MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #AIM322|Amazon QビジネスチャットAPIを安全に呼び出す方法を学ぶ
Build a gen AI app using custom data sources with Amazon Bedrock
セッション概要
- タイトル:Build a gen AI app using custom data sources with Amazon Bedrock
- 日付:2024年12月4日(水)
- Venue: Venetian | Level 3 | Murano 3201B
- スピーカー:
- Sandeep Singh(Senior Generative AI Data Scientist, Amazon Web Services)
- Isaac Privitera(Principal Data Scientist, Amazon)
- 業界:Cross-Industry Solutions
- 概要:Amazon Bedrockを使用して、高度なRetrieval Augmented Generation(RAG)アシスタントを構築する方法を学ぶことができます。RAGアシスタントは、LLMと外部知識検索機能を組み合わせて、正確で有益な回答を提供します。さまざまなデータソースを統合してアシスタントのナレッジベースを拡張し、ナレッジマネジメントパイプラインを効率的に実装する技術を習得し、ユーザーエクスペリエンスを向上させる正確で最新の回答を提供するRAGアシスタントを設計および展開する方法を学びます。
はじめに
AWSのBedrockとKnowledge Baseを活用し、企業データを基盤にした生成型AIアプリケーションを構築する方法について学ぶセッションに参加しました。 テーマ自体が実務に近い内容だったので、とても楽しみでした。
セッションでは大きく分けてRAGワークフローの構成とKnowledge Baseが提供する機能、そしてこれを基盤にチャットボットアシスタントを構築するデモを行いました。このセッションは、説明が詳しく、体系的で分かりやすかったです。 それぞれの内容を段階的に整理してみます。
Introduction to RAG Workflow
RAGワークフローは、データを効率的に処理し、生成型AIモデルを活用して適切な応答を生成するためのプロセスであり、一般的によく知られているパイプラインを説明します。
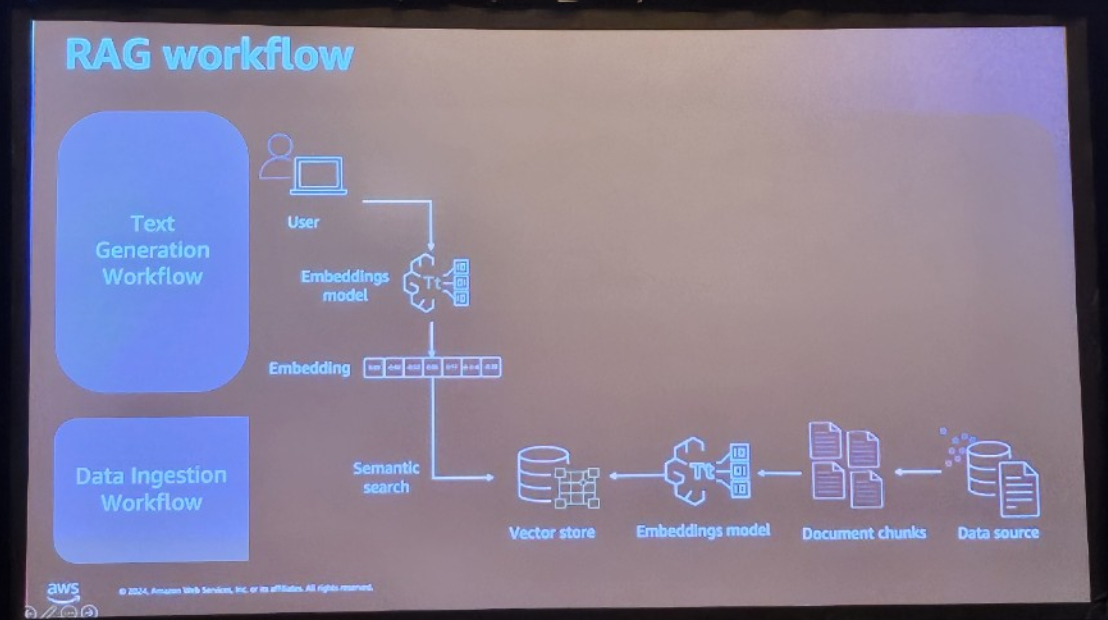
- Data Ingestion Workflow
Data Ingestion Workflowは、文字通りデータを準備するプロセスです。このプロセスは、RAGの基盤となるデータ構造を作成することが重要です。このステップは、その後の検索とレスポンス生成プロセスを円滑にするための基礎となります。
1)S3、Salesforceなど、さまざまなデータソースからデータをインポートし、
2)文書を分割し
3)エンベデッドモデルを使用してベクターに変換します
4)ベクターストアに保存します
- Text Generation Workflow
Text Generation Workflowは、ユーザーのクエリに基づいて応答を生成するパイプラインです。
1)ユーザーが自然言語クエリを入力すると
2)エンベデッドモデルを通じてベクトル化され
3)このベクターをベクターストアで検索します
ユーザーのクエリが入ったら、Data Ingestion Workflowを通じて保存されたベクターDBからクエリベクターの値を検索し、回答を見つけるパイプラインが全体的なRAGパイプラインです。
Amazon Bedrock Knowledge base
Amazon Bedrock の Knowledge Base は、個人データを使用して Foudation Model レスポンスをカスタマイズすることで RAG アプリケーションを迅速に構築できるサービスです。
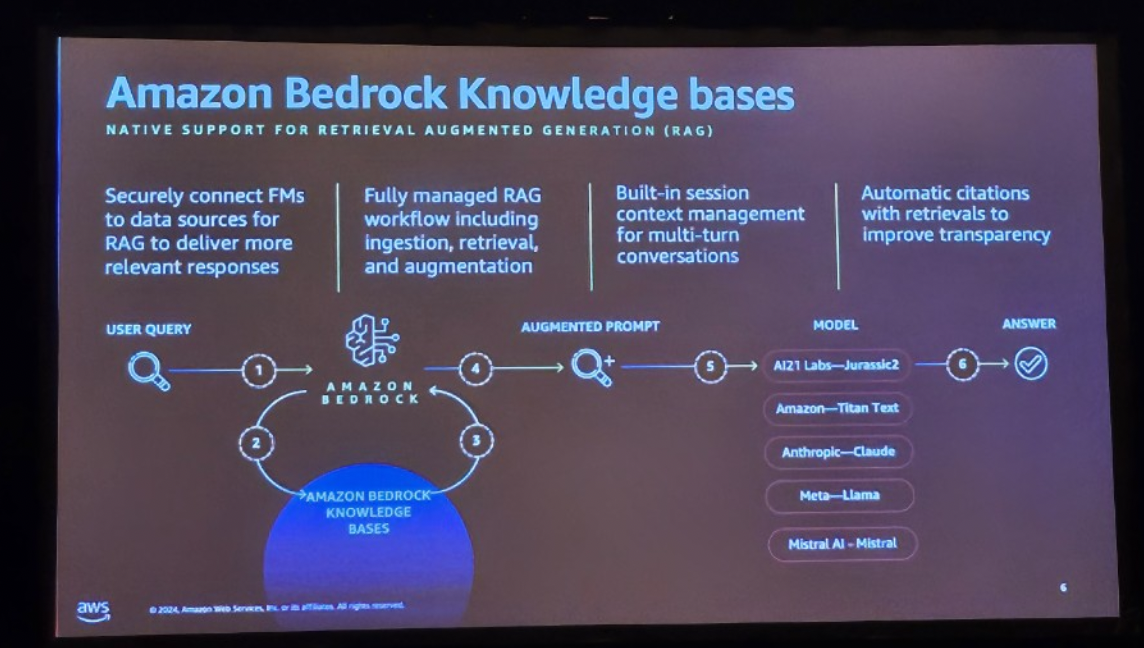
1. 安全なデータソース接続
Knowledge Baseは、組織のデータソースと生成されたAIモデルを安全に接続し、RAGワークフローがより関連性の高い応答を提供できるようにします。データソースとの接続はセキュリティを確保し、組織データを外部に漏らすことなく内部でのみ処理します。これにより、機密データを保護しながら、AIモデルは正確でコンテキストに対応する応答を生成できます。
2. 完全管理型RAGワークフロー
Knowledge Baseは、RAGアプリケーション開発プロセスの複雑さを軽減するために、完全に管理されたパイプラインを提供します。データ収集(Ingestion)、検索(Retrieval)、およびプロンプトの拡張(Augmentation)まで、すべてのプロセスを自動化します。ユーザーはこれらのプロセスを技術的な複雑さなしに迅速に実装することができ、開発時間を大幅に短縮できます。
3. 会話のためのセッション管理
Knowledge Baseには、マルチターン会話をサポートするセッション管理機能が組み込まれています。
ユーザーが以前に入力した会話の内容を記憶し、それに基づいてより自然で連続的な会話体験を提供します。
4.透明性を向上させるための自動引用機能
Knowledge Baseは、検索されたデータのソースを自動的に引用し、応答の信頼性と透明性を高めます。ユーザーは、生成された応答がどのデータに由来するかを明確に確認できます。この機能は、RAG応答に対する信頼性を確保するために重要な役割を果たします。
How to make a Knowledge base?
Amazon Bedrock で Knowledge base を作成する方法を紹介します。
- ソースデータを選択します。ソースデータはS3にあるデータにもなりますが、SalesforceやConfluenceなどにあるデータもソースとして選択できます。
- データのチャンキンググローバルを選択します。チャンキングを行わないことも、サポートされているChunking戦略を使用することも、カスタマイズされたチャンキング戦略を使用することもできます。
- Embedding ModelとVector DBを選択して作成します。

このような単純な Knowledge Base は metadata と incremental update をサポートします。
- メタデータ(フィルタリング、ランキング、セグメンテーションなど)を活用すると、検索結果の精度を向上させることができます。
- Incremental update(増分更新)がサポートされているため、定期的に更新されたり頻繁に更新されたりするデータについて心配する必要はありません。
RetrieveAndGenerate API
前に紹介した方法で knowledge base を作成すると、既存の RAG Workflow で「data ingestion」と「text genertion」に分離されたパーツを 1 つの「Fully manager RAG」パイプラインに簡素化できます。
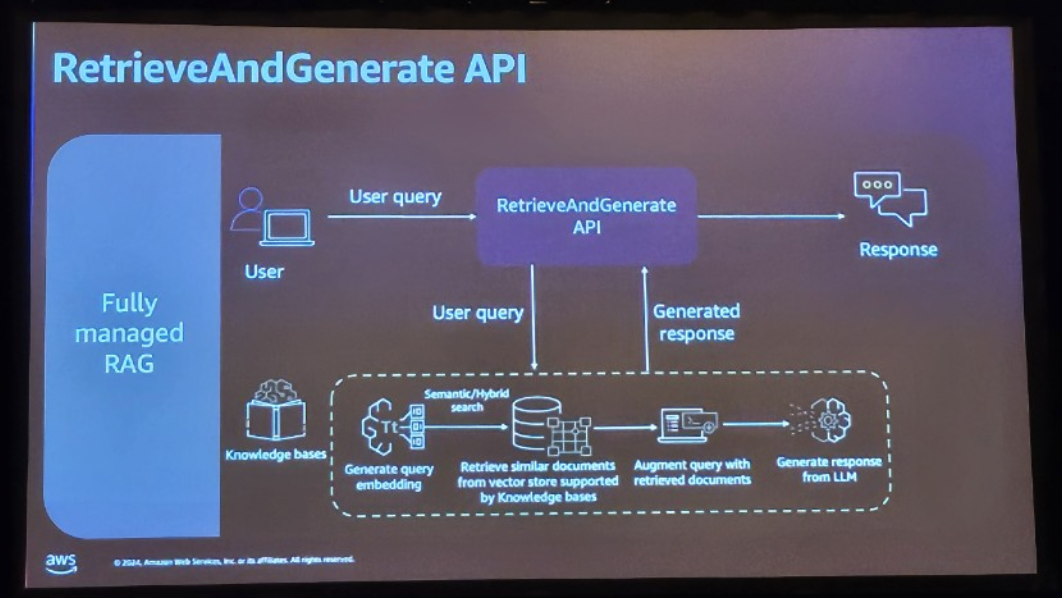
- ユーザーがクエリを発したとき
- RAG API を介して Knowledge base にクエリー Query を渡します。
- この時点で、Knowledge baseは作成時に選択したEmbedding ModelにQueryを埋め込みます。
- 埋め込みプロセスのためにベクトル化されたクエリをSemantic/Hybrid Searchを介してVector Storeからリトリーブします。
- Retrieveされた文書に基づいてAugmented Queryを行い、
- LLM を介して応答を生成し、RAG API を介して転送します。
Structured Data Retrieval – (Newly Announced in re:Invent 2024)
今回の2024 re:Inventで新たにAnnounceされた機能により、非定型データだけでなく整形データの検索が可能になりました。
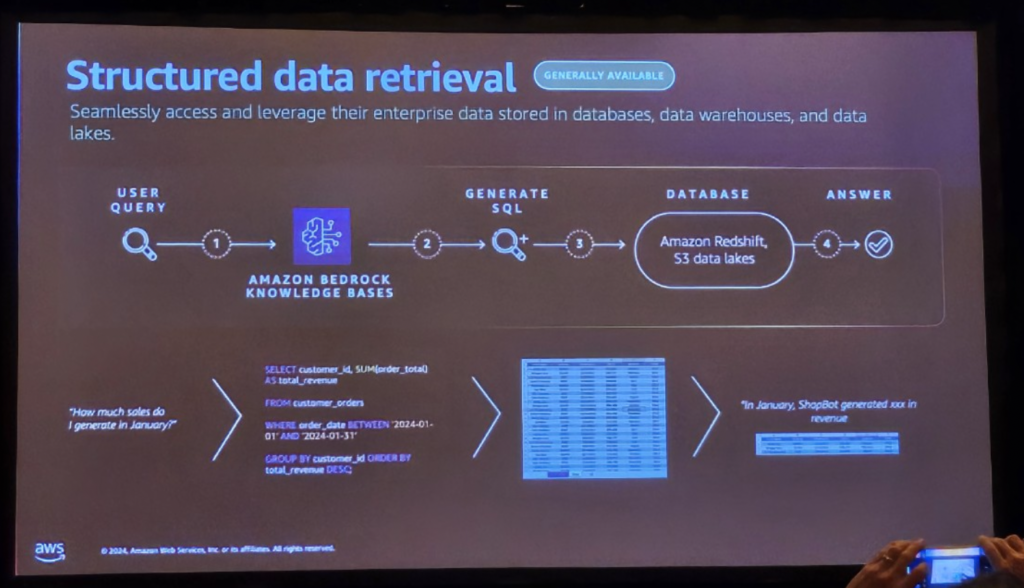
この機能は、DWとデータレイクの自然言語クエリをサポートするための知識ベースを拡張し、アプリケーションがインタラクティブインターフェースを介してビジネスインテリジェンス(BI)にアクセスし、重要なエンタープライズデータを含む応答の精度を向上させることができます。
Re-ranking – ( Newly Announced in re:Invent 2024 )
今回の2024 re:Inventで新たにAnnounceされた機能で、RAGアプリケーションの精度を向上させるためにRe-rank APIをサポートします。

Knowledge Baseで検索された結果をそのまま使用すると、ユーザーの質問に関連性の低い文書が上位にある可能性があります。より正確なコンテキストに基づいて回答を生成できます。
Implicit Filters – ( 2024.04 Newly Announced )
Implicit metadata filteringは、ユーザーのクエリと事前定義されたmetadata Schemaに基づいて自動的にフィルタを生成し、検索結果の関連性を高め、精度を向上させる機能です。

この機能は、メタデータフィールドと値を分析してフィルタを生成し、手動フィルタリングの必要性を減らし、クエリ処理効率を向上させます。
Streaming API– ( Newly Announced in re:Invent 2024 )
Amazon Bedrock Knowledge Bases は RetrieveAndGenerateStream というストリーミング API をサポートするようになりました。この新機能は、応答全体が生成されるのを待たずに、応答が生成されると同時にLLMからリアルタイムで応答を受信できるようにします。

デモ
理論の説明後のデモは、以下のアーキテクチャに基づいています。デモの内容は次のとおりです。
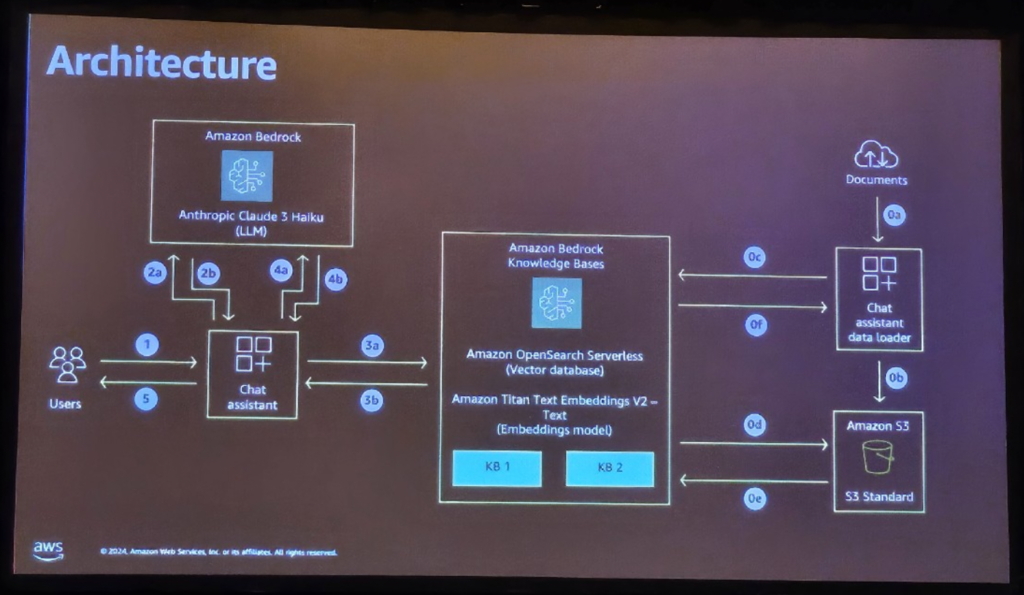
1.デモの主な機能
1) スマートルーティングシステム
- ユーザーが質問をすると、AIは自動的に質問の種類を把握します
- コード関連の質問なのか、一般文書に関する質問なのかを区別
2) 2 つの Knowledge Base
- コードナレッジベース:プログラミング、開発関連情報
- ドキュメントナレッジベース:一般的な説明、ポリシー、ガイドラインなど
2. 仕組み
1) ユーザー質問の入力
- 例:「Pythonでファイルを読み取るには?」
2) AIルータの解析
- Claude AIが質問を分析し、適切なカテゴリに分類
3) Knowledge Base 検索
- 分類されたカテゴリに合ったKnowledge Baseで関連情報を検索する
4) 回答の生成
- 見つけた情報に基づいて詳細な回答を提供
3. 使用例
👤 ユーザー: 「WS Lambda関数を作る方法が知りたいです」
🤖システム:[コードKnowledge Baseにルーティング] → コード例と一緒に詳細な説明を提供します
👤ユーザー:「AWSの料金プランはどうなりますか?」
🤖システム: [ドキュメントKnowledge Baseへのルーティング] → 料金規定に関連する情報を提供します
まとめ
今回のセッションでは、Amazon Bedrock Knowledge Basesの重要な機能と、それを活用したRAGワークフローの全体的な構造について深く学びました。特に、Knowledge Baseの実習を通じて直接データを処理し、クエリとレスポンス生成過程をリアルタイムで体験することができ、非常に有益でした。また、Bedrockに関連して発表された新しい新機能の紹介も興味深く、時間がすぐに過ぎたセッションでした。
記事 │MEGAZONECLOUD AI&Data Analytics Center(ADC) Data Architecture Team チョ・ミンギョンマネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び