MEGAZONEブログ
Amazon Security Lakeによるハイブリッドおよびマルチクラウド環境の監視
Hybrid & multicloud environment monitoring with Amazon Security Lake
Pulisher : Cloud Technology Center ペクソジョン Description : Security Lakeの全体的な紹介とデモデモンストレーションセッション
はじめに
MEGAZONECLOUDは今年、韓国内初のSecurity Lake SDP(Service Delivery Partner)に選定されました。SDP登録のためのプロセスを一緒に準備したメンバーとして、re:Inventで行われるSecurity Lakeセッションを直接聞きたく、このセッションに参加しました。
このセッションはSecurity Lakeの全体的な紹介とデモで構成されていました。Security Lakeは今年GAされたばかりのサービスで、まだ参考になるような内容ではなく、サービス自体を発表にフォーカスしていました。
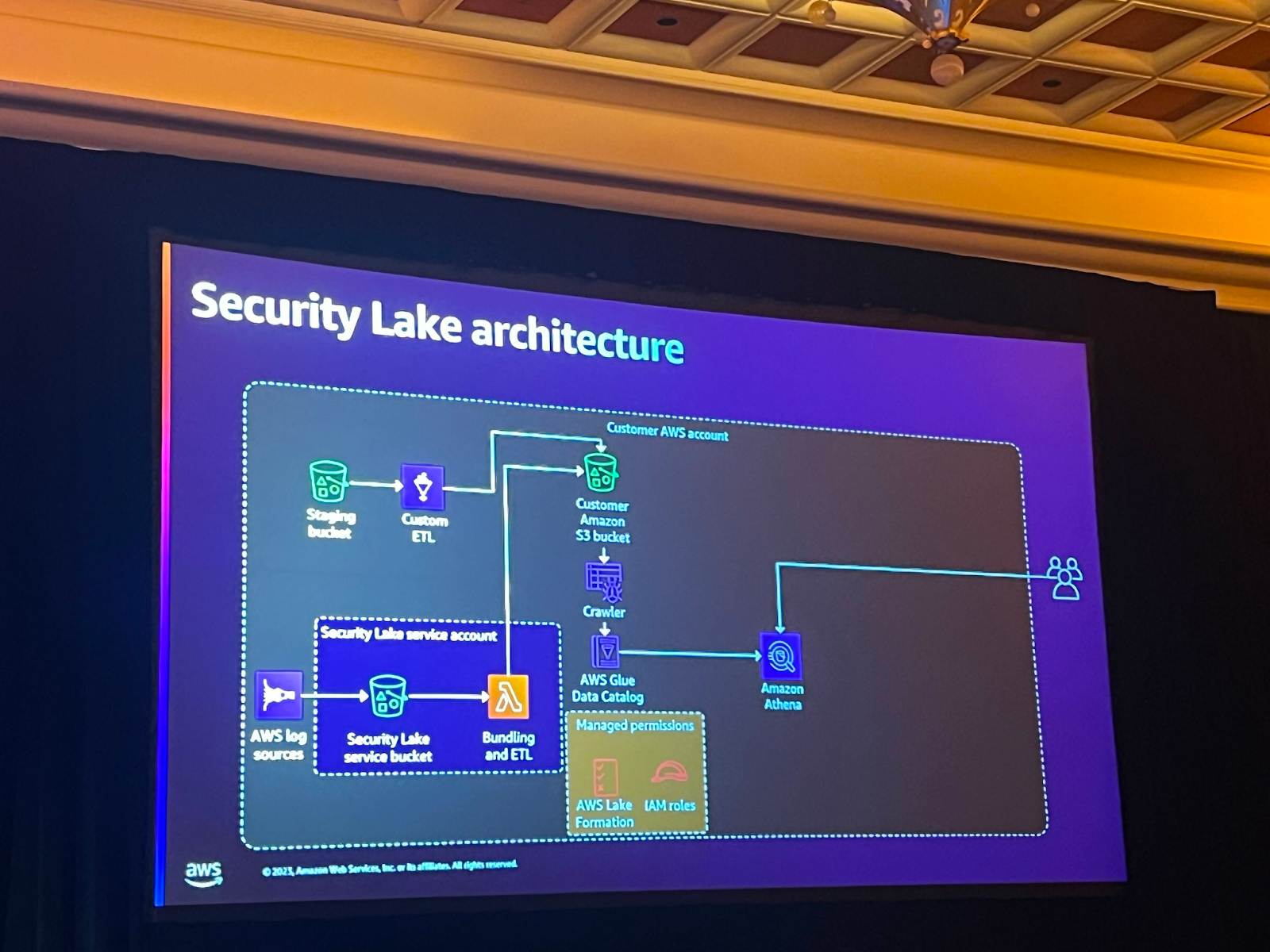
Security Lake Architecture
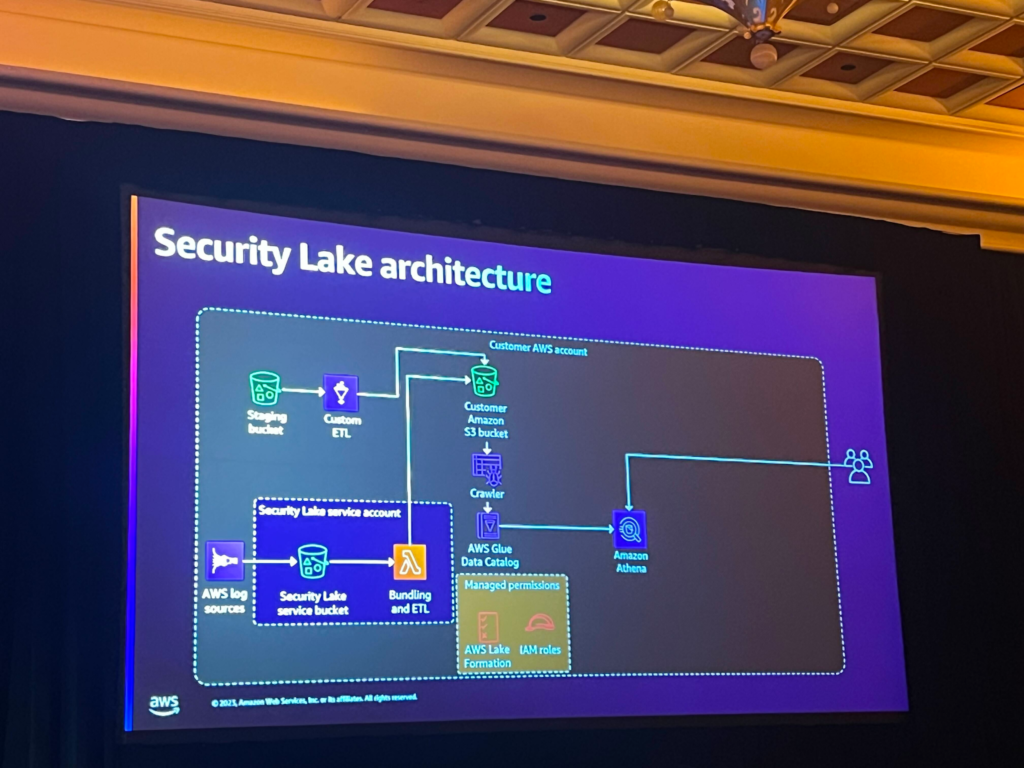
Security LakeはIAMやクロスアカウントの権限の制御などの作業を必要とせず、一つの統合されたサービスでこれらの部分を簡単に制御することができるサービスです。 また、さまざまなサービスからログを簡単に収集してくれます。
Security Lakeがない時は、各リージョンに対するvpc flow logを収集するには、各リージョンで個別に設定が必要でした。 また、ログをOCSFフォーマットで収集するには、同様にフォーマット作業が必要でした。
しかし、Security Lakeを使うと、こうした作業がずっと簡単になり、Security Lakeがデータクローラーを回してカタログも作成し、lake formationで権限制御も簡単にできます。
セッションタイトルから分かるように、ハイブリッドまたはマルチクラウドアーキテクチャでも適用が可能です。他のCSPのデータを持ってくることもでき、データをビジュアル化したい場合にも簡単に設定が可能です。アーキテクチャで分かるように、OpenSearch, splunk, SageMakerでログを購読することができます。
AWS Security Reference Architecture

このアーキテクチャは、単一アカウントが複数のログを制御するアーキテクチャです。ここで、中央アカウントがログ収集を有効にするかどうか、およびクライアントを管理します。
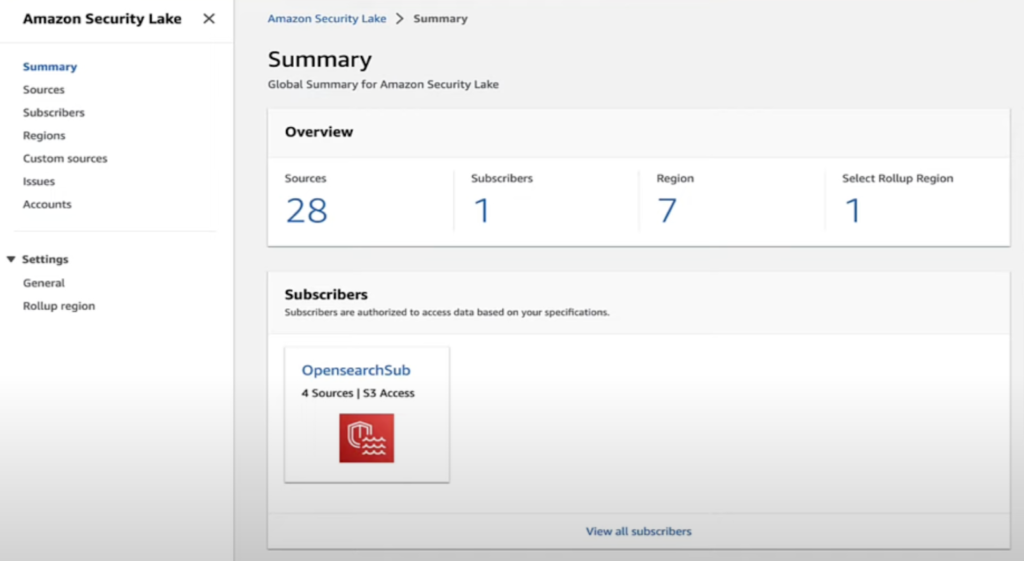
最初の画面ではSecurity Lakeのoverviewとroll-up regionsを見ることができます。
ソースタブではログのソースを管理することができ、subscribersタブではサブスクリプションを選択することができますが、ここではすべてのロギングサービスを全部選択することも、一部だけ選択することも可能です。
ここでData access methodも設定することができますが、これは誰がどのようにデータにアクセスするかを制御するためのものです。最初の方法はLake Formationで、この方法でデータに直接クエリすることができます。二つ目の方法はS3権限を通じた制御です。
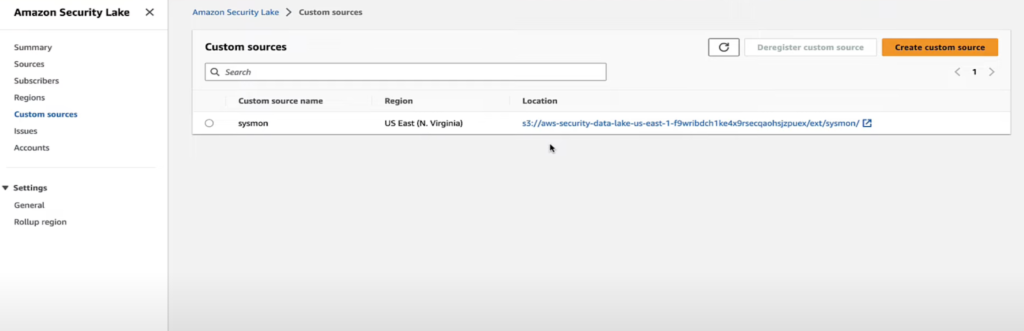
そしてCustom sourceタブでoscfスキーマの詳細を選択することができます。
roll up regionsは一つのリージョンにデータをroll upしたいときに使用できますが、色んなリージョンでデータを収集しますが、一つのリージョンバケットでデータを収集したいときに使用できます。
その下のUsageタブではデータソースやアカウント別に使用量を確認することができます。
上の設定を使ってS3にロードされたログをAthenaで分析することができます。 今回のセッションはcode talkというタイプのセッションなので Security Lakeのログ分析に適用可能ないろいろなクエリについて説明していました。
arbitraryという関数の使用など、発表者が作成したさまざまなクエリについての内容が含まれていて、その中の一つだけ例として紹介すると、下記のようなクエリがありました。
このクエリは7日以内にfindingが重複するfindingを探すクエリです。ここでfindingはSecurity HubがAWS内のセキュリティ状態についての情報を伝達するメッセージだと考えてください。ここで重複するfindingがあるということは、注意すべきセキュリティに関するメッセージがあるということだと考えられます。
SELECT finding.uid, MAX(time) AS time, ARBITRARY(region) AS region, ARBITRARY(accountid) AS accountid, ARBITRARY(finding) AS finding, ARBITRARY(vulnerabilities) AS vulnerabilities FROM amazon_security_lake_glue_db_us_east_1.amazon_security_lake_table_us_east_1_sh_findings_1_0 WHERE eventDay BETWEEN cast(date_format(current_timestamp - INTERVAL '7' day, '%Y%m%d%H') as varchar) and cast(date_format(current_timestamp - INTERVAL '0' day, '%Y%m%d%H') as varchar) GROUP BY finding.uid LIMIT 25
当たり前ですが、分析したデータはOpenSearchやQuickSightで可視化してモニタリングが可能です。
その他にも、クライアントの中にメールログを分析して見たいというニーズがあり、step functionを使用してデータが取得されると分析し、メールを送信するところまで実装を完了させたそうです。
このようにさまざまなセキュリティログを監査し、情報を一元化して組織のセキュリティを強化する方法について知ることができました。
セッションの最後に
Security Lake SDPのレジスター登録プロジェクトに参加し、Security Lakeに対する基本的な理解度はありましたが、模範アーキテクチャと専門SAの説明を聞いて、さらに概念がまとまりました。
セキュリティが日々重要になってきて、セキュリティログの統合的管理の強化が重要ですが、Security Lakeを活用すれば、セキュリティの監視がより簡単になると思います。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner