MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #NSTG323|Amazon S3でのデータレイクの構築と最適化
Build and optimize a data lake on Amazon S3
セッション概要
- タイトル:Build and optimize a data lake on Amazon S3
- 日付:2024年12月4日(水)
- Venue:Mandalay Bay | Lower Level North | South Pacific E | Purple
- スピーカー:
- Thomas Moore(Senior Solutions Architect, Amazon Web Services)
- Jeffrey Hammond(Head of WW ISV Product Management Transformation, Amazon)
- 概要:組織はAWSベースのデータレイクを構築し、何千人ものユーザーがアクセスできるようにし、パフォーマンスを向上させるためにオープンテーブルフォーマット(OTF)を採用しています。このセッションでは、Amazon S3の最新イノベーションとデータレイクの構築と管理のベストプラクティスを紹介します。 また、AWSとさまざまなツールを活用したデータ最適化についても説明します。
はじめに
データが爆発的に増える今日、データを効率的に保存して活用するためのデータレイクの重要性がますます大きくなっています。決定を下すのに不可欠な役割を果たします。このセッションでは、データアーキテクチャの設計、セキュリティと管理の強化、パフォーマンスの最適化などの重要なトピックをカバーし、データ管理の効率性を高め、ビジネス競争力を高めることができます。実際の方法を調べようと申請するようになりました。
データレイクの主なステップ
データレイクは様々なステップを経て設計・実装されます。今回のセッションでは、以下のような主な段階を中心にデータレイクの構築と運営戦略を説明しました。

- The realization : データレイクの必要性を認識します。
- Constructing a resilient architecture : 堅牢なアーキテクチャを設計します。
- Data security and governance:データセキュリティと規制を強化します。
- Optimizing queries:クエリのパフォーマンスを最適化します。
- Data management:効率的なデータ管理を行います。
- Preparingforsustainablegrowth:持続可能な成長の準備をします。
これらのステップは、データレイクの成功した構築と運用のための重要な要素を示しています。それでは、各ステップについて具体的に見てみましょう。
データアーキテクチャと階層化
データを効果的に保存および管理するためには、体系的なアーキテクチャと階層化戦略が不可欠です。データレイクの最初のステップであるThe realizationは、データレイクの必要性を認識し、これによりビジネス価値を最大化することに焦点を当てています。
このセッションでは、Forever E commerceのケースで次の3つの戦略を紹介しました。
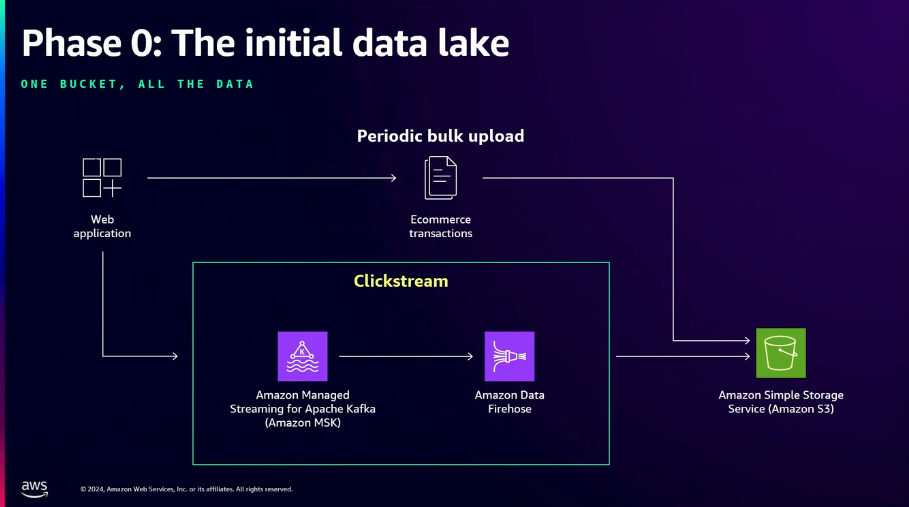
- データ統合と運用課題の解決
Forever E Commerceは、データの増加によるパフォーマンスの低下や検索困難などの運用上の課題を解決するために、Amazon S3をデータレイクとして使用しました。
S3スケーラビリティと高性能を活用して大規模なデータを統合保存することで、データのアクセシビリティと検索効率性を改善しました。
初期段階では、Webアプリケーションとeコマーストランザクションで生成されたクリックストリームデータをAmazon MSKとFirehoseを介してS3に転送してデータを統合管理しました。
この統合アプローチは、既存の分散データ環境で発生していた非効率性を解消し、リアルタイムデータ処理の基盤を築くことができました。 - データ階層化の戦略
Constructing a resilient architecture フェーズでは、データを生、処理された、選択された形式で階層化し、体系的に管理します。
Forever E commerceはクリックストリームデータを生データとして保存し、Glueを利用してユーザーの行動パターンを分析し、必要なデータを選別してビジネス意思決定に活用しました。
このような階層化は、データの品質を維持しながら分析効率を向上させるのに貢献し、大規模なデータを体系的に管理するために不可欠な要素として機能します。
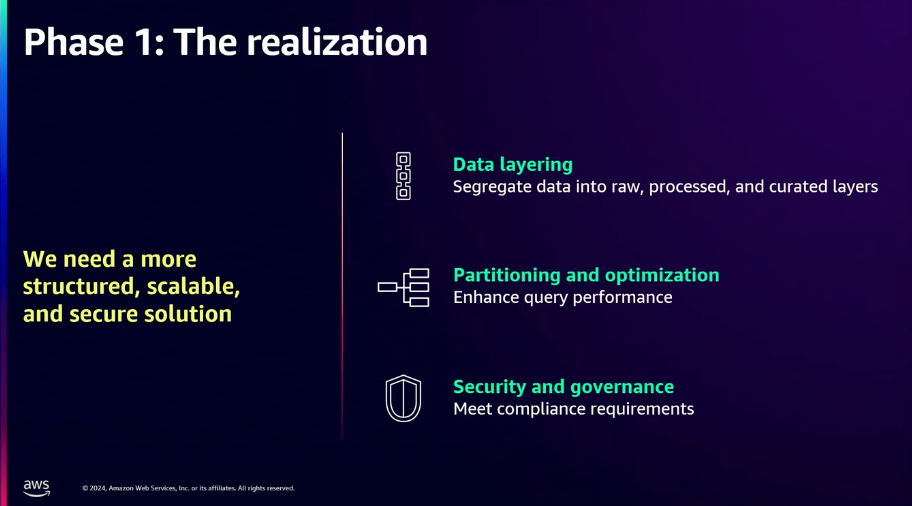
この図は、データレイクの階層化に関連する核心概念を視覚的に示しています。
Data Layering:データを生、処理済み、選別された形で分離して管理します。
Partitioning and optimization: クエリのパフォーマンスを向上させるために、データのパーティショニングと最適化を実行します。
Security and governance : データのアクセス制御と規定を遵守して、セキュリティとガバナンスを強化します。
このような階層化戦略は、データ構造化分析性能の向上を可能にします。

3.自動化と最適化
IcebergとGlueクローラーを活用してデータ階層化を自動化し、処理パイプラインを最適化してデータの価値を最大化しました。
Icebergテーブルはデータの更新と削除作業を容易に処理し、複雑なデータセットを効果的に管理しました。
Forever E commerceは、これにより、運用の複雑さを軽減し、データ処理コストを削減し、大規模なデータ運用の効率を向上させました。
このように、データアーキテクチャ設計と階層化戦略は、データレイク運営の基本を形成する重要なプロセスです。
それでは、こうして構築されたデータをどのように効率的に管理し、最適化することができるのかについて説明します。
データ管理と最適化
データを効果的に管理および最適化することは、データレイクの運用の中心です。Optimizing queriesステップはデータを分析するためのクエリパフォーマンスを最適化し、Data Managementステップは効率的な運用のための管理方法を提供します。
- リアルタイムデータストリーミングの管理
Amazon MSKとGlueを活用して、リアルタイムデータストリーミングと変換タスクを効率的に管理します。 Forever EcommerceはMSKを使用してリアルタイム注文データを処理し、Glueトリガーを介して注文ステータスを変換しました。これにより、ビジネス運営の俊敏性を向上させることができます。 - データアクセシビリティの向上
Glueデータカタログを使用して、データの自動インデックス付けとナビゲーションを簡素化し、データアクセシビリティを向上させました。これにより、開発チームと分析チームが同じデータソースに簡単にアクセスできます。 - パフォーマンスの最適化とコストの削減
Icebergテーブル形式とParquetファイル形式を使用してクエリのパフォーマンスを最適化し、Z-Orderソートで大規模なデータセットでもコストを削減します。 Forever E commerceはParquetファイルを使用して売上データをソートし、Athenaクエリの速度を大幅に改善しました。
次に、これらのデータを保護し、適切にガバナンスを設定する手順であるData security and governanceについて説明します。
セキュリティとガバナンス

データのセキュリティとガバナンスは、データを安全に保護し、コンプライアンスを確保するために不可欠です。 Data security and governance フェーズでは、データ保護と透明性を強化するための方法を取り上げます。
- 細分化されたデータアクセス制御
AWS Lake FormationとGlueデータカタログを活用して、データアクセスを細分化し、データ保護とコンプライアンスを確保します。 Forever E commerceは、機密顧客データを保護するためにLake Formationを使用して権限を設定しました。 - データの透明性とトレーサビリティ
DataZoneを使用してデータの流れを追跡し、データガバナンスを強化することで、データ使用の透明性を高め、コンプライアンスと監査要件を満たすために必要不可欠です。 - データ品質の確保
データ品質ルールを適用し、Glueデータ品質機能を活用してデータの正確性を確保し、CloudWatchとEventBridgeでデータ品質問題に迅速に対応します。例えば、Forever E commerceは、Event Bridgeを通じてデータ異常を自動的に検知し、対応します。
上記のセキュリティおよびデータ品質管理戦略に加えて、AWSは以下のようなツールを通じてデータガバナンスを強化し、データ管理の信頼性を高めています。
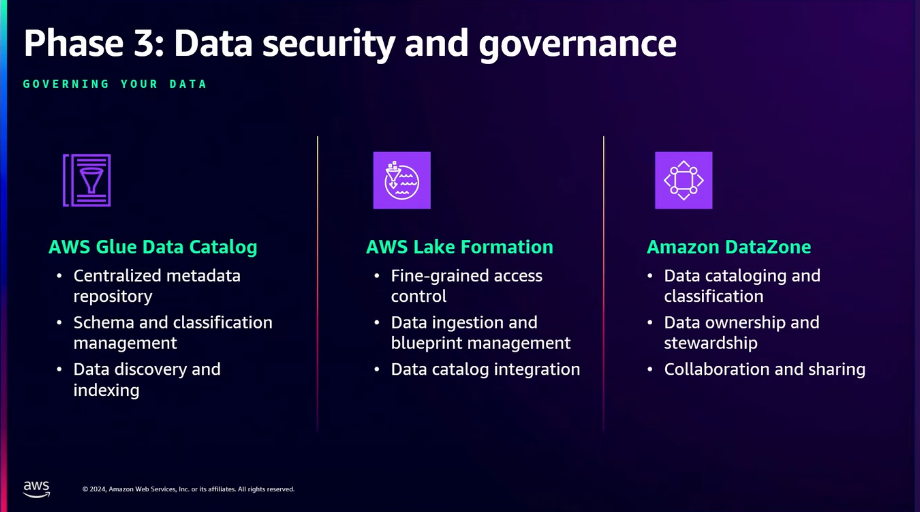
- AWS Glue Data Catalog
データスキーマとメタデータを一元的に管理し、データを分類・検索し、効率的なデータ探索をサポートします。 - AWS Lake Formation
細分化されたデータアクセス制御とデータ収集・管理の自動化により、データ保護とコンプライアンスを確保します。 - Amazon Datazone
データの所有権管理とチーム間のコラボレーションを強化し、データ使用の透明性と効率性の向上に貢献します。
これらのツールは、データ管理環境におけるセキュリティとガバナンスの信頼性を確保し、絶えず変化するデータ規制要件に対応できるようにします。
最後に、データレイクの持続可能な成長のための準備段階である「Preparing for sustainable growth」について説明します。
コスト管理と利用性の向上
データ管理とセキュリティが維持される中で、コストを効果的に管理し、データの利用性を最大化する戦略が必要です。Preparing for sustainable growthフェーズでは、データレイクの長期的なスケーラビリティとコスト効率をカバーします。
- ストレージコストの最適化
S3 Intelligent-Tieringを使用して、データ使用パターンに応じてストレージコストを最適化します。長期データをS3 GlacierとGlacier Deep Archiveに移行し、長期保管コストを削減します。Forever E commerceは、古い販売データをGlacierに移行し、ストレージコストを30%以上削減しました。 - リアルタイムデータの活用
AWS Athenaを活用してリアルタイムのクエリと分析を行い、データの活用性を最大化します。クリックストリームデータの分析にAthenaを使用することで、人気商品をリアルタイムで把握し、プロモーション戦略を策定しました。 - チーム間のコラボレーションを強化する
GlueデータカタログとDataZoneを使用してデータ検索とコラボレーションの効率を高め、チーム間のコラボレーションを促進します。Forever Ecommerceは、チーム間のデータ共有時間を40%短縮しました。
まとめ
データレイクは現代のデータ管理において重要な役割を果たし、AWS S3と関連ツールを活用することで、拡張性とセキュリティを維持しながら効果的な運用環境を提供します。今回のセッションでは、データ管理と運営の重要性を深く理解することができ、特にデータアーキテクチャの設計とセキュリティとガバナンスの必要性を実感することができました。
単純なデータストレージを超えたデータレイクは、データを活用することで企業の競争力を高め、データ階層化と自動化された処理パイプラインはデータ分析を加速し、費用的にも効率性をもたらす点も印象的でした。
今回のセッションは、データ管理の技術的な側面だけでなく、データ中心の組織文化を構築し、データが単なる資産を超え、成長を導く核心要素になることを実感しました。
記事 │MEGAZONECLOUD Enterprise Managed Service Center (EMS) Cloud Engineer 6 Team ウォンミンジ
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び