MEGAZONEブログ

re:Invet2023 Day2 Adam Selipsky 基調講演
Adam Selipsky Keynote
Pulisher : MEGAZONECLOUD Tech Team Description : re:Invet2023 Day2 基調講演レポート
Keynoteレポートをはじめるにあたって
AWSのCEOであるAdam Selipskyが伝えるメイン基調講演である2日目の基調講演は、AWSが今年新規に進める事業に対するインサイトが含まれている基調講演と言っても過言ではありません。
今回のキーノートは生成型AIだけにフォーカスしたキーノートではないかと思うほど、生成型AIに関する多くの新機能、アップデートが発表されました。今年度AWSが注目している生成型AIを活用したサービスのうち、主な内容を抜粋して本レポートでお伝えします。
Amazon S3 Express One Zone


AWSで最も古いサービスであるS3は、最も安価で多くの用途に使用できる魅力的なサービスです。 そのため、多くのお客様の多くのワークロードにS3は欠かせない機能の一つです。
最も単純なストレージ用途からウェブホスティング、EC2、ECS、EKSなどアプリケーション内部のログを抽出して保存する用途まで多くの場所で使用するのがS3機能です。
今回紹介されたAmazon S3 Express One Zoneはコンピューティングとストレージ間の遅延に対して数ミリ秒の遅延時間を保証し、最も頻繁に使用されるデータが位置するストレージとして使用するのに適した最新のS3ストレージクラスです。
既存のS3 Standardに比べて最大10倍良い読み取り/書き込み性能を提供するにもかかわらず、リクエスト費用は50%安いため、頻繁に読み込まれるデータに対する活用度が高いと思われますが、まだ保存費用に関する詳しい情報は出ていないので、費用構造は全体的な確認が必要と思われます。
以前はS3にデータを保存する時、特定のAWSのRegionだけを選択することができましたが、S3 Express One Zoneを使うと、特定のAWSのRegionで特定の利用可能領域だけを選択してデータを保存することができます。コンピューティングリソースとそのS3を同じ可用性領域に配置してサービスをすることで、もっと良い性能と一緒に従来よりコンピューティング費用を少なく使うことができると思います。
また、Amazon S3 Express One Zoneは、機械学習(ML)教育及び推論、対話型分析及びメディアコンテンツ制作のような要求集約的な作業のための最も性能が優れたストレージクラスであるため、産業群の中で大量のデータを迅速に処理しなければならないデータ分析分野でのワークロードにおいて、より利点を享受することができると期待されます。Amazon S3 Express One Zoneは、現在使用しているAmazon S3 APIで作業することができます。
AWS Graviton 4


今回のGraviton4は、従来のGraviton3に比べてデータベースは最大40%、Webアプリケーションは30%、大規模javaアプリケーションは45%高速化されました。
また、最大30%向上したコンピューティング性能、50%より多くのコア、75%より多くのメモリ帯域幅を提供し、Amazon EC2で実行される幅広いワークロードに最高の価格対性能比とエネルギー効率を提供します。
Graviton4はAmazon EC2 R8gインスタンスで利用可能で、R8gインスタンスは、現世代のR7gインスタンスよりも最大3倍以上のvCPUと3倍以上のメモリで、より大きなインスタンスサイズを提供します。
これにより、お客様はより多くのデータを処理し、ワークロードを拡張し、結果までの時間を短縮し、総所有コストを削減することができます。
Graviton4は、次のような幅広いワークロードに適しています。
・データベース:Amazon Aurora, Amazon RDS, Amazon Redshift, Amazon DynamoDB
・アナリティクス:Amazon Redshift、Amazon Athena、Amazon QuickSight
・ウェブサーバー:Amazon Elastic Beanstalk、Amazon EC2
・バッチ処理: Amazon EMR, Amazon Batch
・広告配信:Amazon Advertising、Amazon Pinpoint
・アプリケーションサーバー:Amazon Elastic Beanstalk、Amazon EC2
・マイクロサービス:Amazon Elastic Container Service(ECS), Amazon Elastic Kubernetes Service(EKS)
Graviton系列は現在運用されている環境に適用するには時間がかかりますが、AI/MLなど高スペックのサーバーを必要とするサービスが台頭し、それに伴いGravitonタイプへの関心が高まっていると思われます。
移行におけるメリットと特異点を確認し、今後は多数の環境に適用するとよいと思います。
Graviton4ベースのR8gインスタンスは現在プレビューとして提供されており、今後数ヶ月以内に一般リリースされる予定です。
AWS Trainium2

顧客はますます大きなモデルをトレーニングしており、この状況を反映するためにAIおよびMLトレーニング用の新しいAWS Trainium 2チップがリリースされました。
今回のリリースバージョンは、数千億~数兆個のパラメータを使用するFM教育に最適化されており、従来のAWS Trainiumより約4倍高速です。
Amazon独自のTrainium2チップは、OpenAIのChatGPTのようなAIチャットボットが実行するようなAIモデルのトレーニングにも適しています。
Trainium2は以下のような幅広いワークロードにおすすめです。
・機械学習:自然言語処理(NLP)、コンピュータビジョン(CV)、推薦システム
・生成型AI:テキスト生成、画像生成、動画生成。
Amazon Bedrock 3つの新機能

今年Bedrockサービスがリリースされましたが、Model Customができないため、活用性に多くの制約がありました。 しかし、今回のリニューアルにより、モデルに対するFine TuningとPre-Train機能を提供し、ユーザーが各ケースに合った独自のモデルとアプリケーションを構築することができるようになりました。
Amazon BedrockのKnowledge Basesを使用すると、Amazon Bedrockの基礎モデル(FM)を企業データに安全に接続し、検索拡張生成(RAG)に使用することができます。追加のデータにアクセスすることで、モデルはFMを継続的に再訓練することなく、より関連性が高く、コンテキストに特化した正確な回答を生成することができます。ナレッジベースから検索されたすべての情報には、透明性を高めるためのソース帰属が付属しています。
Knowledge Basesは、初期ベクターリポジトリの設定を管理し、埋め込みとクエリ処理を処理し、プロダクションRAGアプリケーションに必要なソース帰属と短期記憶を提供します。
必要に応じて、RAGワークフローをカスタマイズして特定のユースケースの要件を満たすことも、RAGを他の生成型人工知能(AI)ツールやアプリケーションと統合することもできます。
データの場所を指定し、データをベクトル埋め込みに変換する埋め込みモデルを選択すると、Amazon Bedrockはアカウントにベクトルデータを保存できるベクトルストアを作成します。
このオプションを選択すると(コンソールでのみ利用可能)、Amazon BedrockがアカウントのAmazon OpenSearch Serverlessにベクターインデックスを作成し、ユーザーが直接管理する必要がなくなります。
Gen AIはユーザーが簡単にAIモデルを開発することが最大の強みであるため、Customモデルを作ることができなければ、事実上Gen AI技術を活用したとは言えません。今回のBedrockの新技術は、このような限界点を十分に補完し、各組織内部に必要なモデルを開発することに大きな助けになることが期待されます。
Guardrails for Amazon Bedrock

この機能は、責任あるAIポリシーを通じてGen AIアプリケーションを簡単に保護するのに役立つ新機能です。ガードレールを作成するために、Bedrockは設定ウィザードを提供し、モデルが避けてほしいトピックに関する自然言語を入力することができます。
ガードレールは、独自の微調整を通じて作成したユーザー定義モデルを含め、Bedrockを通じてアクセスできるすべての基礎モデルと一緒に使用することができ、エージェントと一緒にガードレールを使用することもできます。
例えば、AWS Amazon Bedrockを使用する場合、Guardrailを活用することで、一定以上のセキュリティを確保することができます。お客様では、Bedrockを使用する際に、Guardrailをぜひご利用いただければと思います。
Amazon Q

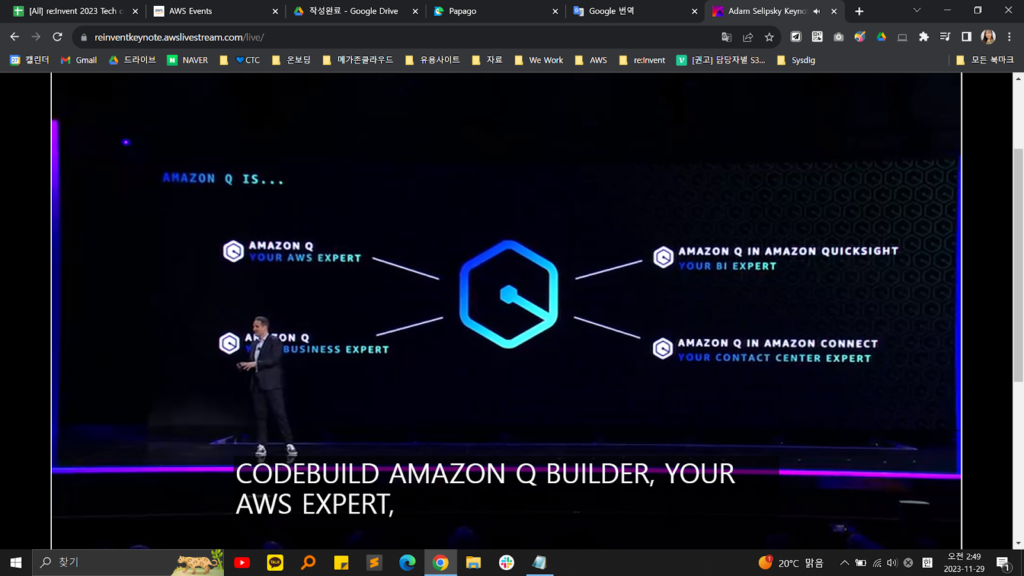
Amazon Qは、ビジネス環境に適した生成型AIベースのアシスタントで、AWSに最適化された生成型AIです。Amazon Qは、ユーザーベースのプランを提供し、製品の使用方法に合わせて機能、価格、オプションを提供し、各ユーザーの既存のアイデンティティ、役割、権限に基づいて相互作用を調整することができます。
また、AWSはAmazon Qの基本モデルのトレーニングにお客様のコンテンツを使用しないため、企業情報を安全に保つことができます。
Qをパーソナライズして作成したり、様々なサービス(Slack、Zendesk、Jiraなど)との接続も可能で、また、すべての組織の人々が使用可能であると同時に、すべてのビジネスに対する質疑応答が可能です。
例えば、マーケティングマネージャーはAmazon Qにプレスリリースをブログポストに変換したり、プレスリリースの要約を作成したり、提供されたリリースに基づいてメールドラフトを作成するよう依頼することができます。
また、社内スタイルガイドなどを含む社内コンテンツを検索し、会社のブランド基準に合ったレスポンスを提供します。 その後、各ソーシャルメディアチャネルでストーリーを宣伝するためのカスタムソーシャルメディアメッセージを作成するようAmazon Qに依頼することもできます。実施したキャンペーンの結果を分析したり、要約を要求することもできます。
Amazon QはAWSに関する基本的な事項について簡単に検討が可能と思われます。セキュリティにおいても、オープンサーチとQを利用し、素早く簡単に可視性の良いグラフを作成するなど、多くの場所で活用できると思います。
また、セキュリティとプライバシーが搭載されたと発表されましたが、最近AIのセキュリティに対するイシューが多いため、企業で使用する場合、既存のChatGPTなど生成型AIとはどのように構成されるのかも今後の確認と検討が必要だと思われます。

また、AWSは業務用生成型AIエージェントAmazon Qのプレビュー機能のうち、Javaアプリケーションコードが使用する依存性のバージョンを更新する機能であるCode Transformationを導入しました。
この機能により、Javaアプリケーションのランタイムバージョンをアップグレードすることができます。
Javaアプリケーションを8から17にアップグレードすると仮定すると、Javaランタイムのバージョンを単純に上げるだけではアプリケーションの動作を保証することができず、依存するパッケージもアップグレードされたプラットフォームで実行できる必要があります。
Amazon Q Code Transformationは既存コードを分析して依存パッケージとリファクタリング可能な非効率的なコードコンポーネントを識別し、ベストプラクティスを適用します。 Amazon Qが生成した変更計画を私たちが受け入れてJavaビルドを実行すると、更新されたアプリケーションが生成されます。
Springフレームワークの観点から見ると、もしAmazon Qが本当にパッケージの依存関係を修正してくれれば、インターネット上で発見される古い古いgradle.buildファイルが吐き出すエラーを苦労して修正する必要がなくなるのではないかと思います。
AWSの内部ユースケースでは、たった2日間で1,000個のJavaアプリケーションのバージョンをアップグレードすることができたそうです。 人が直接パッケージ間の依存構造をたった2日間で把握することはできなかったでしょうが、生成型AIが持つ潜在的な汎用性を確認することができました。

もう一つの機能として、Amazon QuickSightでデータを使って自然言語プロンプトで命令し、データに関するストーリーを作成してもらうことができます。
例えば、特定の商品の年度別売上グラフを見て、マーケティングの方向性を設定してもらうように依頼することを想定してみましょう。
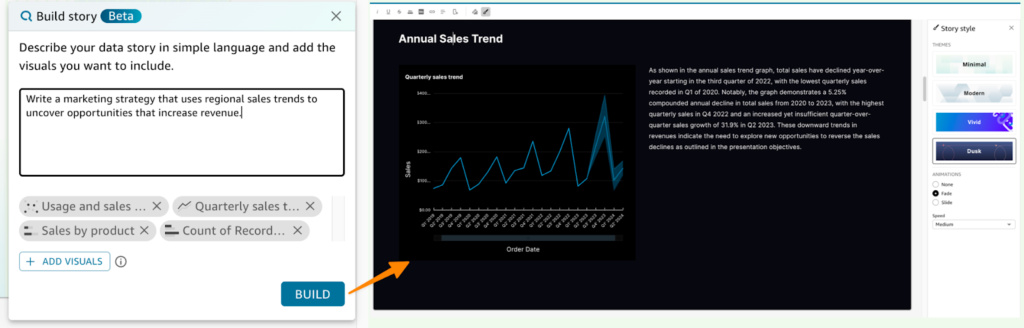
図のようにプロンプトを入力すると、売上グラフ(時系列)の右側にテキストが表示され、年間売上状況を分析したナラティブが表示されます。
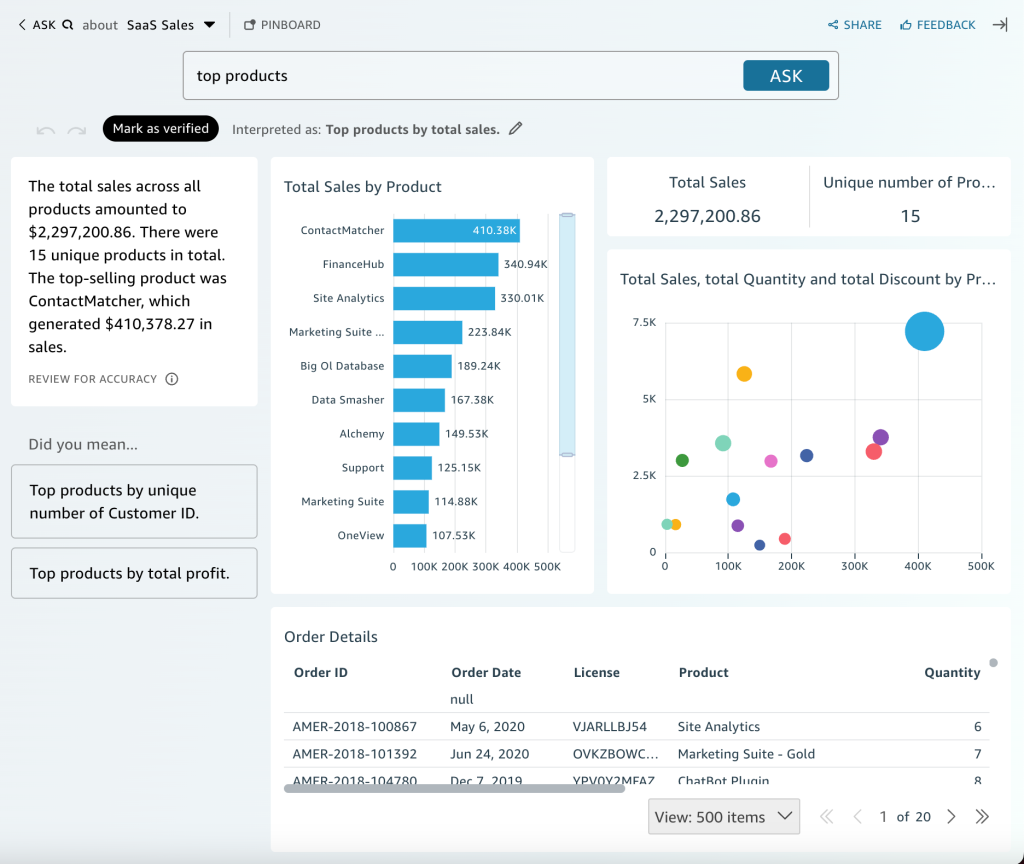
質疑応答機能の場合、top productsを要求したら、商品項目別に売上集計後、降順ソートされ、ダッシュボードが構成されました。
AIが発展し続け、ChatGPTのようなAIの需要が増加するにつれて副作用も多いですが、それは不正確であることと、個人の職業群にAIが同化されず全く違う回答をすることでしたが、Amazon Qはこのような欠点を正確に補完して発売され、個人の専門性や作業効率の向上が期待できそうだと思いました。
Zero-ETL integrations

昨年のリインベントでZero-ETLについての言及がありましたが、この機能はDWとDB間のデータ移動をより簡単にし、ETLプロセスを簡素化してくれます。
データパイプラインでのETLは難易度のある作業ではありませんが、本当に単純な作業の繰り返しでスキーマやカラムが変わることによってコードを変えなければならないという不幸が発生していました。
このような作業は生産効率にも役立たず、データを通じたイノベーションを阻害する要素は明らかです。
従来はRedshiftとAurora Mysql間のintegrationが可能でしたが、今回新たに登場したZero-ETLはAurora postgre、RDS mysql及びDynamo DBが追加されました.。
そしてOpenSearchとDynamo DB間のZero-ETL機能がGAされました。
既存のRDBMSを利用している顧客を対象にRedshiftの分析要件を導入する前よりも難易度が低くなり、多くの顧客が簡単にRedshiftの導入を決定することができると思います。
Keynoteを終えて
Amazon S3 Express Onezoneの場合、どこでも歓迎される機能だと思いますが、最近進行したプロジェクト事例を例に説明すると、SAP on AWSプロジェクトでSAP HANA DBにデータバックアップをAWS Backintというエージェントを通じてEC2からS3にBackupを進行した件がありました。
SAPワークロードの特性上、大きなデータを長期間保存しなければならない部分、そしてデータ整合性及びデータ損失に対して敏感な当該ワークロードに適用すれば、もう少し安全で、もう少し早く、より高いRTOを得ることができると思いました。
また、社内でGen AIプロジェクトを進め、チャットボットサービスを開発する中でBedrockを活用しましたが、モデルのカスタマイズが難しく、性能改善に限界がありました。Bedrockの機能の中で最も惜しい部分が補完されたので、その機能を通じて全体の性能を高め、完成度の高いアウトプットが期待できると思います。
このように生成型AIにフォーカスを当てて、様々な新機能、更新事項をお客様のワークロードや環境に合わせて今後も提案していきたいと思います。
注目の新規サービス
・Amazon S3 Express One Zone
・AWS Graviton 4 (R8g Instances for EC2)
・AWS Trainium2
・Amazon Bedrock (Fine Tuning, Retrieval Augmented Generation with Knowledge Bases, Continued Pre-training for Amazon Titan Text Lite&Express)
・Agents for Amazon Bedrock
・Guardrails for Amazon Bedrock
・Amazon Code Whisperer customization capability
・Amazon Q (Code Transformation, Amazon QuickSight)
・Zero-ETL integrations with Amazon Redshift
・Amazon DynamoDB Zero-ETL integration with Amazon Opensearch Service
・Amazon Data Zone AI recommendations
・Kipher
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner