MEGAZONEブログ

Improve your search with vector capabilities in OpenSearch Service
OpenSearch Serviceのベクトル機能で検索を改善
Pulisher : Managed & Support Center ビンナリ
Description:Amazon OpenSearch Serviceの利点とデータ処理方法、ベクターデータベースとして使用する方法についての紹介セッション
はじめに
OpenSearchサービスは、大量のログや様々なデータを効果的に分析するのに便利なサービスです。私は主に運用業務を行っているので、このような便利なツールを効果的に活用する方法を知りたいと思い、このセッションに参加しました。
セッションの概要紹介
このセッションでは、Amazon OpenSearch Serviceの利点、データ処理方法、ベクターデータベースとして使用する方法、OpenSearch Serviceを使用してユーザーが最も関連性の高い結果を得るのに役立つ方法などを紹介します。

Amazon OpenSearchサービスは、大量のデータを効果的に活用するためのインテリジェントな検索エンジンおよびログ分析ソリューションです。
OpenSearchサービスを通じて、次のような主な機能と利点を得ることができます。
1.データのインデックス作成と他データ検索
2.安全かつ効率的な分析
3.迅速なデータ統合
4.コストの最適化
5.簡単な展開オプション
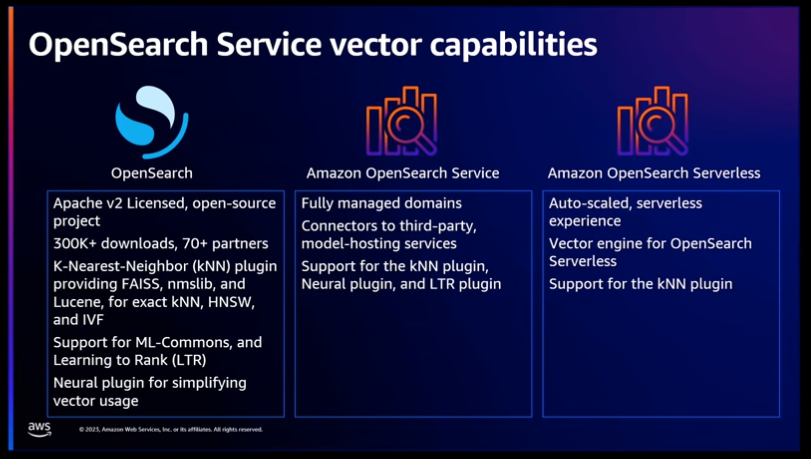
OpenSearchはApache v2ライセンスに準拠したオープンソースプロジェクトで、ML-CommonsとLearning to Rank (LTR)をサポートし、Neuralプラグインでベクトルの使用を簡素化します。
Amazon OpenSearchサービスは、完全に管理されたドメインを提供し、サードパーティのホスティングサービスに接続するためのツールも提供しています。また、Amazon OpenSearch Serverlessは、バクタエンジンを活用することで、サーバー管理なしでGenerative AIアプリケーションなどを構築するのに役立つ高性能バクタストレージと検索機能が利用可能です。

OpenSearchサービスは、LLM言語モデルを活用して検索の関連性を向上させ、この情報をベクトルとして保存することで、さまざまな種類のデータを一緒に使用し、さまざまな方法で検索できるように支援します。 さらに、生成型AIアプリケーションでプロンプトエンジニアリングをより効果的に実行するのに役立ちます。
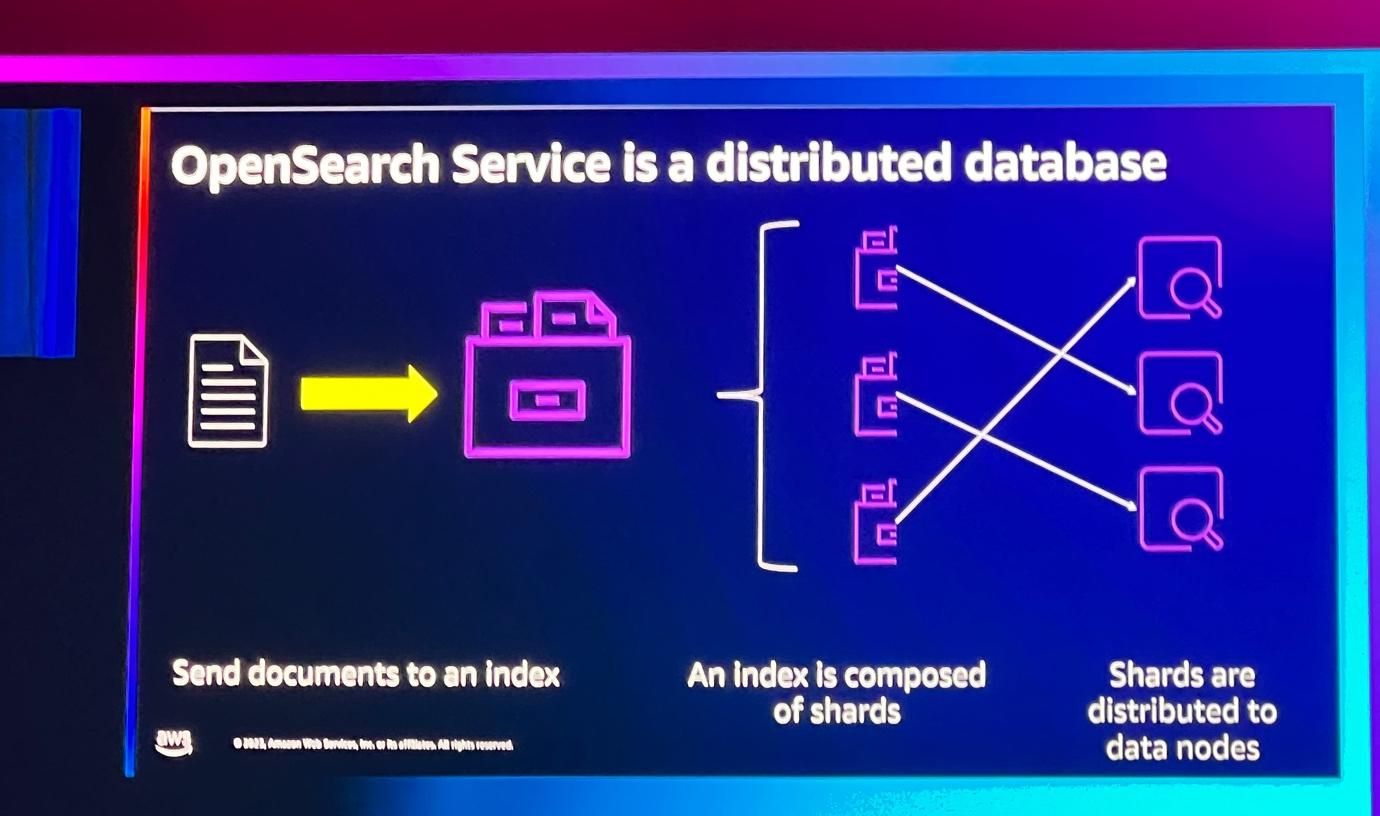
OpenSearchはRESTAPI基盤でJSON文書を通じてデータを伝達して処理します。クライアントはインデックス化するためにJSON文書をOpenSearchに送信すると、その文書のすべてのフィールドを検索可能にしてくれるコア構造であるインデックスに送ります。インデックスは複数のシャードで構成されており、シャードはデータをパーティション化して分散保存する役割をします。
OpenSearchはデータノードにシャードをランダムに分散させ、可用性のためにレプリカなどを設定し、オリジナルとレプリカが同じインスタンスに位置しないようにし、クラスターでデータが失われた場合、復旧可能にします。 このようにすることで、OpenSearchはREST APIを通じてJSON文書を処理し、インデックス、シャード、データノードなどの構造を活用してデータを効率的に保存し、管理します。

OpenSearchでは検索インデックスの処理にLuceneが重要な役割を果たします。
Luceneはリリースされてから20年以上経った検索および情報検索のためのJavaライブラリです。
OpenSearchはこのLuceneライブラリをベースにして分散レイヤーを提供しています。
Luceneはテキスト検索とインデックス化に特に強力であり、OpenSearchはこれにより様々な検索とデータ管理作業を行い、Luceneを通じて効率的で迅速な検索とデータ処理が可能です。

OpenSearchのクエリ実行プロセスは以下の通りです。
まず、ユーザーのクエリテキストが分析され、検索可能な形に変換されます。
分析されたクエリ用語は逆インデックスで照会され、クエリロジックが適用されます。照会された結果は最終的にスコアを付けてソートされて返されますが、この時、クエリの性能は一致する結果の数によって決定されます。このような効率的なクエリ処理により、OpenSearchはユーザーに正確で迅速な検索結果を提供します。

OpensearchのVector(ベクトル)は浮動小数点値の配列で、テキストを数学的に表現する方法です。LLMにテキストを入力すると、その結果、配列形式の数値であるベクトルが得られます。 このベクトルは、そのテキストを特定の値の集まりとして表します。Opensearchでは、このベクトルを利用して検索や類似度測定を行います。
例えば、テキスト間の類似度を測定する場合、様々な方法(例えば、距離測定など)を使ってベクトル間の関係を把握します。
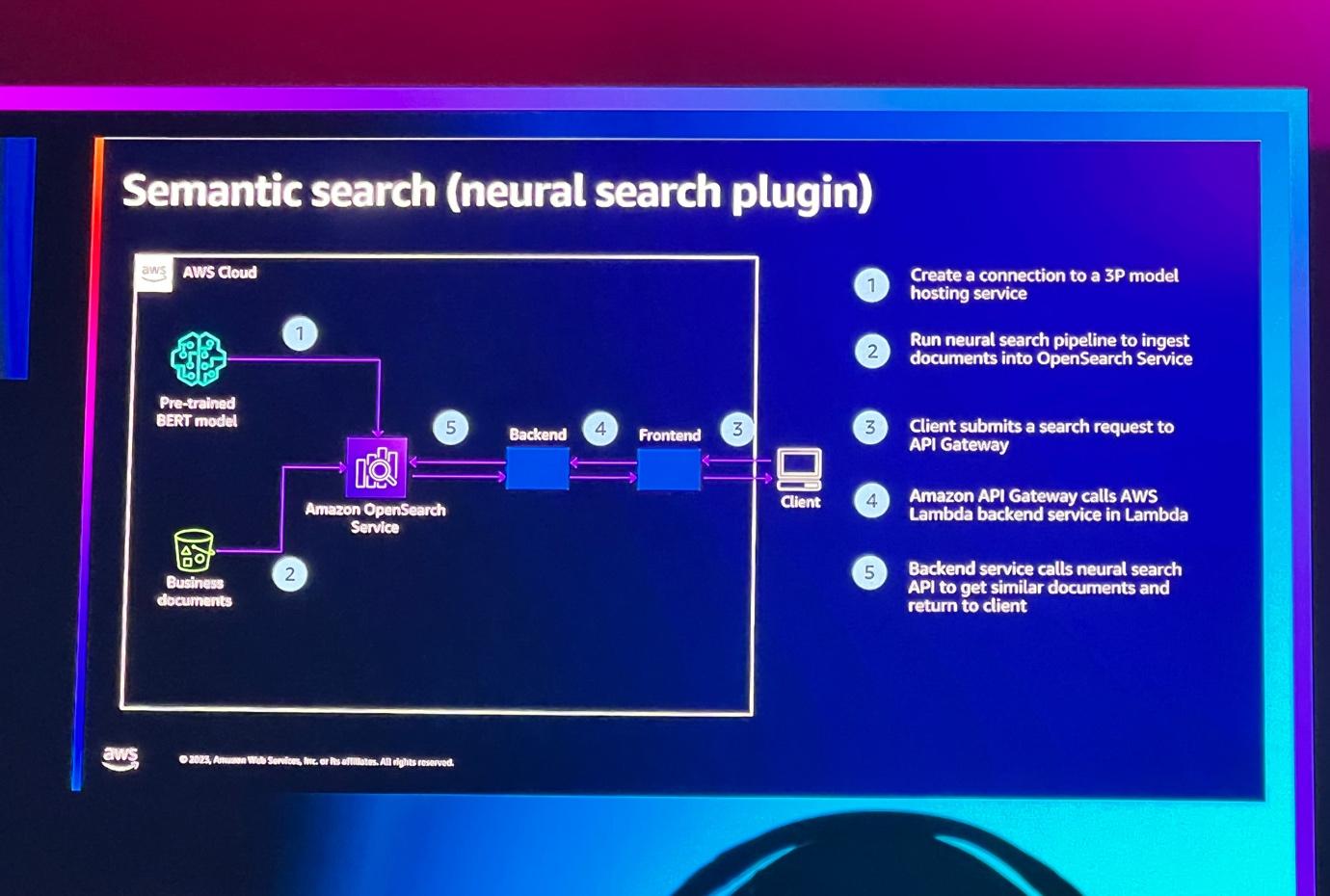
Neural pluginは、テキストデータをインポートして3rdコネクタに送信し、その後、埋め込みをOpenSearchにインポートするプロセスを簡単にします。例えば、SageMakerにある事前訓練されたモデルとOpenSearch Serviceのコネクタを活用します。ビジネスドキュメントをOpenSearchに送信すると、OpenSearchがSageMakerへの呼び出しを自動化して結果ベクトルを取得します。 ユーザーはその後、フロントエンドでクエリを実行して結果を確認することができます。
セッションを終えて
このセッションを通じて、Amazon OpenSearch Serviceの様々な機能と活用方法について理解することができました。 特に、テキストデータの効率的な処理とベクトル活用による関連性の向上についての内容が興味深かったです。OpenSearchの様々な機能を活用しながら、より効果的なデータ検索と管理が可能になると期待しています。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner