MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #AIM381-S|ElasticsearchとAmazon Bedrockを使用したRAGアプリケーションの構築(sponsored by Elastic)
Building RAG applications with Elasticsearch and Amazon Bedrock (sponsored by Elastic)
セッション概要
- タイトル:Building RAG applications with Elasticsearch and Amazon Bedrock (sponsored by Elastic)
- 日付:2024年12月4日(水)
- Venue:Venetian | Level 3 | Murano 3304
- スピーカー:
- Ayan Ray(Senior Partner Solutions Architect, Generative AI, Amazon Web Services)
- 業界:Cross-Industry Solutions
- 概要:Amazon Bedrock の Elasticsearch Open Inference API と Playground と Elastic の統合を使用して、開発者が Amazon Bedrock ですべての大規模言語モデルを使用して RAG アプリケーションを構築できる柔軟性を向上させる方法を学びます。このセッションでは、膨大なモデルライブラリを活用して高度な検索環境の開発を簡素化する方法を検討します。開発者がElasticsearch環境内で直接高度なモデルテストと埋め込み機能を使用してインタラクティブ検索を改善する方法を学びます。このプレゼンテーションは、AWSパートナーElasticによって提供されます。
はじめに
私たちは、これまでに何かを検索する際に、私たちが検索したい内容のキーワードを直接選んで検索に活用してきました。しかし、このような検索は、ユーザーのキーワード抽出能力に応じて、あるいは同じトピックがさまざまなキーワードによって正確なデータを見つけることもできないかもしれません。ただし、Elasticsearchを使用したSemantic検索を利用する場合は、より自然な質問でより包括的で正確なデータを検索できます。このセッションでは、Elasticsearch と Amazon Bedrock を使用して RAG (Retrieval Augmented Generation, 検索拡張生成) アプリケーションを作成する方法について説明します。
New Normal
生成型AIは検索のニューノーマルとなりました。従来の検索エンジンのデータ提供方式は、ユーザーのキーワード検索に対して、単に関連するページのリンクを表示するだけでしたが、生成型AIは単純なリンクを表示するだけでなく、実際の回答を提供します。
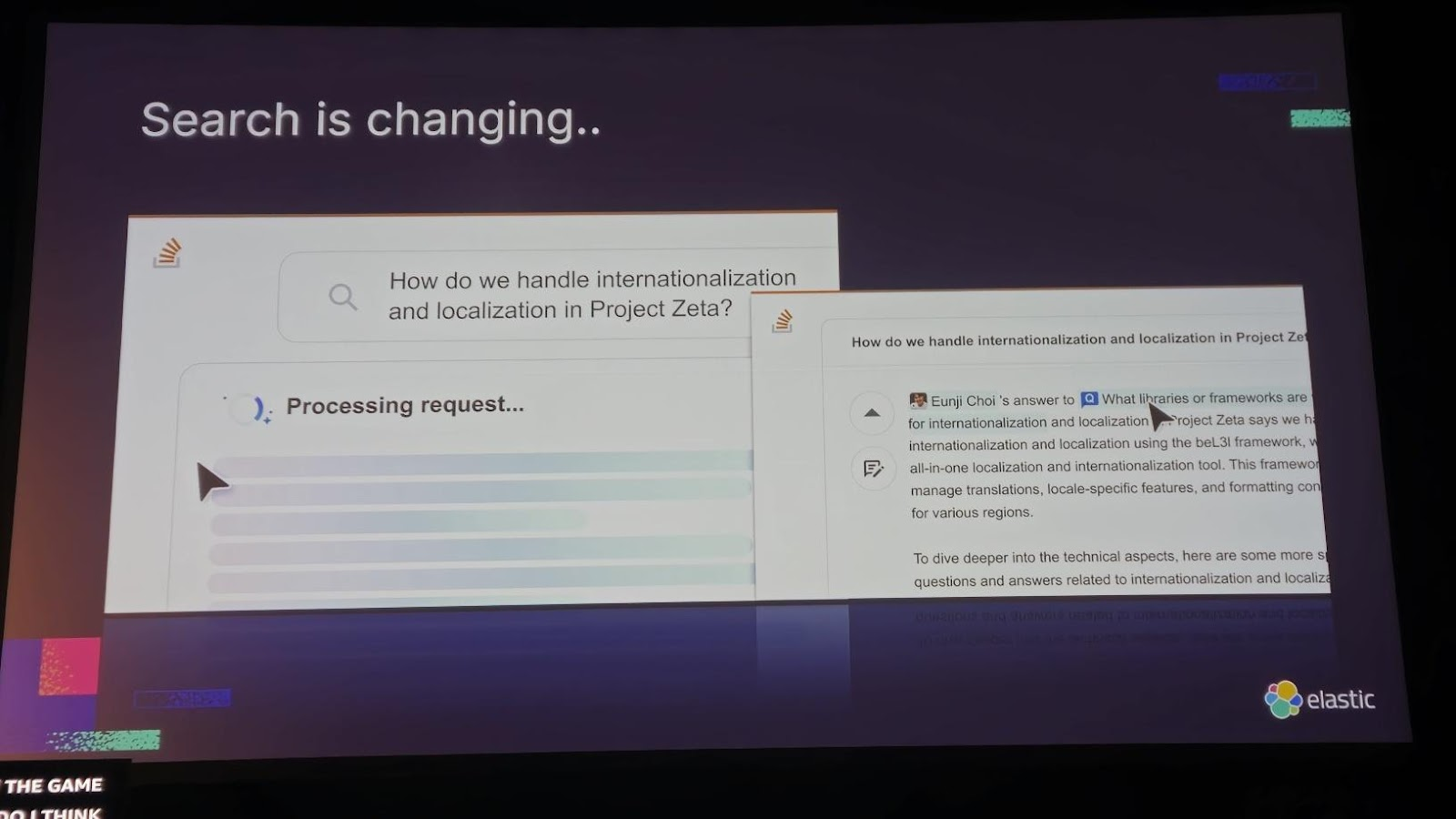
このような生成型AIの核心的な部分がまさにRAGと言えます。ユーザーが知りたいことが一般的な内容であれば問題ありませんが、特定の企業の情報、あるいはAIが学習していない最新情報に関する内容であれば話は変わってきます。

Elasticsearchのさまざまな機能
RAGにとって最も重要な部分はVectorの類似度検索であり、Elasticsearchはこの機能を提供します。Elasticsearch Relevance Engine (ESRE)は、AIベースの検索アプリケーションを駆動するように設計されています。
VectorDBとして速度向上及び企業単位又はペタバイト単位のスケール単位のデータでも活用可能であることを確認しました。 また、関連検索及びRAGに活用できる最高のhybrid search機能も有しており、簡単にElasticsearchを活用できるようにELSER、量子化など様々な機能をサポートしています。
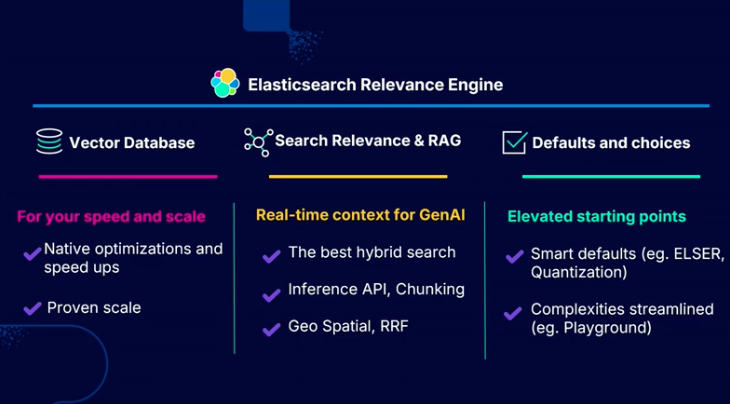
ここ数年、Elasticsearchは様々な面で目覚ましい性能向上を遂げてきました。
マルチグラフベクトル検索の高速化によりレイテンシーが60%以上削減され、スカラー量子化とバイナリ量子化により、速度とメモリの最適化がそれぞれ8倍、32倍以上改善されました。 また、インデックス作成速度も144%以上向上しました。

1) Better Binary Quantization (BBQ)
特に、BBQの場合、Elastic 8.16バージョンで新たに提供されるもので、実数ベクトルを量子化してビット単位に変換し、最大95%のメモリを節約することができます。ベクトル量子化時間自体も数十倍速くなり、ベクトル検索パフォーマンスも向上しました。

2) New _inference API
New _inference APIを使ってAmazon Bedrockと接続するなど様々なエンドポイントを生成して活用することもできます。例えば、APIの最後にbedrock-embeddingsと書いた後、JSON構文で一回だけPUTコマンドを送ると新しいエンドポイントが生成され、このエンドポイントを通じてbedrock-embeddingsという名前でAmazon BedrockのTitan embeddingsモデルを活用することができます。

3) Rerank API
inference/rerank APIで検索結果をRe-Rankingすることができます。最初の検索結果を再配置して、質問に応じて結果の優先順位を調整する機能です。

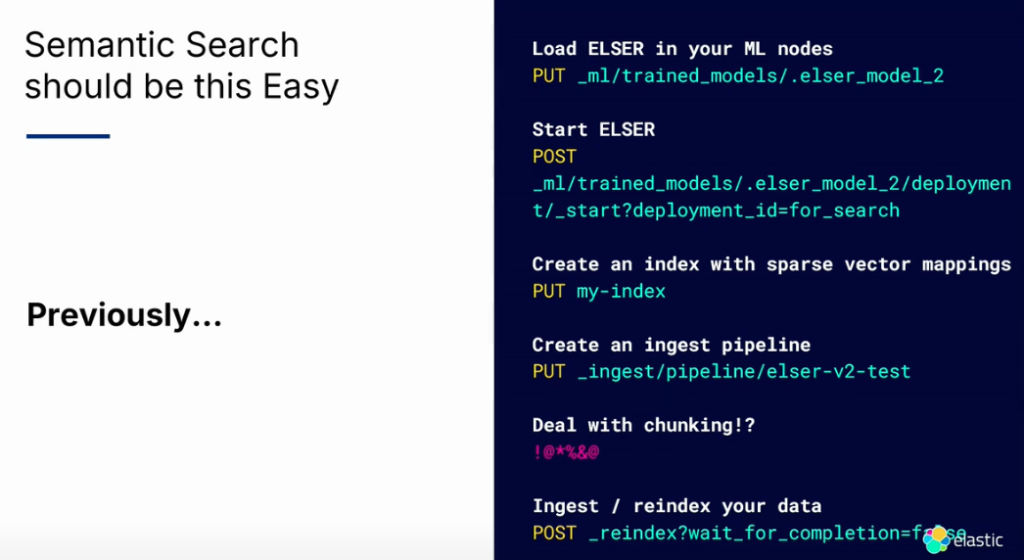
4) Semantic Text Field
従来のSemantic検索は、下記のようにかなり複雑な作業が先行しなければなりませんでした。
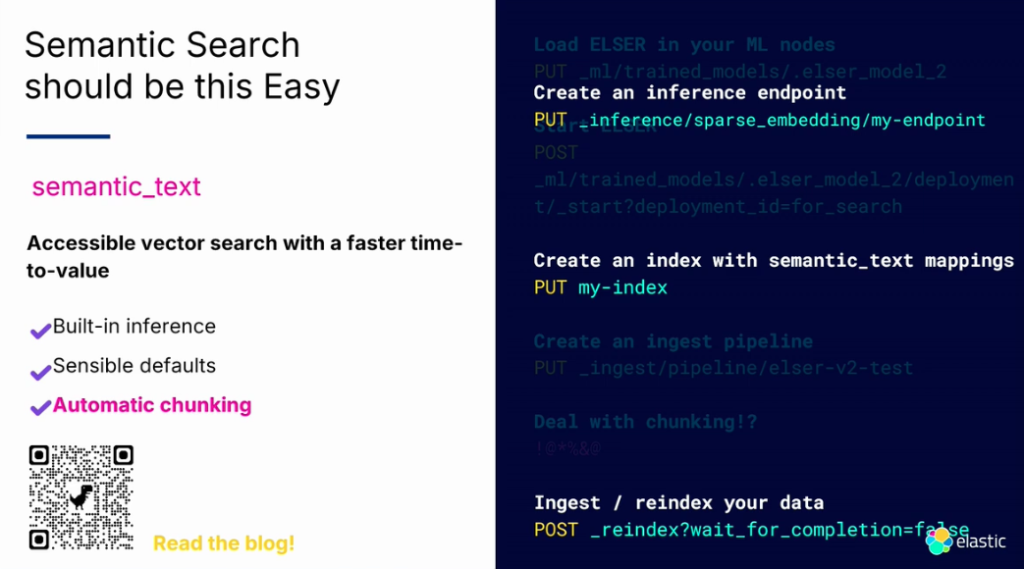
しかし、今はSemantic Text Fieldを設定すれば、複雑なプロセスは除いて自動的にチャンキングと埋め込みを管理することができます。
5) RRF
Reciprocal Rank Fusion (RRF)は、異なる指標を持つ複数の結果を一つの結果セットに結合する方式です。 結果のスコア尺度が異なる二つの検索方法であるLexcial & Semantic検索結果を一つの結果に結合する方式で、別途のチューニングが必要なく、指標が互いに関連しなくても高品質の結果を得ることができます。

6) Geospatial search
地理的な検索をすることもできます。例のようにbounding boxを選択して検索したい空間を選択します。
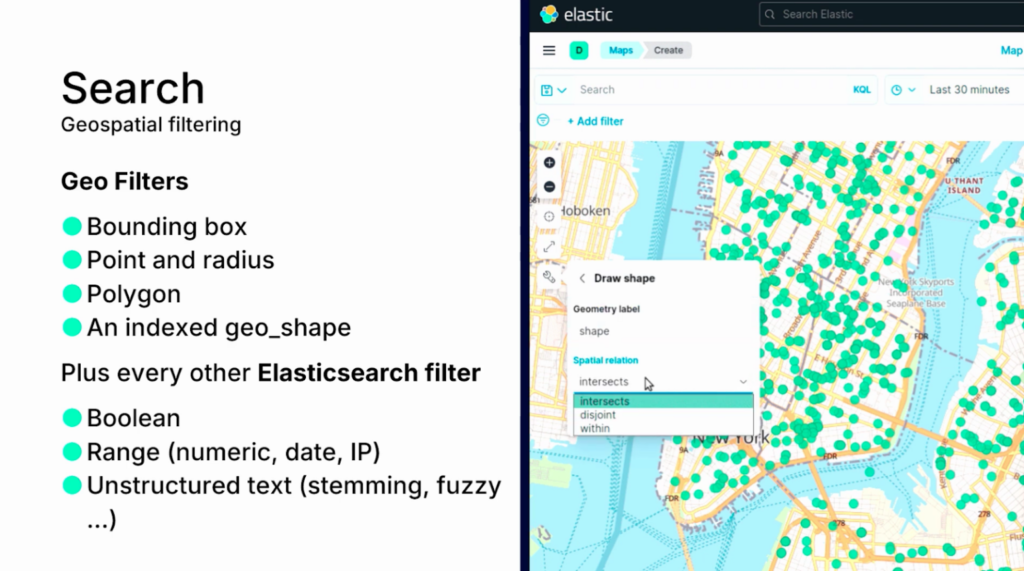
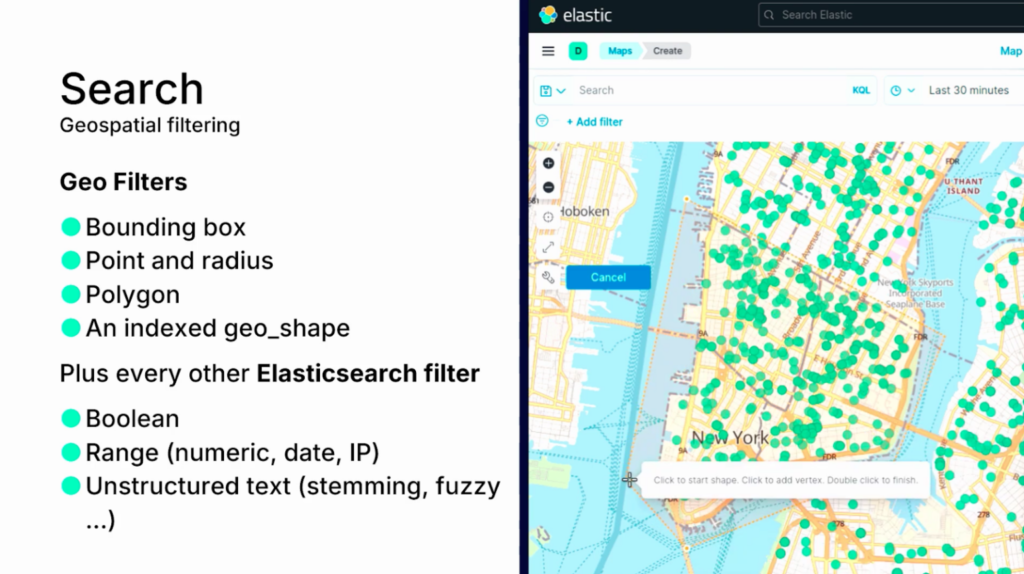
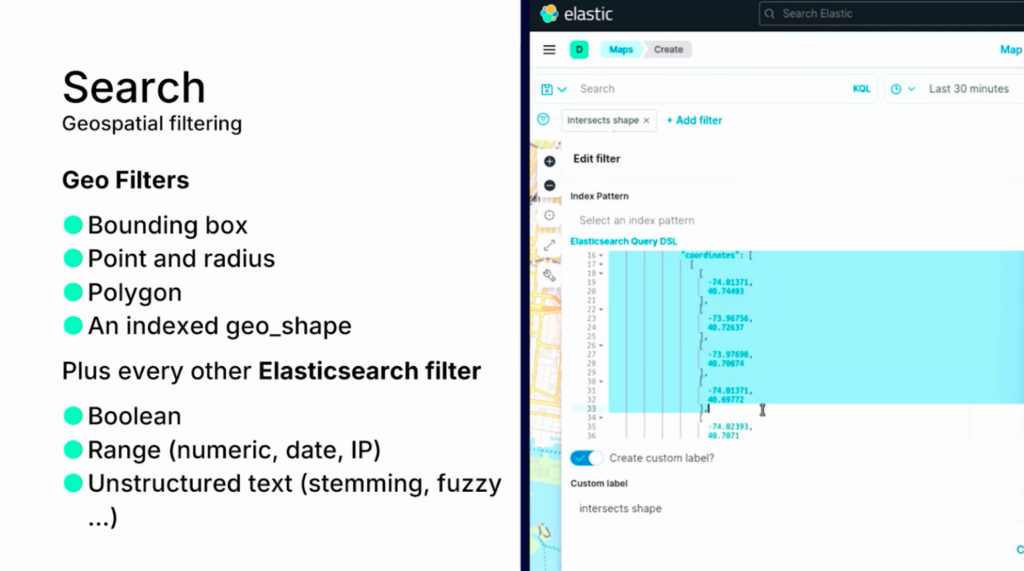
空間が選択されると、実際のクエリは次のように設定され、検索が行われ、目的の空間内の検索結果を確認することができます。地理的検索は、例えば、不動産関連企業で生成型AIを組み込んだアプリケーションを設計する必要がある場合に活用することができます。
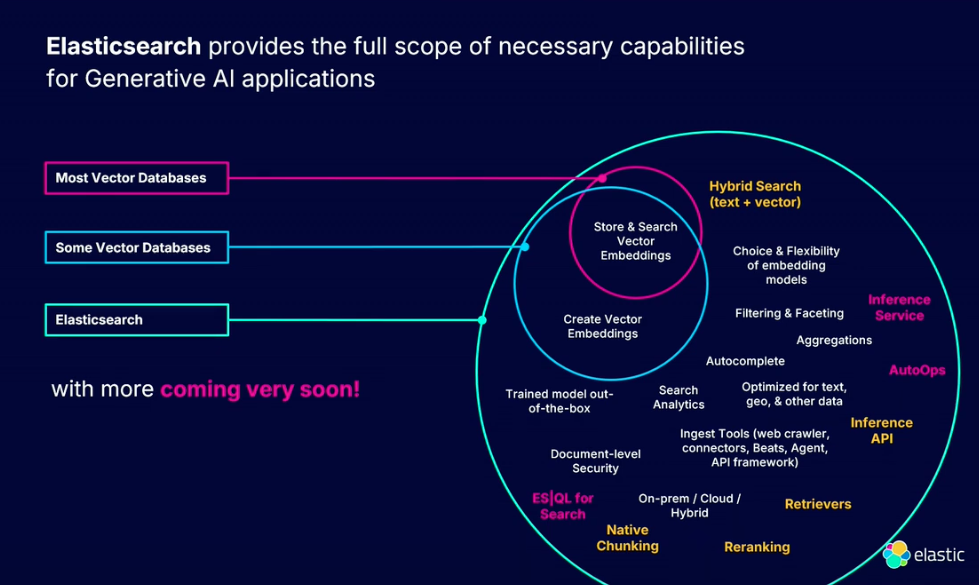
このように、Elasticsearchは生成型AIアプリケーションに必要なコンポーネントを提供しており、今後も提供していきます。
まとめ
今回のセッションでは、RAGアプリケーション開発のためにVector Databaseとして活用できるElasticsearchの様々なFeaturesについて説明しました。Elasticsearchは、生成型AIアプリケーションに必要なコンポーネントを提供するために継続的に努力しており、今後も継続的に関連機能を追加していく予定です。生成型AIでRAGは切り離せない核となる部分であり、RAGにとってVector Searchは必ず必要な部分であり、今後Elasticsearchがどこまで発展して生成型AIの核となるのかが楽しみです。
記事 │MEGAZONECLOUD AI & Data Analytics Center(ADC) Data Engineering 2 Team チョン・ジソン マネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び