MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #STG208|Data on AWS: 3社のAI Innovatorの成功の鍵
Data on AWS: The key to success for 3 AI innovators
セッション概要
- タイトル:Data on AWS: The key to success for 3 AI innovators
- 日付:2024年12月2日(月)
- Venue:Wynn | Convention Promenade | Latour 2
- スピーカー:
- Nova DasSarma(Member of Technical Staff, Anthropic, PBC)
- Andrew Kutsy(Product Manager、Amazon)
- Josh Smith (Engineering Manager, Canva)
- Bar Fingerman(Head of Engineering, Bria AI)
- 業種:Cross-Industry Solutions
- 概要:組織はデータを使用して意思決定を行う方法を革新しています。このカスタマーセッションで、Anthropic、Bria AI、CanvaがAWSで生成されたAIモデルをトレーニングするためのスケーラブルで費用対効果の高いデータファンデーションを構築および管理する方法を学びます。高レベルの集約スループットを拡張し、大規模なデータエステートでメタデータカタログを管理し、AIで生成されたコンテンツを責任を持って保存するためのパフォーマンスを最適化するアーキテクチャアプローチ、デザインパターン、およびベストプラクティスをご覧ください。コンテナ化されたアプリケーションとデータ環境を統合し、大規模にデータを準備し、データローディングとチェックポイント技術を使用し、生成AIを責任を持って構築する方法についてのインサイトを得てください。
はじめに
今回のセッションでは、最近多くの企業が解決しようとしている3つの主なトピックについて学びました。
データの品質と膨大なデータから希望の高品質データセットを選別する方法、ストレージ性能を最大化してコンピューティングのメリットを最大限に活用する方法、最後に大規模ストレージを構成する際に長期的な観点から弾力的に拡張できるようにする方法について見てみましょう。
データキュレーション
さまざまなデータソースから膨大な量のデータが収集されている最近の鍵は、このデータをどのように扱うかです。ほとんどの場合、ビジネス上の結論を出すためにこれらのデータはすべて必要ありません。特定の分野に答えるためには、特定の分野に関するデータのみが必要です。この部分では、Data Curationの概念が出てきます。データキュレーションとは、特定の目的のためにデータを洗練して整理することです。

このようなCurationが重要な理由はまたあります。データが収集されることから実際に使用され、どんな結果が出るまでのエンドツーエンドピペラインを考えてみると、データが私が望む目的に合うように整えられていなければ、必要なデータを見つけるためにボトルネック現象が発生することになります。その結果、GPU時間単位でコストが発生する次のプロセスには意味のないアイドル時間が追加され、すぐに意味のないリソースの使用につながります。全体のプロセスが遅くなることはもちろん、追加のコストまで発生します。
Canvaの事例
Canvaはグラフィックデザインプラットフォームで、ユーザーが自分のデータで簡単にデザインコンテンツを作成できるようにするツールです。ユーザーのデータを使用できるため、常に企業が望むデータだけを利用するわけではありません。ポリシーに合わないデータを使用することができ、Canvaではこれを防ぐ方法を見つける必要がありました。

だからContent Moderationを導入しました。 Canvaにアップロードされるすべてのコンテンツは、次のアーキテクチャに従って処理されるようになっています。 Amazon RekognitionとModelを活用して、コンテンツが安全であるか、そうでないか、またはHuman checkが必要かどうかを確認します。

さらに、Perceptual hashを使用して類似コンテンツを検出し、特定の問題が発生した場合は、同様のコンテンツを一緒に見つけて対処できます。
Bria AIの事例
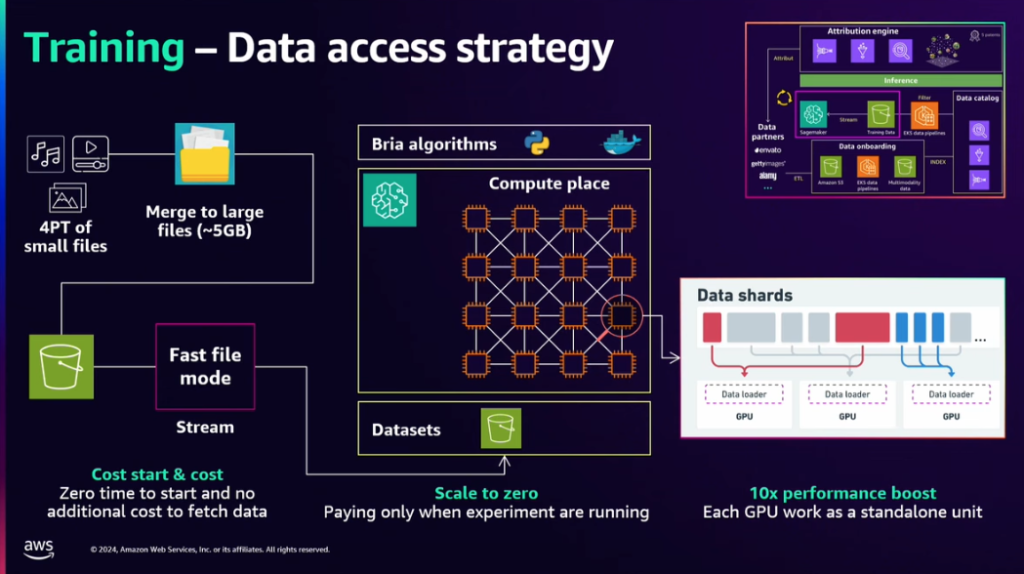
Briaは、モデルを訓練するために、次のアーキテクチャとビジネスモデルを活用してサービスを運営しています。
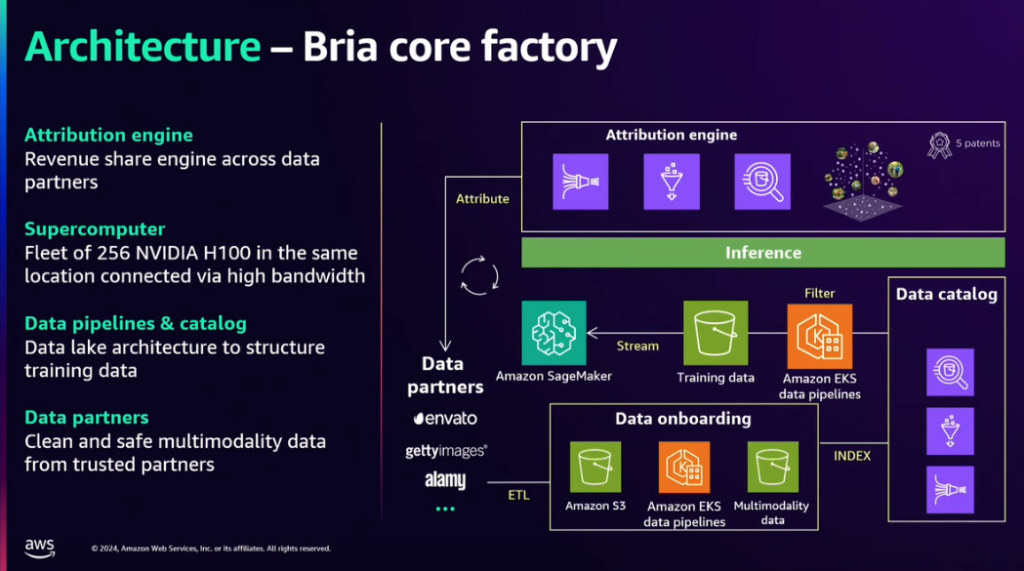
1) Data Onboarding
データパートナーから提供されたデータを、ETL 過程を通じて Amazon S3、EKS data pipelines などに収集、積載します。
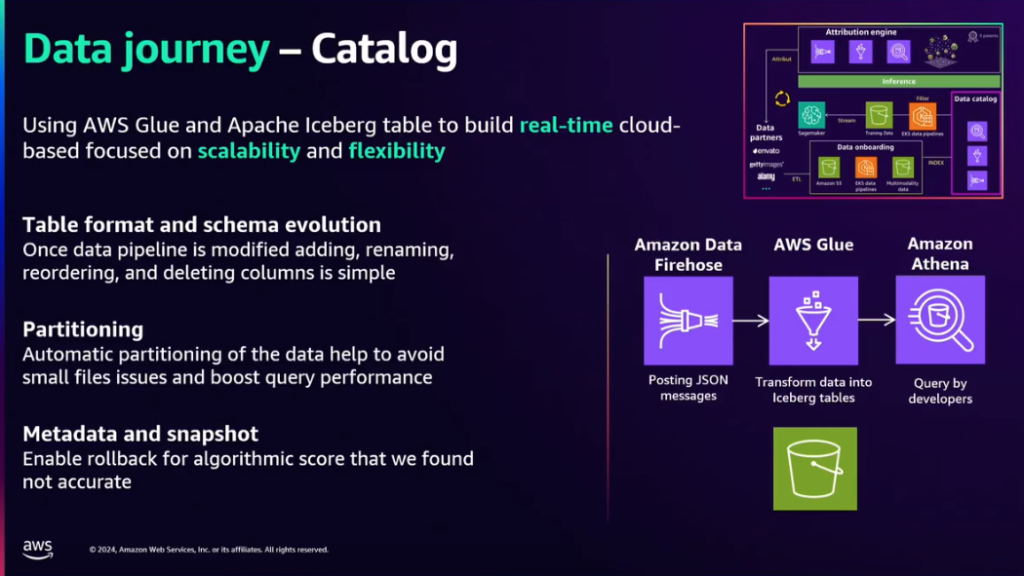
2) Data Catalog ロードされた
データは、Data Catalog に索引付けされて追加され、これはその後のモデルトレーニングデータとして活用されます。
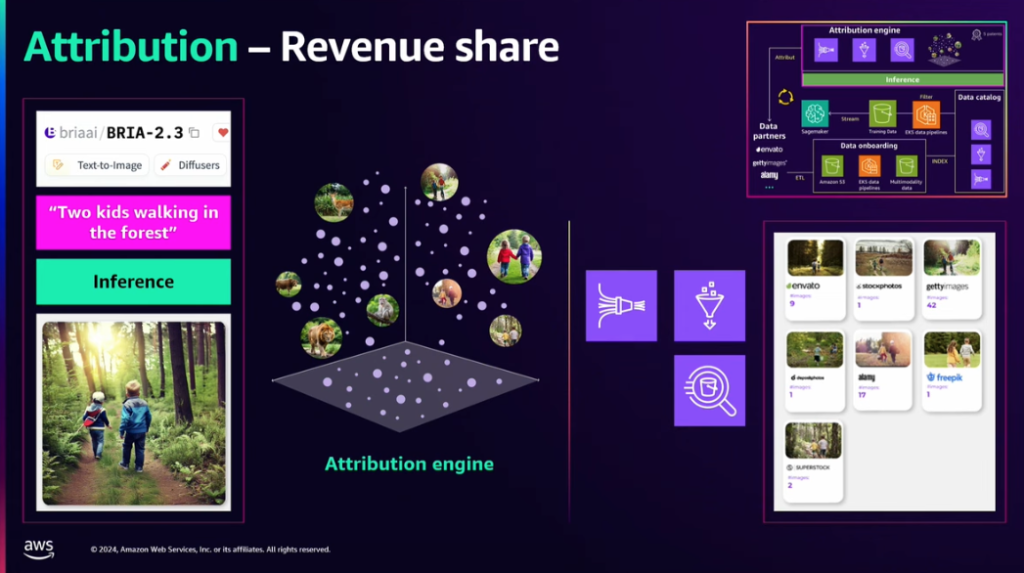
3)モデルがInferenceになると、Attribution Engineで利用された画像を追跡し、そのデータを提供したパートナーに適切な収益を配分します。
Anthropicの事例
Anthropicは、過去に比べてはるかに大量のデータをはるかに高速に処理しています。どのようにデータを処理しているかを見てみましょう。

Anthropicは、基本的にS3のさまざまなサービスを通じて弾力的なストレージを構築しています。
高性能タスク、特にshuffleを多用するタスクでは、S3 Express One Zoneを活用します。このサービスは、Hadoop、EBSなどの他のファイルシステムに代わるもので、必要に応じてIOPSを処理できるようにします。
多くの帯域幅を必要とするタスクでは、クロスバケット複写を利用します。これにより、データをコンピューティングリソースと同じ場所に保存できますが、そこで処理する必要はありません。
最後に、S3 Intelligent-Tieringを使って一度モデルトレーニングに使用すると、再使用されない90%のデータを自動的にデータを階層化してコストを削減します。

まとめ
別々のモデルとパイプラインを構成し、サービスに適したデータのみを取り除くCanva、必要なデータのみパートナーから提供され、収益を共有するBria AI、S3ストレージを積極的に活用し、階層的な分類を通じてCurationを行うAntropicの事例まで見ました。実際に生成型AI関連業務を進めてみると、Data Curationが反映されず、意味のないデータが含まれるなど、さまざまな問題を経験することができますが、このようなさまざまなケースを通じてData Curationが何を意味し、どのように達成できるのか適切なインサイトを発掘できると思われます。
記事 │MEGAZONECLOUD, AI & Data Analytics Center (ADC), Data Engineering 2 Team、チョン・ジソン マネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び