MEGAZONEブログ

Ultra-low latency vector search for Amazon MemoryDB for Redis
Amazon MemoryDB for Redisの超低レイテンシー・ベクトル検索
Pulisher : Mass Migration & DR Center ムン・ポンギ
Description : Amazon Redis用MemoryDBに対して非常に短い検索時間を提供するvector searchの紹介セッション
はじめに
Redis用Amazon MemoryDBの遅延時間が非常に短いベクトル検索関連の新技術が出てきて、本当にAIが必須の世の中になってきたような気がして、vector searchについて知りたいと思い、参加しました。
セッションの概要紹介
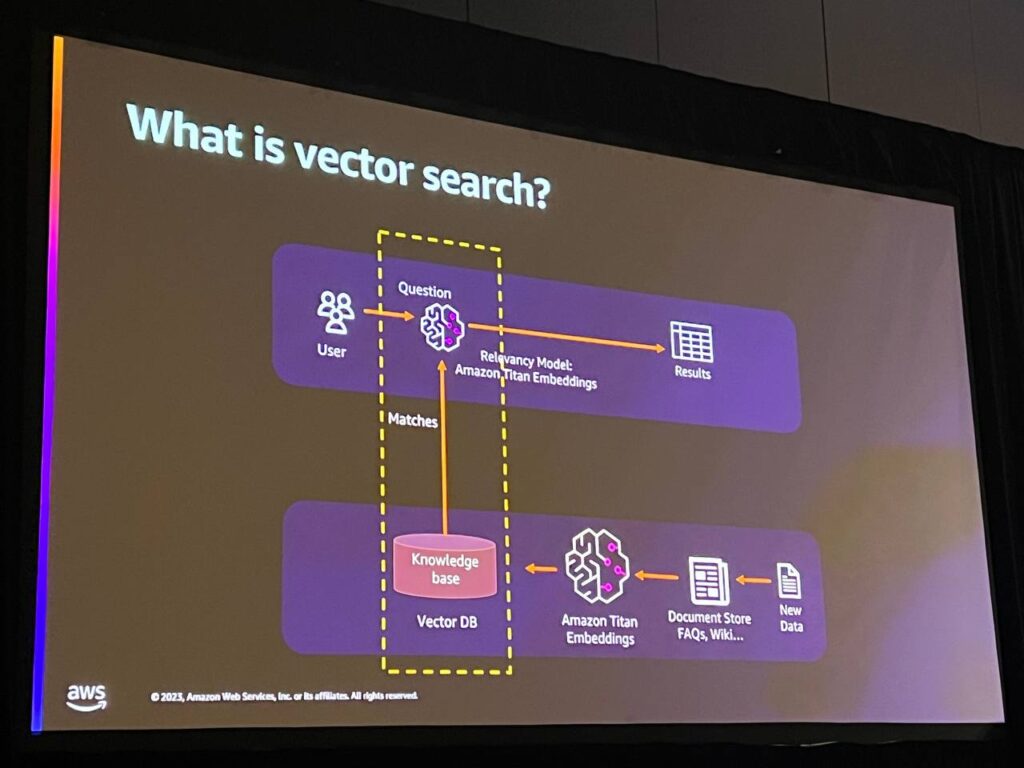
ベクトル検索は数学的な概念であり、データを効率的に保存および検索するために、人工知能および機械学習アプリケーションで使用されます。ベクトルはデータを表し、各値はその特徴を表します。パフォーマンスと検索精度のバランスを保ちながら、多くのデータを迅速に探索することができます。
MemoryDBとベクトル検索は、高いパフォーマンスと99%以上のリコール率を提供し、結果の関連性を高めます。ベクトルは、基礎モデルだけでなく、伝統的な人工知能や機械学習技術と相互作用する際に特に役立ちます。
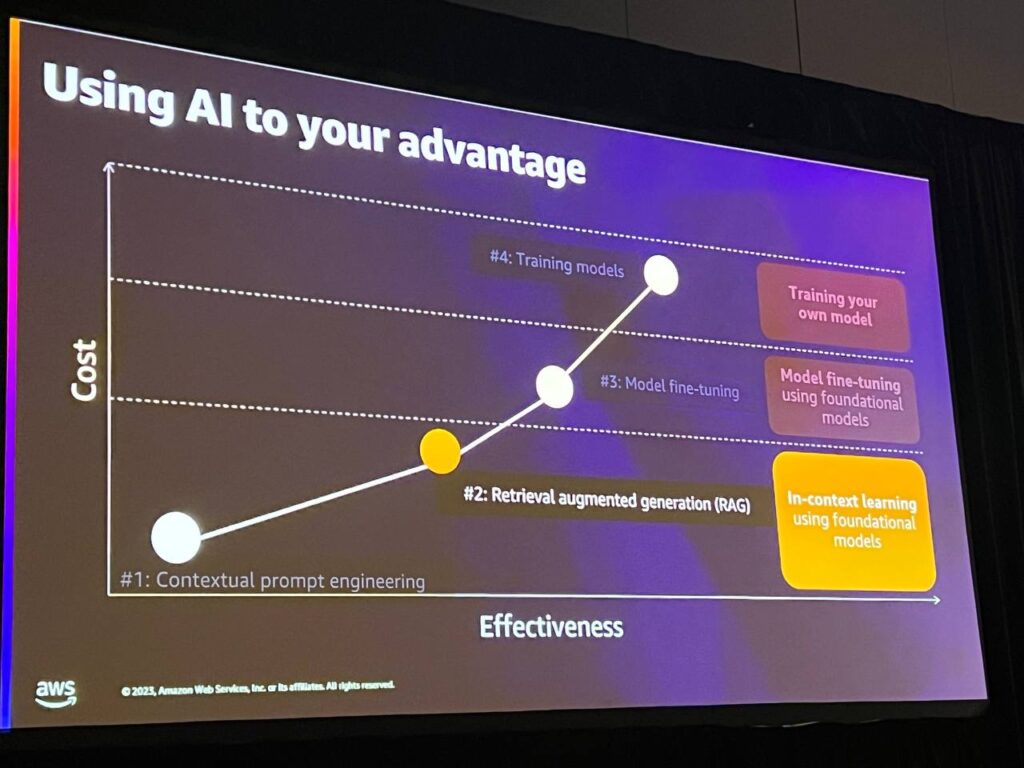
理想的な世界では、誰もが独自のカスタマイズされた機械学習モデルを持つことができますが、現時点ではこれが実現可能ではありません。 多くのデータ、計算能力、専門的な知識が必要であり、それに伴うコストも発生します。
そこで開発されたのが「検索拡張生成」技術です。
この技術は、機械学習モデルを自分で作成したり、調整する能力がない人のために、一般的なモデルに独自のデータを組み込むことで、結果の関連性を向上させます。この技術は主にベクターデータベースを使用してベクターエンベデッドを格納し、高速な類似性検索を実行しますが、最近、生成型AIの成長によりベクターデータベースの需要が高まり、AWSはデータベースオプションにベクターサポートを追加しています。
このアプローチは、データの移動を最小限に抑え、同期によりアプリケーションアーキテクチャを簡素化し、高いパフォーマンスとユーザーエクスペリエンスを提供します。

全体的な観点からは、ベクターをベースデータと一緒に保存することは非常に合理的であり、通常は同じデータベースに保存することを意味します。このアプローチにより、アプリケーションアーキテクチャが簡素化され、データの移動や複数のプラットフォーム間の同期の必要性が最小限に抑えられ、より良いパフォーマンスとユーザーエクスペリエンスを提供することができます。AIアプリケーションの作業や構築のために、データベースの観点から新しいコンポーネントを学習し、導入する必要はありません。

そのため、データベースポートフォリオのさまざまなオプションにベクターサポートを追加したのです。 そのため、AWSで構築された各データベースには独自の利点があり、ベクターサポートも例外ではありません。
たとえば、全文検索に大きく依存するAIアプリケーションを構築する場合は、Open Search Serverlessを使用する必要があります。Open Search Serverlessは、そのユースケースに合わせて構築されており、サーバーレスのシンプルなデプロイメントモデルのおかげで、Amazon Bedrockのようなものを使用する際のデフォルトのベクターデータベースオプションです。 ACID(原子性、一貫性、分離性、永続性)準拠のトランザクションが必要な場合は、Auroraのようなものがベクターと一緒に、そのユースケースの資産準拠のトランザクションに適しています。
しかし、これから見ていきますが、99%以上の再現性、同時性、高性能を要求するアプリケーションがある場合は、MemoryDBのベクトル検索が良いオプションになる可能性があります。

・超高速性能:MemoryDBは毎秒100,000回の書き込みと470,000回の読み取りをサポートし、低遅延で高速なパフォーマンスを提供します。
・Redis互換性: MemoryDBはRICE互換性のある唯一のソリューションで、Redis APIを完全にサポートしながら、分散トランザクションログ技術を活用します。
・耐久性と可用性:分散トランザクションログを活用し、MemoryDBは複数の可用性領域に冗長データを保存し、データの耐久性と可用性を保証します。
・完全管理型:MemoryDBはAWSで完全に管理されるサービスであり、ユーザーはインフラ管理を気にすることなく、安定的に活用することができます。
・スケーラビリティ: MemoryDBは、クラスタあたり最大500ノードと数百万件のリクエストをサポートし、垂直および水平方向に拡張可能です。
・セキュリティとコンプライアンス: MemoryDBは、データの耐久性と一貫性を提供しながら、安全な環境を提供し、コンプライアンスを遵守してセキュリティを強化します。

MemoryDBは最速のベクトル検索エクスペリエンスを提供し、低パフォーマンスの限界を超えたAIおよびMLアプリケーションをサポートします。MemoryDBを使用すると、ベクトルクエリ検索を数ミリ秒で実行することができ、データを更新したり、新しいデータを追加すると、MemoryDBは数ミリ秒でインデックスを更新し、リアルタイムで最新の結果を提供します。MemoryDBは、毎秒数万件のベクトルTPSを99%以上のリコールレベルで処理します。

プレビューは今日から5つのリージョンで追加料金なしで利用できるようになりました。 数分後に開始方法についてお話しする際に、より詳細な情報をご覧いただけます。ベクトル検索プレビューは、Latticeエンジンバージョン7.1で利用可能です。これは2種類のインデックスをサポートしています。

メモリがサポートするインデックスの種類は2種類あります。FLATインデックスは、インデックスにあるすべてのベクトルを通して検索することができます。シンプルですが、各インデックスをすべて参照する必要があるため、コストが比較的高くなります。 より大きなデータセットがある場合は、HNSWを使用することができます。これは多くのベクターデータベースで使用される典型的なインデックス技術であり、大規模なデータセットに最適で、優れた性能を発揮します。
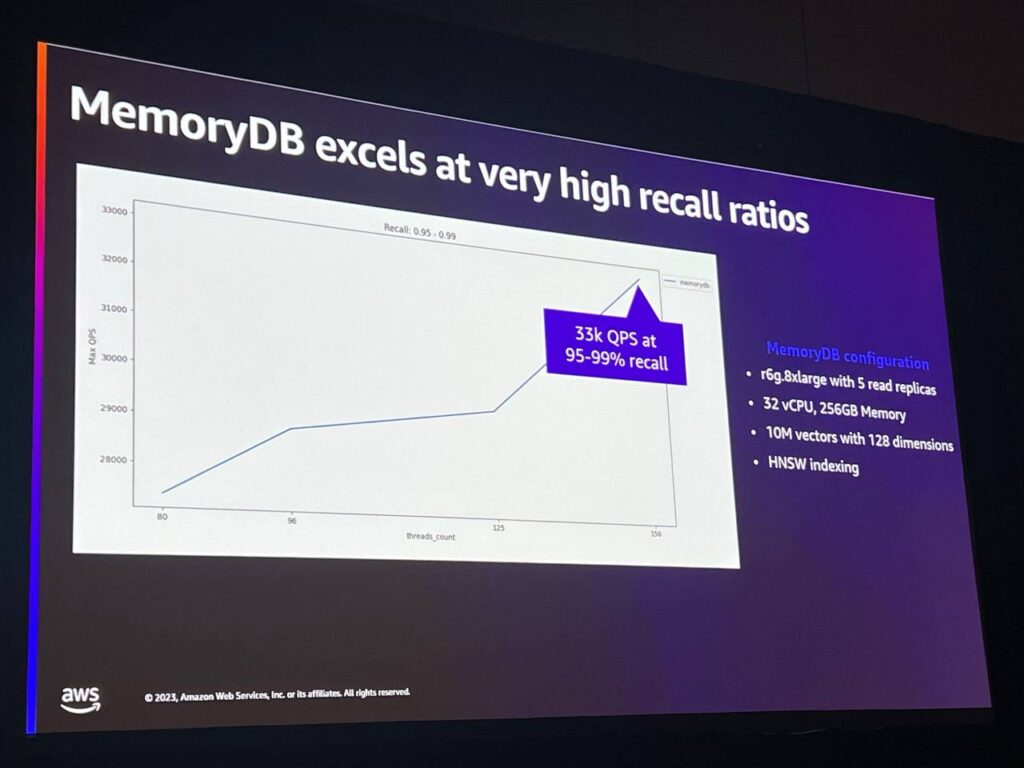
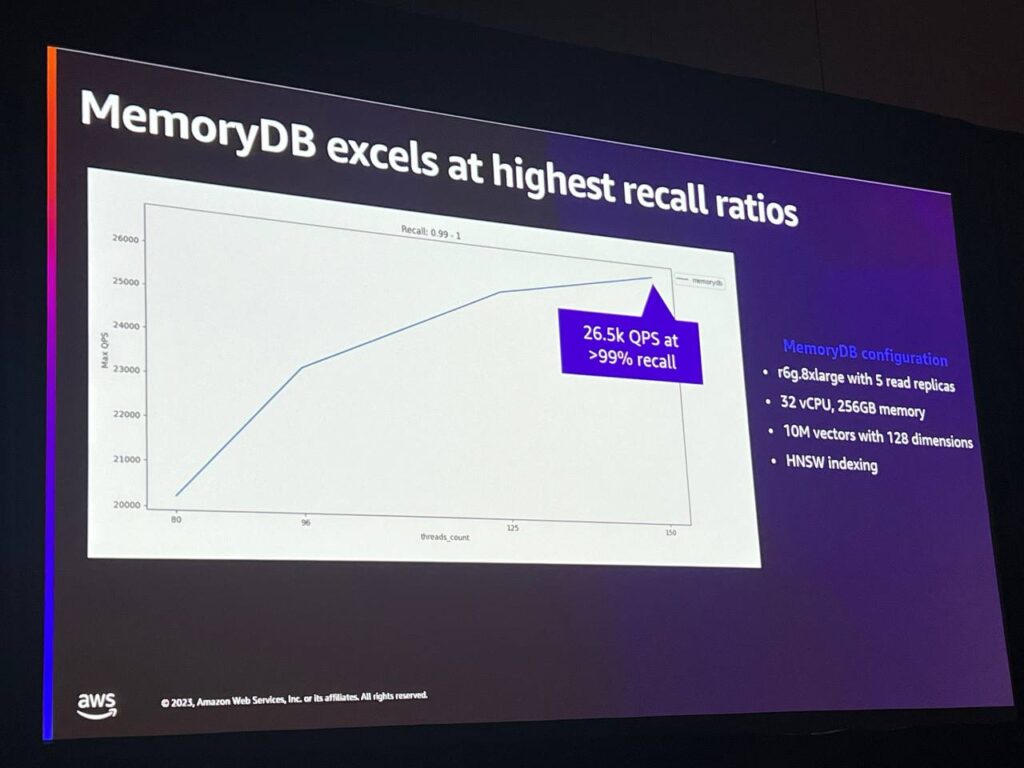
高いパフォーマンスと高いリコールレベルはメモリにとって理想的です。 このベンチマークでは、それぞれ1,000万ベクトルと128次元の大きなデータセットを使用し、95%から99%のリコールレベルでは毎秒33,000ベクトル検索を達成することができ、リコールレベルを90%に上げると毎秒26,000以上のリクエストを達成することができます。このような数値を達成できるのは、MemoryDBのユニークな特性によるもので、インデックスだけでなく、インデックスを作成するデータ自体もすべてメモリ内にあるためです。
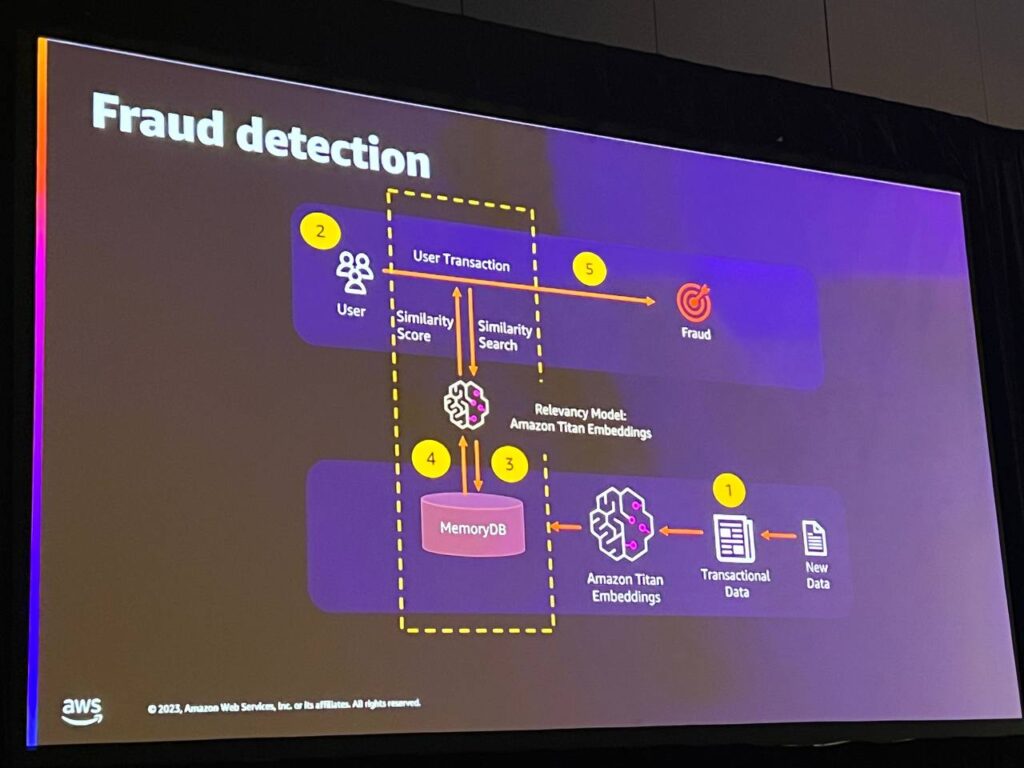
上記のケースは、MemoryDBに非常に適した不正検出(ユースケース)です。 高性能と低遅延のベクトル検索機能が必要な場合に最適です。 これは不正検出のユースケースです。 この場合、過去のデータ、つまり過去の取引データを取得し、それをベクトルに変換してMemoryDBに保存します。
そして、顧客が銀行、クレジットカード、または小売タイプのアプリケーションで中立的なアクションを実行しているかどうかをリアルタイムで確認し、既存のトランザクションを過去のトランザクションの履歴またはベクトルと比較し、類似性を探します。類似していない場合は取引を拒否し、類似している場合は以前のパターンと一致するため、取引を承認します。
セッションを終えて
MemoryDBとvector searchがますます大きくなっているAIとMLに焦点を当てて設計されたような気がしましたし、一般的なRDBMSでもvectorをサポートしていますが、現在IT業界が全てAIに焦点を当てて変化して利便性を提供して市場シェアを上げようと努力しているようです。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner