MEGAZONEブログ

Amazon Aurora HA and DR design patterns for global resilience
グローバルな耐障害性を実現するAmazon Aurora HAとDRのデザインパターン
Pulisher : Managed & Support Center ムン・ボンギ
Description : Amazon Aurora RDSのHAとDRの構築パターンを学ぶセッション
はじめに
Amazon Aurora RDSのHAとDRの構築パターンを知り、実務でAurora RDSを構成する際、国内およびグローバルサービスに適用できるかどうかを検討して構築パターンを学習するためにセッションを申し込みました。
セッションの概要紹介
このセッションでは、高可用性とディザスタリカバリパターンを使用してシステムをより弾力性のあるものにする方法を学びます。

弾力性とは、ワークロードがインフラストラクチャやサービスの中断から回復する能力であり、負荷に応じてリソースを動的に拡張および縮小し、ネットワークの問題などで発生する中断を緩和する能力です。 これは、可用性と災害復旧という2つの柱によってサポートされます。

可用性は、ワークロードが利用可能な時間の割合です。これは一定期間の測定値であり、ここで測定している時間のうち99.99%の可用性があります。システムに冗長性を追加することは、単一障害点を排除し、可用性を向上させる強力な方法です。

・災害復旧は、災害事象、特に単一の災害事象に対処するための技術と戦略です。
・RTO(リカバリ時間目標)は、一つのイベントの最大持続時間を表します。この時間中に発生するダウンタイムとして理解することができます。
・RPO(リカバリポイント目標) 許容可能な最大データ損失量を表します。これは通常、時間単位で測定され、例えば、インシデント後の最後の1分間のデータ損失を許容できると言えます。これは主に非同期技術を使用し、レプリケーションの遅延が発生する場合です。
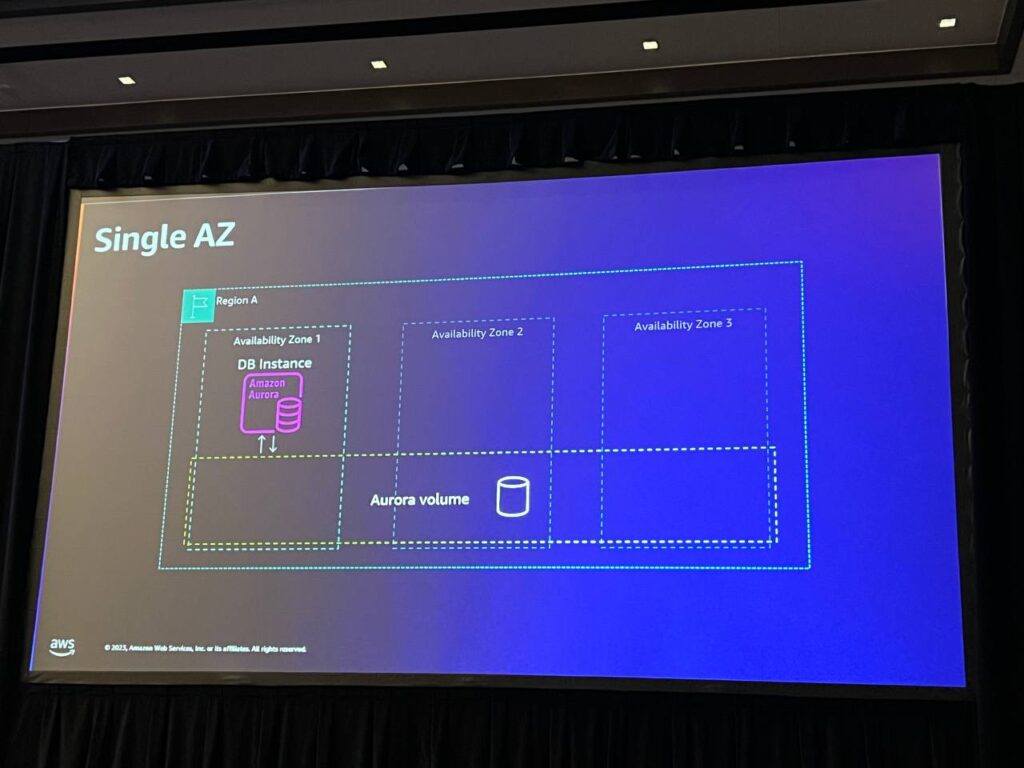
Single AZ設計パターンは、可用性領域1に1つのデータベースインスタンスがあります。これにより、コストとパフォーマンス、可用性のバランスが取れます。このインスタンスは、クエリの処理とバッファプールが行われる場所であり、ここにはデータが保存されていません。 Auroraは、ストレージをAuroraボリュームと呼ばれる抽象化で分離します。
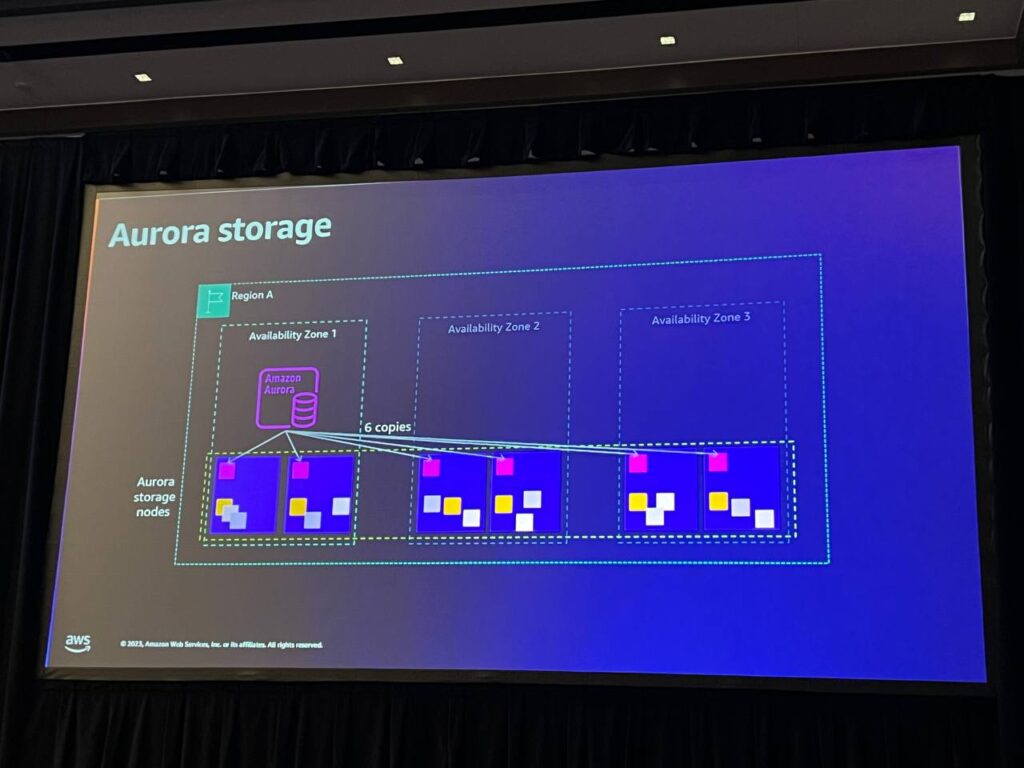
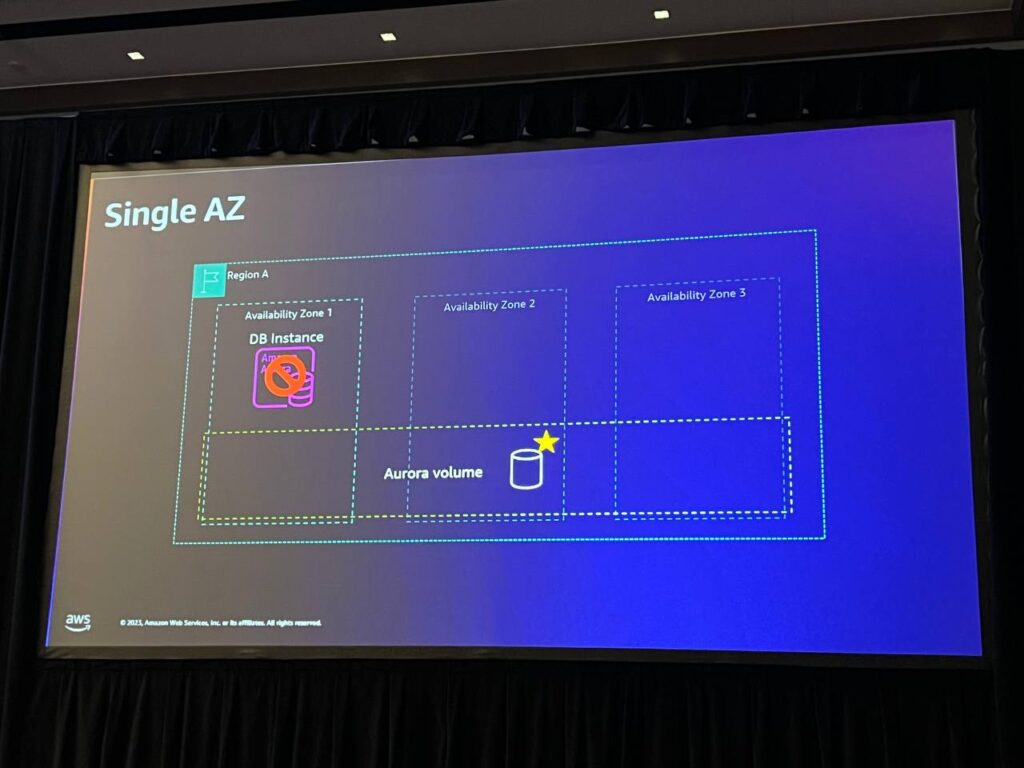
Auroraは3つのAZでデータベースの耐久性を提供し、Single AZパターンを使用します。この設計は、コストとパフォーマンスのバランスを提供し、データベースが必要に応じて最大128テラバイトまで柔軟にサイズを調整することができます。
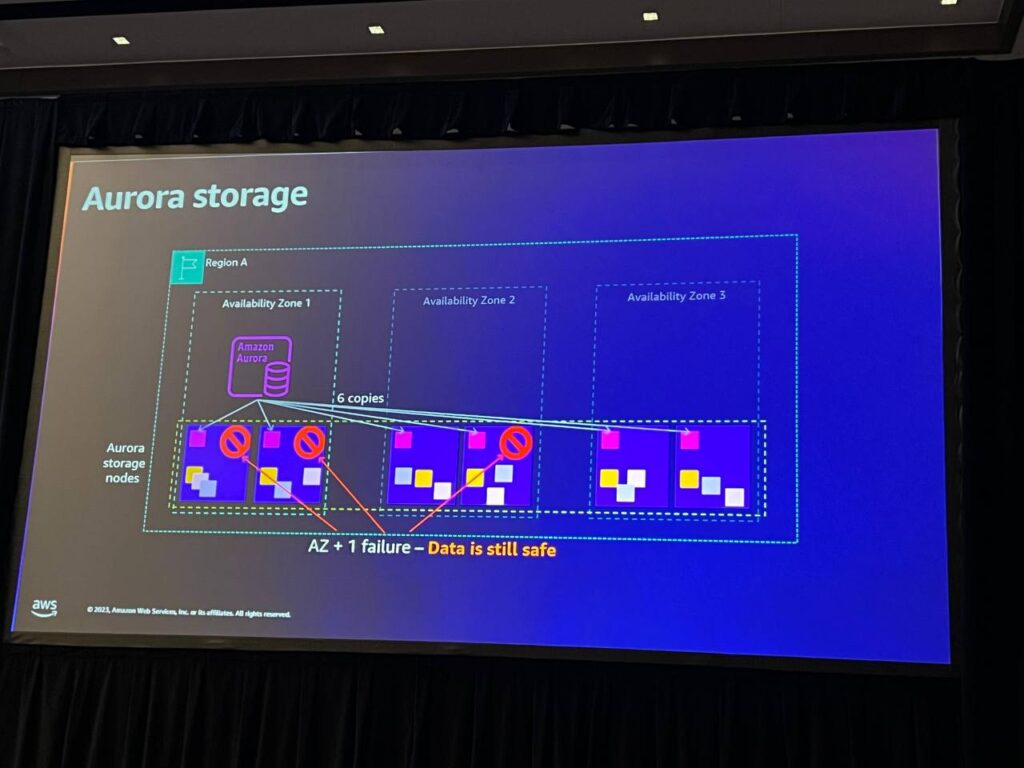
1つのインスタンスが使用できなくなると、システムは使用できなくなりますが、データは耐久性を維持し、Auroraストレージに保存されます。ストレージは複数の専用ストレージノードで構成され、暗号化されたデータを6つのコピーに分散し、3つの可用性領域にわたって安定したパフォーマンスを提供します。
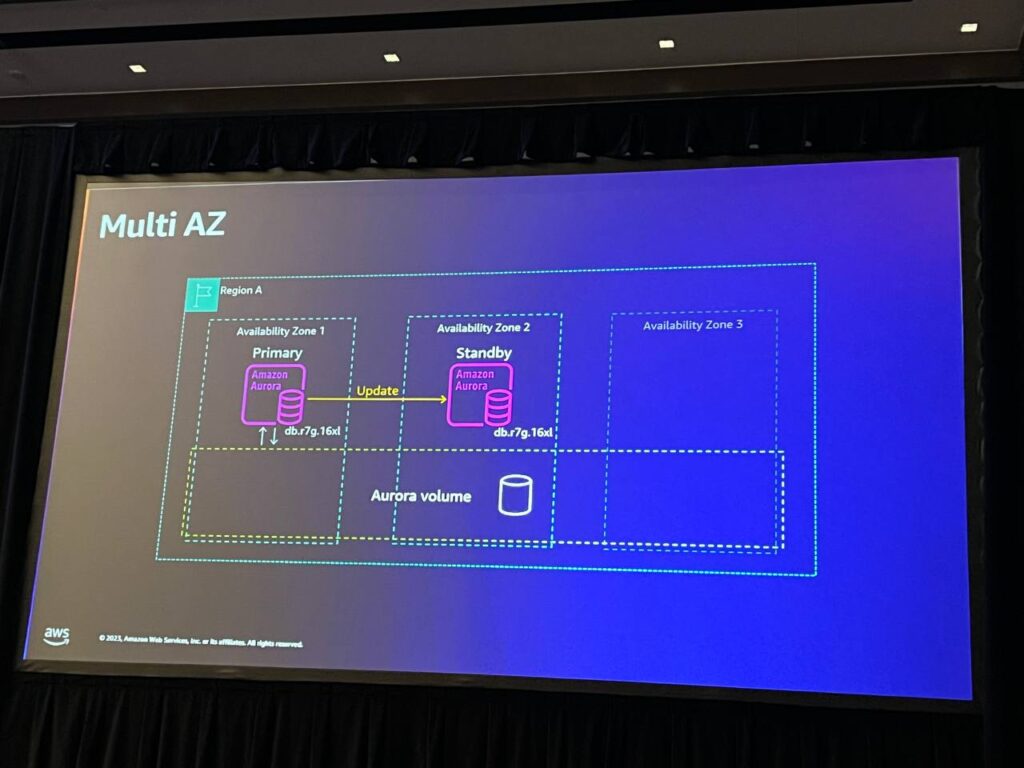
Multi-AZパターンは、別のデータベースインスタンスを展開し、第2の可用性ゾーンに配置することで可用性を向上させます。 そして、共有ロールストレージにアクセスすることができます。ここにはストレージがないため、データの複製はありません。 これは「Auroraクラスター」と呼ばれるものです。
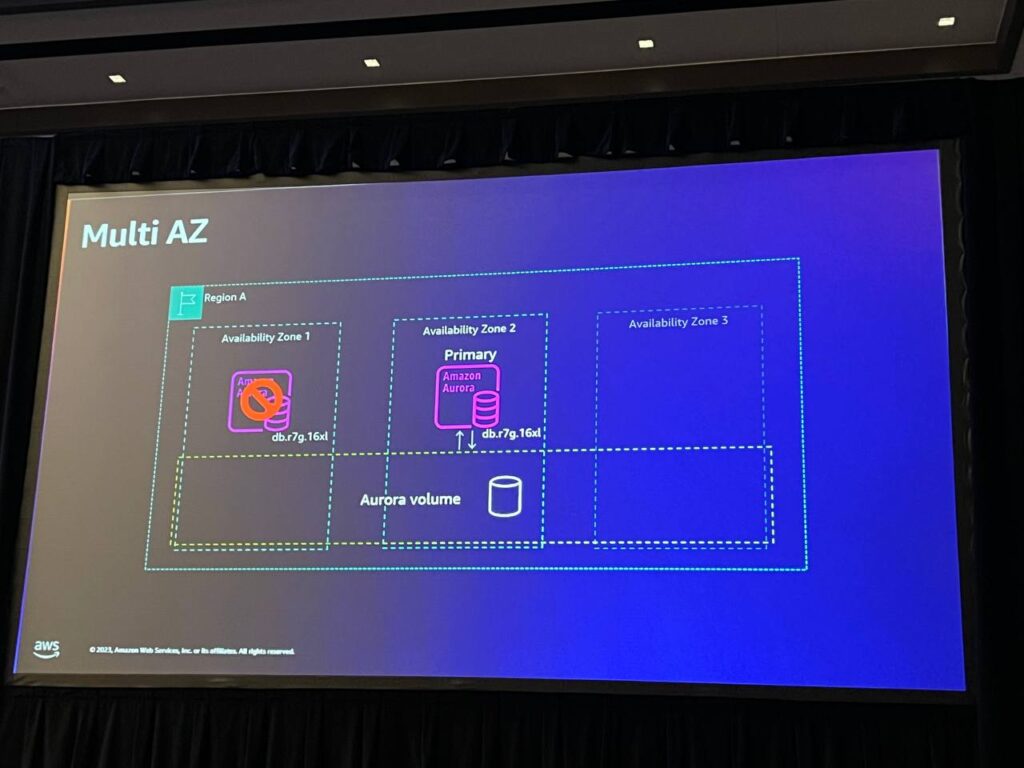
障害が発生した場合、最初のノードに障害が発生すると、スタンバイノードがメインノードに昇格し、同じAuroraストレージに接続します。この切り替えは非常に迅速に行われ、60秒未満で復旧することができます。ここでは、RPO(リカバリポイント目標)に関する会話はありません。 同じストレージです。影響を受けるのはトランザクションのみです。
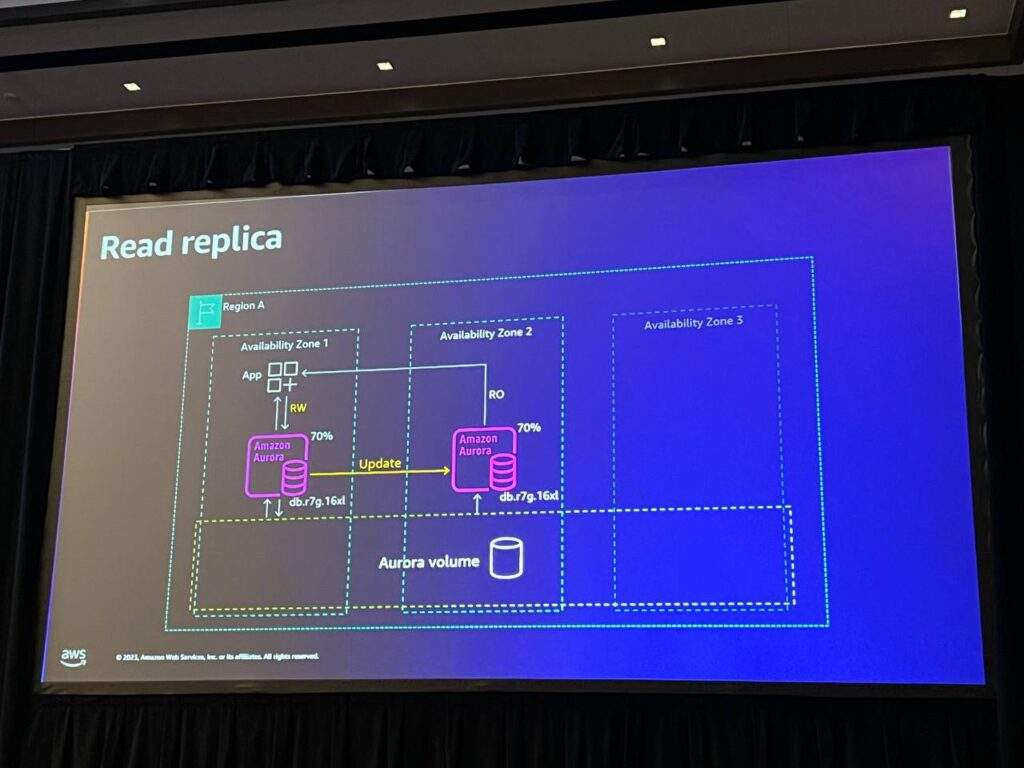
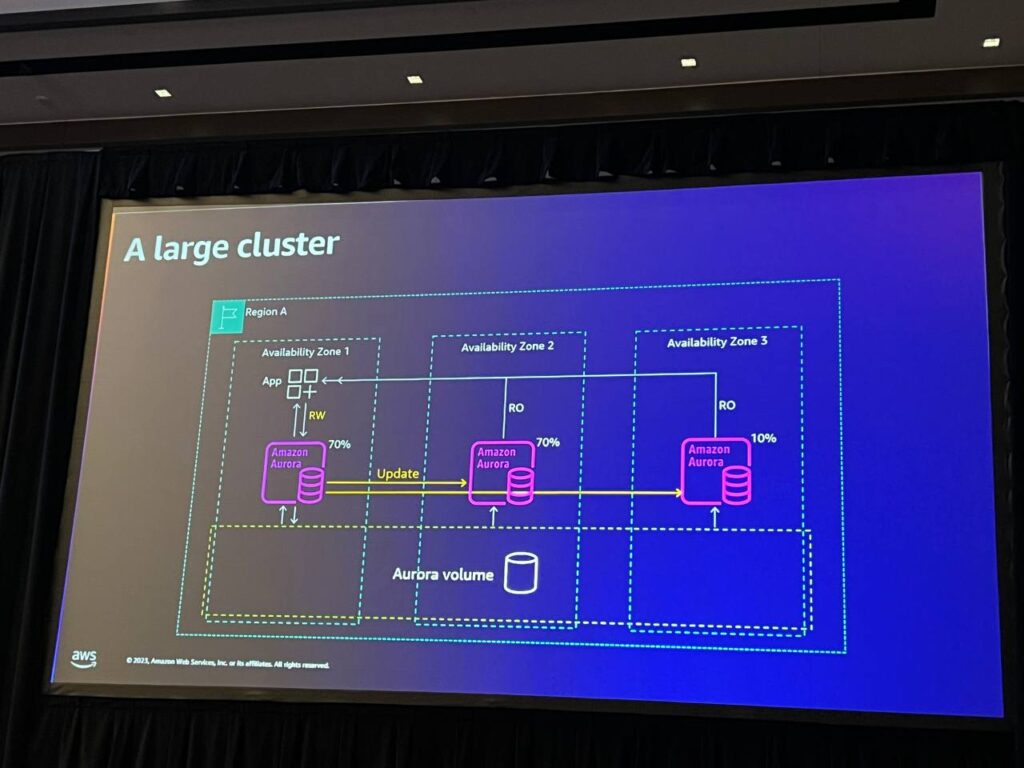
Auroraでは、別途の措置が必要なく、2番目のノードで読み取り専用クエリを実行することができます。 そのため、アプリケーションを再設定してROノードに接続すれば、読み取り専用クエリのみを実行することができます。従来記録していた読み取りクエリをRWノードからROノードに移し、処理するRWノードに余裕を与えます。 それでも更新リンクは維持され、2つのノード間の遅延は非常に低いです。
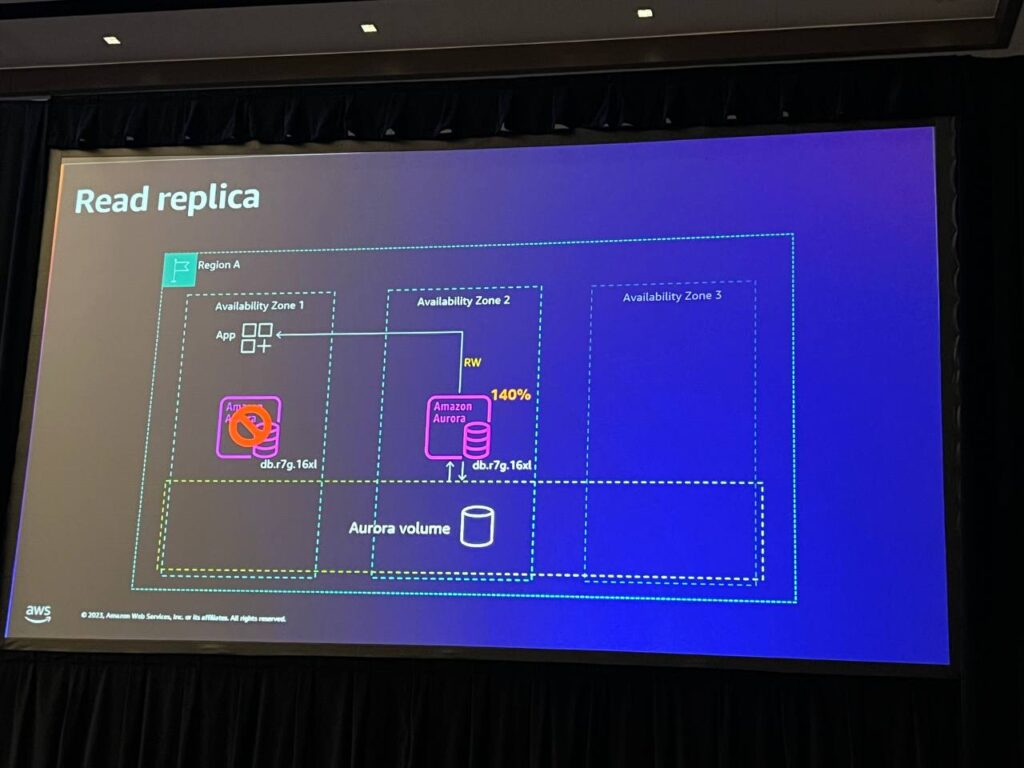
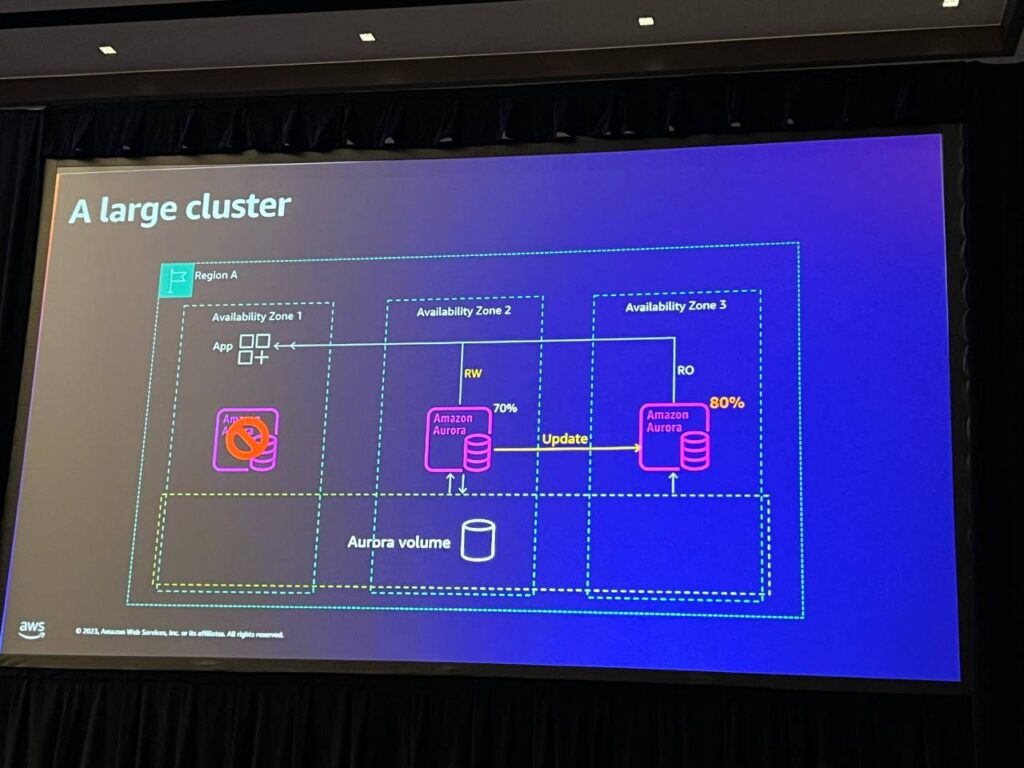
そして、2つのノードには負荷が70%なので余裕があります。 しかし、RWノードが故障した今、決済をしようとすると、残りの1つのノードに140%の負荷があり、これに対して何か対策を講じる必要があります。 この場合、3番目のノードを追加して可用性をさらに向上させました。 最初のノードが使用不可能になった場合、残りの2つのノードとも100%未満になります。 したがって、私たちは安全であり、可用性やパフォーマンスの問題は発生しません。
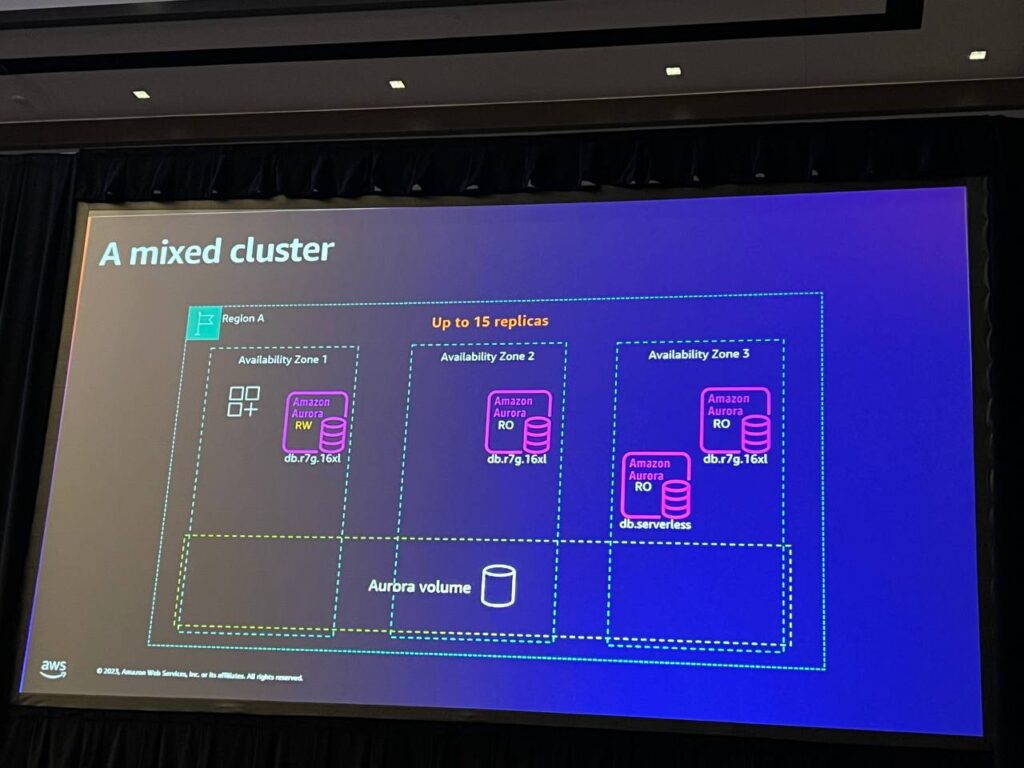
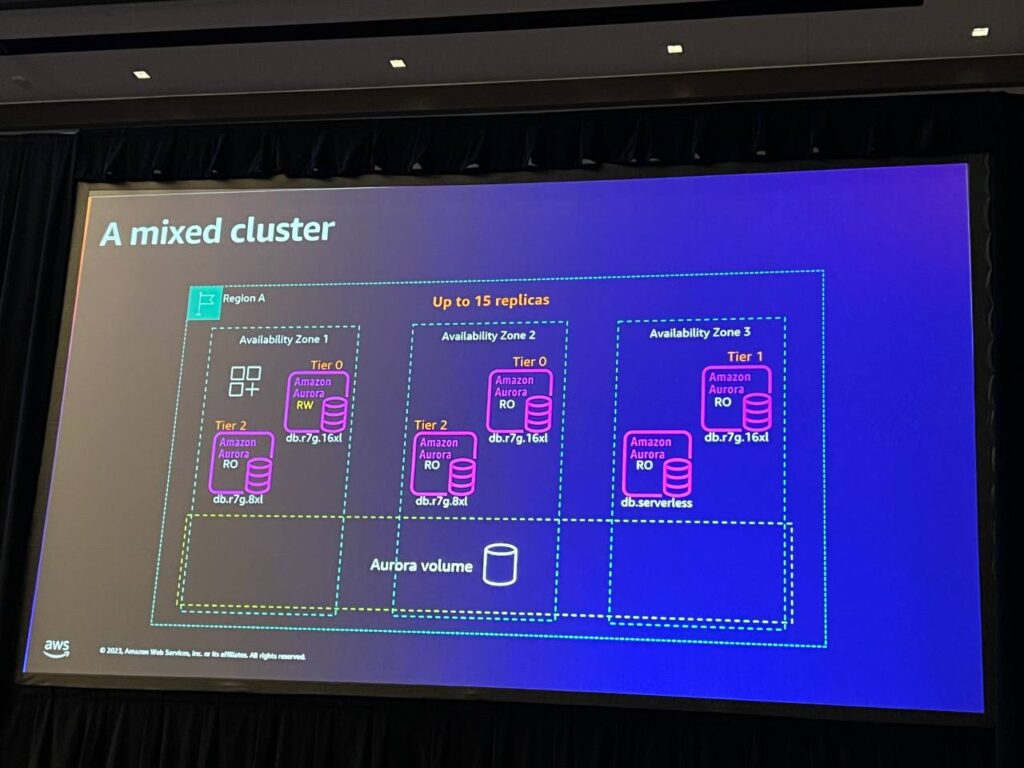
パフォーマンスをさらに拡張したい場合は、必要に応じて最大15個のレプリカを追加することができます。異なるサイズのレプリカを柔軟に調整したり、自動的に負荷を調整するserverlessなレプリカを追加したり、コスト管理のために小さなレプリカを追加することができます。インスタンスサイズはいつでも変更可能で、古いインスタンスを終了して新しいインスタンスを展開することで簡単に管理することができます。 ただし、障害復旧の順序を定義するために、ティアレベルを設定して各インスタンス間の優先順位を区別します。
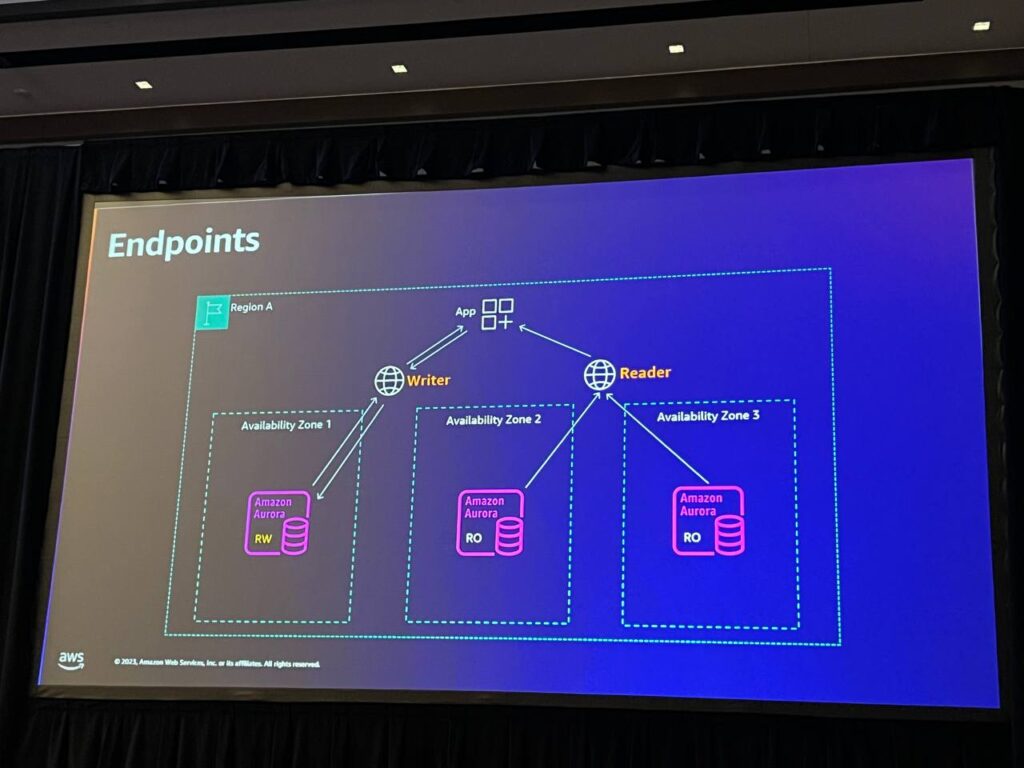
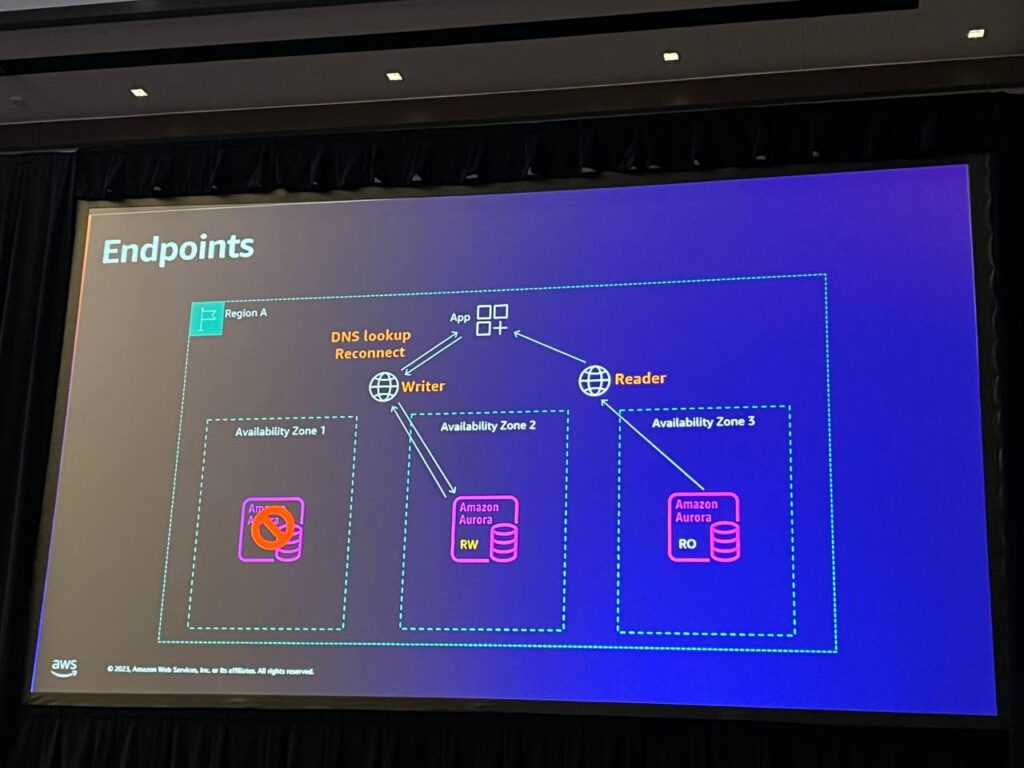
Endpointは基本的に2つのEndpointがあります。まず、クラスターEndpointまたはライターEndpointと、すべてのリーダーノードを代表するリーダーEndpointがあります。これらは単なる2つのDNS名であり、アプリケーションをEndpoint名で接続すると、Auroraが内部で何が起こるかを管理します。
再接続し、DNS TTLが適用されるのを待つだけで、新しいノードを取得することができます。 また、カスタムエンドポイントを作成することもできます。2つに限らず、必要に応じていくつかのノードをグループ化し、バックエンド処理Endpointなどとして指定することができます。
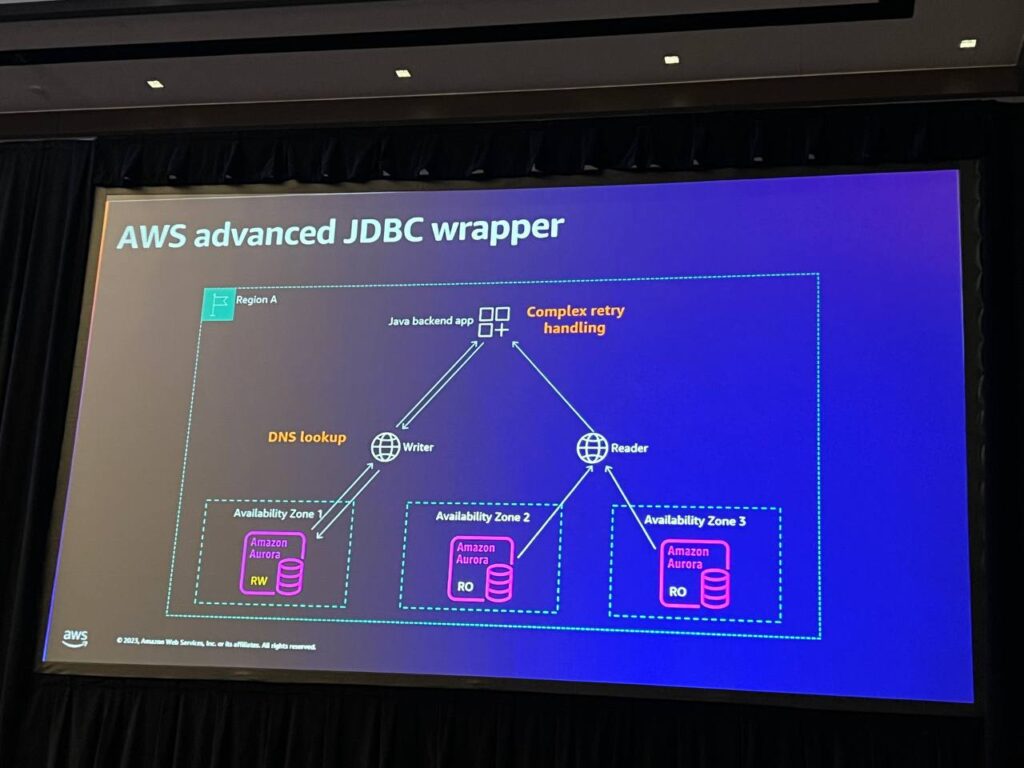
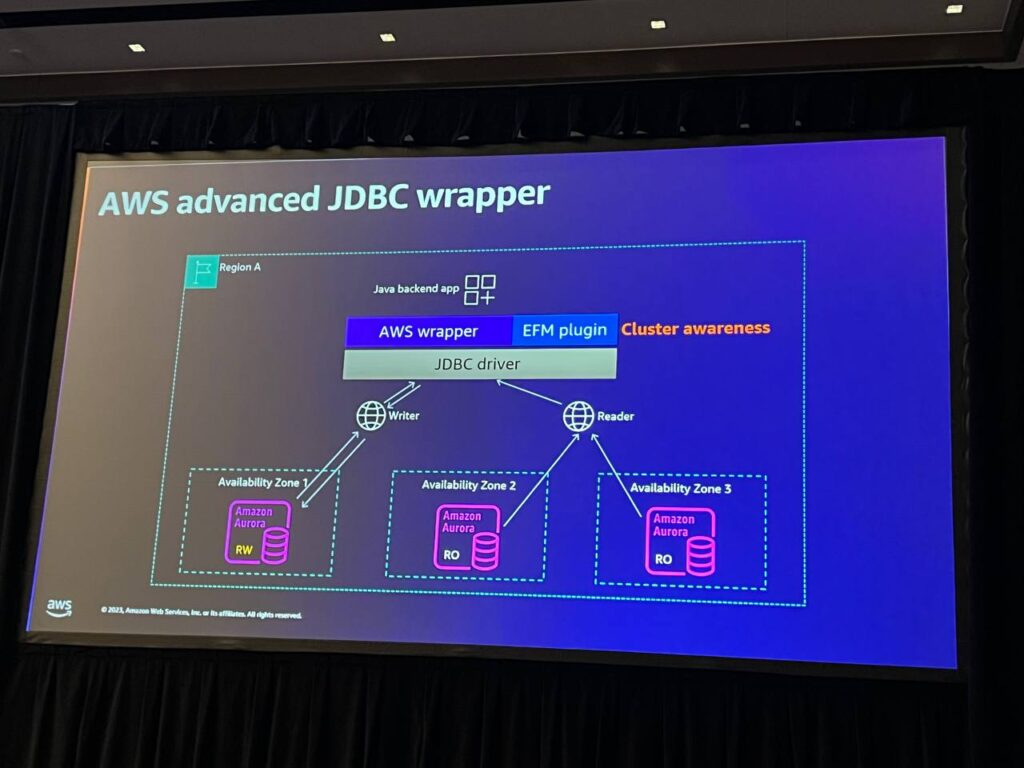
JDBC WrapperはJava環境で使用されるツールであり、ライターがフェイルオーバーするとDNS接続が発生するため、特別なエラー処理が必要です。このドライバーは、Aurora内部で発生する状況を認識し、クラスターのトポロジーを理解するため、DNSを使用せずにフェイルオーバーが発生した場合などに迅速に対応することができます。これにより、フェイルオーバーを最大66%高速化することができます。
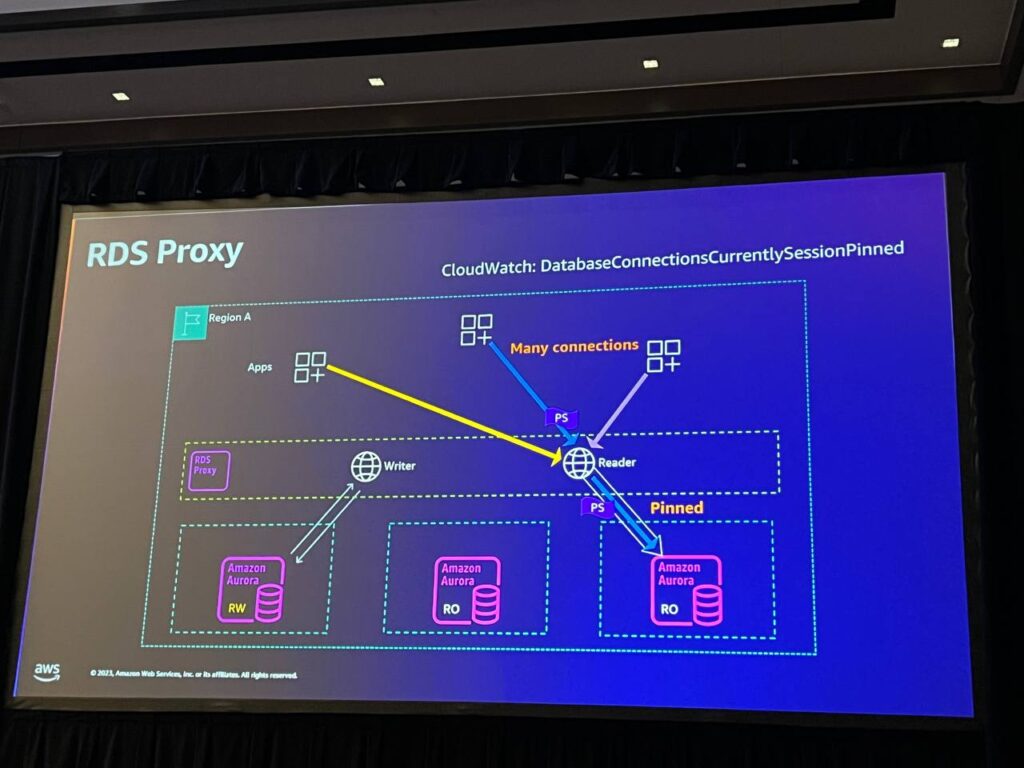
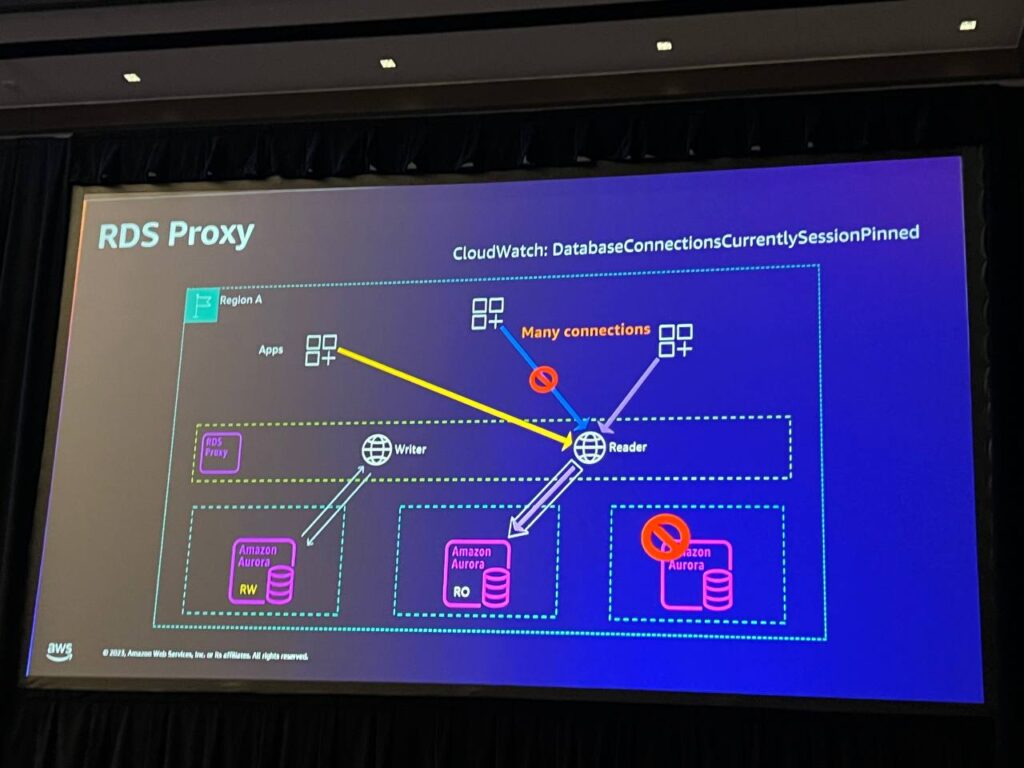
RDS Proxyは、Auroraデータベースへの接続プーリングとマルチプレクシングを提供します。フロントエンドで多くのステートレス接続を処理する際に便利で、接続制限と連携してパフォーマンスを最適化します。RDS Proxyはセッションの状態を効果的に管理し、フェイルオーバー時に透過的に処理し、アプリケーションの安定性を高めます。CloudWatchメトリックを通じてモニタリングすることができ、開発者が状況を理解し、対応することができます。
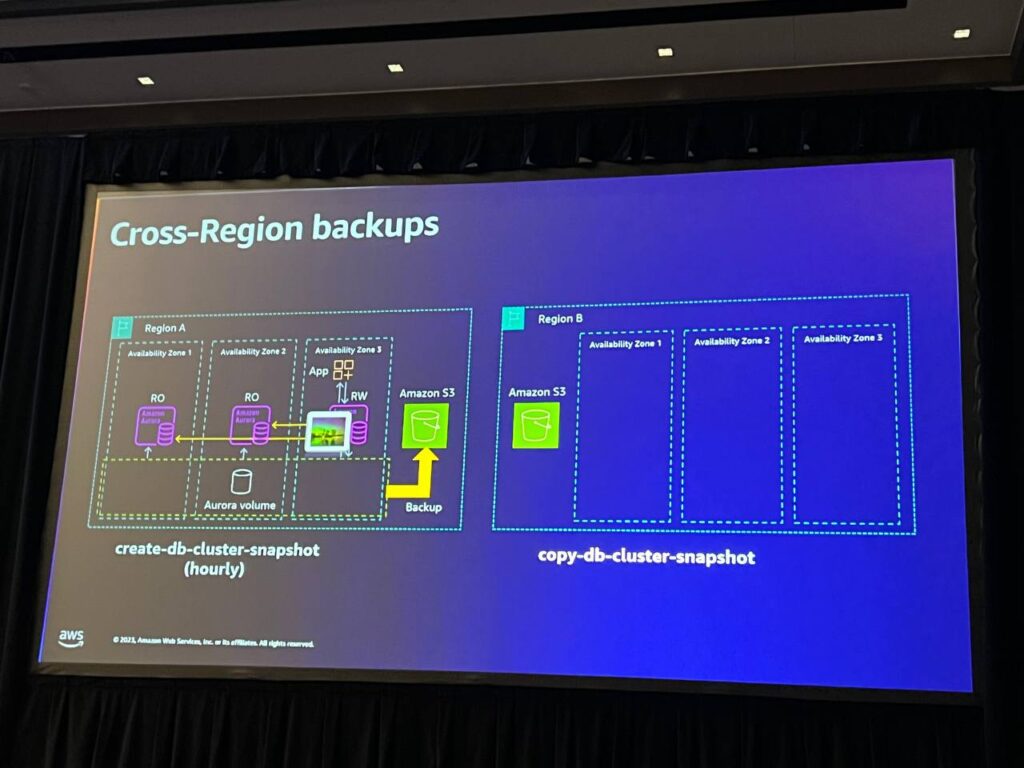


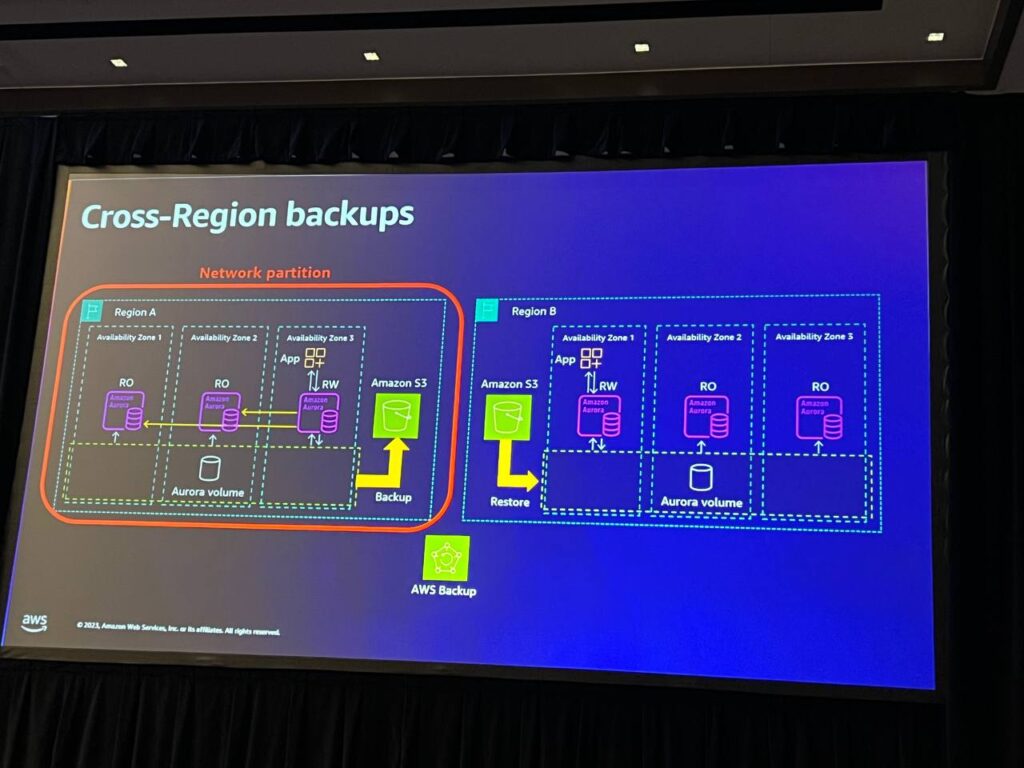
AWS Auroraを利用したグローバル耐久性設定は、バックアップと他のリージョンへのコピーを通じて実装されます。これにより、データの非同期的な複製が行われますが、スナップショット間の間隔によるRPO(リカバリポイント目標(RPO)の問題とネットワークパーティションの考慮が必要です。AWS Backupサービスを活用することで、このような複雑なプロセスを簡素化することができます。
RTO(運用再開時間)は約60分程度と予想され、ネットワークパーティションシナリオへの対応が必要です。このようなグローバル耐久性設定は完璧なソリューションではありませんが、ある程度の耐久性を提供することで、グローバルな災害に備えることができます。障害シナリオの理解とAWS Backupを適切に活用することで、データの安定性を維持することができます。
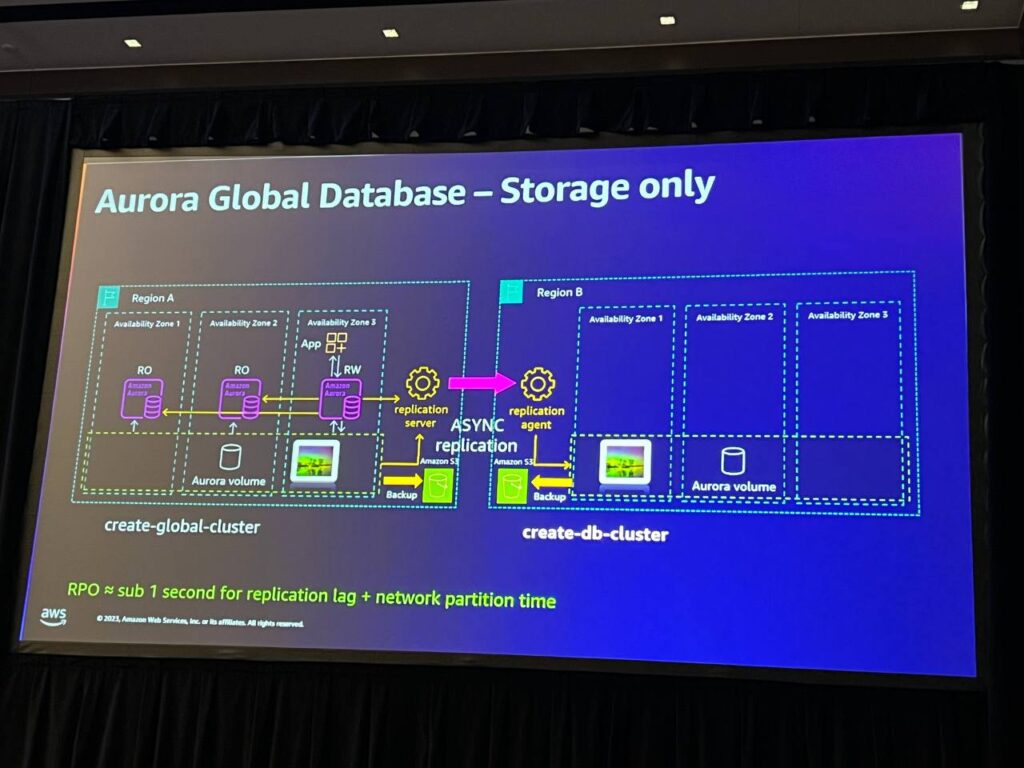


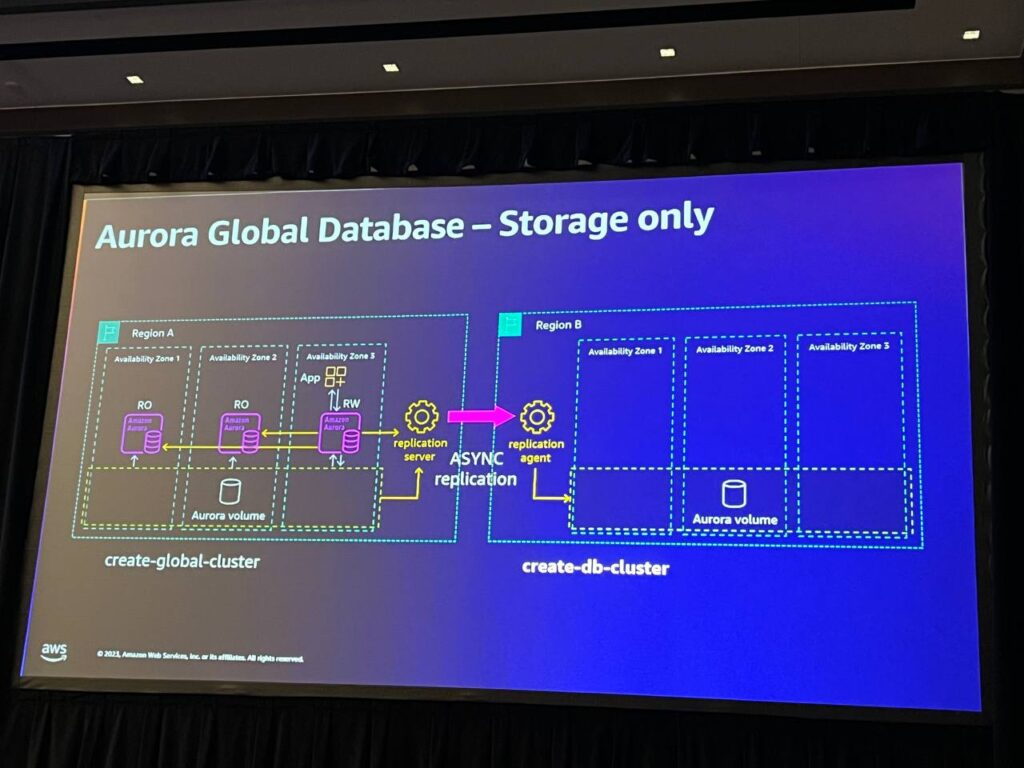
グローバルデータベースについて説明します。 既存のクラスターがある場合、グローバルクラスターを作成し、最初のクラスターとリージョンを作成した後、2番目のリージョンのクラスターをグローバルクラスターの一部にすることができます。その後、レプリケーションサーバーとレプリケーションエージェントを設定し、リージョンAからリージョンBにデータを非同期にレプリケートします。これは非同期レプリケーションであり、RPOは通常1秒未満に改善されています。 両リジョンでバックアップを実行できるため、実行中のシステムとバックアップの両方の安全性を確保することができます。グローバルクラスタに障害が発生した場合、他のリージョンへのフェイルオーバーが可能で、この構成のRTOは約15分程度と予想されます。
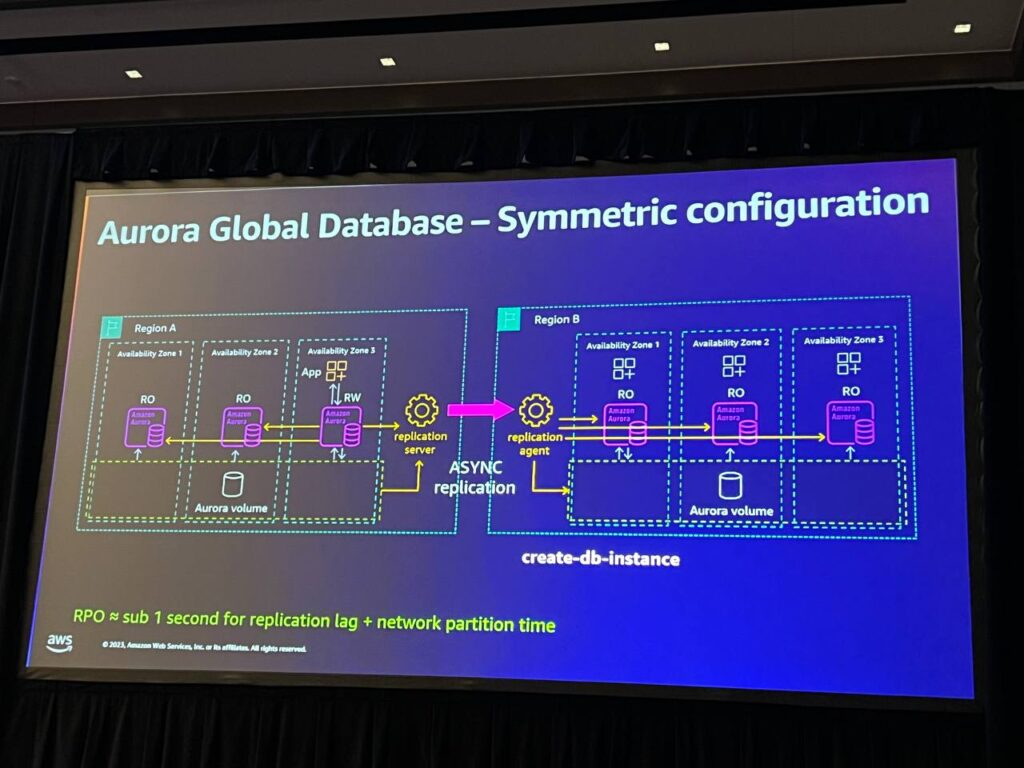


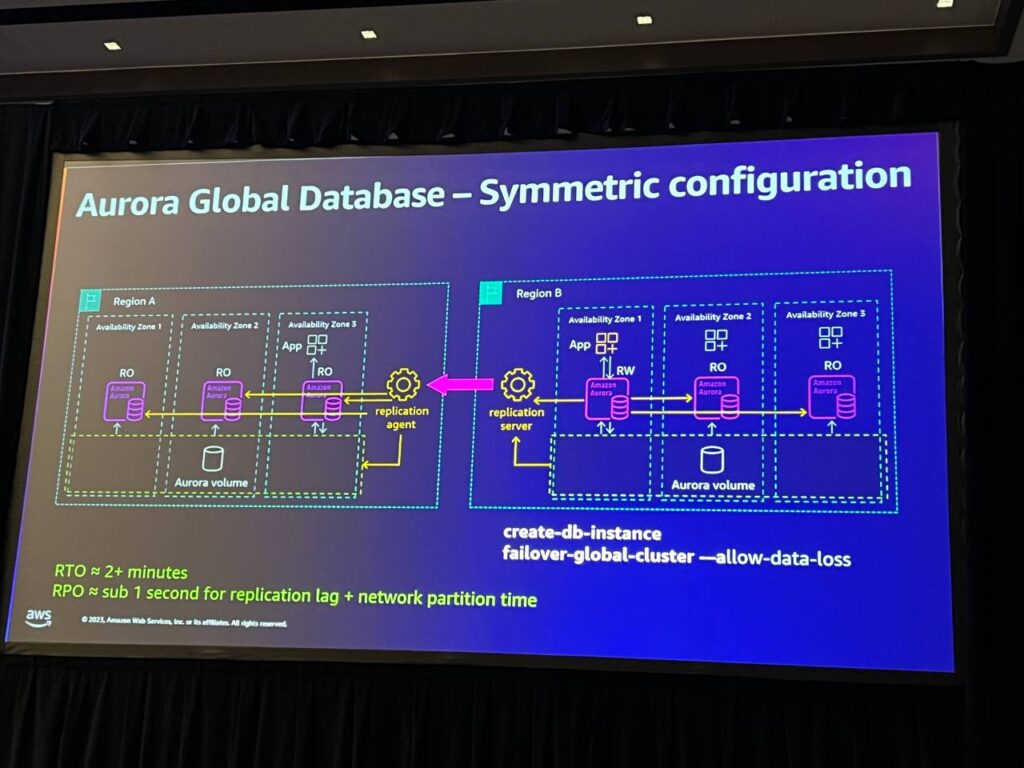
symmetric configurationは、あらかじめ偏差を生成し、エリアAと一致させることで動作します。これは、緊急時に作業を行うための最小限の設定が必要です。TIMが述べたように、レプリケーションエージェントを使用してROノードとして動作するように構成されています。これにより、これらのノードは読み取り専用レプリカのように動作し、アプリケーションが読み取りタスクを実行できるようになります。問題が発生した場合、同じフェイルオーバーコマンドを実行し、その場合、ほぼ瞬時に切り替わります。
ネットワーク分離の状況では、読み取り専用クラスタに切り替えてネットワーク分離時間を最小化し、リージョンAで問題が発生した場合、ボリュームをバックアップし、リージョンBにデータを移動して耐久性を復元します。すべてのプロセスは自動的に行われます。
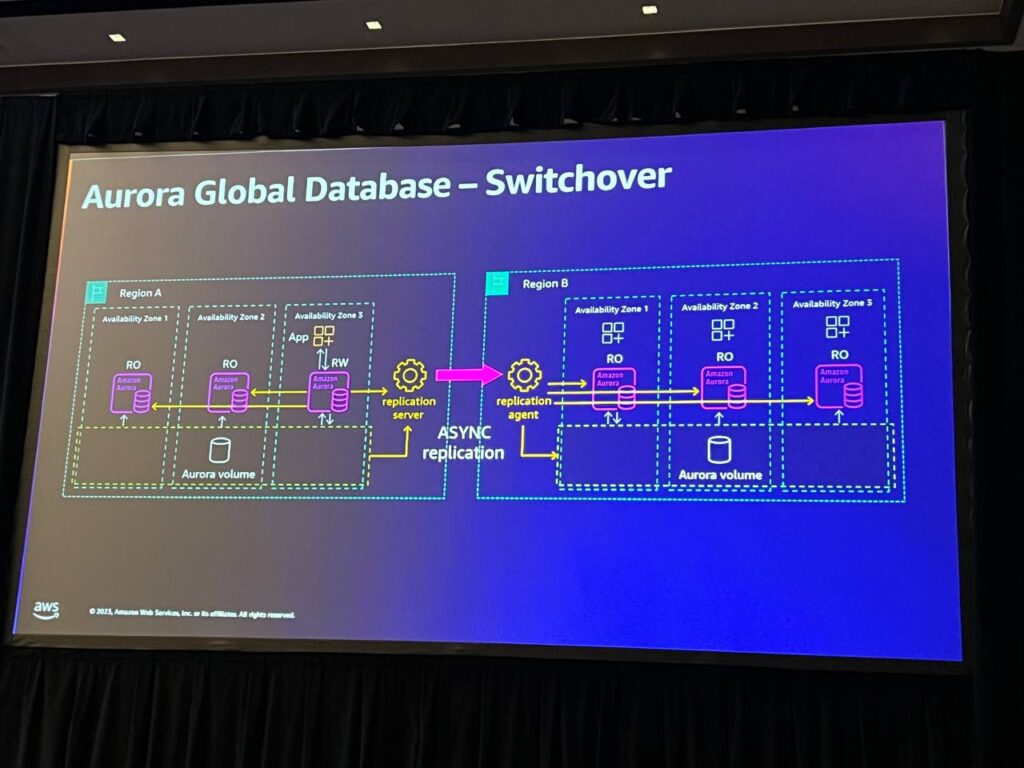
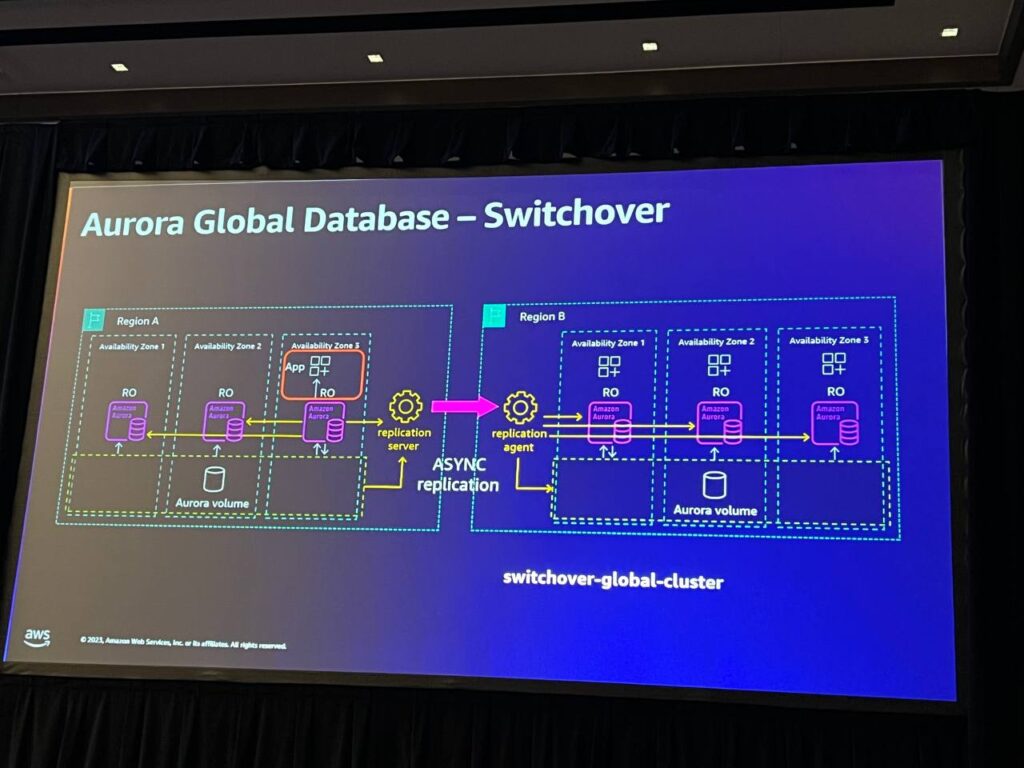
Switchoverコマンドは、managed failoverと混同される部分を改善したコマンドです。 このコマンドは、リージョンAのクラスタを読み取り専用にし、レプリケーションキューをリージョンBに移動させて、2つのボリュームが同じデータを持っていることを確認した後、安全にリージョンBを昇格させる役割を果たします。 このプロセスは自動的に行われます。このコマンドは、毎月の障害復旧を実行し、再度失敗させるテストやリージョン移動に有用であり、1日に3回の移行を行うモデルにも適用することができます。
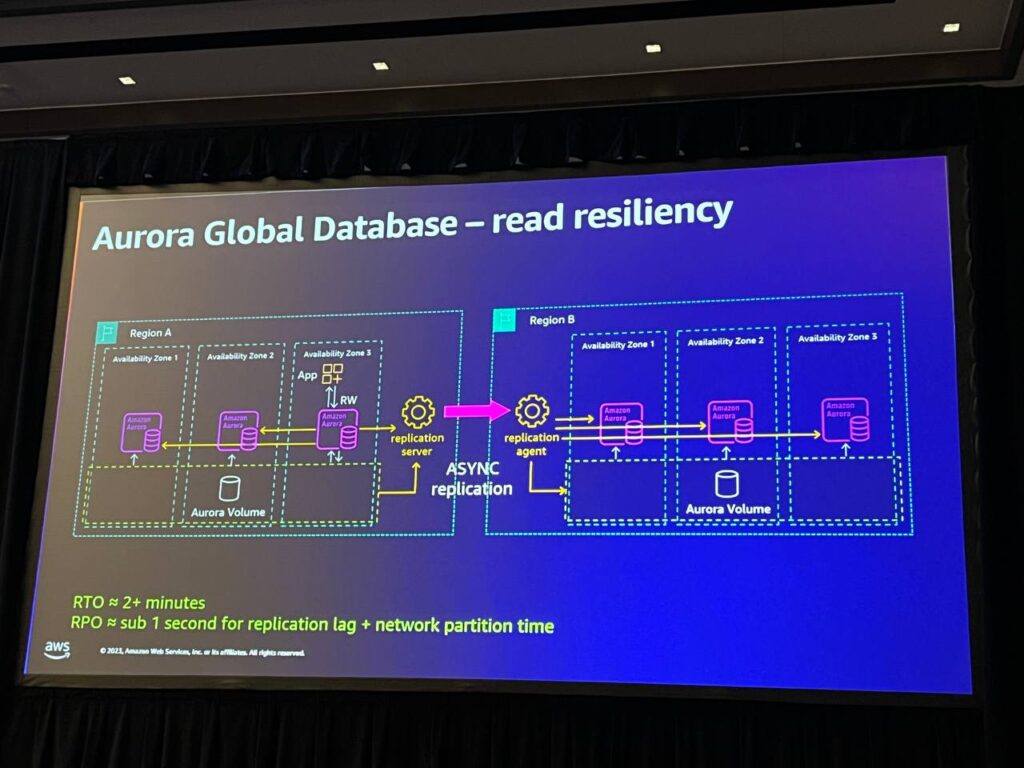
Read resiliencyは、書き込み操作を行わずにデータを読み取る能力として重要です。 特に、ウェブサイトの一部を表示する読み取り専用ノードを活用することで、ユーザーに継続的なサービスを提供することができます。これは、リージョンAで問題が発生しても、ウェブサイトの一部を引き続き利用できるようにすることで、耐久性を高めることができる効果的な技術です。 また、読み取り専用ノードをユーザーに近い地域に配置することで、低遅延を実現することができます。
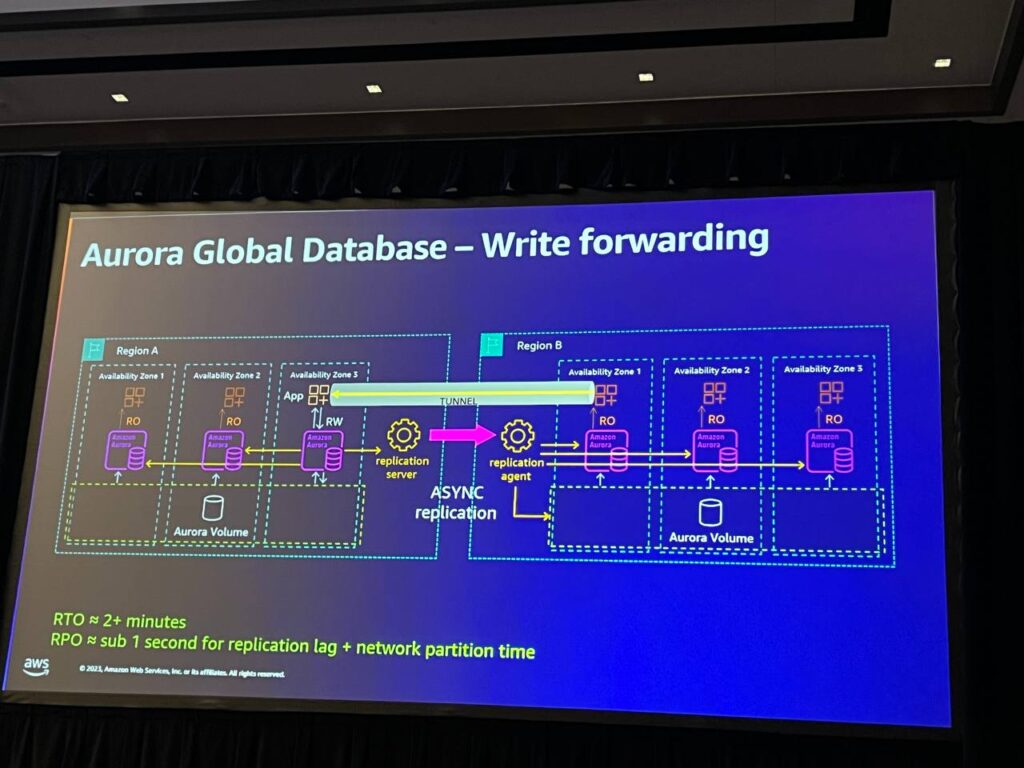
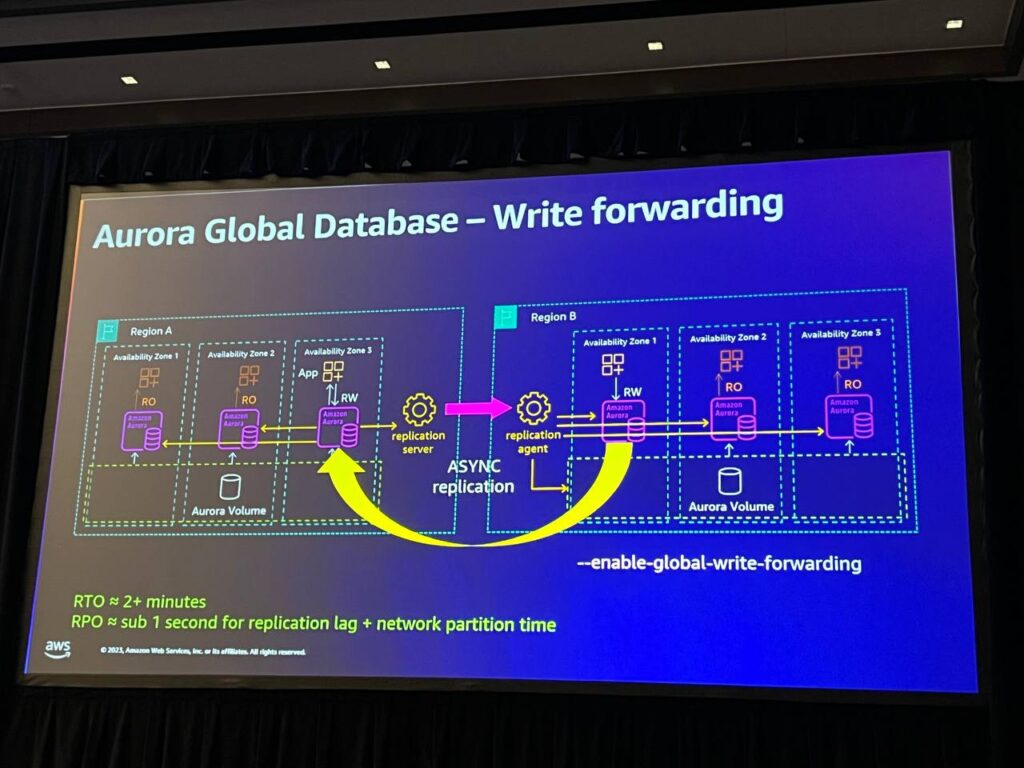
スタンスにWrite forwardingを有効にすると、RWアプリケーションがそのインスタンスに接続できるようになります。 そして、このようにすると、更新を実行する際に、そのROをベースリージョンとRWに転送します。 そして、RWノードの観点からは、ほとんど別の接続が入ってきて更新を行うように見えます。 したがって、これは奇妙なことではなく、標準的なプロトコルです。RWが転送されると、もちろん複製され、再び更新を見ることができるようになります。
Session Read Visibility
セッションレベルでの読み取り一貫性を持ちます。 更新を実行すると、その書き込みがリージョンBにレプリケートされるまで待機し、セッション内で以前の書き込みを読み取ることができることを意味します。一貫性の面では安定していますが、書き込み転送とレプリケーションに依存しています。
Eventual Read Visibility
更新を実行し、同じ待ち時間を持ちますが、書き込みが戻ってくるのを待つことはありません。 そのため、以前の書き込みは表示されない可能性があり、その書き込みを読み返すと奇妙な結果が出る可能性があります。適切なコード処理が必要で、耐久性を向上させることができますが、注意が必要です。
Global Read Visibility
更新を実行し、その書き込みとその後のすべての書き込みの複製が完了するまで待ちます。これにより、すべての書き込みが可視化されますが、ネットワークとレプリケーションに大きく依存し、待ち時間が長くなります。正確性が必要な場合に適していますが、耐久性の面では推奨されません。
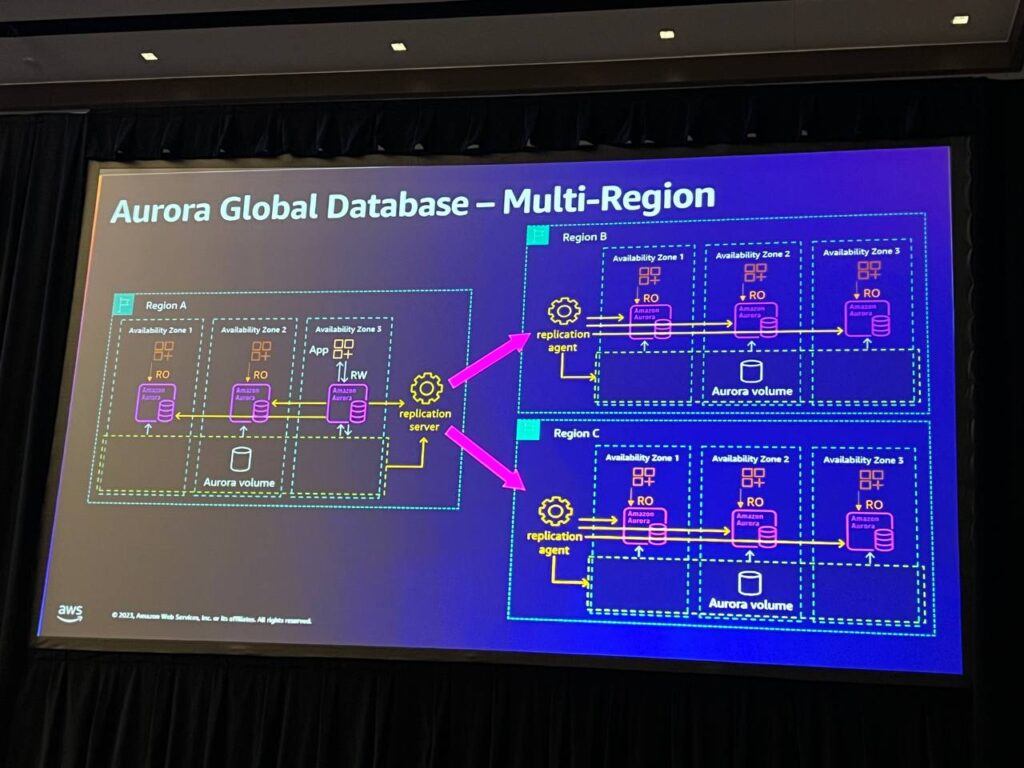
Multi-Region
複数の地域にデータベースを設定し、グローバルな耐久性を持ちます。 各地域で複製されたデータは地域間で安定的な可用性を提供し、障害が発生した場合、一つ以上の地域でシステムを維持することができます。これにより、地域間の障害に対する耐久性を確保することができます。
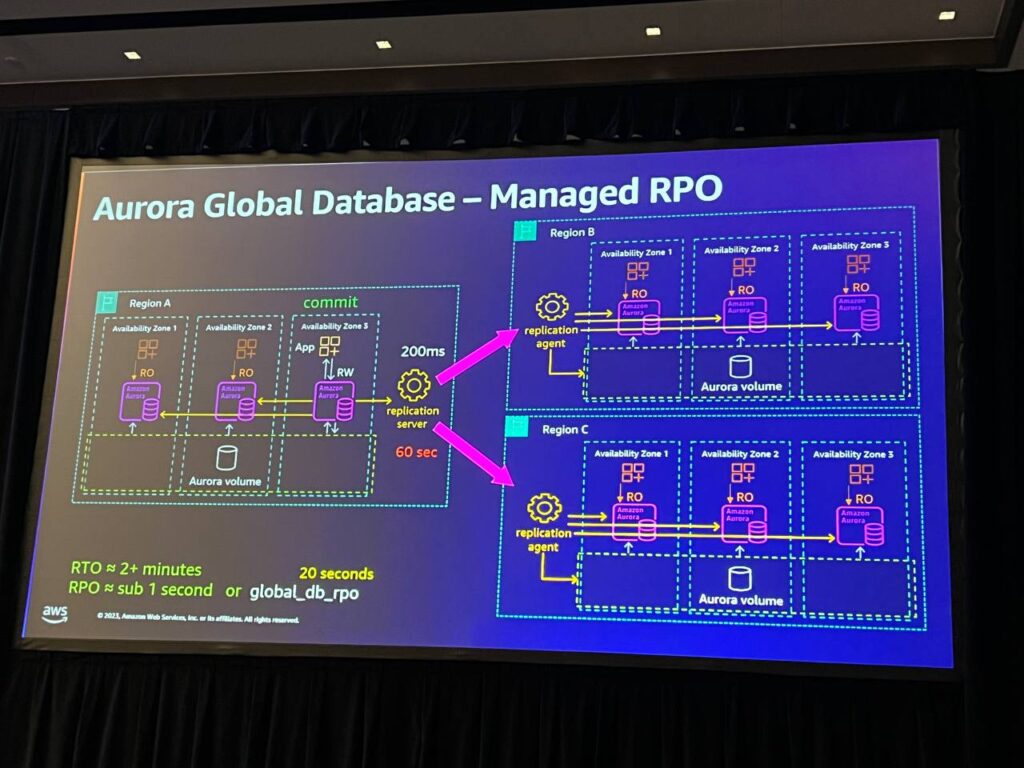
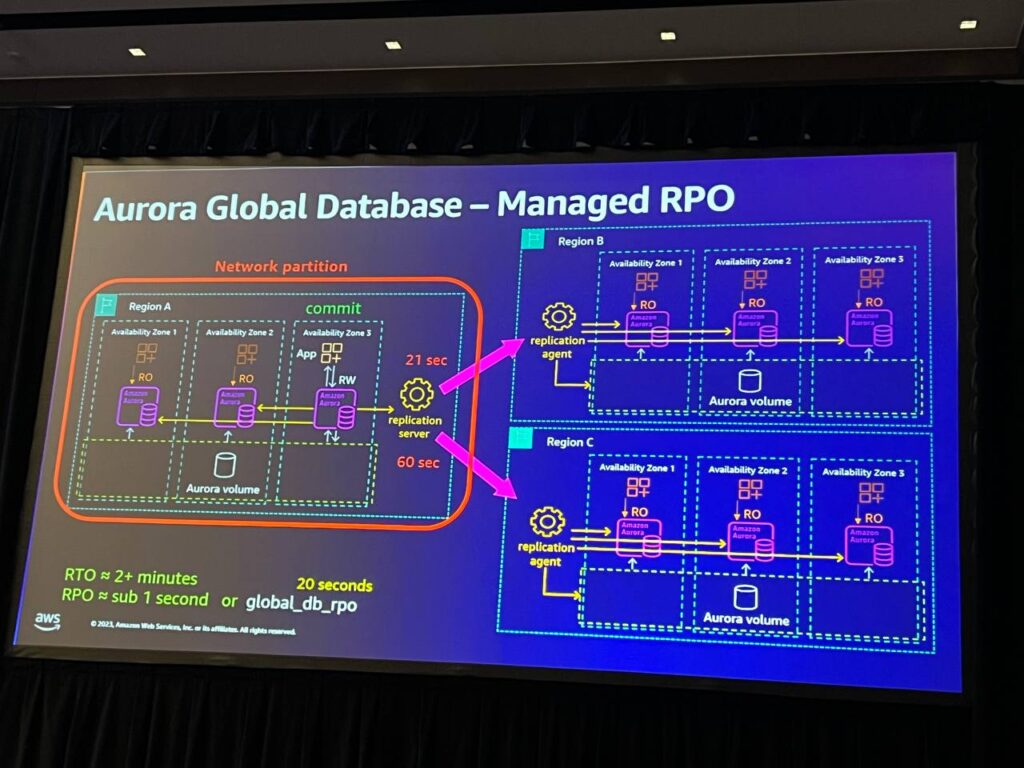
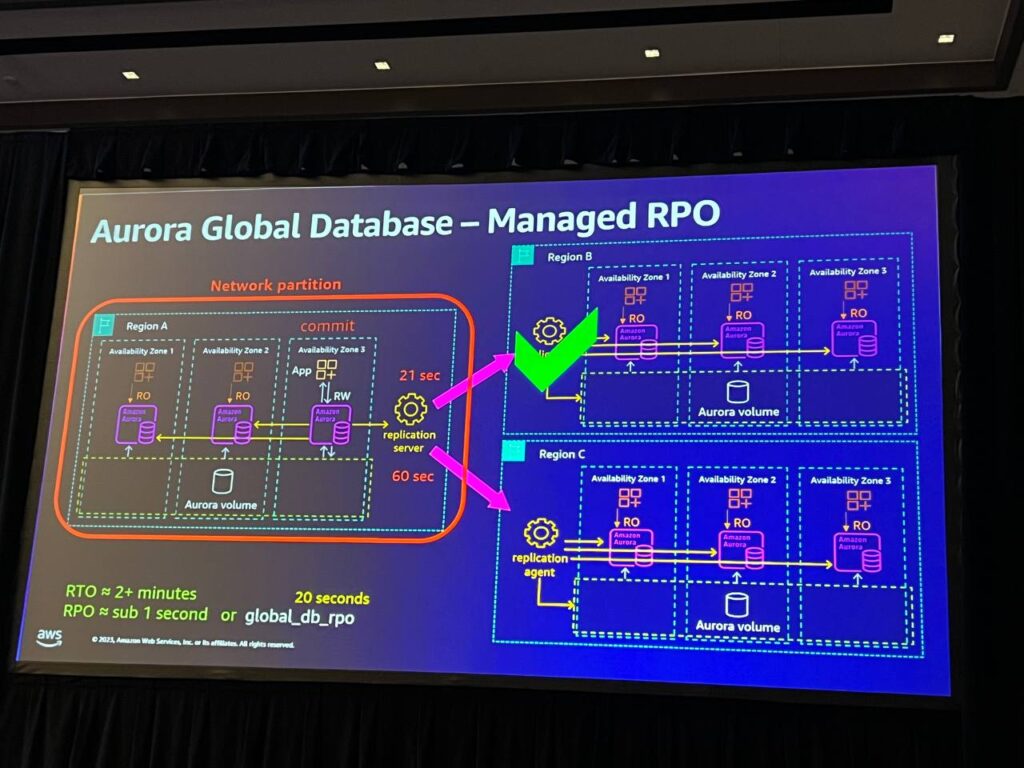
Managed RPO
Aurora PostgreSQLで使用されるglobal DB RPO(Recovery Point Objective)パラメータを設定し、コミットを調整する方法でデータベースの耐久性を制御します。指定されたRPO時間中、いずれかのレプリカが遅延されない状態でコミットが行われるため、データ損失を最小化し、安定性を維持します。これにより、価値の高いトランザクションに対する耐久性を確保することができます。
セッションを終えて
Auroraのストレージ構成と安定性の説明とHAとDRの構築パターン、ユニークな機能について詳しく説明することができ、Auroraを使用してグローバルサービスと無停止運営のための事項を検討し、実務に適用できるかどうかを考えることができる有意義な時間でした。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner