MEGAZONEブログ

NEW! Google NEXT’25 <Breakout sessionレポート #BRK2-179>
AIが企業活動に広く浸透する今、「良質なデータ」が成功のカギを握っています。しかし、データがサイロ化し、ガバナンスや活用が難しくなっている企業も少なくありません。
そんな中、Google CloudはLakehouseアーキテクチャを通じて「AIに使えるデータ基盤」を整備するためのベストプラクティスを本セッションでデモを含めてお話しされておりました!
セッション概要
- タイトル
- Best practices for building a lakehouse on Google Cloud
- スピーカー
- Brad Miro
- Developer Advocate,Google Cloud
- Brad Miro
- 概要(公式)
- Google Cloud Next では、数多くの素晴らしい AI 機能が発表されています。これらの機能を最大限に活用するには、データが安全かつ一元的に管理されていることを確認する必要があります。この講演では、レイクハウスを設定して、下流のワークロード向けにデータを準備する方法を学びます。データの権限管理、メタデータ管理の設定、オープンソース フレームワークを使用した変換の実行など、Google Cloud プロダクトのアーキテクチャに関するデモもご覧いただけます。

まとめ
- BigQuery が「ガバナンス中心のLakehouseの司令塔」として進化中
- Apache Iceberg テーブルを BigQuery 上でフルマネージドで扱える新機能がPreview公開
- BigQuery から PySpark を直接実行できる「Serverless Spark in BigQuery」もPreview発表
- セキュアで統合的なデータ管理が、AI時代の“土台”になるというメッセージが強調
データの価値を最大化するには「Lakehouse × ガバナンス」が不可欠

AIを導入しても、信頼できる・整備されたデータがなければ意味がないという問題意識から、
Google CloudはLakehouseを「ガバナンスを前提としたアーキテクチャ」として位置付けている。
Lakehouseの目的は以下のように整理することができる
- Data Lakeの柔軟性 × Data Warehouseの分析力
- データサイロの解消:重複コピーを減らし、「単一コピーで全社活用」を目指す
- バッチ・ストリーム・マルチモーダルデータも含めて一元管理
BigQueryが“Lakehouseの中核”へ進化

BigQueryはもはやデータウェアハウスではなく、「Lakehouseの統合基盤」として活用が広がっています。
- 構造化・非構造化データを一元的に管理
- KafkaやCloud Storageなどの外部データもBigQuery経由で扱える
- LookerによるBIダッシュボード連携、Vertex AIによるML連携も可能
また、メタデータの可視化やカラム単位のアクセス制御(Policy Tags)など、
セキュアで使いやすいガバナンス機能が多数組み込まれている点も大きな特徴。
NEW! BigQueryでApache Icebergテーブルをフルマネージド運用(Preview)

従来Iceberg テーブルは自己管理が前提でしたが、今回発表された新機能では以下が可能になります
- Cloud Storage上のIcebergテーブルを、BigQueryが直接書き込み・管理可能
- ストリーミング・クエリの高速化、自動最適化、高スループット対応(最大GB/秒単位)
- ファイングレイン(列単位)アクセス制御、堅牢なリカバリ機構にも対応
これにより、オープンフォーマット × エンタープライズ向けの操作性を両立できるようになりました。
NEW! BigQuery上でPySparkを動かせる「Serverless Spark in BigQuery」(Preview)
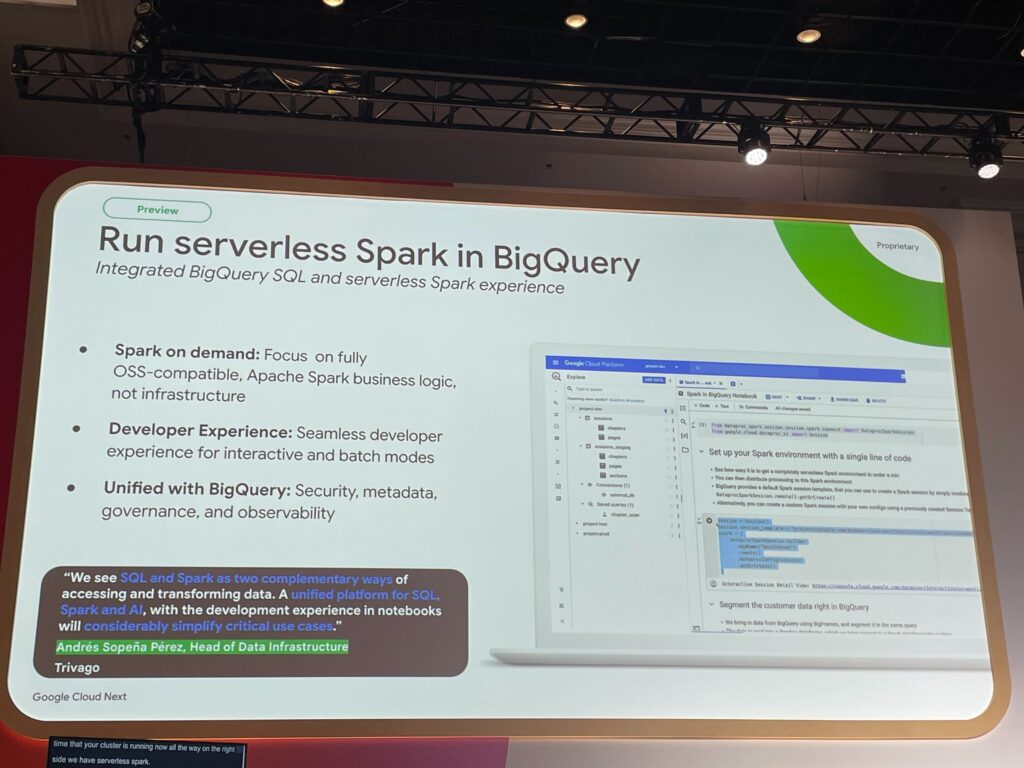
さらに、BigQuery Studioで直接PySparkノートブックを実行できる新機能のPreview発表です!
- Dataproc Serverless Sparkと連携した完全マネージドSparkセッション
- BigQueryメタストアを通じてSparkとBigQuery間で双方向にデータ共有
- GeminiによるSparkコード自動生成にも対応
これにより、SQLだけでなくPython/Sparkによる柔軟なデータ処理・MLモデリングが
1つの環境で完結できるようになります。
他にも紹介された実践的機能・サービス
ストリーミング処理とETL
- Dataflow(Apache Beamベース):テンプレートによるノーコード連携、リアルタイムML対応
- Kafkaマネージドサービス:Pub/Subとの連携で低遅延処理
オーケストレーションTool
- Cloud Composer(Apache Airflowベース)
- Google Workflows(YAMLでAPI制御)
- Cloud Scheduler(cron代替)
- BigQuery Scheduled Queries:SQLクエリの定期実行
データガバナンス
- データプロファイル生成:分布、NULL率、外れ値検知など
- リネージ機能:どのデータがどこから来て、どこで使われているかを可視化
- データ品質ルール設定:しきい値や値の妥当性チェック

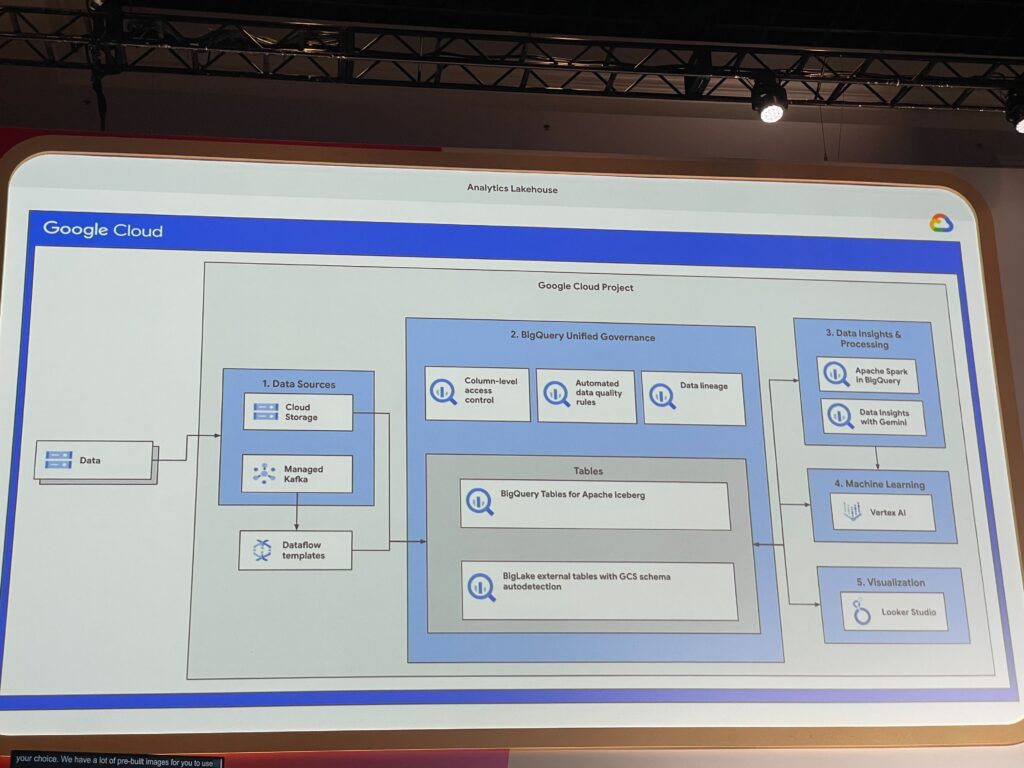
デモ構成:これが“理想的Lakehouse”の実像
セッション後半では、以下のようなLakehouse構成のライブデモが披露されました!
- Cloud Storage + Kafka → Dataflow → BigQuery(Icebergテーブル)
- BigQuery Policy Tags によるアクセス制限
- Geminiによるインサイト生成+SQL提案
- Lookerでのダッシュボード連携
- Vertex AI + Jupyter(Workbench)によるモデル開発
- PySparkノートブックをBigQuery Studioから直接実行(Preview)
AI活用を前提とした、非常にモダンで洗練されたアーキテクチャとなっており、
「データの信頼性と柔軟性を両立させる設計」として、勉強し始めてばかりの身としては非常に参考になる構成。
AI時代のデータ戦略は「Lakehouse+統合ガバナンス」で決まる
このセッションを通じて強調されたのは、データはもはや「蓄積するもの」ではなく、
「安全に、柔軟に、そして素早く使える状態にしておくこと」こそが価値につながるということかと思います。
Google CloudのLakehouse戦略は、BigQueryを中心に据え、信頼できるデータ活用基盤を一気通貫で実現するアプローチでまさにGoogleCloudここにあり!というGoogleNEXT’25の中でも一番勉強になったセッションでした!ここをもっと理解を深めたいなと思います。


