MEGAZONEブログ

Improving user experience at Epic Games using Amazon Timestream
Amazon Timestreamを利用したEpic Gamesのユーザー体験の向上
Pulisher : Mass Migration & DR Center ムン・ポンギ
Description : Epic GamesがAmazon Timestreamを使用してユーザーエクスペリエンスを改善し、パフォーマンスを向上させた方法を紹介するセッション
はじめに
ゲーム業界ではクラウドをどのような用途で使っているのか気になりました。ちょうどFortniteを開発したEpic GamesがAmazon Timestreamを使用してユーザーエクスペリエンスを改善し、パフォーマンスを向上させた事例を聞きたいと思い、セッションを申し込みました。
セッションの概要紹介
Epic GamesがAmazon Timestreamを使用してユーザーエクスペリエンスをどのように改善したかをご紹介します。
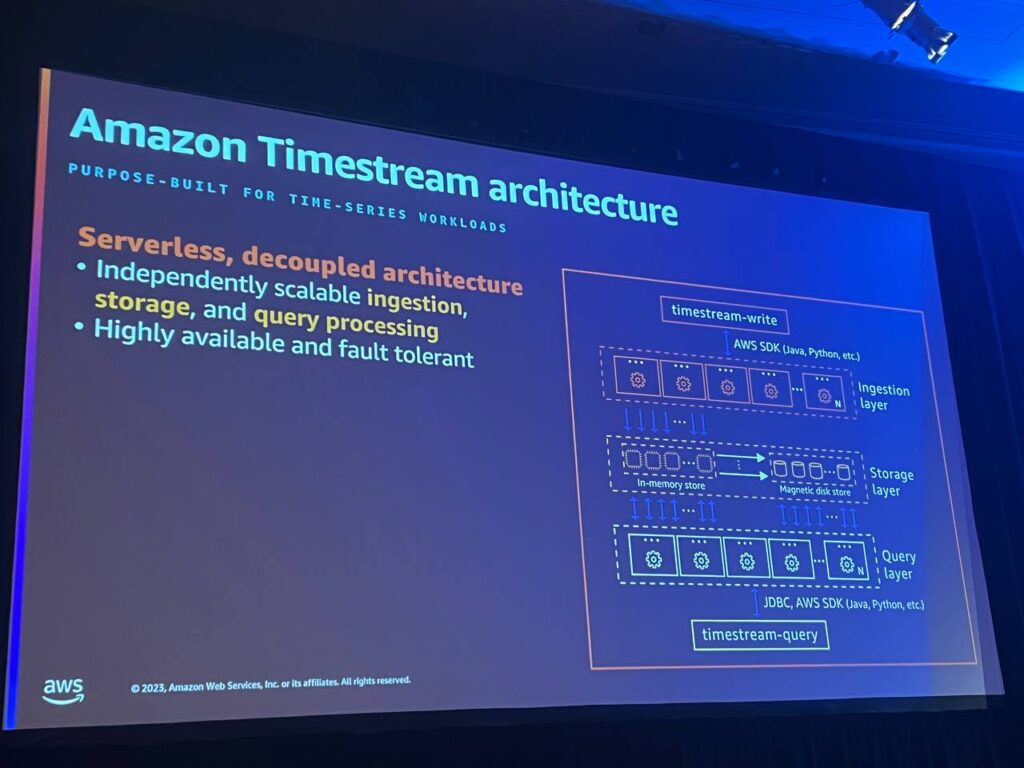
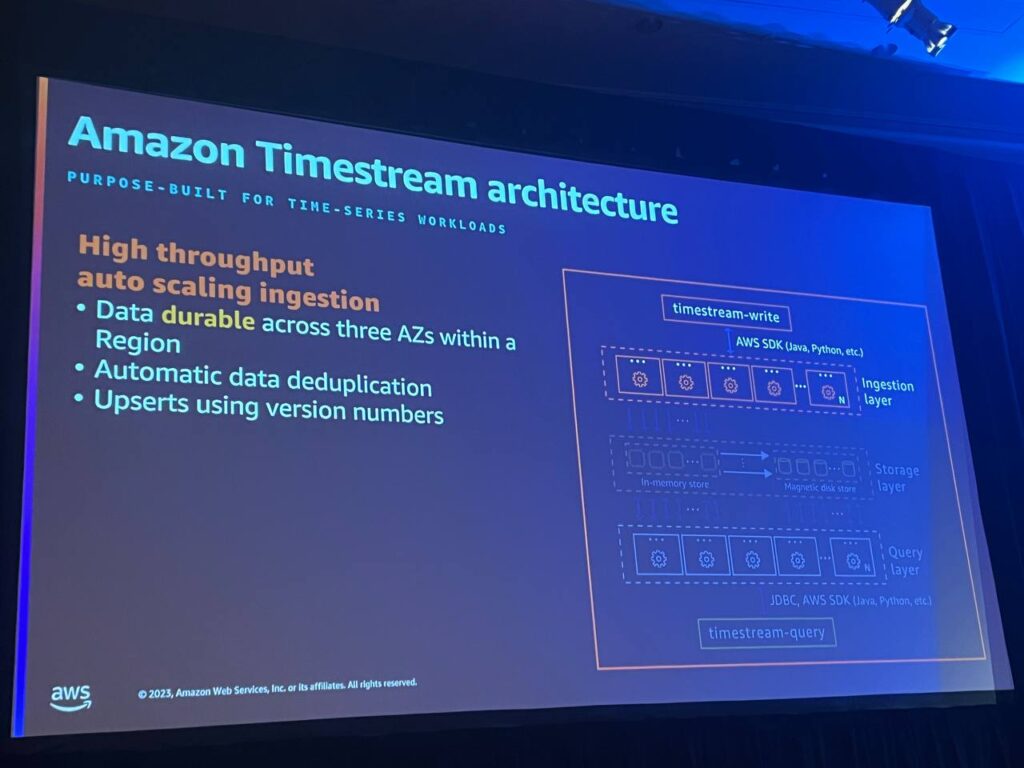


Serverless, Decoupled Architecture
Timestreamは完全なサーバーレスアーキテクチャーを提供します。プロビジョニング、監視、管理するインスタンスがなく、サービス自体がすべてのタスクを処理します。 また、収集、保存、クエリは完全に独立して自動スケーリングされます。各レイヤーはお互いに影響を与えることなく、動的にリソースを割り当て、特定のワークロードに対応します。
High Throughput Auto Scaling Ingestion
インジェクションレイヤーは、データの重複を排除し、特定のワークロードに応じて動的にリソースを拡張することで、毎秒数ギガバイトのデータを処理し、テラバイトのデータをクエリします。
Tiered Storage
データはメモリストレージと磁気ストレージに階層化され、データ保管ポリシーによって自動的に移動されます。メモリストレージは最近のデータに最適化されており、磁気ストレージは大規模な分析と長期ストレージに最適化されています。
Scalable SQL Query Engine
適応型クエリエンジンは、メモリストレージと磁気ストレージを横断するクエリを実行します。ユーザーはデータの位置を考慮することなく、SQLクエリを作成して実行することができ、時間範囲に応じてデータを効率的に取得して処理することができます。

ここには2次元空間があります。X軸に沿って時間があり、Y軸にはパーティショニングを支援する測定値があります。時間によって特別にパーティションを分割し、供給する値によって責任を負うものです。 そして、その空間は、メモリストアと磁気ストアの2つの異なるストレージの間でさらに分割されます。
クエリ時に、エンジンはインデックスに移動し、X軸とY軸に沿ってパーティションを識別し、必要なデータを特定し、処理に必要なリソースを推定し、データを処理します。クエリにはwhere節があり、時間予測器、ある種の時間範囲、そして理想的には測定名と一致する次元予測器を提供することで、関連するデータを見つけるための交差点を計算することができます。Timestreamは自動的にマテリアルデータをパーティション化します。
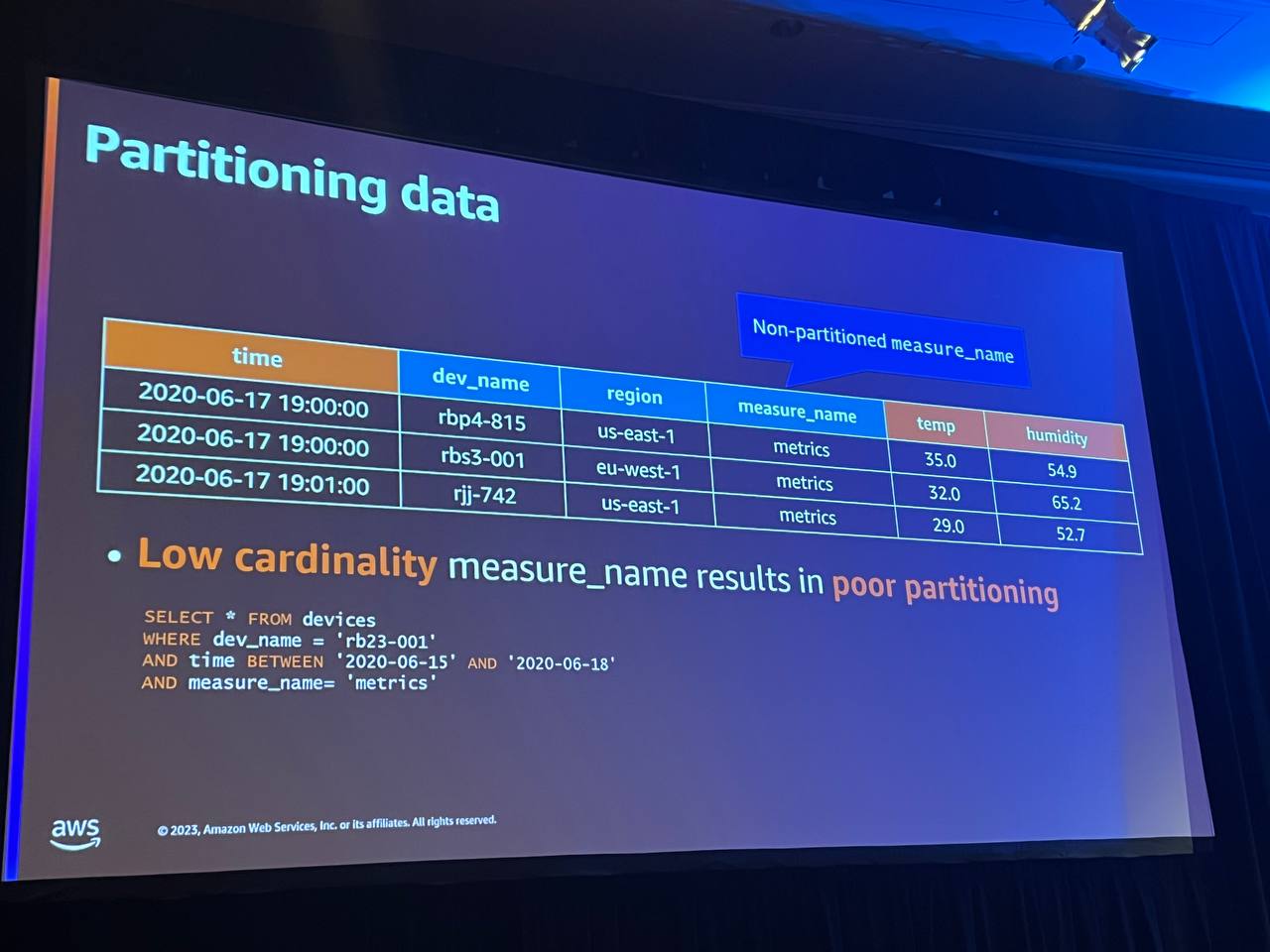
ここには、いくつかのレコードしかないタイムストリームテーブルがあります。 各レコードには、いくつかの次元とメジャーがあり、特別なメジャー名があります。このメジャー名列の値が非常に低いカーディナリティである場合、Timestreamにデータを最終的に分割する機会を与えません。下記のクエリを見ると、時間範囲と時間予測器を提供し、いくつかの測定値に基づいてフィルタリングしています。
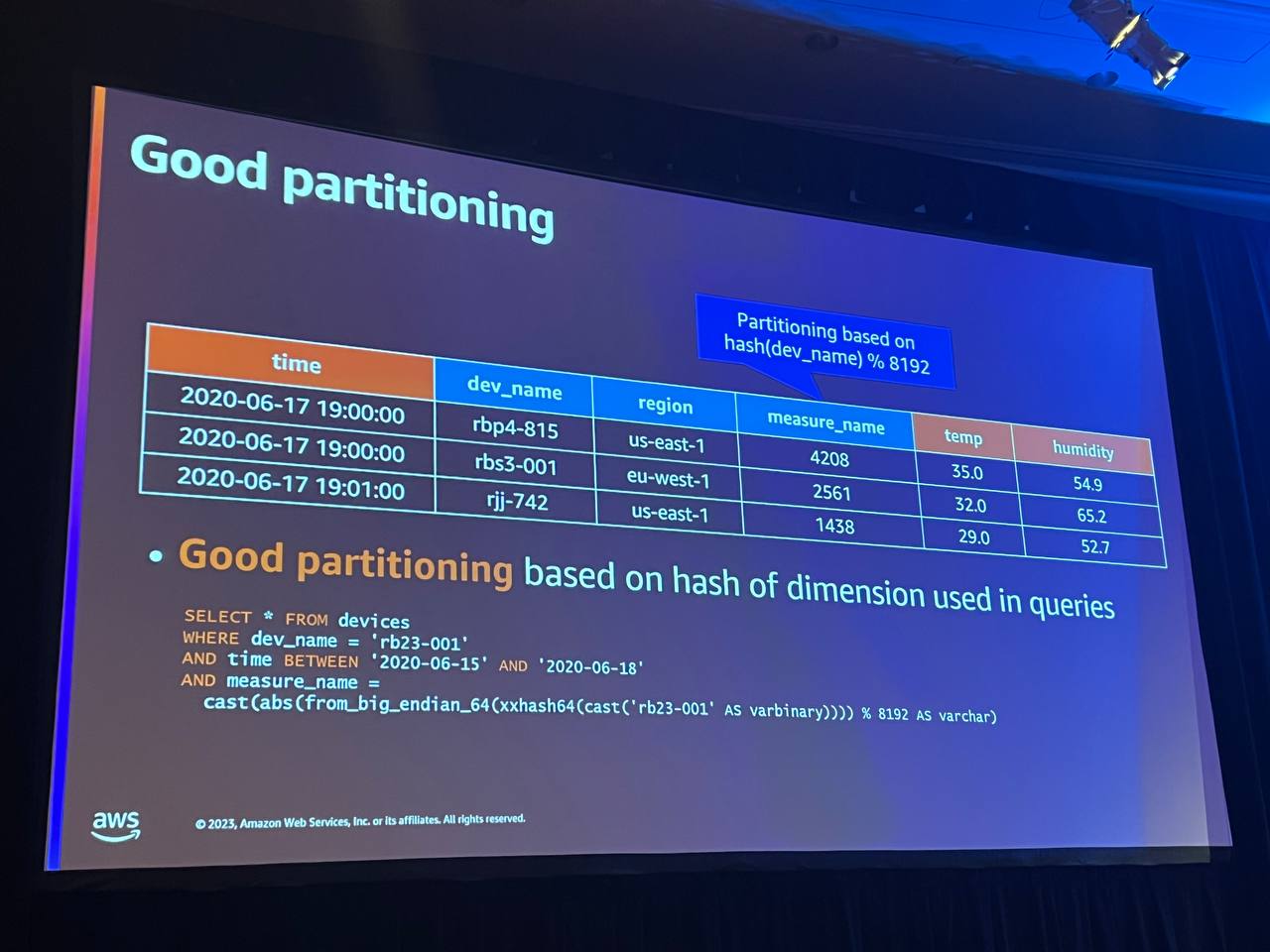
しかし、ここで非常に低いカーディナリティ値を使用した場合、Timestreamは必要以上に多くのデータをスキャンし、クエリを遅くします。 そのため、クエリで頻繁に使用する非常に高いカーディナリティに基づいて、メジャー名列に値を供給します。 たとえば、デバイス名で頻繁にフィルタリングする場合は、デバイス名に対応するメジャーを作成することをお勧めします。しかし、メジャー名列は一意の要素しかサポートできません。 そのため、何十億もの行があっても、8,192個の一意の要素しか持つことができません。 そこで推奨するのは、その高カディナリティ次元の値をハッシュ化し、8192を掛けることです。 そうすれば、すべてのパーティションにかなり均等に分散されます。

適切なパーティション体系と、Timestreamがクエリのニーズの理解に基づいてリソースを動的に割り当てることで、データセットが非常に大きい場合でもうまくスケーリングすることができます。このグラフは、Timestreamのパフォーマンス改善中に実施したいくつかの実験に基づいています。
ここでは、3つの異なるデータセットが収集されており、1日あたり1テラバイトから22テラバイトのデータセットが投入されています。最も大きなデータセットでは、1時間あたり約30億イベントを投入しています。 ここでは、各データセットに対する一連のクエリのパフォーマンスを示すバーが表示されています。これは、クエリと通知とダッシュボードと分析クエリを組み合わせたものです。 ご覧のとおり、これらのインタラクティブなクエリは、データセットサイズが大きくなっても非常によくスケーリングします。 そのため、このグラフの左から右に移動しても、データセットサイズが最大22倍まで大きくなっても、一部の長時間実行されるクエリの全体的なレイテンシーは5倍以上増加しません。
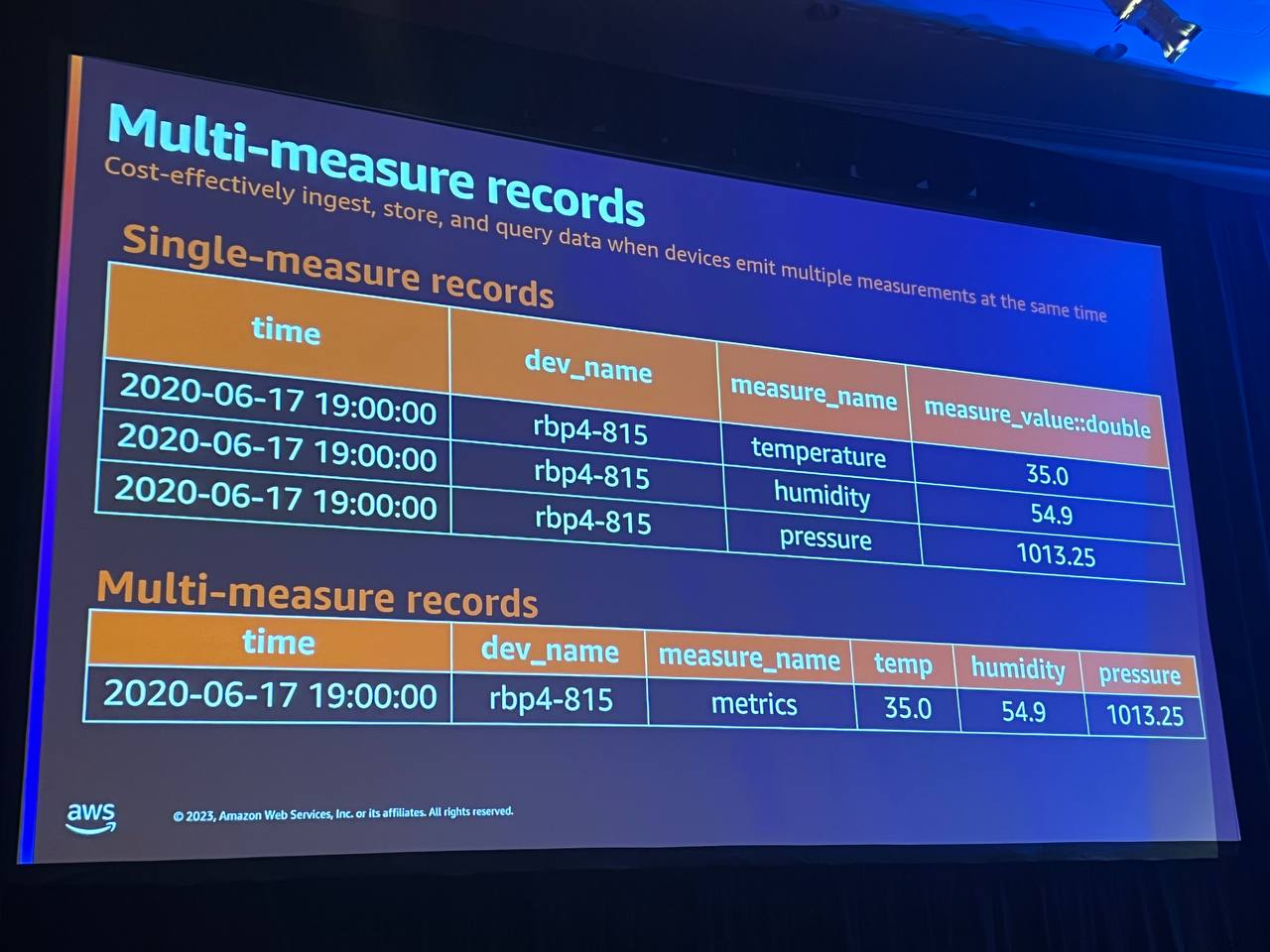
マルチ測定レコードを使用すると、個々のサーバーのすべての測定値を一度に保存できるようになりました。圧縮されたストレージ表現形式を使用し、単一測定値よりも重複する時間、次元が少なくなっています。これにより、ストレージコストが削減され、結果を計算するためにデータをインポートしてスキャンするクエリの長さが短縮されます。マルチ測定モデルは、クエリの簡素化にも役立ちます。
単一測定テーブルに対するクエリがある場合、そのクエリは、CPUとメモリという2つの異なる側面を各区間で比較し、どちらが低いかを判断するだけの簡単なものです。 従来の単一測定モデルを使用する場合、これらの測定値をソートするために、最初にいくつかの共通のテーブル表現を作成し、その後、一番下のselectステートメントで比較を行う必要がありました。 しかし、マルチ測定レコードを使用すると、このような手順は不要で、簡単に比較を行うことができます。

マルチ測定モデルは、クエリを簡素化するのにも役立ちます。ここでは、単一の測定テーブルに対するクエリがあります。このクエリは、CPUとメモリという2つの異なる側面を単純に比較し、どちらが各セグメントの下限境界であるかを判断します。 従来の単一測定モデルを使用する場合、最初にこれらの測定値を並べ替えるためにいくつかの共通のテーブル表現を作成し、次に下部のselectステートメントで比較を行う必要があります。
しかし、現代の測定値の表現やクエリの作成方法を見ると、2つの異なる測定値や測定値が同じ行の異なる列にあるという単純さから、コメント式は必要ありません。 そのため、このようなクエリははるかに簡単に作成でき、理解しやすくなっています。

スケジュールされたクエリは、指定されたスケジュールに従って結果を事前に計算します。スケジュールされたクエリは、Timestreamがサポートする様々なSQLをサポートします。Timestreamは拡張性と高可用性を提供します。また、クエリの結果を計算しながら、一定期間ごとに対象テーブルとそのテーブルの結果を徐々に更新し、テーブル自体は通常、基本データよりもはるかに小さいです。
集約されたデータは、非常に高速にアクセスできるメモリ階層に保持されます。このようなポイント照会クエリは非常に高速にアクセスすることができ、このデータははるかに長く保持されます。

バッチロードを使用すると、CSVファイルやS3から大規模な時系列データを簡単にインポートできます。非常に大きなデータセットの場合は、分割された小さなファイルを推奨し、コンソールまたはCLIを使用して既存のテーブルまたは新しいテーブルにデータをロードすることができます。最も重要なことは、CSVファイルの列とタイムスタンプと寸法および測定値との間のマッピングを定義することです。 CSVファイルのタイムスタンプがメモリ層の保存期間を超えている場合は、注意が必要です。
メモリ層は非常に高い頻度でアクセスするように最適化されているため、タイムスタンプがその期間を超えている場合、Timestreamはそのデータを磁気層に直接書き込もうとします。 ただし、磁気層はデータベースごとに最大250のアクティブなパーティションをサポートし、一度に最大250のパーティションにのみ書き込むことができます。

Unloadは、計算結果を取得し、その結果をS3に書き込めるようにするものです。 S3の結果を取得できるようになった瞬間、データレイク、ML、AI、ETLのユースケースが多くなります。データをApache ParquetやCSV形式で書き込むことができます。データを圧縮してパーティションに暗号化したり、S3キーを使用したり、キー管理システムを通じて顧客が直接管理するキーを使用することができます。
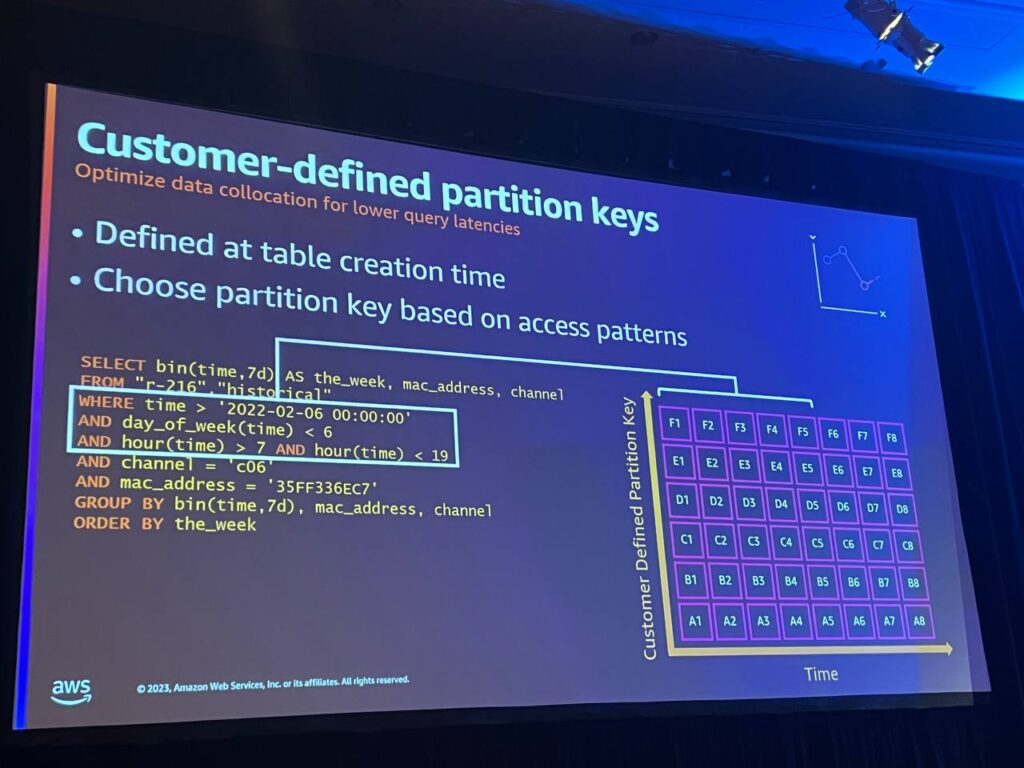

Customer-defined partition keyはテーブル生成時にパーティションキーを定義します。パーティションを定義すると、データが投入されると、Timestreamは自動的にそのデータを分割します。
また、パーティションキーと一致する追加のフィルターを提供することで、Y軸に沿ってパーティションを識別するのに役立ち、データモデリングがより簡単になります。 測定列を定義する必要はなく、テーブルを定義する際にパーティションキーを定義するだけです。これにより、グループが簡素化され、測定値名でフィルタリングする必要がなくなります。単にデバイス名でフィルタリングするだけです。

Epic Gamesがどのようにユーザーエクスペリエンスを向上させたかをご紹介します。

2022年12月現在、EGSはPCランチャーを使用しているアカウントが2億3千万以上あります。月間アクティブユーザー数は約6,800万人に達しています。私たちは、次のような予測可能な毎日の使用パターンを持っています。毎分約83,000件のリクエストを処理し、平均レコードサイズは約250バイトで、最大2.3KBまで急増します。つまり、毎分約23MB、1日あたり約33GBのデータを処理していることになります。

Timestreamは、アーキテクチャと負荷を考慮した後、playtimeを分析するために必要なデータベースとして選択されました。主な要件は、コードの最大限の再利用、特にプレイタイムの保存に使用したコードと同じコードを使用し、総プレイタイムを迅速に取得することでした。Timestreamはそれが可能で、ほとんど手を加えることなく同じオブジェクトでデータベースを作成することができました。
磁気ストレージの構成により、年単位のデータを迅速に処理し、また、年単位のデータを分単位でクエリを実行しても、Timestreamは6倍長いクエリを制限内で正常に処理しました。最後に、非同期的なラムダによるクエリ処理により、パフォーマンスをチューニングする様々な方法が提供されました。

私たちのフルサービスのトラフィックは、予想以上に大きな影響を与えました。容量を計算し、Timestreamでどのように動作するかについて多くの仮定をしましたが、実際に見たのは、7日間分の生の重複排除されたプレイタイムデータの合計が約63ギガバイトになり、平均してフルサービスが毎分約7,000リクエストで攻撃し、12,000リクエストまで増加したことでした。
つまり、Timestreamの63ギガバイトのすべてのデータポイントを毎秒約100回以上検索し、最大で毎秒約200回まで増加したことになります。

API提供データベースのサイズを縮小しました。必要なデータのみをクエリするように調整し、ビジネス要件を満たすために、1日分のプレイ時間を集計し、レーティングとフルサービスに必要なサポートを提供することにしました。
新しいインフラを構築し、スケジュールクエリを活用してデータを変換しました。データ変換のためのスケジュールクエリはデータベース作業なので注意が必要でしたが、複数の領域に分けてダウンサンプリングすることで、問題を防ぐことができました。 この変更により、データベース容量が大幅に削減され、クエリ速度も改善されました。
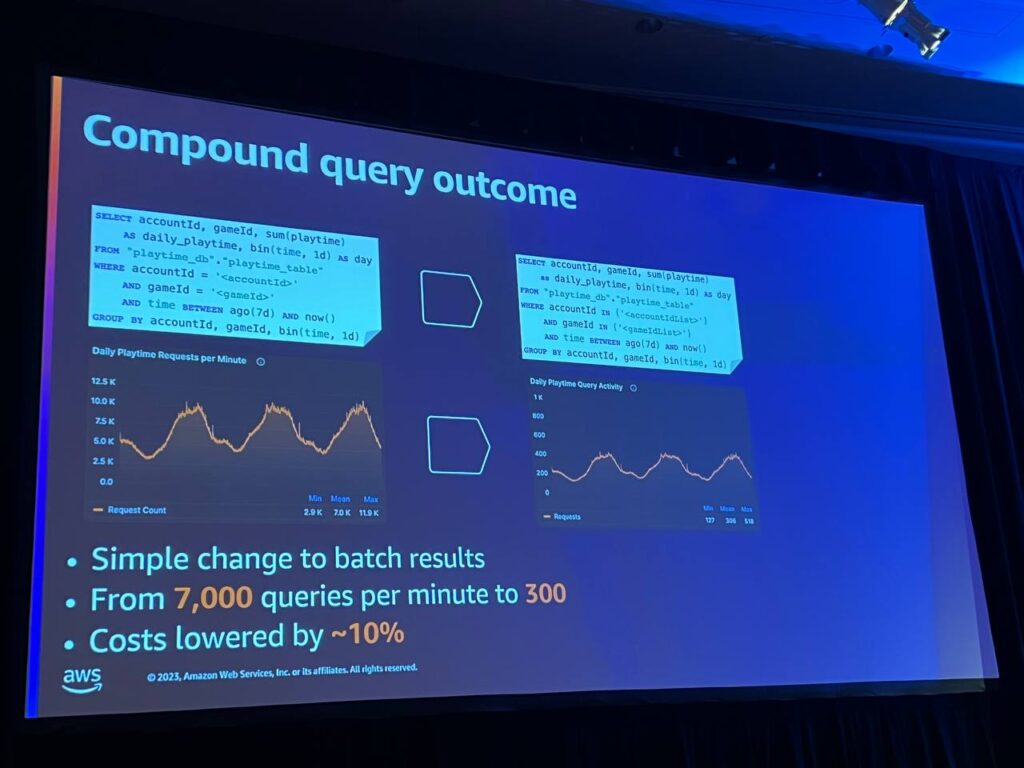
ラムダにバッチ機能を追加し、完全に無関係な複数のリクエストを1つのクエリにグループ化します。 まず、ラムダを再設定して、Playtonリクエストキューからメッセージのバッチを受け取るようにします。ラムダは、すべてのバッチアカウントゲームを単一のタイムストリームに入れ、集約データベースに対してクエリを実行します。タイムストリームからクエリの結果を受け取った後、すべてのメッセージを個々のメッセージに分離します。
その後、それらを応答ポストバックトピックに戻し、呼び出しサービスがクエリをバッチで処理するようにします。このコードにより、クエリの数を元のボリュームの約1/23に減らすことができ、リクエストごとに単一のクエリを実行する場合よりもクエリのスループットが向上し、コストをさらに10%削減することができました。

要約すると、Time Streamを選択した理由はいくつかあります。 第一に、既存の入力フローとオブジェクトを再利用できること、第二に、非同期実装のための合理的なクエリ時間があったことです。また、磁気ストレージの調整可能な機能が気に入っており、長期的なデータを保存するのは非常に簡単でした。 また、1年分のデータを照会するのに非常に高速でした。また、現在の負荷に基づいてパフォーマンスとコストを調整できるアーキテクチャの柔軟性があることがわかりました。 最後に、最初の試行で完全に成功したわけではなく、最初の設計からフィードバックを受け、反復することで成功を収めることができました。
データをダウンサンプリングするためのスケジュールクエリを追加し、パフォーマンスの高い複合クエリを活用するためにリクエストを配置し、データを効果的にパーティション化しました。 また、以前と同じオブジェクトとデータを活用することで、新しい機能を追加する余地ができました。
セッションを終えて
Epic Gamesの事例を見て、サービスのアーキテクチャの設計がいかに重要であるかを体感することができ、問題を解決するために明確な要件定義が必ず必要であり、それを基に最適なものを導入し、数多くのテストを経てアーキテクチャを柔軟に拡張する方法を間接的に体験することができました。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner