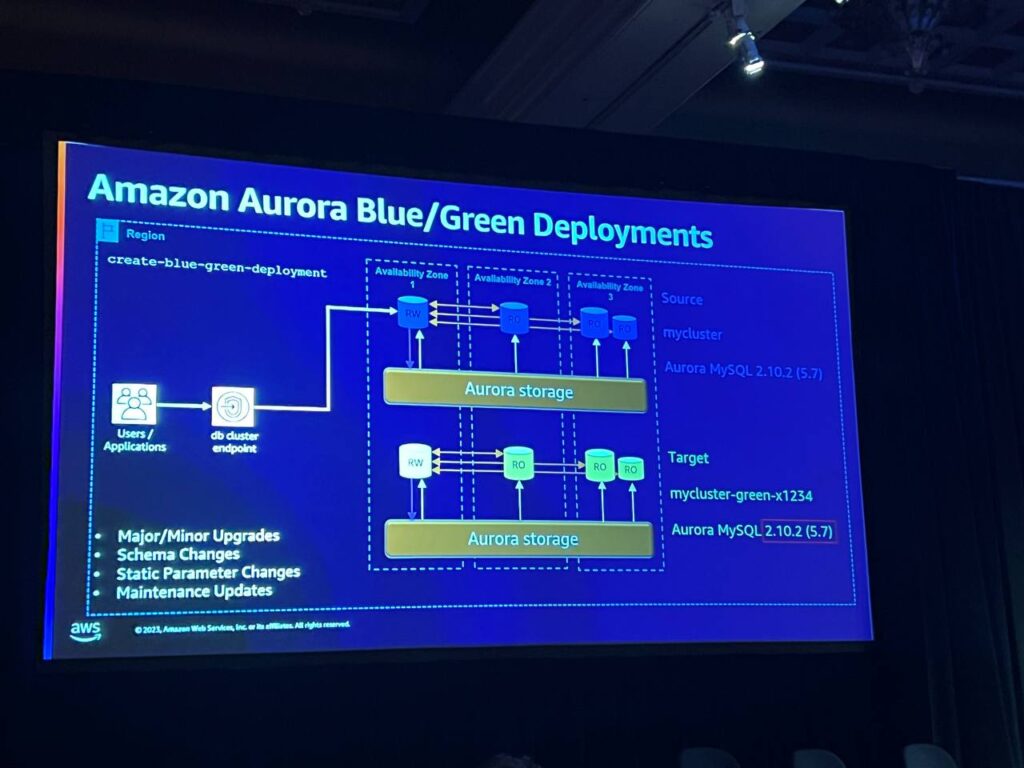
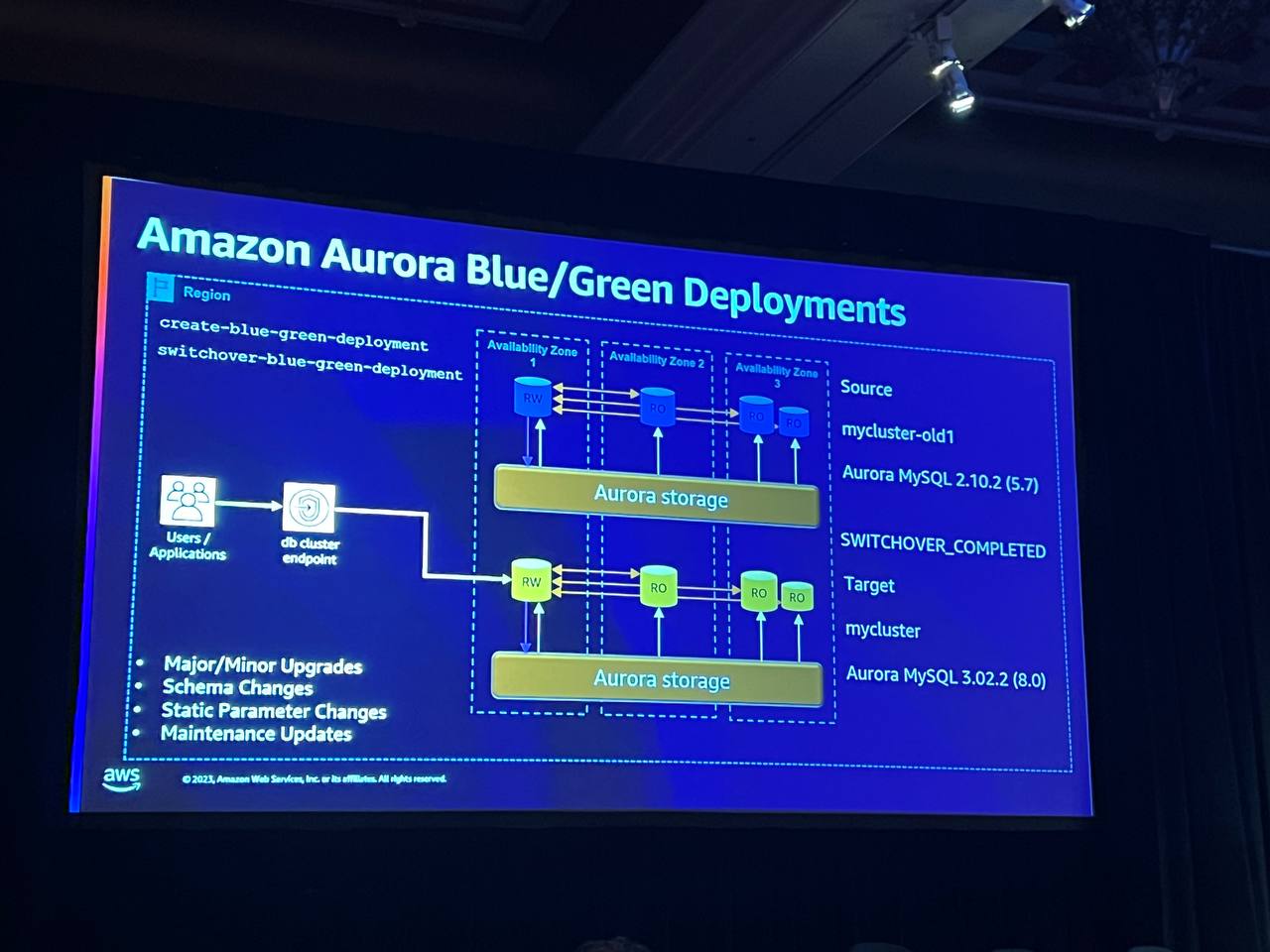
ブルー/グリーンデプロイメントは、設定全体のコピーを作成してデータベースのアップグレードを実行します。このモデルには、インスタンス、パラメータなどがすべて含まれ、ターゲットの名前はブルーとグリーンの面で同様に表示されます。アップグレードはスキーマやパラメータの変更などの作業を自動化し、主にメインバージョンのアップグレードに使用されます。データベース間の同期のためにレプリケーションの遅延を最小化し、スイッチオーバーを通じてアプリケーションを新しいクラスターに切り替えます。
この時、すべての構成変更を確認した後、変更を完了し、スイッチオーバーを実行します。アプリケーションは、エンドポイントの変更で自動的に新しいクラスターに移動し、ターゲットの名前も変更されないため、スクリプトの修正が必要ありません。 これにより、変更作業が簡素化され、ブルーグリーン展開が完了したら、削除を実行します。この時、元のソースを削除するのではなく、分離して確認作業を行った後、安全に削除できるようにします。
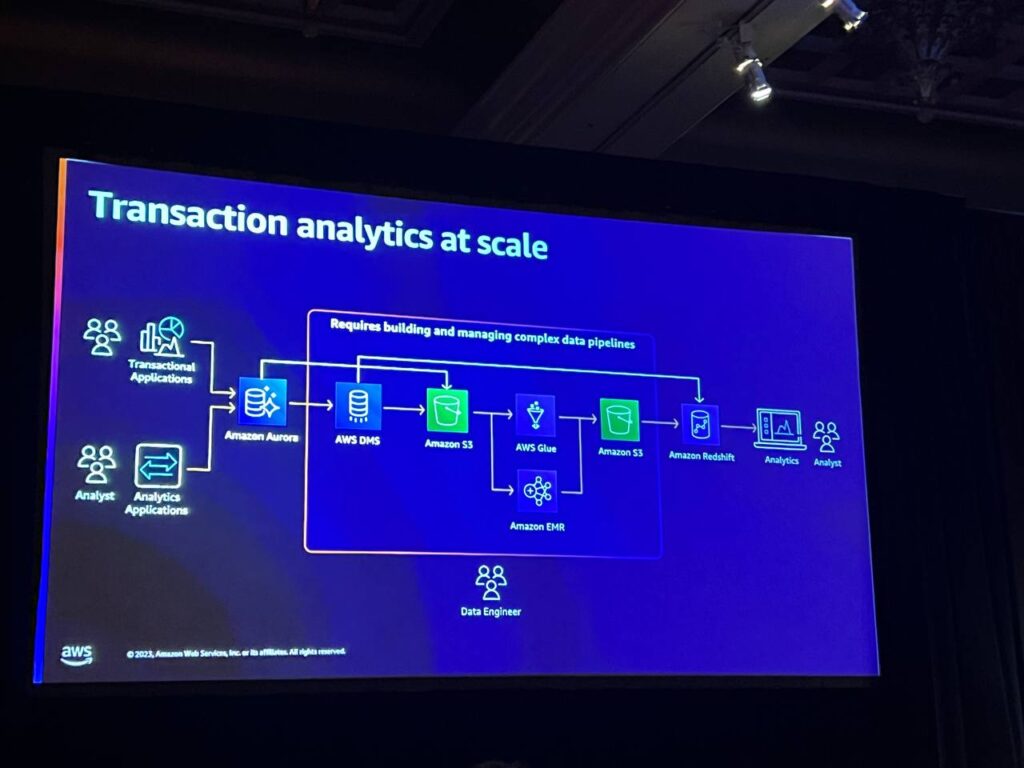
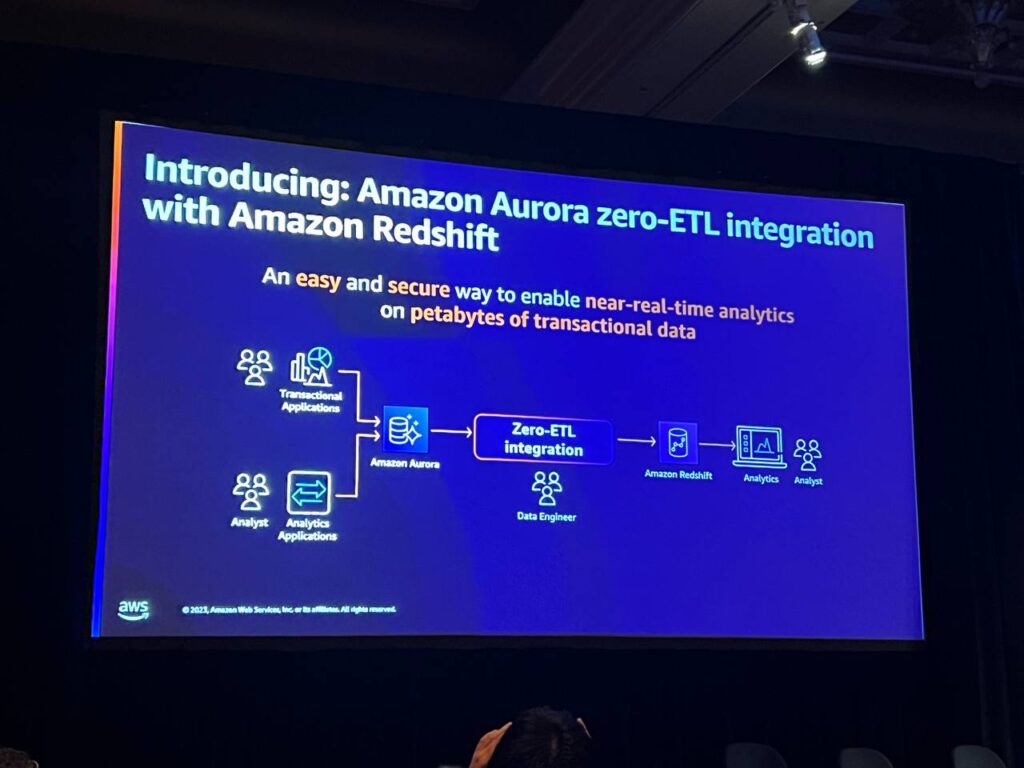
左側の伝統的なセットアップを見ると、2つのシステムを接続するために多くのサービスを利用することができますが、これは私たちが設定、維持、運用することがたくさんあります。 実際に多くの変換を行うことなく、単に一方から他方へのデータが必要な場合、これは複雑な作業です。 zero-ETLは簡単、安全、非常に高速で、バッチ処理ではなく、AuroraとRedshiftの間で変更をストリーミングすることができます。
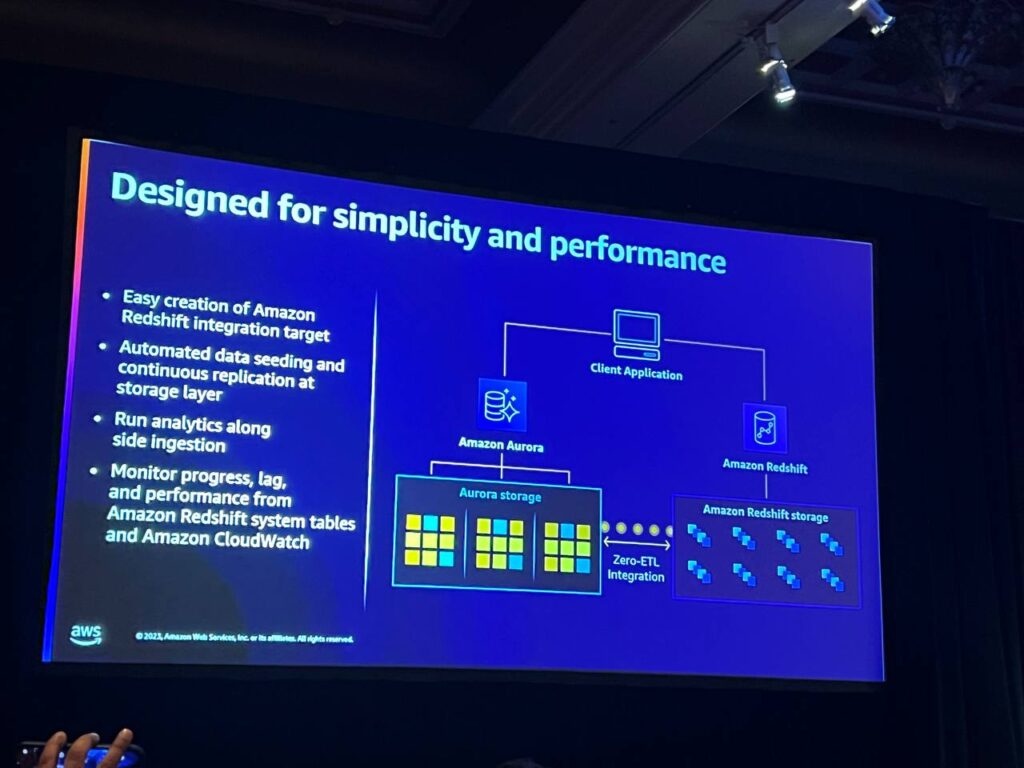
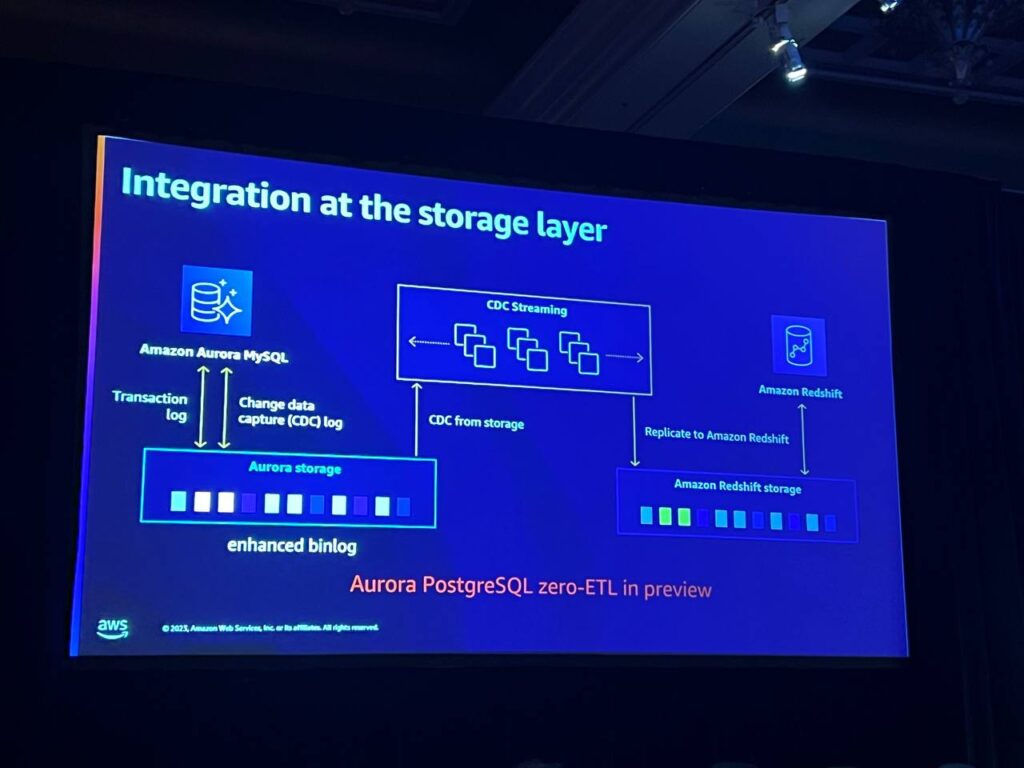
zero-ETLの重要な特徴は、リポジトリ間の転送であり、初期シード生成から継続的な複製、変更検出、復元まで自動化されています。レプリケーション機能の動作を確認するためのメトリックが提供され、遅延や問題を迅速に把握することができます。
MySQLの場合はbinlogを使用し、AuroraからRedshiftへの移行には並列直接エクスポートを利用します。強化されたbinlogを使用して、継続的なRedshiftの変更を処理するCDCパイプラインに供給します。これにより、Redshiftへの更新の待ち時間が非常に短くなります。
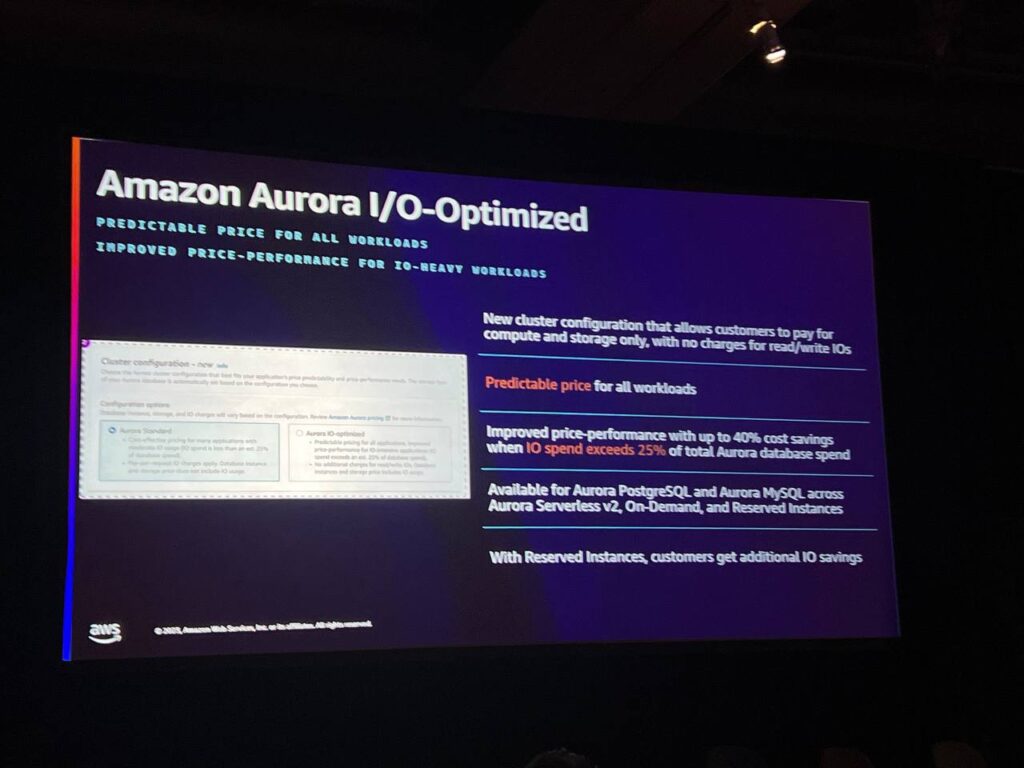

Aurora I/O-Optimizedは、高いI/O負荷に対して予測可能な価格と優れた性能を発揮します。コンソールでの画面ショットは、作成または変更時にどちらかを簡単に選択できることを示しています。
これは主に大量のI/Oを実行するユーザーを対象としており、Aurora全体の支出の25%以上をI/Oコストに使用する場合、40%程度のコスト削減を確認し、この機能を使用してコストを50%以上節約した事例もあります。PostgreSQL、MySQL serverless v2、オンデマンドに対してサポートされ、クラスターレベルで設定され、すべてのノードに適用されます。月に1回切り替えることができますが、月に何度も切り替えることも可能です。試してみたい方はいつでも可能です。

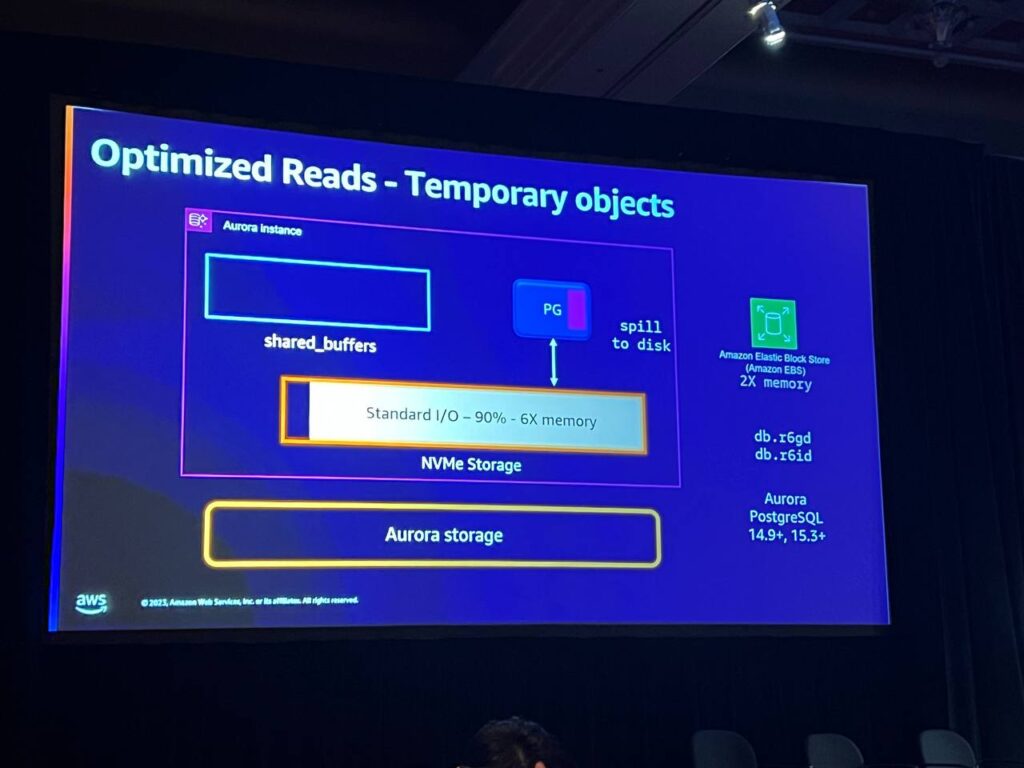
Temporary objectsとは、ソートやディスクへのスパイルなどの作業を意味します。Auroraでは従来、このようなスパイルが発生するとEBSに移動していましたが、最適化された読み取りを使用すると、スパイルはNVMストレージに移動します。これにより、6倍のメモリが確保され、より大きなソートが可能になり、レイテンシーが削減されます。
標準のI/Oプランを使用する場合、Auroraインスタンスタイプを注文すると、そのNVMストレージの90%を一時的なオブジェクトに割り当てます。これにより、Auroraインスタンスのサイズを大きくすることなく、ソートや大規模なインデックスを構築したり、大量のソートを同時に行う必要がある場合に、この機能を使用することができます。一方、IO最適化を使用する場合は、2倍のメモリを提供します。


Tiered Cacheは、追加のキャッシュ層として全体のメモリサイズの4倍を使用できるようになり、インスタンスでより多くの作業を行うことができるようになりました。 このキャッシュは、メタデータを活用してブロックがTiered Cacheにあるかどうかを確認し、ない場合は通常の読み取りが行われます。ブロックがメモリに読み込まれ、使用が停止されると、そのメタデータが更新され、Tiered Cacheにあると表示されますが、これは非同期的に行われるため、他の作業を妨げることはありません。
Tiered Cacheにブロックをインポートする時、メタデータを活用するため、Auroraリポジトリに比べて高速で、更新時にはメタデータのみ迅速に更新され、無効化やキャッシュの更新にほとんど変更がないため、迅速に処理されます。
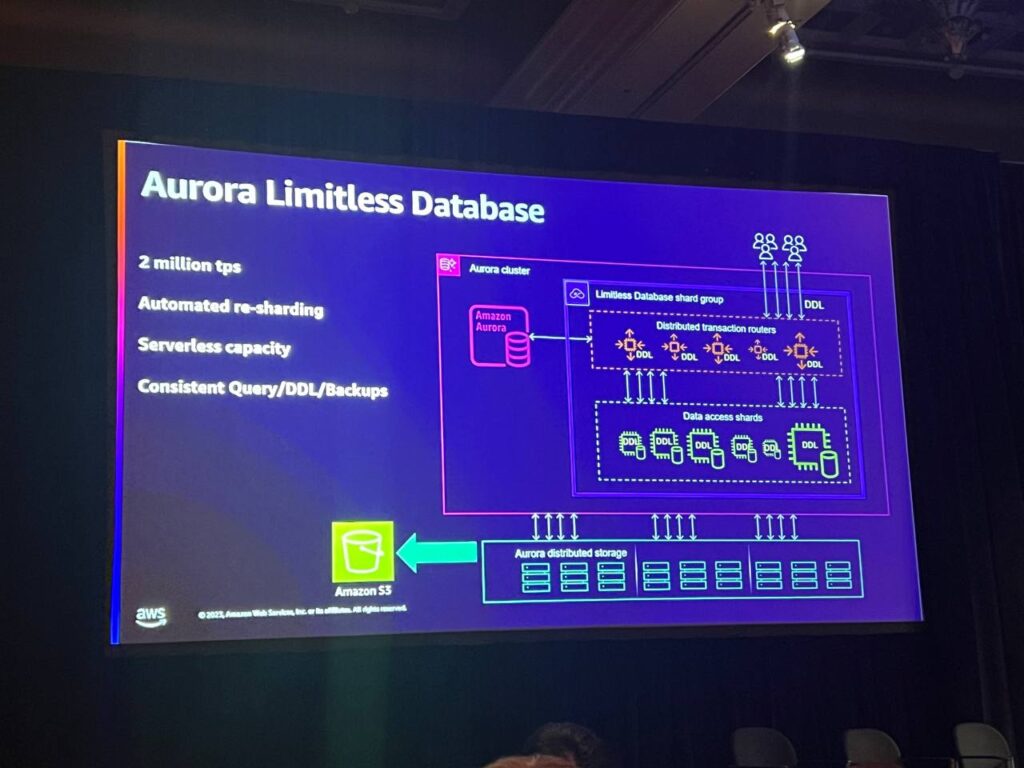
Limitless Databaseは一般的なオーロラクラスタから始まります。これは別のものではなく、その一部であり、リポジトリとこれらの要素を集めるコンテナであるシャードグループがあります。まず、分散トランザクションルーターを取得し、これを単にルーターと呼びます。ここでアプリケーションを接続し、クエリはここを経由してルーティングされ、分散クエリ、分散トランザクション、DDL、demailなどを処理します。データはシャードに保存されており、サイズが異なることを確認することができます。ハッシュシャーディングを行い、データ分布に応じてカットして一致させます。Limitless Databaseは拡張が可能です。最大2百万TPSまで可能で、システムがよく拡張することができます。
また、シャードが発生すると自動的にリシャードして分離します。サーバーレス技術を使用して、ルーターとシャードの両方について言及したサーバーレス容量があります。このサーバーレス技術のおかげで、日中にすべての負荷が移動しても、分割や追加なしで処理することができ、一貫性を維持します。DDLを実行する際、ルーターとシャードの両方がそのDDLを認識するため、システム全体で分散トランザクションを実行します。一貫性のあるシステムなので、一貫性のあるバックアップを行うことができ、分割トランザクションの問題が発生しません。
セッションを終えて
Amazon Auroraの革新について知ることができて良かったし、その機能がどのような方式で駆動されるのか、細かい説明を聞くことができて良かったです。 そして、過去の事例及びどのような問題を改善して性能が向上し、コスト削減効果を達成したかの説明も聞くことができ、これを実務でどのように適用及び導入できるかを考えることができるセッションでした。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner