MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #AIM232-S|Intel&OPEAと共にAWSでのRAGデプロイの最適化による生成型AIのシンプル化(sponsored by Intel)
Simplify gen AI by optimizing RAG deployments on AWS with Intel & OPEA (sponsored by Intel)
セッション概要
- タイトル:Simplify gen AI by optimizing RAG deployments on AWS with Intel & OPEA (sponsored by Intel)
- 日付:2024年12月3日(火)
- Venue:Wynn | Level 1 | Lafite 4 | Content Hub | Pink Screen
- スピーカー:
- Ezequiel Lanza(Open Source AI Evangelist, Intel)
- Anthony Vance(Principal Engineer, Intel Corporation)
- Jon Handler(Director, Solutions Architecture, Search Services, AWS)
- 業界:
- Cross-Industry Solutions
- Financial Services
- Healthcare & Life Sciences
- 概要:生成型AI導入の複雑さ、コスト、人材不足の問題を解決するために、Linux Foundation AI&DataがOpen Platform for Enterprise AI(OPEA)をリリースしました。 OPEAは、独自のデータとオープンソースツールを組み合わせて、カスタマイズされたソリューションを提供します。 IntelとOPEAパートナーは、RAGパイプラインを活用してAIを民主化しており、Amazon EC2、EKS、RDS、OpenSearch、およびXeonを通じて最適化されたRAGパイプラインをすばやく設定する方法を紹介します。
はじめに
今日のセッションでは、Generative AIアプリケーションのデプロイプロセスを合理化し、開発効率を最大化するためのオープンソースフレームワークOPEA(Open Platform for Enterprise AI)について説明します。
OPEAの実際のユースケースにより、進行中のプロジェクトに直接適用できるアーキテクチャやパイプラインを構想できると期待しました。さまざまなコンポーネントが有機的に接続され、その過程で発生する可能性のある技術的な障壁をどのように解決できるかについての答えを見つけることができる時間になると思いました。
Generative AI Applicationの限界と複雑さ
最近、Generative AIテクノロジはテキスト生成、画像生成、データ分析など、さまざまな分野で爆発的な関心を集めていますが、実際に企業の環境に適用するにはまだ多くの障害があります。

- さまざまなコンポーネントの統合問題アプリケーションは、
平均して20〜30のコンポーネントで構成されており、それらが正しく互換性がない場合、展開プロセスでエラーが発生します。 - ベンダーの依存関係の問題特定
のプラットフォームやベンダーの技術に依存すると、柔軟性が低下し、長期的なコスト負担が増加します。 - 標準不足
企業は開発過程で検証された事例や明確なガイドラインが不足し、多くの時間を再設計とテストに費やしています。
OPEAは、これらの問題を解決するために、オープンな構造と標準化されたベストプラクティスを提供し、企業がアプリケーションを効率的に開発およびデプロイするのに役立ちます。
About OPEA
OPEAは、AWS、INTEL、Open Searchなどのグローバルテクノロジー企業が協力して開発したオープンソースフレームワークで、マイクロサービスアーキテクチャに基づいて設計され、各コンポーネントを独立して管理できる柔軟性と拡張性を提供することができます。あります。

- Plug & Play 構造: ユーザーは、特定のベクターデータベースや LLM などのコンポーネントを必要に応じて交換できます。
- Blueprintの提供:チャットボット、ビデオQ&A、ビジュアルQ&Aなど、20以上のアプリケーションのブループリントを提供することで、デプロイプロセスを簡素化します。
- Communityベースのコラボレーション:OPEAは、さまざまな企業やコミュニティの貢献を通じて継続的に改善されており、新しい要件に柔軟に対応できます。
AWS & Intel & OPEA
| AWS | インテル | OPEA | |
| Platform | O | ||
| サービス | O | ||
| Model/Hardware | O |
1. AWS: OPEA がデプロイされる主要なクラウド環境で、AWS の複数のサービスが利用されます。
- EKS(Elastic Kubernetes Service):マイクロサービスの展開とオーケストレーション。
- Open Search:データストアと検索エンジン。
- SageMaker / Bedrock:AIモデルの学習と展開。
- AWSはOPEAとの統合により、スケーラビリティとマルチクラウドサポートを提供します。
2. INTEL:Intel Gaudi 2 AI Accelerator(高性能AIモデルアクセラレータ)は、学習、推論に最適化されたハードウェアを提供します。
- 最適化されたモデル:LLMおよび他のAIモデルに最適化されたソフトウェアスタックを提供します。
- Hugging Faceなどのオープンソースモデルや特定のカスタムモデルもサポート。
- OPEAのブループリントを活用して、Intelハードウェアと最適化されたAIモデルを簡単に展開できます。
3. OPEA:GenAIアプリケーションの基本構造を設計し、展開プロセスを簡素化するためのフレームワークを提供します。

上の図は、一般的なOPEAのChatBot Pipelineです。
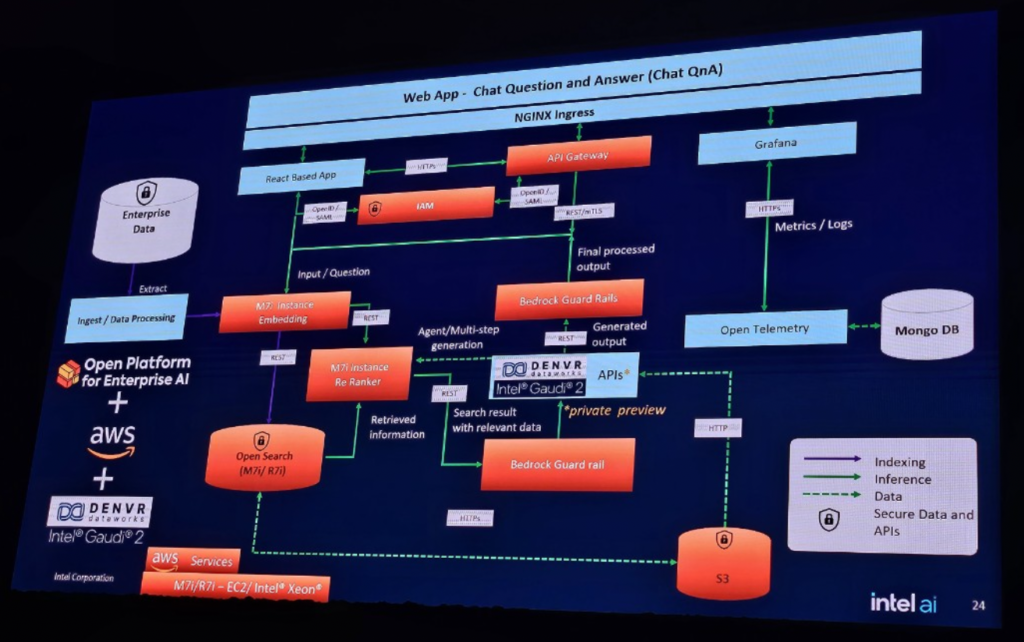
上の図は、一般的なOPEAのChatBot PipelineにAWSサービスを適用したバージョンです。
OPEAはプラットフォーム自体では特定のテクノロジに依存せず、AWSのクラウドサービスとIntelのAIハードウェアとソフトウェアを選択的に組み合わせてアプリケーションを開発およびデプロイできるように設計されています。この構造は、企業が特定のベンダーに縛られることなく最適な技術スタックを選択する自由を提供します。
About OpenSearch
AWSが主導するオープンソースの検索および分析エンジンで、OPEAプラットフォームでバックエンドのデータ処理と検索を担当するコアサービスです。

- 検索エンジン機能:OpenSearchは整形データと非定型データを検索でき、Lexical / Vector / HyBrid Searchをサポートします。これにより、Generative AIアプリケーションで高度な検索体験を提供します。
- ベクトルと生成AIのサポート:OpenSearchは、近接ネイバー検索(KNN)アルゴリズム(HNSW、IVFなど)を利用して、ベクトルデータを効率的に処理します。これにより、意味ベースの検索および推奨機能が可能になります。
- データ分析と視覚化:大規模なログデータを処理し、それを視覚化ダッシュボードの形式で表現することができ、リアルタイムの監視と通知設定が可能です。
- スケーラビリティと柔軟性:AWSクラウドベースのマネージドサービスと独自のディストリビューションサービスの両方をサポートし、ユーザーはクラスタサイズと設定を自由に調整できます。
OpenSearchは単に検索ツール以上の役割を果たしており、OPEAのデータストアと検索機能を強化するための重要な要素となっています。
OPEA Config ㅣ Retriever & Data Prep
OPEAのCONFIGは、RetrievalとData Prepの設定を効率的に管理および最適化する重要な役割を果たします。これにより、Generative AIアプリケーションを迅速にデプロイして柔軟に管理できます。
1. Retrieval設定
- 検索エンジンの選択:OpenSearch、Redisなど、さまざまな検索エンジンを設定できます。
- 検索パラメータの調整:KNNアルゴリズム(HNSW、IVFなど)などで検索性能を最適化します。
- 検索クエリの最適化:ベクトルとテキスト検索を組み合わせて効率的な検索を提供します。
2. Data Prepの設定
- データソースの定義:ローカルファイルシステム、クラウドストレージなどからデータをインポートします。
- データ前処理:データの洗練、トークン化、ベクトル化などのタスクを設定できます。
- パイプライン構成:データ処理パイプラインを設定して、複数の前処理を順次処理します。
3. RetrievalとData Prepの統合
統合パイプライン:データを準備し、すぐに検索に利用できるように、RetrievalとData Prepをリンクします。
まとめ
今回のセッションを通じてOPEAの機能を直接体験することができました。 OPEAはオープンソースのプラットフォームであり、GitHubで完全なコードとワークショップ資料を公開しており、実際にConfigファイルを修正してパイプラインを再構成でき、直接カスタマイズすることもできます。特に、EKSとCloudFormation Stackを活用して自分のAWSアカウントに直接テストできるコードが提供されており、クラウド環境でGenerative AIプロジェクトを簡単に実行できることが非常に良かったです。 EKSベースでGenerative AIプロジェクトをまだ進めていないのですが、今回の機会を通じて実際にOPEAのコードを活用して新しいプロジェクトアーキテクチャを構築するのに役立つことができるように聞いたやりがいを感じました。
記事 │MEGAZONECLOUD AI&Data Analytics Center(ADC) Data Architecture Team チョ・ミンギョンマネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び