MEGAZONEブログ

Accelerate generative AI and ML workloads with AWS storage
AWSストレージでジェネレーティブAIとMLのワークロードを加速する
Pulisher : Cloud Technology Center ペク・ソジョン
Description:StorageをAI/MLワークロードに合わせて最適化する方法について紹介するセッション
はじめに
最近、AI/ML、そしてGenAIが話題として急浮上しています。それに伴い、私も関連技術について少しずつ興味を持って調べているのですが、AI/MLもデータに基づいてモデルを訓練する必要があり、このようなデータをロードするストレージをAI/MLワークロードに合わせてどのように最適化できるのかが気になり、このセッションを申し込みました。
セッションの概要紹介
Overview

今回のセッションでは、MLに焦点を当てて、MLワークロードのためのストレージの選択とチューニングについて説明します。GenAIアプリケーションを構築するためには、どのようにデータを保存し、ストレージを管理するかについて多くの検討が必要です。MLモデルは膨大な量のデータで訓練され、ストレージには当然、大量のデータがロードされる必要があるからです。
The Role of Storage in ML
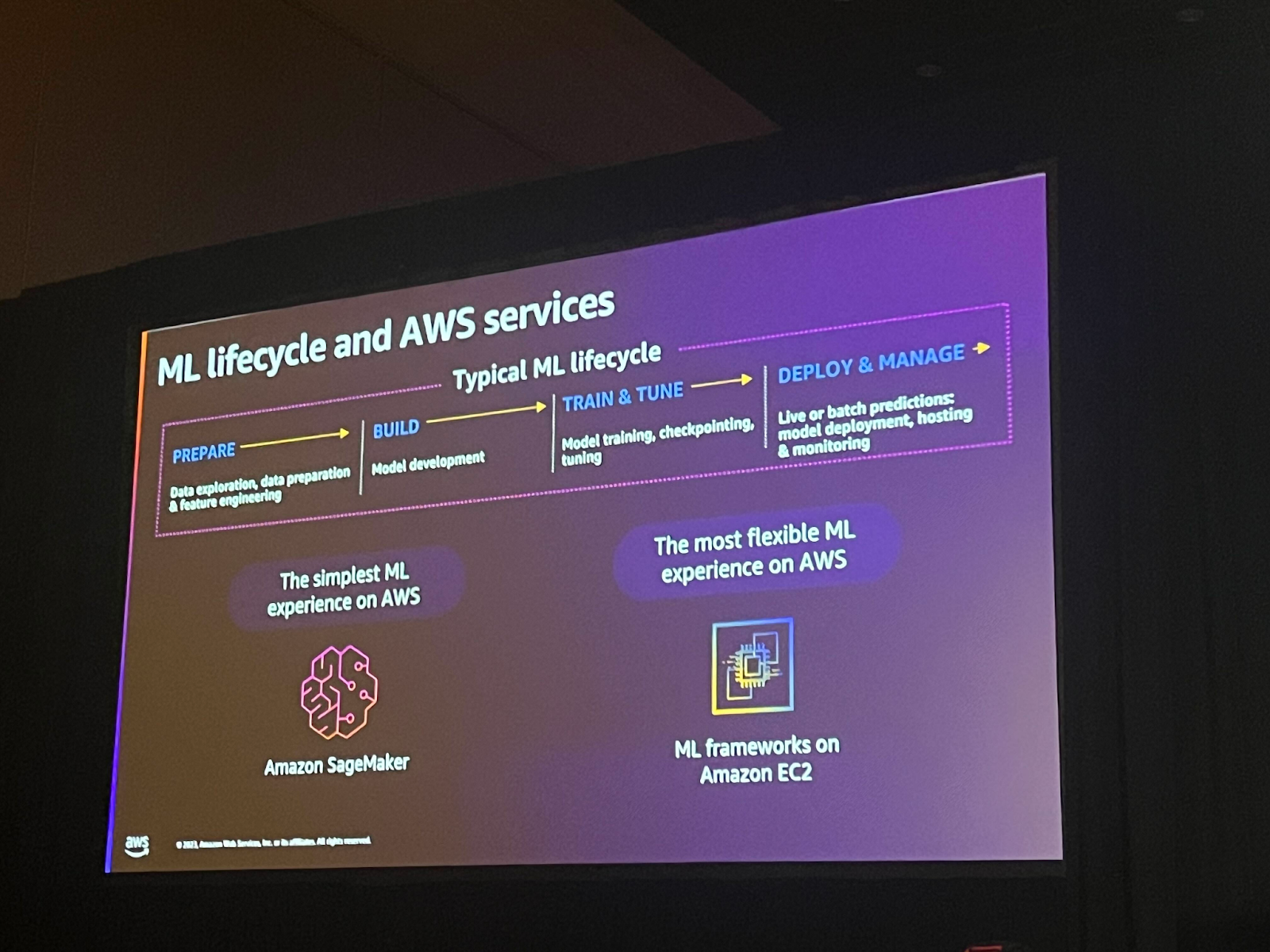
ML lifecycleはMLプロジェクトを進めるプロセスを説明します。一般的に以下の4つの段階を含みます。
1.Prepare:必要なデータを収集、精製などを通じて、モデル学習に必要な形式にデータを加工します。
2.Build:機械学習モデルを構築する段階で、選択したアルゴリズムとモデル構造を使用して初期モデルを生成します。
3.Train & Tune: 構築したモデルをトレーニングデータで学習させ、検証データを使用してモデルの性能を評価し、チューニングする。
4.Deploy&Manage:訓練されたモデルを実際の環境に展開した後、モデルの性能をモニタリングし、最適化します。

SageMakerはフルマネージドサービスで、インフラストラクチャを管理することなくモデルを学習させることができるサービスです。SageMakerはストレージからデータを取り込んでモデルを訓練し、結果を保存する過程もサポートしてくれますが、柔軟性が多少落ちる可能性があります。柔軟にcustomizeをしたいなら、EC2上でML frameworkを使うこともできます。

大きなデータを使用するほど、データの読み込み性能に影響する要因を理解することが重要です。
1.データセットサイズとファイル数: 大規模なデータセットや多数のファイルは、処理時間を増加させる可能性があり、これにより読み込みが遅くなる可能性があります。
2.個々のファイルのサイズと種類:大きなファイルは転送と処理時間を増加させる可能性があり、ファイルの種類はデータ処理方法によって影響を与える可能性があります。
3.データロード方式: バッチ処理やリアルタイムデータロードのような方式によって性能が異なる場合があり、並列処理や分散ロードがデータロード性能の向上に役立ちます。
4.アクセスパターン: 読み取りまたは書き込み作業が頻繁に行われたり、特定の部分に集中している場合、パフォーマンスに影響を与える可能性があります。
Amazon FSx for Luste

これまでオンプレミスでファイルシステムを使用していて、それをクラウドにlift&shiftで移行する必要がある場合は、SageMakerを使用してモデルをトレーニングする際のデータソースとしてAmazon FSx for Lusterを使用することをお勧めします。 Amazon FSx for Lusterは高性能の完全管理型ファイルシステムで、機械学習ワークロードに最適です。
MLワークロードに使用するメリットは以下の通りです:
・あらゆるMLアプリケーションと互換性がある
・スケーラブルで高速なデータアクセスが可能
・コスト最適化されたオプションがあり、サーバーのサイズを選択し、サイズに応じてサーバーがデータを読み書きする方法を選択できます。
Amazon S3

S3は高い耐久性と速度を誇るオブジェクトストレージで、S3もMLストレージとして使用することができます。S3をMLストレージとして使用した場合のメリットとしては、高速性、拡張性、利便性があります。 また、S3には様々なクラスが用意されており、データの使用パターンに合わせて保存することができます。

モデルトレーニング作業に必要なS3内のデータをSageMakerにロードする際に使用できるモードは2つあります。Fast file modeを使用すると、S3内のデータをストリーミングして取り込むことができます。File modeはデータロード時に選択されるdefaultモードです。

今回のリインベントでS3の新しいクラスが発表されましたが、このクラスは高スループットと低遅延でコンピューティングリソース集約的なワークロードに使用するのに適しています。
秒単位で多くのトランザクションを処理する必要がある場合は、拡張性が重要なので、S3 directory bucketを使用すると良いでしょう。 これは一般的に使われるバケットタイプとは異なり、S3 Express One Zoneクラスでのみ使用できるバケットタイプです。General purpose bucketとは違ってデータを階層構造で保存し、接頭辞の制限がないため、拡張性と性能がより優れています。
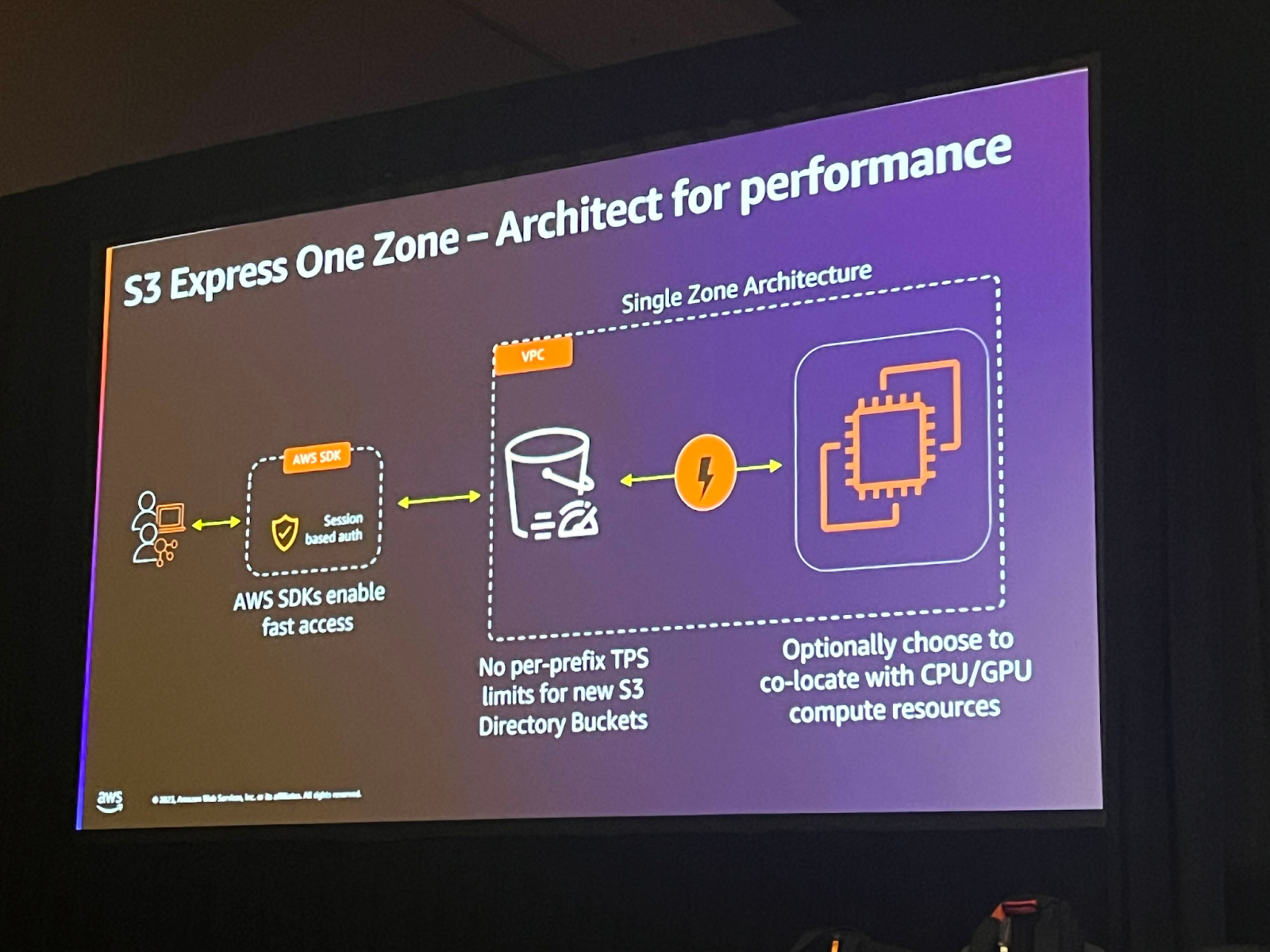
このクラスを使用する場合、コンピューティングと頻繁にアクセスするデータを保存するストレージを同じ利用可能領域に位置させ、レイテンシーを下げることができます。既存のオブジェクトをdirectory bucketに移動するには、importボタンをクリックして簡単にオブジェクトをコピーすることができます。

MLワークロードを最適化するには、やはりスループットと速度が重要です。

このような部分に役立つ新機能がさらに追加されました。
Amazon S3 Connector for PyTorch: S3でデータに効率的にアクセスして保存できるようにPyTorchのトレーニング作業を改善しました。
Mountpoint for Amazon S3: ファイルシステム操作でAmazon S3 Express One Zoneクラスに保存されたオブジェクトにアクセスできるようになりました。
Mountpoint for Amazon S3 with local cache: よくアクセスするデータをローカルでキャッシュして読み込むことができます。
セッションを終えて
このセッションを通じてAI/MLのためのストレージタイプと最適化方法について知ることができました。 関連して新しい機能がたくさん紹介されたので、近いうちに実際にテストしてみたいと思います。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner