MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #AIM315|生成型AIを活用したインテリジェント文書処理革新
Transforming intelligent document processing with generative AI
セッション概要
- タイトル:Transforming intelligent document processing with generative AI
- 日付:2024年12月2日(月)
- Venue:MGM Grand | Level 1 |
- スピーカー:
- Chin Rane (Generative AI Specialist SA, Amazon Web Services)
- Issac Ibrahim (Assoc Specialist Solutions Architect AIML, AWS)
- 業界:Cross-Industry Solutions, Financial Services, Healthcare & Life Sciences
- 概要:生成型AIを活用したインテリジェント文書処理(IDP)技術を紹介します。多言語OCR、文書分類、RAGベースのルールマッチングなど、文書処理の自動化のためのさまざまな活用事例を見て、文書中心のビジネスプロセスの効率を高める方法を学びます。
はじめに
企業がデータ中心の意思決定を加速するにつれて、インテリジェント文書処理(IDP:Intelligent Document Processing)の重要性がますます大きくなっています。 AWS IDP ソリューションは、コスト削減、精度の向上、従業員の生産性の向上という重要な目標を達成する上で重要な役割を果たします。
このセッションはワークショップの形で行われ、AWS IDP サービスと Generative AI テクノロジーを活用したドキュメント処理の自動化を中心に構成されました。 Amazon Textract、Amazon Comprehend、BedrockなどのAWSサービスがドキュメント処理パイプラインでどのような役割を果たしているかを体験できました。
最近、当部門でも文書自動化を含むデータ処理プロジェクトを多く進めており、今回のセッションで学んだ内容をもとに、実際の業務にすぐに適用できる知識が得られることを期待して参加しました。
Agenda
このSessionは企業のIDPサービスとは何か、顧客会社での成功したIDP導入事例を説明し、Generative AIとの関連性と活用性についての内容で構成されます。

Why Intelligent Document Processing Matters?
企業がIDPを導入する主な理由は、次の3つにまとめられています。
- コスト削減:反復的で時間のかかる作業を自動化し、リソースを効率的に配分
- 精度向上: 正確なデータ処理によりエラーを低減し、信頼性を向上
- 生産性の向上:従業員が高付加価値業務に集中できる環境を提供
IDP Use Case
実際のケースでは、HealthFirst、Paytmなどのグローバル顧客がAWS IDPサービスを活用して業務効率を最大化したケースが共有されています。は強力なツールであることを示しています。

1. HealthFirst
- 分野:ヘルスケア
- ユースケース:医療チャート抽出ワークフローの自動化
- パフォーマンス:Amazon Textractを使用してデータ抽出プロセスの効率を10〜20倍向上
- ビジネス効果:手作業依存を大幅に削減し、データ処理速度を向上させることで運用効率を向上
2. Paytm
- 分野:金融
- 活用事例: 文書から顧客データを抽出し、信用評価や取引分析に活用
- パフォーマンス:Amazon Textractを活用して97%のドキュメント処理精度を達成
- ビジネス効果:高精度が要求される金融業におけるプロセスの合理化と信頼性の大幅な向上
3. Elevance Health
- 分野:ヘルスケア
- 活用事例:保険請求伝票処理の自動化
- パフォーマンス:Amazon Textractを使用して請求文書の処理時間を短縮し、90%以上のプロセスを自動化
- ビジネス効果:顧客満足度を高め、運用コストを削減することで競争力を強化
Components & Features of AWS IDP

次に、AWS の主要な IDP サービスコンポーネントと機能について簡単に説明します。これらのサービスはドキュメント処理ワークフローのすべてのステップをサポートし、APIベースに簡単に統合できます。
[ Amazon Textract ]
- OCRを超えてフォーマット、テーブル、キーと値のペアデータを抽出する
- 文書の概要と質問の回答(Query)機能までサポート
[ Amazon Comprehend ]
- テキスト分類、NER(Named Entity Recognition)、PII / PHIデータ識別などのNLP機能
[ Amazon Bedrock ]
- 生成型AIベースのモデルで、ドキュメントの要約、データの正規化、スペル校正などを提供
[ OpenSearch Service ]
- 検索とデータ分析のための拡張可能なプラットフォーム
Pipeline w/ IDP Services & Foundation Models
以下のアーキテクチャでは、AWS サービスと Generative AI モデルを統合して、従来のドキュメント処理パイプラインを自動化および強化する方法について説明します。
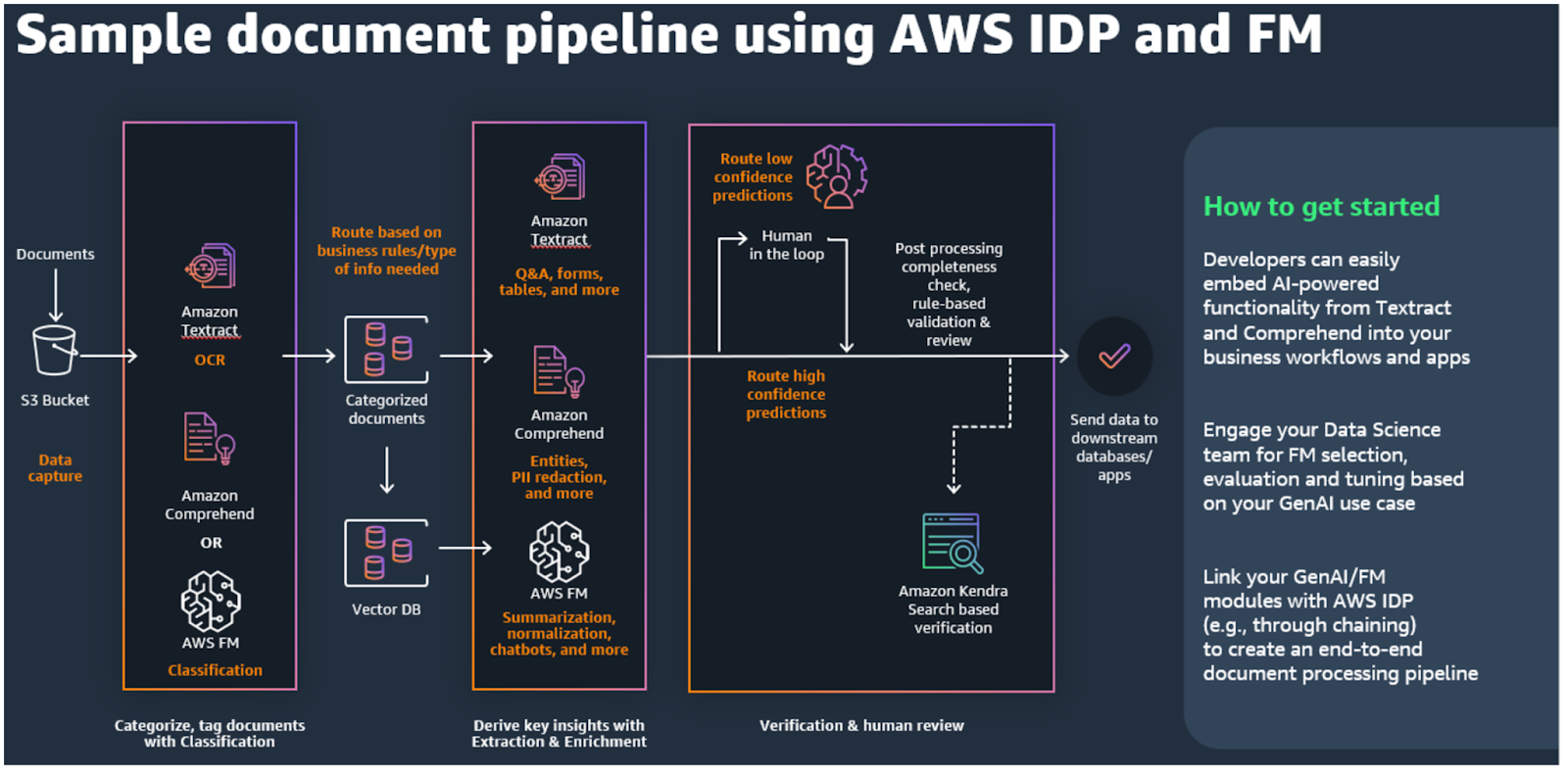
パイプラインは、次の主要なステップで構成されています。
1. 文書のキャプチャと保存
- Amazon S3 にドキュメントをアップロードして保存します。
- さまざまな形式の文書(画像、PDFなど)を処理します。
2. OCRとTextの抽出
- Amazon Textract を使用してドキュメントからテキストを抽出します。 TextractはOCR、表抽出、フォーム抽出をサポートし、文書から重要な情報を自動的に抽出できます。
- Bedrockを使用してマルチモードテキストを抽出できます。テキストと画像を同時に処理することで、精度を高めることができます。
3. 文書分類
- 抽出されたテキストに基づいて文書がどのようなものかを分離します。たとえば、パスポート、運転免許証、保険書類などに分類できます。
- LLMベース:Bedrockを使用して抽出されたテキストを分析し、文書タイプを自動的に識別します。
- 埋め込みベース:テキストをベクトルに変換した後、既存の文書と比較して最も類似したタイプを見つけます。
4. 情報抽出
- 文書から重要なデータを抽出します。
- Textract Forms APIを使用して、フォームから名前、日付、金額などのデータを抽出します。
- クエリ機能を使用して特定の情報を抽出できます(例:「医師の名前は何ですか?」)。
- Foundationモデルにより、手書きや抽出が難しいデータを補完し、精度を高めます。
5. データの正規化と変換
- 抽出されたデータは、指定されたフォーマットに変換する必要があります。
- Bedrockを使用してテキストを標準化し、エラーを修正できます。
6. 検証とルールベースの処理
- 抽出されたデータをルールベースの検証で確認します。文書に必要なフィールド(ex:名前、住所など)が正しく含まれていることを確認してください。
- Confidence Scoreを使用すると、信頼性の低い文書を人の検証段階に移動できます。
- Generative AI を使用してエラーが発生した場合に修正できます。
7.レビューと最終検証
- すべてのデータが抽出され正規化された後、レビュー段階を経て人が直接検証することができます。
- 検証されたデータはダウンストリームシステムに送信され、追加の処理が行われます。
8. 最終出力とシステム統合
- 検証されたデータはデータベースまたはアプリに渡され、最終的な決定または後続の操作に使用されます。
ワークショップでは、前述の理論とパイプラインを基準に実習をしてみました。
まとめ
このセッションでは、AWSのIntelligent Document Processing(IDP)ソリューションとGenerative AIを活用して、ドキュメント処理の効率と正確性を最大化する方法を学びました。具体的には、Amazon Textract、Amazon Comprehend、およびBedrockがどのように互いに結合して、データの抽出、強化、検証、および分析までの全プロセスをサポートするかを実践することで確認できました。
今回のセッションでは、Generative AI と AWS IDP サービスが実際の業務にどのように適用できるかを考えさせ、今後のワークフロー設計に重要な参考資料になりそうだと思いました。
記事 │MEGAZONECLOUD AI&Data Analytics Center(ADC)、Data Architecture Team、チョ・ミンギョンマネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び