MEGAZONEブログ

クラウド運用をインテリジェントに自動化
クラウド運用をインテリジェントに自動化Intelligently automating cloud operations
Pulisher : Enterprise Managed Service Group ミン・ジホ
Description : AWSのAIOpsのリソースと機能についての紹介セッション
はじめに
今回のセッションを通じて、様々な事例とアーキテクチャを取得し、このセッションで選定してくれるAWSリソースを学習し、機能を選別して、運用の業務を改善したいと思っています。
セッションの概略紹介
Amazon Inspector、AWS Config、Service Quotas、AWS Health、AWS Well-Architected Tool、AWS Trusted Advisorを使用して、ベストプラクティス、セキュリティの結果、耐障害性、パフォーマンスから洞察を得ることができます。 得られたデータインサイトについて議論した後、再現性のある自動化パイプラインを設定し、異常検知を使用してAWS Health Awareを使用してアカウント全体の自動化を推進する方法を確認するセッションです。

AIOpsサービスおよび代表的なサービスおよび機能として、以下の3つがあり、そのうちCloudWatch異常検知兆候機能は、選択した指標の記録値を分析し、時間、日または週単位で繰り返される予測可能なパターンを見つける機能です。
CloudWatch Alarm機能を使用して、いつもと違う値が見えた時、通知をすることができます。
1.Amazon Forecast
2.EC2 Auto Scaling Predictive Scaling
3.CloudWatch Anomaly Detection
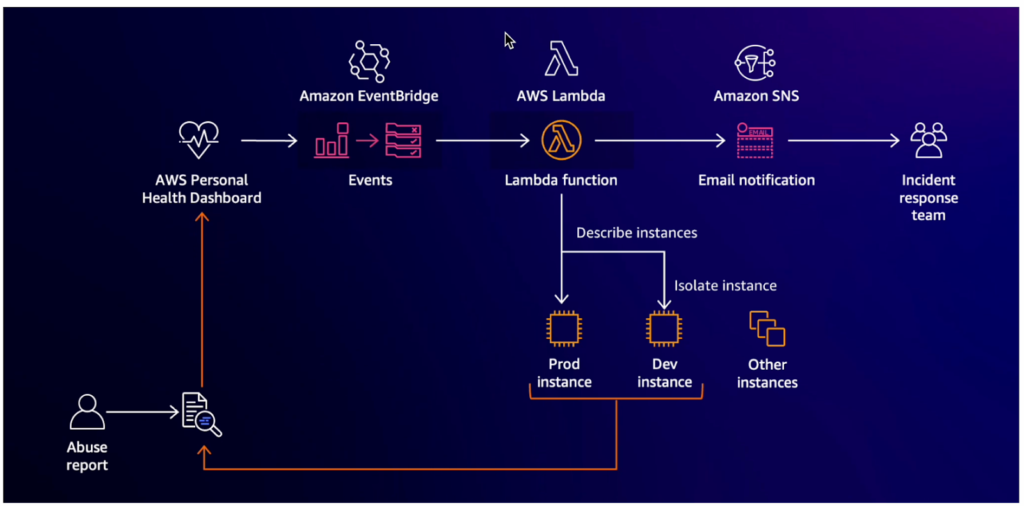
最初のシナリオとして、Abuseイベント発生時、そのイベントはAmazon Event Bridge、Lambda、SNSを経て運営担当者に伝達されるフローです。上記のように設定すると、EventBridgeのイベント検証を通じて様々なイベントの受信やアラームの送信を行うことができます。
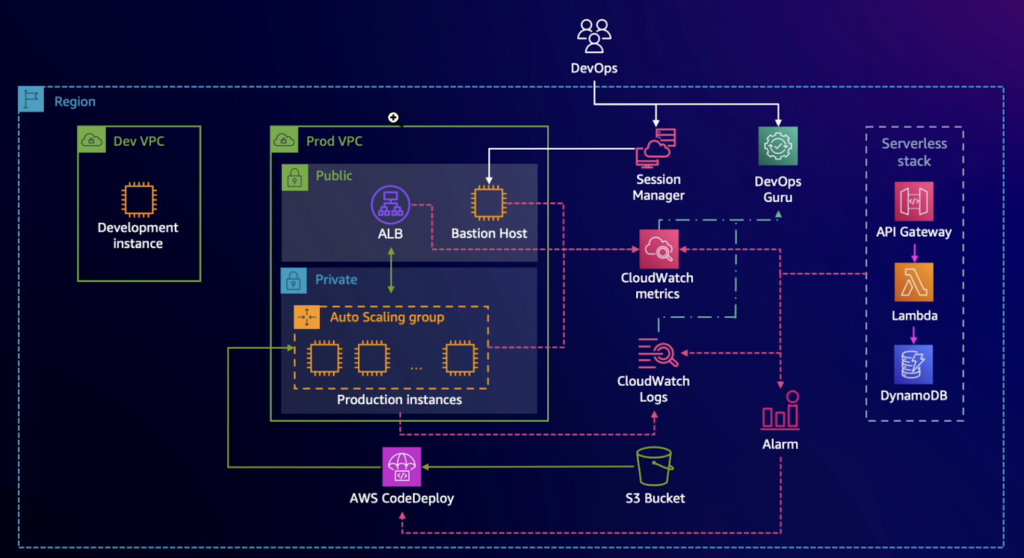
二つ目のシナリオは、CloudWatchのAnomaly Detection機能を有効にし、Codedeployのデプロイ時にAnomaly Detection機能を有効にした指標のアラーム発生時、ロールバックするシナリオです。
開発環境でECSを展開する時、正常かどうかを特定の指標(4xxエラー、5xxエラー)でアラーム発生時にロールバックするようにすると、開発者のテスト作業負荷を減らすことができると判断されます。
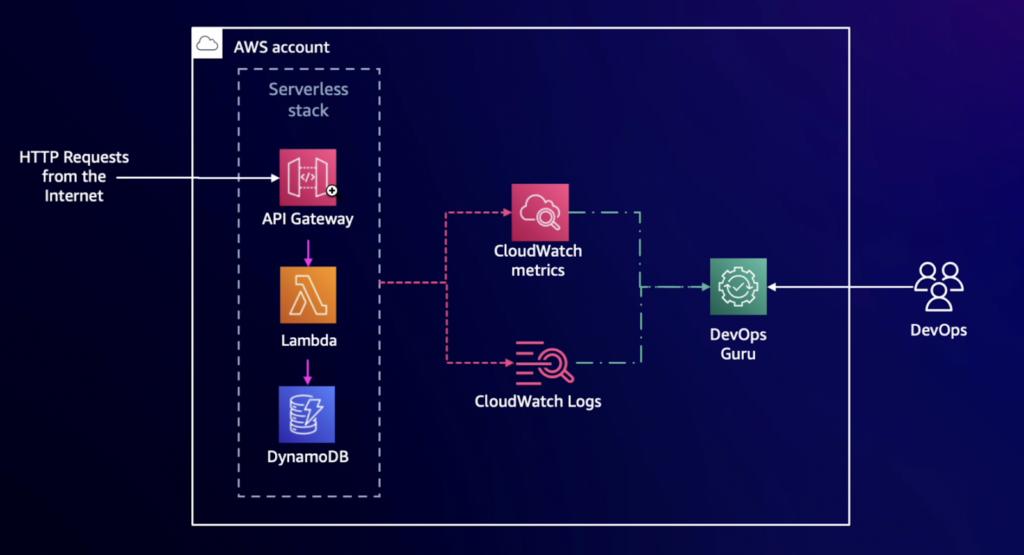
三つ目のシナリオで、AWS DevOps Guruサービスを有効にした時のメリットを見ることができるシナリオです。
上のアーキテクチャで、API GatewayへHTTPトラフィックが集中した時、アーキテクチャで発生する現象をAWS DevOps Guruではどのように提案し、どのようにトラブルシューティングをするかを見ることができます。
AWS DevOps Guruではどのように提案し、どのようにトラブルシューティングを支援するかを確認することができます。

青色は既存のCanaryResponseTime、CanaryResponseTime (expect) はCanaryResponseTime指標でAnamaly Detection機能を有効にした時に生成された指標です。
固定された値でしきい値を設定した場合、ビジネスによってトラフィックが大きくなったり小さくなったりするため、アラームの最適化をしなければならないオペレータの手間がありますが、この機能を使ってアラームの最適化作業を簡素化することができます。
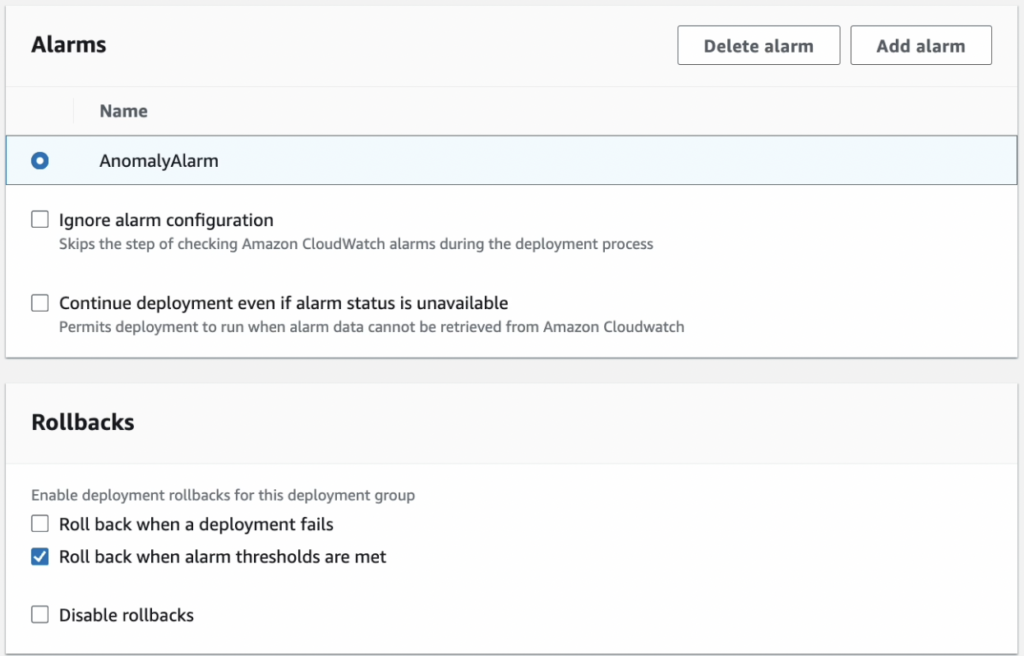
上の機能はCodeDeploy Rollbacks機能です。
Rollback基準でAIOps Anomaly Detectionアラームを生成する時便利だと思います。
Rollbackトリガーアラームでアプリケーション関連指標を全て設定しておけば、最小限の努力でモニタリング環境内で開発にもっと集中することができます。

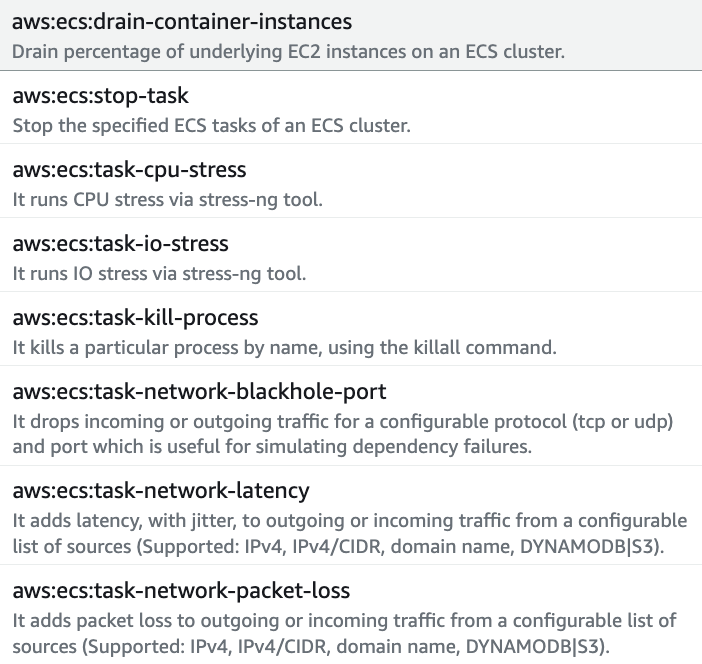
上の図はFIS Action Type別の発生状況を示しています。
AWS FIS(AWS Fault Injection Service)はAWSワークロードに対する障害注入実験を行うことができる管理型サービスです。何らかのインシデントが発生した場合に備えて、オペレータはその対応をするためにアーキテクチャを構築し、自分なりの方法でテストまで行います。
しかし、インシデントはテストの隙を突いてオペレータを苦しめます。テストを進めることができるFISを使えば、より正確なテスト環境を作ることができます。
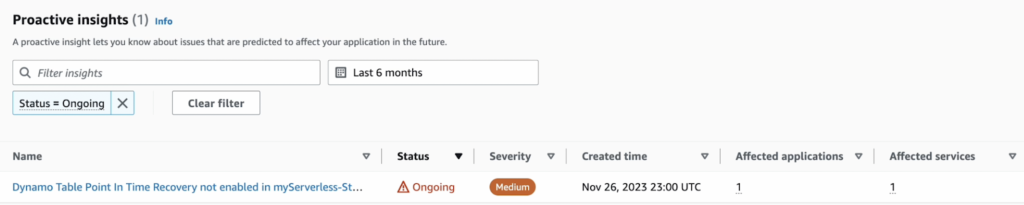

DevOps Guruのサービス機能であるProactive Insightsを説明するための図です。
AWS DevOps Guruは活性化されたAWSリソースを基準に「Proactive Insight」を提供します。
Proactive Insightsとは、リソースに問題が発生する部分を事前に確認して運営担当者に伝達する機能です。上記の機能を通じて、運営担当者は現インフラストラクチャに対して不足している部分を確認し、補完するためのガイドも提供します。
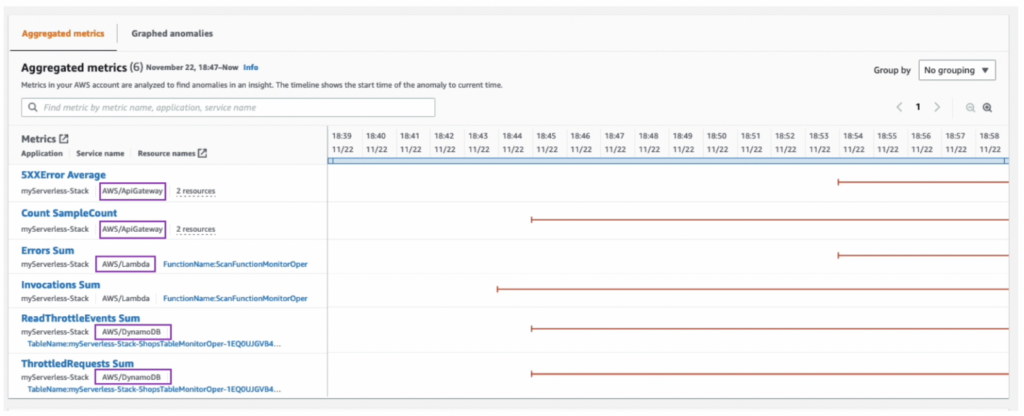
DevOps Guruのサービス機能であるAggregated metricsです。
インシデントが発生した時、異常現象が発生したメトリックを時間帯別に一覧表示します。
上記のメトリクスにより、根本原因を探す時間を短縮することができ、影響度の把握にも役立ちます。
セッションを終えて
AIOpsのリソースと機能について見てきました。
オペレータが見逃していた管理ポイントをAIが見つけてガイドしてくれるので、より堅固な運営ができそうです。
また、AIが運用担当者を置き換えることはできないと思いました。 その理由としては、顧客の商業イベントをAIは過去のデータから現在のインフラに問題があると判断するでしょうし、オペレータはその内容を知っているので問題だと判断しないでしょう。
結局、AIとオペレーターが互いに置き換えずに共存した状態で運営をすれば、より完璧な運営ができると思います。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner