MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #ANT311|生成型AIのためのデータ準備
Prepare your data for generative AI
セッション概要
- タイトル:Prepare your data for generative AI
- 日付:2024年12月3日(火)
- Venue:MGM Grand | Level 1 | Grand 117
- スピーカー:
- Roshin Babu(Sr Solutions Architect, Amazon)
- Houssam Hamad(Sr. Analytics Specialist Solutions Architect, Amazon Web Services)
- 業界:Cross-Industry Solutions
- 概要:生成されたAIアプリケーションにはさまざまなデータソースからのデータが必要であり、最適な経験のためにデータは信頼性が高く信頼性が高く、よく管理されなければなりません。このセッションでは、End-to-End生成型AI体験のためのAWSの強力なデータ関連基盤を紹介します。一括およびリアルタイムのデータパイプライン、高データ品質、カスタマイズされた要件のためのベクトルデータ管理、および統合データガバナンスを介して生成型AI用のデータを準備する方法を学びます。
はじめに
「あなたのデータが生成型AIのために準備されていないなら、あなたのビジネスも生成型AIのために準備されていない」 – McKinsey
という言葉があるほど、企業にとってデータはビジネスに直結する部分と言えます。
本セッションでは、AWSのサービスがどのように生成型AIをサポートするのか、データ基盤、統合、そしてガバナンス戦略に焦点を当てて説明します。
生成型AI用のAWS Data Capabilities
まず、生成されたAIアプリケーションには、まず深く包括的な機能を提供するData Foundationが必要です。 AWS は、データ分析、AI/ML サービスを通じて、最適なコストでどの Use case にも合った環境を提供します。
第二に、生成型AIアプリケーション用のデータ統合が必要です。堅牢なGenAIでは、Data Foundationに必要な複数の階層間統合が必要です。 AWS は Zero-ETL などのさまざまな機能をサポートし、簡単にすべてのデータ間の統合を可能にし、より強力な Data Foundation を構築するのに役立ちます。
第三に、生成されたAIアプリケーションのための正しいガバナンス戦略が必要です。エンドユーザーがデータと対話するために必要な複数のデータインフラストラクチャへのアクセスをエンドツーエンドで管理する方法が必要です。

End-to-End Data Foundation
AWS のサービスを活用した End-to-End Data Foundation は、複数の階層に分けられます。
- データ収集
- バッチ、マイクロバッチ、リアルタイムインジェクションをサポートし、それぞれの目的に合わせてAmazon Kinesis、Amazon MSK、DB Migration Service、Glue Connectorsなどを提供します。
- このステップの鍵は、作業に適したツールを使用し、各データソースタイプに合わせて設計されたサービスを使用することです。
- データ処理
- データ品質の検証と変換作業のためにEMR、AWS Glueなどを提供します。
- データ品質の検証と変換作業のためにEMR、AWS Glueなどを提供します。
- データ保存
- データレイク用のS3およびGlue Catalog、データウェアハウス用のRedshift、その他のRDBおよびOpenSearch Serviceなど、さまざまなサービスを提供しています。
- データレイク用のS3およびGlue Catalog、データウェアハウス用のRedshift、その他のRDBおよびOpenSearch Serviceなど、さまざまなサービスを提供しています。
- データ活用
- BI用Amazon QuickSight、生成型AI用Amazon Bedrock、ML用SageMakerなど、さまざまなサービスを使用してデータ分析に活用できます。
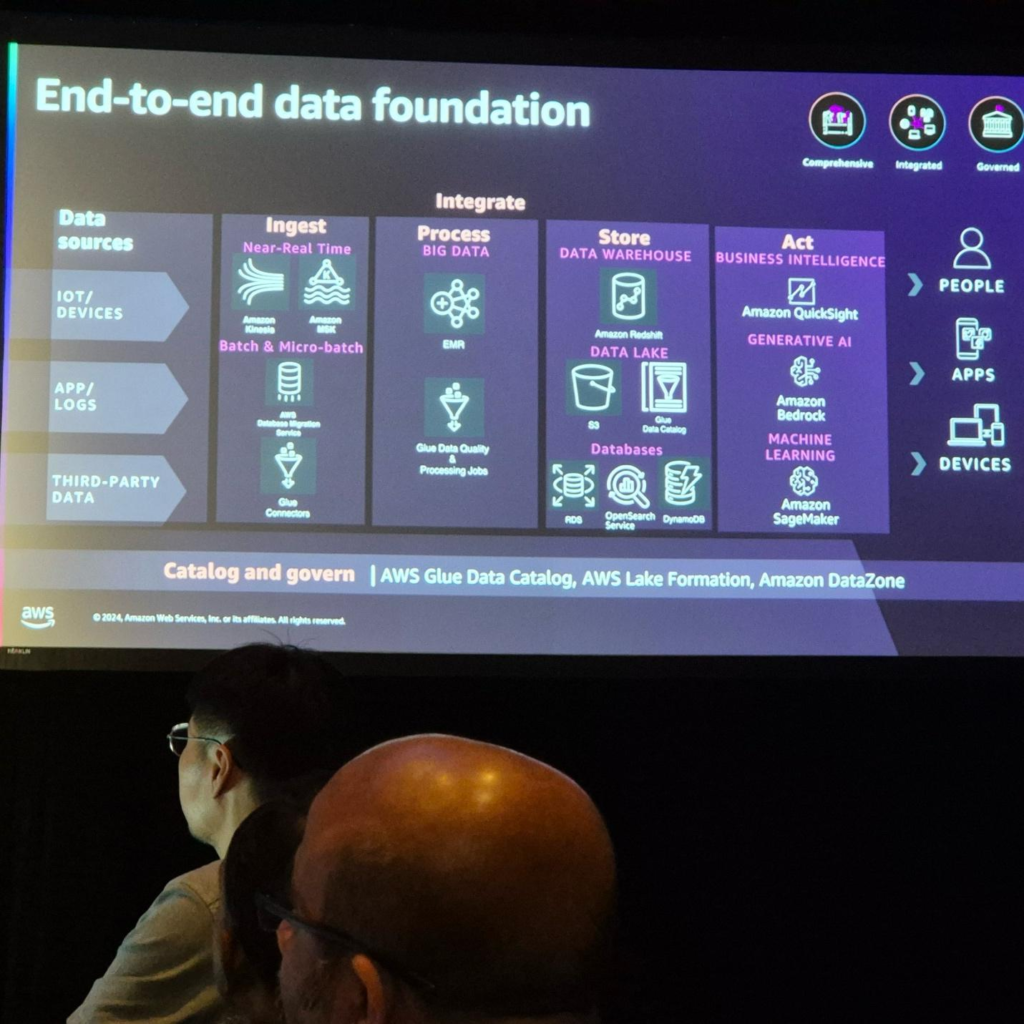
Data Foundation ベースの GenAI Application Architecture
前述の階層を、生成型AI用のData Foundationに具体化すると、次のようになります。
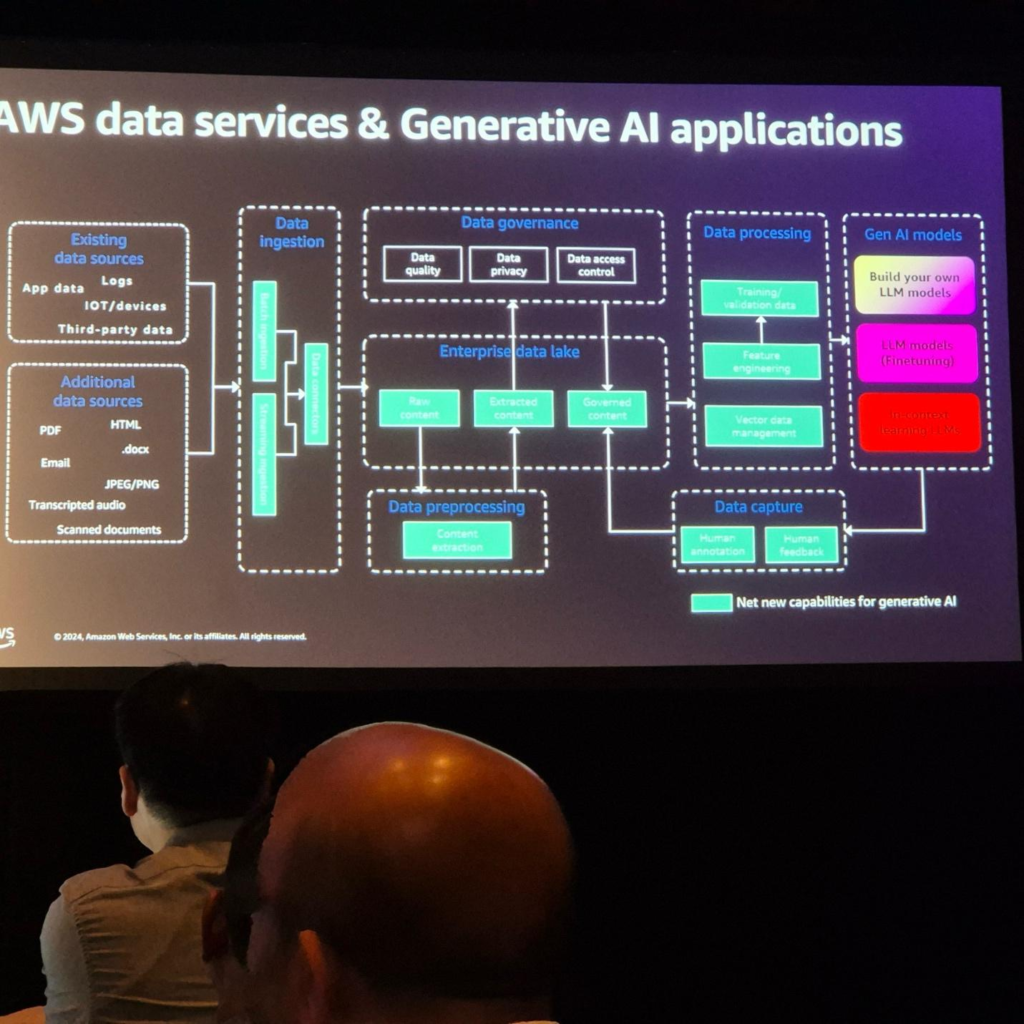
- データソース
- データは、さまざまなソースからさまざまな形式でさまざまな方法で収集されます。データ収集レイヤーは、これらのデータソースと接続できるさまざまなコネクタを介してデータを収集します。
- データは、さまざまなソースからさまざまな形式でさまざまな方法で収集されます。データ収集レイヤーは、これらのデータソースと接続できるさまざまなコネクタを介してデータを収集します。
- データガバナンス
- アーキテクチャ全体で起こるすべてのタスクを管理する方法が必要です。このステップでは、Data Meshパラダイム内でProducer-Consumerモデルを有効にする必要があります。
- これには非常に強力な権限分離が必要です。 Data Zoneを使用すると、これらの機能を活用できます。
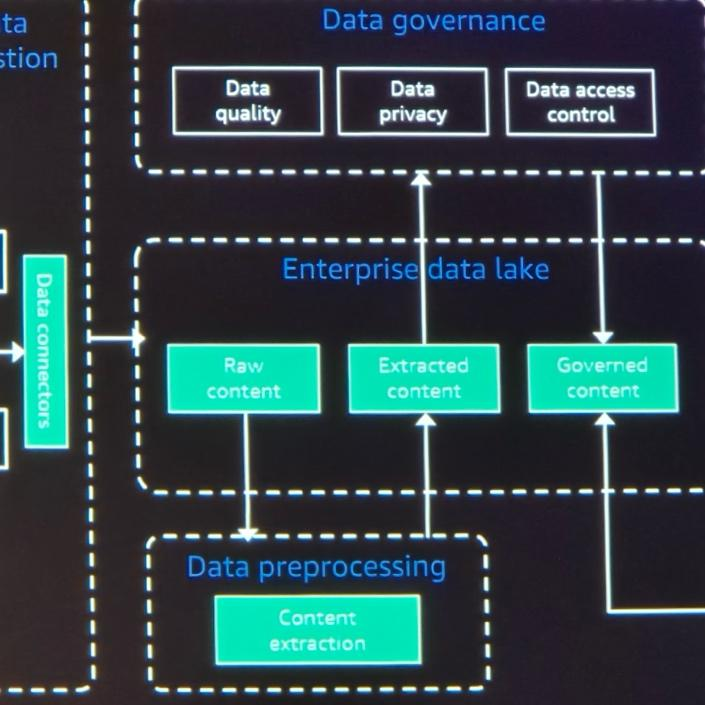
3. データレイク
- 1 つ以上の Enterprise Data Lake を使用するか、分散環境でデータを管理します。
- 重要なのは、1つのテーブルではなく、複数のテーブルと複数のビューを組み合わせて1つのデータになることです。
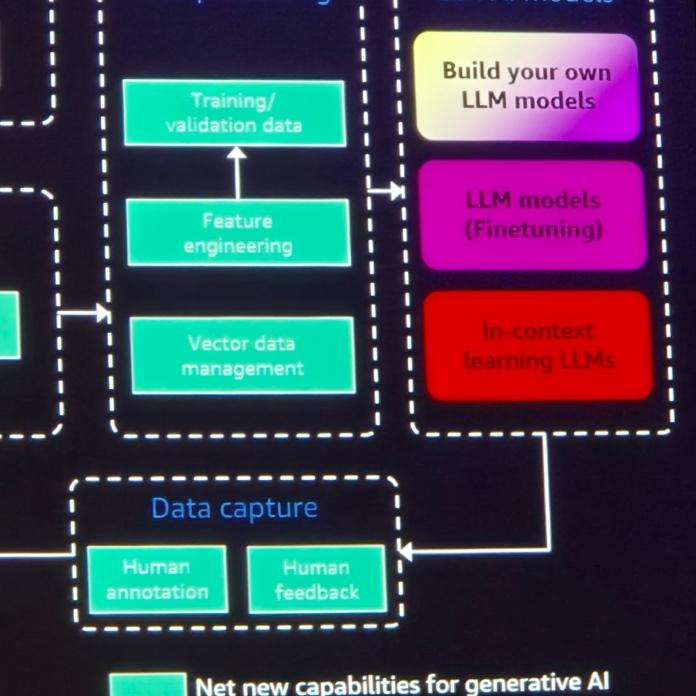
4. Data Capture & Feedback
- 最後に、Human in the Loopフィードバックを使用してRAGを有効にし、生成されたAIアプリケーションとモデルを微調整することができます。
- これにより、ビジネス要件を満たす品質の高い結果を提供できます。
まとめ
最近、生成型AI関連業務を進めてみると、日が経つにつれて、少し特別で珍しいケースに合った生成型AIアプリケーションを望む顧客が増えています。これらのニーズに合ったアプリケーションを開発するには、堅牢なData Foundationと統合データ管理とガバナンスが不可欠であると感じています。
前述のように、AWSはこれらのニーズを満たすための最適なサービスを提供し、End-to-Endプロセスをサポートします。これにより、生成型AIを活用したビジネス目標を達成し、競争力を強化できるようになります。
記事 │MEGAZONECLOUD AI&Data Analytics Center(ADC)、Data Engineering 2 Team チョン・ジソン マネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び