MEGAZONEブログ

Netflix’s journey to an Apache Iceberg-only data lake
ネットフリックスのApache Iceberg専用データレイクへの道のり
Pulisher : AI & Data Analytics Center チョ・ミレ
Description:Netflixのファイルシステム管理方法の紹介セッション
はじめに
業務で最近DataLakeを構築開発する作業をしましたが、updateロジックが適用されるべき業務領域がありました。 icebergの議論もありましたが、別の開発イシューのため導入はしませんでした。 OTTコンテンツを主導しているNetflixでは、ファイルシステム管理をどのように行っているのか確認するために申請しました。
セッションの概要紹介
Netflixがどのようにカスタマイズされたツールでこのタスクを適切な規模で管理し、安全なIcebergテーブルやIceberg RESTカタログなどの独自の社内機能を開発したかをご紹介します。HiveベースのデータウェアハウスからIceberg専用データウェアハウスに移行するまでのNetflixの道のりと、その移行過程で発生した問題をどのように克服したかをご紹介します。
既存のHive型DataLakeからApach Icebergへの移行

Netflixは約1エクサバイトのデータレイクを運用していましたが、データの一部 (約300ペタバイト) は従来のApache Hiveのテーブル形式のままでした。タイムトラベルやスキーマの進化など、Apache Icebergが提供するよく知られた利点に触発され、NetflixはHiveを完全に段階的に廃止し、既存のデータをIcebergに移行しました。
Iceberg ecosystem

・テーブルマネージャ – Janitors : スナップショットの期限切れ、ファイル削除などの作業を処理し、メタデータの一貫性を確保します。
・Auto-Tune : Icebergテーブルでユーザー操作によってトリガーされるイベントを受信し、リソースと構成を効率的に調整します。
Rest catalog service – Advantage

・RESTカタログは、Icebergテーブルの基本的な詳細を抽象化することで、ユーザーインタラクションを簡素化し、データ操作の全体的な効率を向上させます。
・RESTカタログを追加すると、標準化されたインターフェースが導入され、メタデータ操作の一貫した管理が保証されます。
効率的なテーブルのマネジメントサービス – Janiots

・JanitorサービスはIcebergテーブルの管理を担当し、効率的な運営とメンテナンスを保証します。
・スナップショットの期限切れ : Icebergテーブルと関連性のないスナップショットの期限切れを処理し、効率的なデータ管理とリソースの最適化に貢献します。
テーブルの効率的な管理者サービス – Autolift

・スキーマの更新を効率的に処理し、進化するデータ構造を大規模に管理するための強力なソリューションを提供することで、Icebergのスケーラビリティを向上させます。
・動的スキーマ切り替え:Sparkプロセスを活用してスキーマの更新に動的に適応し、進化するデータ構造とのシームレスな統合を保証します。
iceberg テーブルの安定性
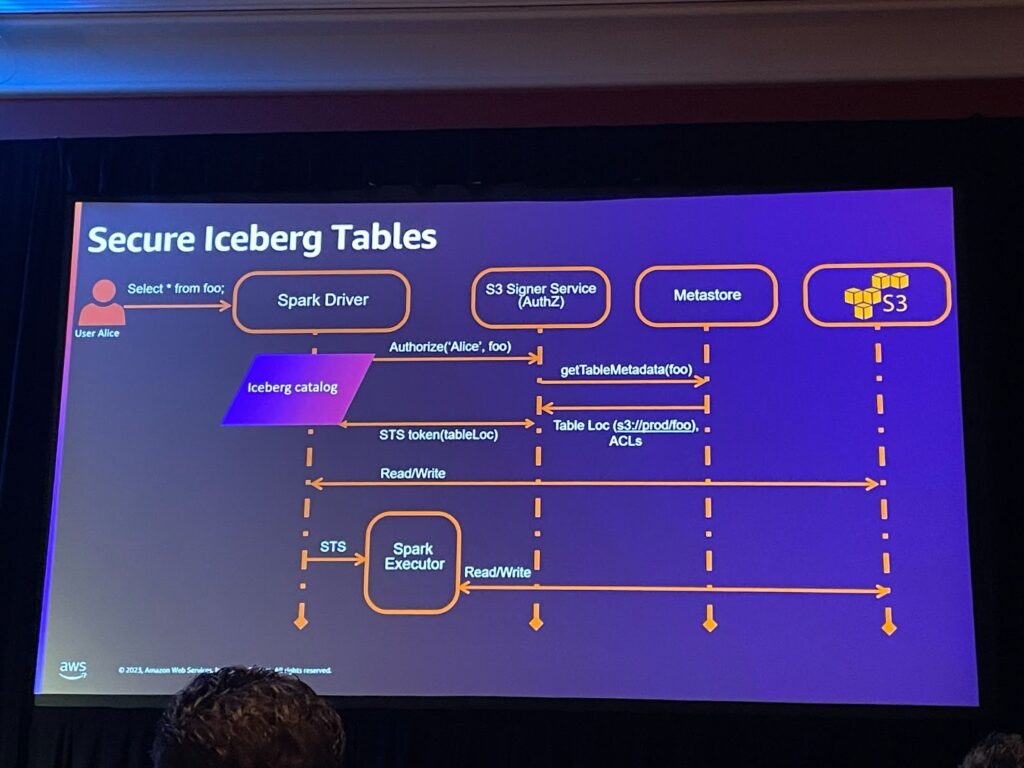
- ユーザーにIcebergテーブルの読み取り、書き込み、または管理権限が付与され、セキュリティを強化するためにデータへの制御されたアクセスを維持します。
Hive to Icebergへの移行に貢献します

・マイグレーションを容易にし、データの移動とユーザーの摩擦を最小化する。
・Delta Copying Mechanism:Icebergのメタデータ階層を利用して、元のHiveテーブルを新しいIcebergテーブルと同期し、挿入と削除を通じて履歴データを保存する。
セッションを終えて
Hiveに対するIcebergの強みについて確認することができました。実際、Hiveに対する概念や活用力がまだ未熟で、直接その違いを実習して確認するにはもう少し勉強が必要な部分だと感じました。足りない部分を補充した後、icebergを活用するかどうかを早急に検討する予定です。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner