MEGAZONEブログ

Improve your search with vector capabilities in OpenSearch Service
OpenSearch Serviceのベクトル機能で検索を改善
Pulisher : AI & Data Analytics Center ソン・スルギ
Description : Amazon OpenSearch Serviceをベクターデータベースとして使用する方法についての紹介セッション
はじめに
検索エンジンは、データ量が多くなり、次元が高くなるにつれて、単純な類義語検索のレベルを超えて、様々な検索方法やデータ保存方法などが発展してきました。 特に、Gen AIが脚光を浴びている昨今、ベクトルベースの検索エンジンの使用が可能なOpenSearchへの関心が高まっている状況で、検索性能を高めることができる方法論について確認することができると期待しています。
セッションの概要紹介
検索エンジンは、ユーザーに目的に合った情報にたどり着くための経路を提供します。検索された項目がユーザーの意図と一致する場合、関連性があると見なされます。関連性のある結果の検索には、カタログにデータが存在するかどうか、データの分析方法、テキストやベクトル表現、ランキング機能、その他の操作が含まれます。このセッションでは、Amazon OpenSearch Serviceをベクターデータベースとして使用する方法を学び、ユーザーが最も関連性の高い結果を得るためにどのように役立つかを学びます。


人工知能(AI) & 機械学習(ML)のブーム
- 最近、優れた基本的なNLPを提供する大規模な言語モデル(LLM)が生まれ始め、チャットボットサービスがこのような専門分野の認知度を高めるきっかけとなりました。
- セマンティックとは、検索技術の一つで、テキストの意味を理解し、キャプチャして検索結果の精度を向上させる技術です。
- 大規模言語モデル(LLM)は、テキストをベクトルに変換してセマンティック情報をキャプチャします。 これは、テキストの意味、文脈、概念を含みます。
- Open Searchは、このようなベクトルベースのSemantic検索をサポートし、検索結果のSemantic一致率を向上させます。ベクトル化された自然言語テキストを使用して、検索クエリとデータ間のSemantic一致を測定し、検索結果をより正確に提供します。

OpenSearch サービスの主なワークロード
- Open Searchはサーバーレスオプションを提供し、サーバー管理やインデックス戦略について心配することなく機能を使用できるようにします。
- 検索 Workload
- データフロー : データがOpen Searchに流れると、Open Searchがそのデータに対するインデックスを生成し、ユーザーはクエリを介してそのデータを検索し、結果を取得することができます。
- インデックス : 効率的な検索のためにそのデータに対するインデックスを生成します。
- セマンティック検索:ベクトル化された自然言語テキストを使用してセマンティック検索を行い、検索結果をテキスト対テキストの一致ではなく、ベクトル空間での意味的類似性を考慮して提供します。
- 分析ワークロード
- ログデータのモニタリング:Open Searchは、ログデータを収集して可視化ダッシュボードに出力することで、インフラ、アプリケーション、セキュリティなどのリアルタイムモニタリングをサポートします。
- 統合および機能拡張:Open Searchは、様々な統合および機能拡張を提供し、データを効率的にクエリしてモニタリングするのに役立ちます。
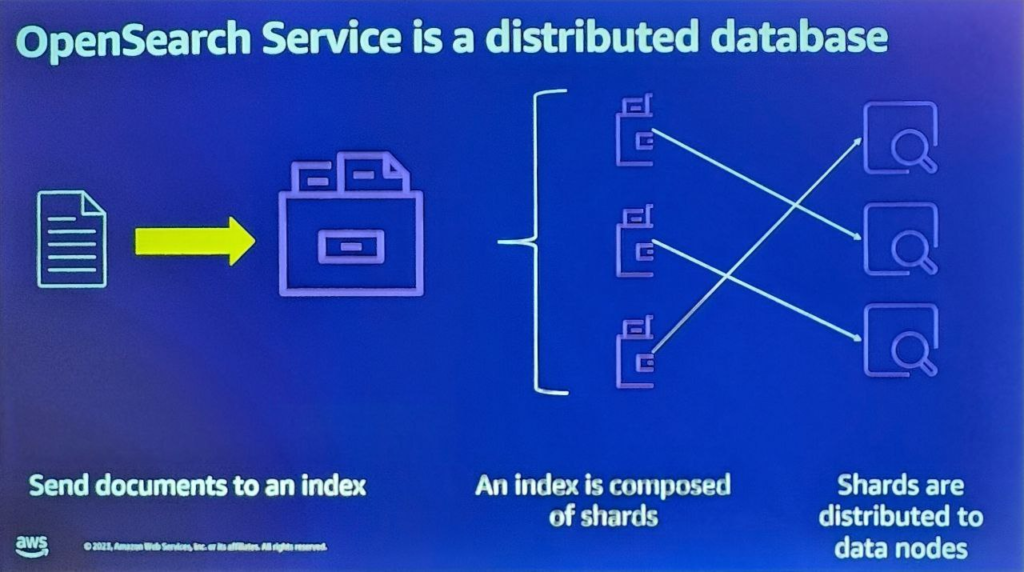
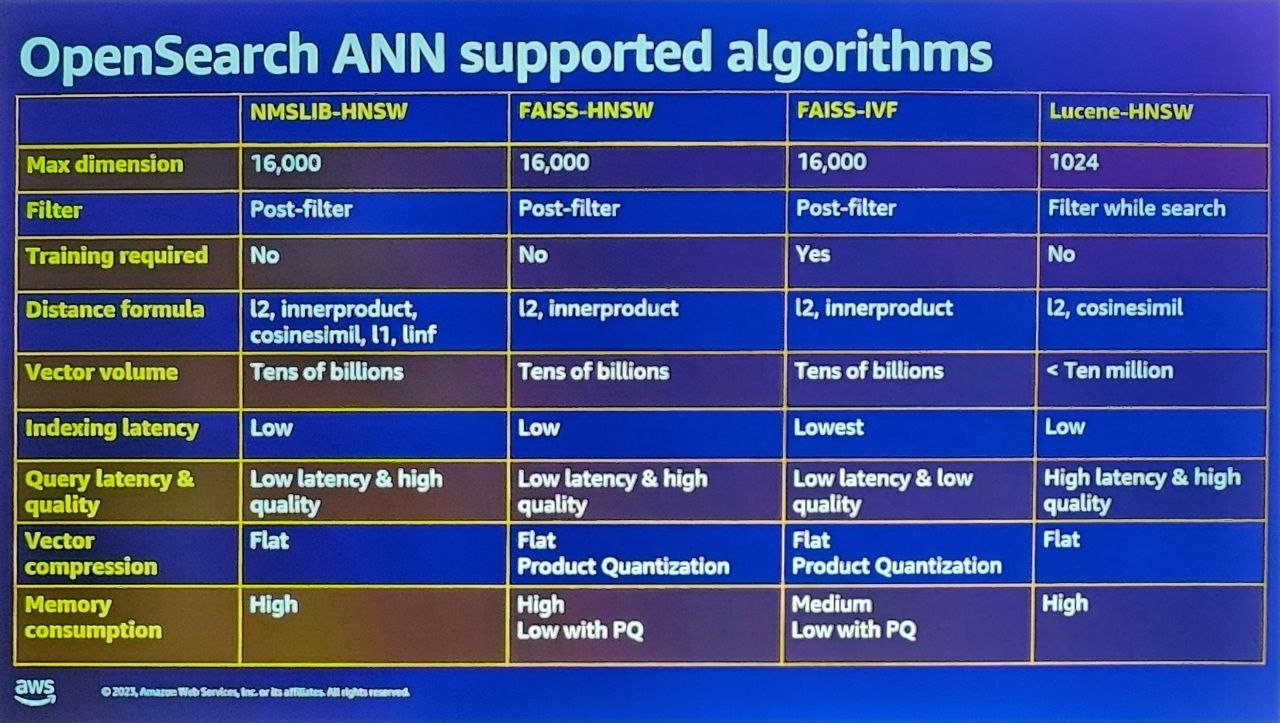
OpenSearchのデータ保存と検索原理
- Open Searchに文書を送ると、Open SearchはJSONのすべてのフィールドをインデックス化して検索可能にします。
- インデックス自体はデータのパーティションのためのシャード(shard)で構成されます。基本シャードを指定すると、データを小さなシャードにランダムに分散させます。
- そのデータに対する検索を実行する際、KNN検索方法が活用され、データポイント数が数十億件に達する場合、ANN検索が適用されます。
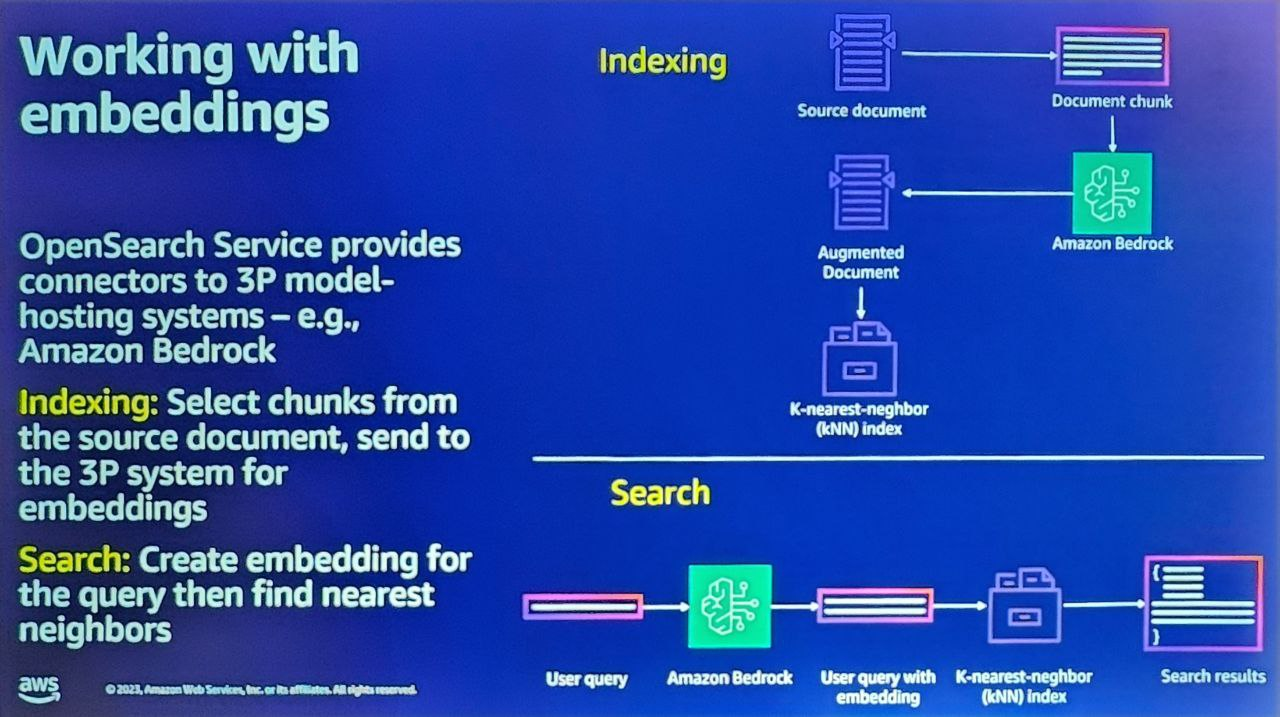
OpenSearch Embedding 機能と原理
- OpenSearchは3rd Partyモデルに対するコネクタを提供し、Bedrock、Claude、CohereなどのLLMモデルとの連動が可能です。
- チャンクされた文書を3rd Partyモデルホスティングシステムに渡すと、拡張された文書がベクトル化され、OpenSearchでエンベデッドしてインデックス化されます。
- 検索のためのユーザークエリが実行されると、インデックス作成と同じ過程を経てクエリ値がエンベッディングが生成され、エンベッディング値に基づいてKNN指数を評価し、検索結果を導き出して配信します。

OpenSearch を Vector Store として使用することで得た教訓
- すべてのインフラを自動的に構築することができ、インデックス管理、検索、バックアップなどの機能を簡単に活用することができます。
- しかし、Vectorを基盤とする検索は、誤った推論による検索品質の低下が発生する可能性があるため、Hybrid Query機能の適切な活用が必要です。
- Hybrid Query機能は、Sementic検索方法とLexical検索方法を並行して活用する方法です。
- 各手法には長所と短所があり、状況や環境によって異なる性能を発揮することができるので、各手法の重み付けを調整することで検索性能を向上させる努力が必要です。

OpenSearchの今後の発展方向性に対する提言
- 現在、特定の圧縮方式に対する圧縮率程度の調整しかできないため、様々な形態の圧縮方式を選択することができず、設定が難しい側面があるため、様々な圧縮方式をサポートすれば、検索効率を高めるための様々な試みが可能になると思われます。
- ベクトル検索時、全体次元に対するアプローチにより、メモリを非効率的に使用しなければならない状況であるため、サブセットを構成して検索する機能を提供することで、メモリ効率及び検索性能を向上させることができると期待しています。
- OpenSearch Open source project内に存在するModel-serving Frameworkを導入することで、ユーザー定義モデルをアップロードして使用できるようにすることで、各ユーザー環境に合わせて性能向上ができるように支援が必要です。
セッションを終えて
OpenSearchがGenAIを活用したLLMモデル活用の中心で、ベクトルDBおよびRAGとしての活用度が高まっている状況で、各環境に応じた性能向上技法と限界点などについて確認することができました。
現在も継続的に進化しているサービスであるため、ユーザーとしてその進化の方向と内容に貢献するために積極的な使用とフィードバックが重要であることを知ることができ、このようなintercativeな参加が最終的に業務遂行時の効果及び効率向上に役立つと期待されます。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner