MEGAZONEブログ

Amazon Aurora Limitless Databaseによるスケールの実現
Achieving scale with Amazon Aurora Limitless Database
Pulisher : Managed & Support Center ビンナリ Description : 新たに発表されたAmazon Aurora Limitless Databaseに関する紹介セッション。
はじめに
Amazon Aurora Limitless Databaseが11月27日に新規発表されたため、既存のAmazon Auroraと何が違うのか、どのような方法でLimitlessが実装されるのか、また、運営の観点からどのようにうまく管理して最適化された方法で使用できるのかが気になり、このセッションを選択しました。
セッション概要の紹介
Amazon Auroraは、MySQLとPostgreSQLの互換性を備えた、高性能と可用性のために設計されたクラウドリレーショナルデータベースサービスです。
このセッションでは、アプリケーションがどのようにペタバイトのデータを毎秒数百万件のトランザクションに拡張できるかを学び、Aurora Limitless Databaseのアーキテクチャ、分散トランザクション管理、サーバーレス拡張機能を確認し、適切なアプリケーションパターンと避けるべきアプリケーションパターンを知ることができます。

アプリケーションのデータサイズとクエリボリューム、データシステムの拡張に伴い、これをより効率的に作業するための要求が発生しました。 これに伴い、Aurora Databaseでペタバイト規模のデータ管理のための自動化された水平拡張をサポートする新機能Amazon Aurora Limitless Databaseが発表されました。 (現在はプレビューとして提供されています)


RDS作業拡張の最も一般的なアプローチはshardingという技術です。しかし、shardingはクエリの複雑さ、トランザクションの一貫性維持の難しさ、複数のノードを管理しなければならない管理の複雑さをもたらします。 数億人のユーザーが使うアプリケーションのような場合には、毎秒数百万件のトランザクションの拡張が可能で、ペタバイト単位のデータの管理ができるAurora Limitless Databaseが大きな助けになるでしょう。
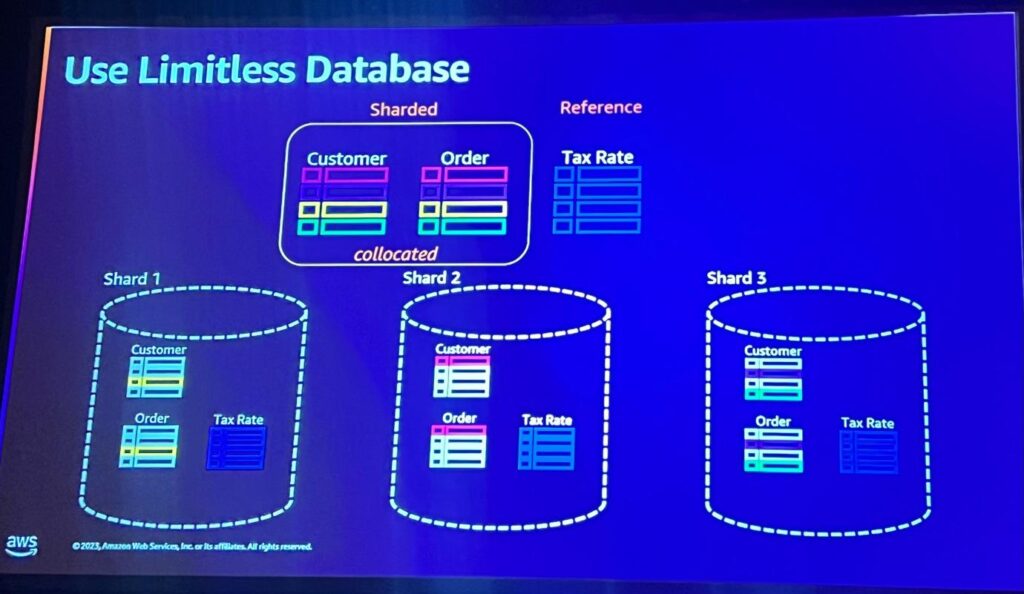
Limitless DatabaseではshardedテーブルとReferenceテーブルという二つの新しいタイプのテーブルを導入しました。
shardedテーブル : 複数のshardedに分散され、データはShared key基準で分割されます。
Reference(参照)テーブル : すべてのシャードにすべてのデータがあり、不要なデータ移動を除去し、迅速なクエリジョインが可能です。頻繁に修正されないデータに適しています。

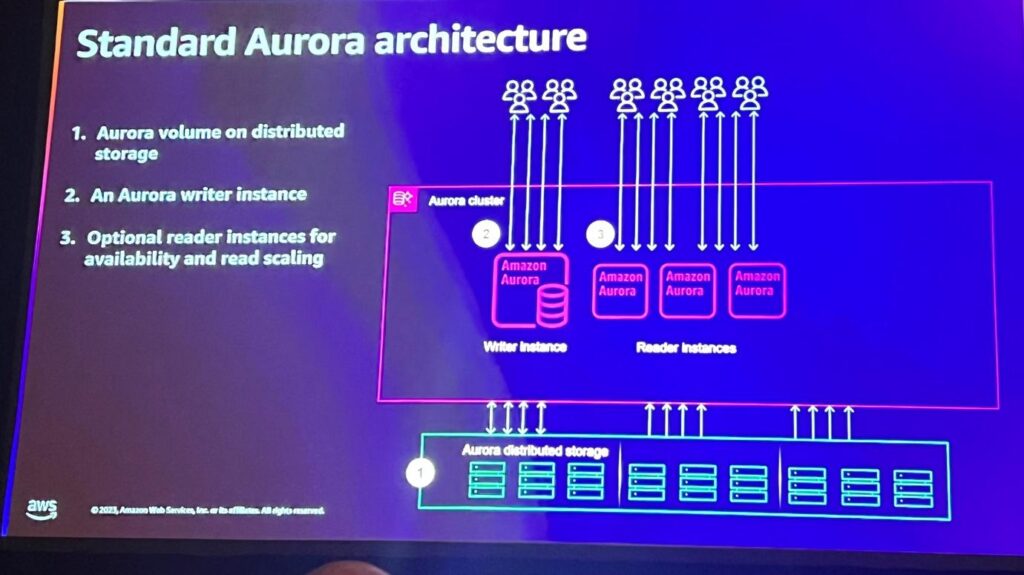
現在のAuroraの基本アーキテクチャは、分散された共有ストレージと1つのWriter(書き込み)インスタンス、可用性に合わせたオプションのReader(読み取り)インスタンスで構成されています。読み取りインスタンスは、書き込みインスタンスが利用できない場合、代わりに動作してサービスします。
Limitless Auroraはシャードグループという概念を追加して、読み取りと書き込みの両方を処理し、アプリケーションのトラフィックを管理します。
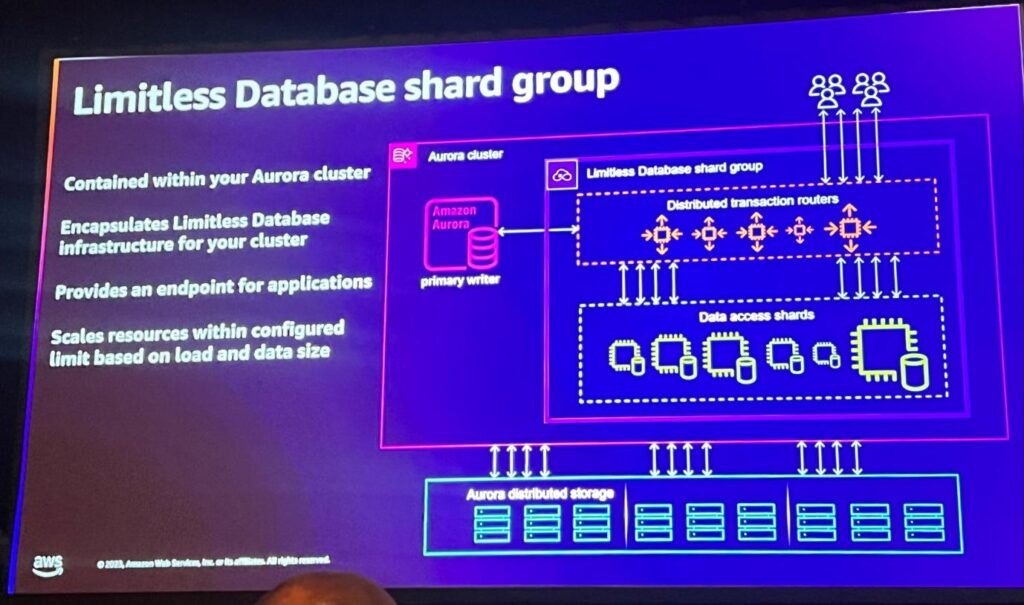
Limitless Databaseはshard groupで無制限のDatabaseをカプセル化し、アプリケーションサービスのための新しいエンドポイントを提供します。あらかじめ構成された制限内でRDS内で垂直、水平に拡張されます。
Distributed Transactionはルーターを介して行われますが、すべてのアプリケーションがルーターを介して接続されています。
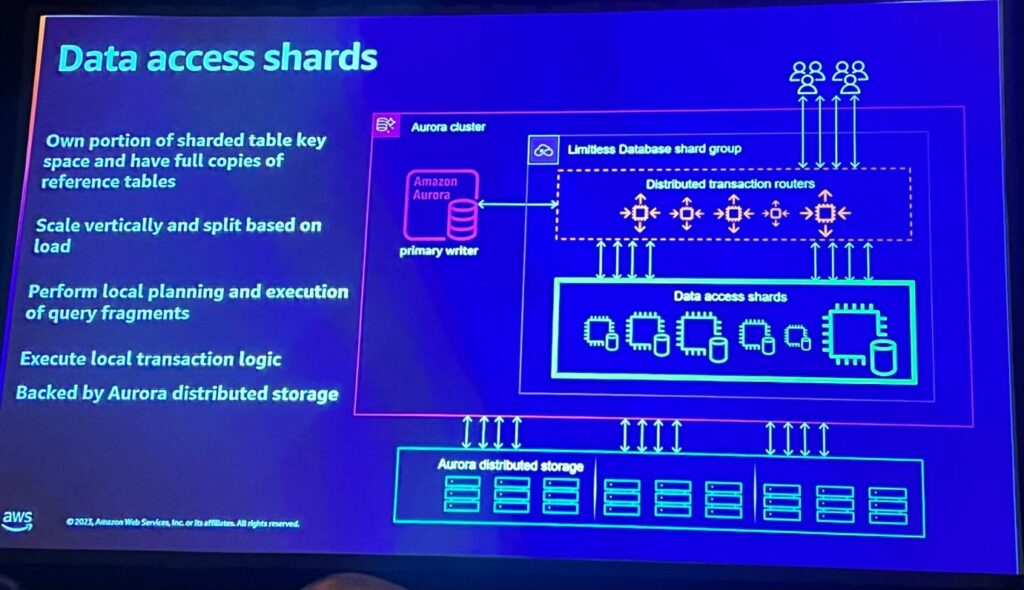
主な概念は、分散トランザクションルーターとデータアクセスシャードです。 これらはメタデータを保存し、スキーマとテーブルキー範囲間のマッピングを把握しています。データアクセスシャードはキー空間の一部を所有しており、ローカルクエリの計画と実行、ローカルコミット、ローカルトランザクションロジックを処理し、高いパフォーマンスを提供します。
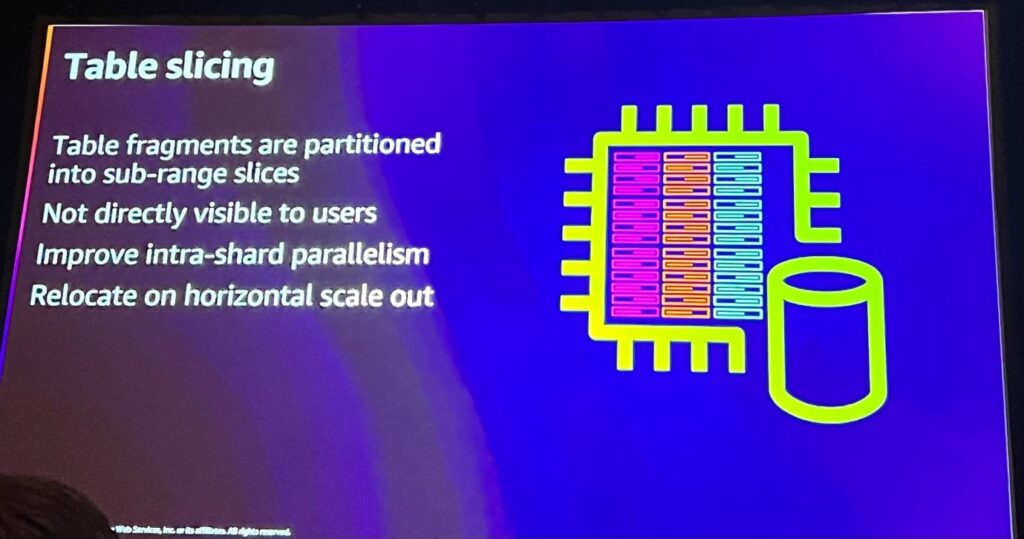
AuroraのルーターとRDSは同期され、強力な一貫性を維持し、テーブル生成のような作業がすぐにすべてのルーターに伝播されるのではなく、内部的にテーブルスライスが行われます。テーブルスライシングはユーザーに直接見えないため、効果的なイントラシャード並列性と水平スケールアウトが可能になり、効率的なクラスタの管理が可能になります。

クエリフローは次のようになります。
ルーターはクライアントからクエリを受け取り、どのシャードにクエリを送るか、どのジョインを送るべきかを決定して部分クエリを生成し、トランザクションコンテキストと一緒に複数のシャードに送信します。
シャードはルーターから受け取った部分的なクエリをローカルジョインやスキャンなど実行します。
シャードがそのデータに対する詳細を知り、データアクセス経路、テーブルスキャン、ローカルジョインなどの作業を行うようになると、ルーターは最終的にジョイン、フィルタ、集計を実行する必要がなく、軽くなります。
これにより、最高のパフォーマンス、最小のレイテンシー、最高の全体的なスケーラビリティを実現します。
セッションを終えて
Amazon Aurora Limitless Databaseセッションでは、新しくリリースされたLimitless databasedの機能とアーキテクチャについて紹介しました。シャードグループ、分散トランザクションルーター、データアクセスシャードなどの核心概念を通じて無限の拡張が可能なLimitless databaseの革新的な構造を確認することができました。
特に、シャードの細分化と効率的なクエリ処理のための技術的向上に感銘を受け、大規模データを扱う顧客社でこれにより高い性能と拡張性を達成できることが期待されます。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner