MEGAZONEブログ

Take a load off:Diagnose & resolve performance issues with Amazon RDS
負荷を軽減:Amazon RDSのパフォーマンス課題を診断・解決する
Pulisher : Managed & Support Center ムン・ボンギ
Description : Amazon RDSの性能最適化案と運営業務の最適化、そしてRDBMSの性能問題を解決する方法の紹介セッション
はじめに
DBAとして業務を遂行しているため、運営中のAWS RDSの性能最適化方法を聞きたかったし、性能改善ヘルパーとCloudWatchの機能を最大限に活用してRDSの運営業務を最適化し、RDBMSの性能問題を効率的に診断して解決する方法を見つけたいと思いました。
セッションの概要紹介

今日のセッションでは、Amazon RDSのモニタリングとAmazon auroraのパフォーマンスと診断について説明します。
まず、Amazon RDSについて少し説明するコンテキストを設定することから始め、次に、データベースのパフォーマンスの問題を克服するのに役立つさまざまな監視サービスとツールについて詳しく説明し、第2部では、Amazon RDSのデータベースパフォーマンスの診断とトラブルシューティングに関連する最新のイノベーションのいくつかを紹介します。
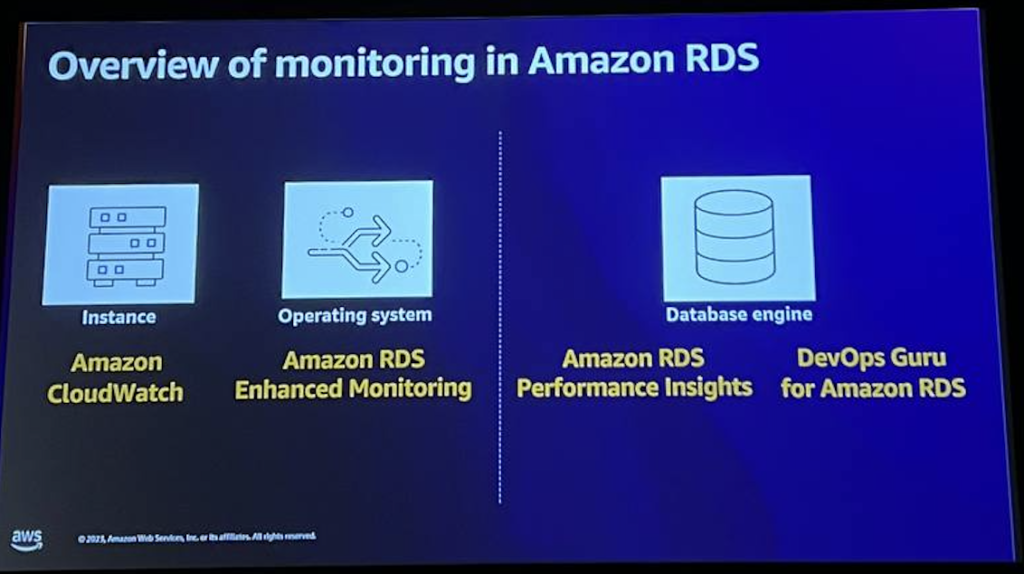
Amazon RDSは、完全に管理されたリレーショナルデータベースサービス運営作業の自動化で、アプリケーション開発に集中できます。Amazonのモニタリングツールを紹介します。Amazon CloudWatchは主にインスタンスレベルのモニタリングに使用し、RDS Enhanced Monitoringはオペレーティングシステムレベルのより深い可視性を提供し、RDS Performance Insightsはデータベースエンジンレベルのパフォーマンスモニタリングと診断を行い、Amazon DevOps Guru for RDS:機械学習を使用してパフォーマンス問題の予測と推奨事項を提供します。

Amazon CloudWatchは主要なAWS監視サービスであり、すべてのデータベースリソースとアプリケーションスタック全体を監視するために使用できます。 また、CPU使用率、ストレージ出力ストレージ、IOPSネットワーク使用率、その他の数十のインスタンスレベルの指標など、Amazon RDSのインスタンスレベルの指標を監視することもできます。Amazon RDSの強化された監視は、詳細なオペレーティングシステムのメトリックをより深く可視化します。
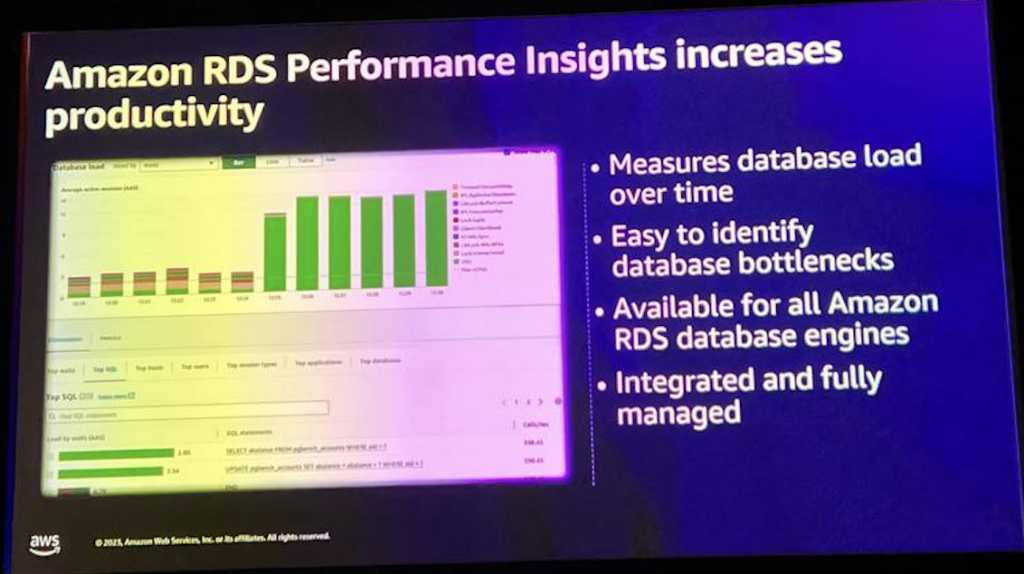
RDS Performance Insightsはインストールする必要がなく、データベースのパフォーマンス問題を診断し、解決するのに効率的です。データベースエンジンレベルの性能モニタリングと診断を行い、セッションと待機イベントを通じたデータベース負荷の測定が可能です。 また、深い分析による性能問題の解決と最適化を可能にします。
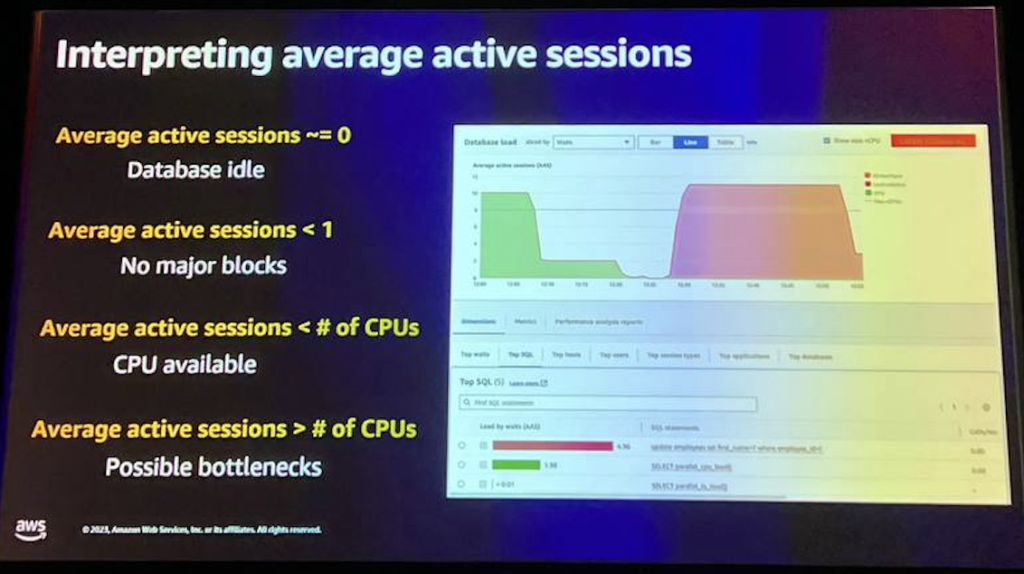
Performance Insightsは、データベースの負荷を測定します。 負荷を測定する際には、平均アクティブセッションで表され、毎秒毎にサンプリングし、各アクティブセッションに対して以下を収集します。SQL、CPU、I/O、ロック、コミットログ、wait eventの平均値を測定します。 そして、databaseの多次元分析 深刻な性能低下や最低性能が発生しないようにデータベース調整を検討することができます。

このプレゼンテーションで見たすべての内容を活用して、実際のデータベースパフォーマンスの問題を解決してみましょう。
そのため、いくつかのメトリクスを詳細に分析し、おそらくいくつかの問題の解決策が見つかることを期待しています。

オンラインウェブストアのあなたのチームは、とりわけ最近の注文ページを担当しています。
そのような日だったのですが、いくつかのアラームが鳴り、更新が非常に遅くなり、時間がかかるという報告もあります。これは明らかに良くない状況であり、顧客を満足させるために非常に迅速な対策を講じる必要があります。

データベースのパフォーマンスであろうとシステムのパフォーマンスであろうと、パフォーマンスの問題を扱うときは、通常、次の3つの質問に答える必要があります。 まず、問題の根本的な原因は何なのか、2番目の質問は、誰が責任を負うのかということです。 それが人間であれば、私たちは彼らと対話することができ、それが機械であれば、私たちは彼らと推論する別の方法を見つけることができます。 そして、あなたが探したい答えは、「どのように修正できるのか」という質問に対するものです。
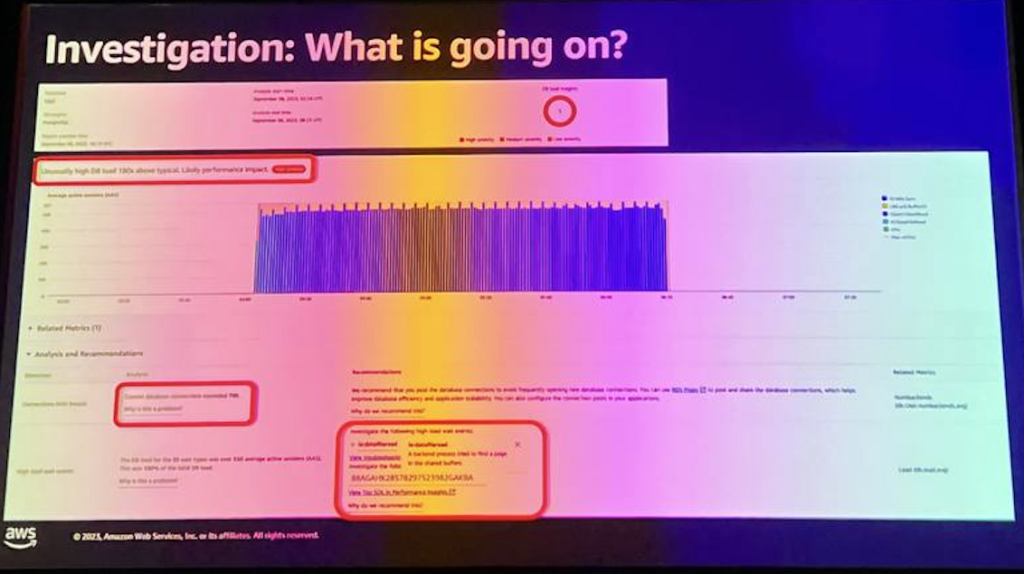
それでは、最初の質問に答えましょう。 何が起こっているのでしょうか?データベースを長々と表示するページ内の主なパフォーマンスを見ていきます。 ご覧のとおり、データベースが正しく機能していない兆候がいくつかあり、大きな青いスパイクがその証拠であることがわかります。
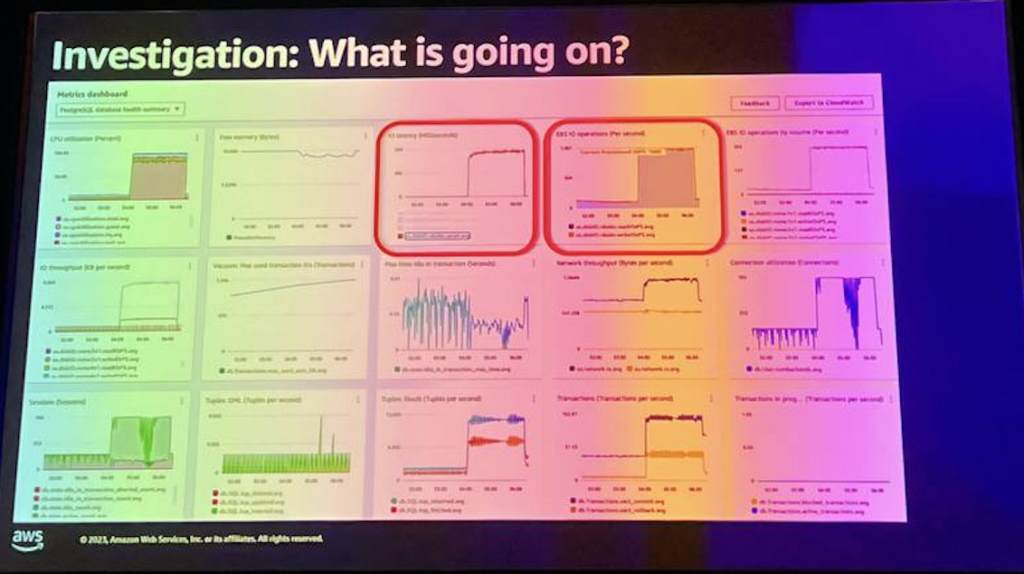
これが私たちが持っている典型的なLTPシステムです。
これは過渡的なシステムであり、リクエストごとに500ミリ秒程度の時間がかかるのを見るたびに、そのシステムの範囲内であればおそらく大丈夫だと言えます。
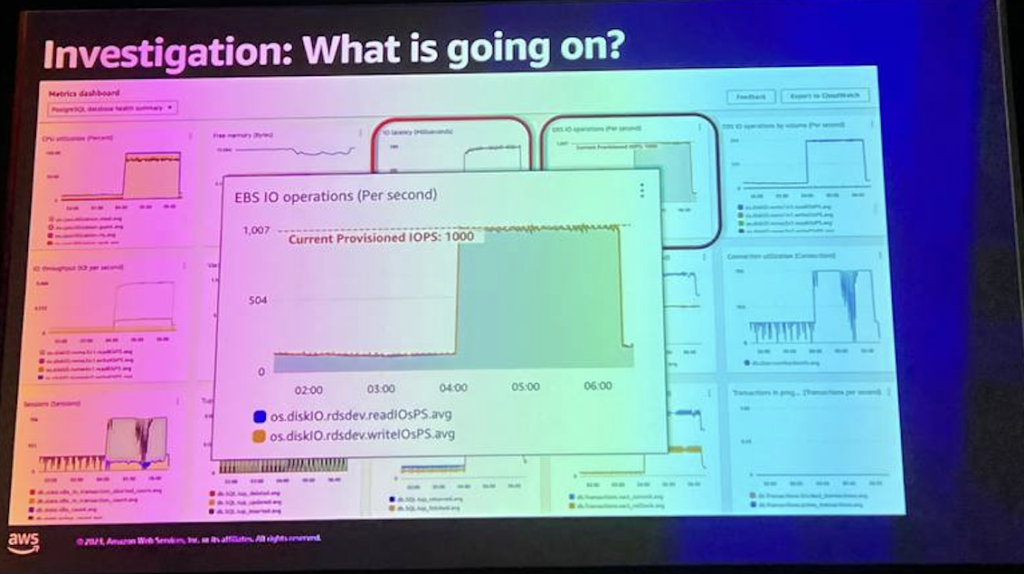
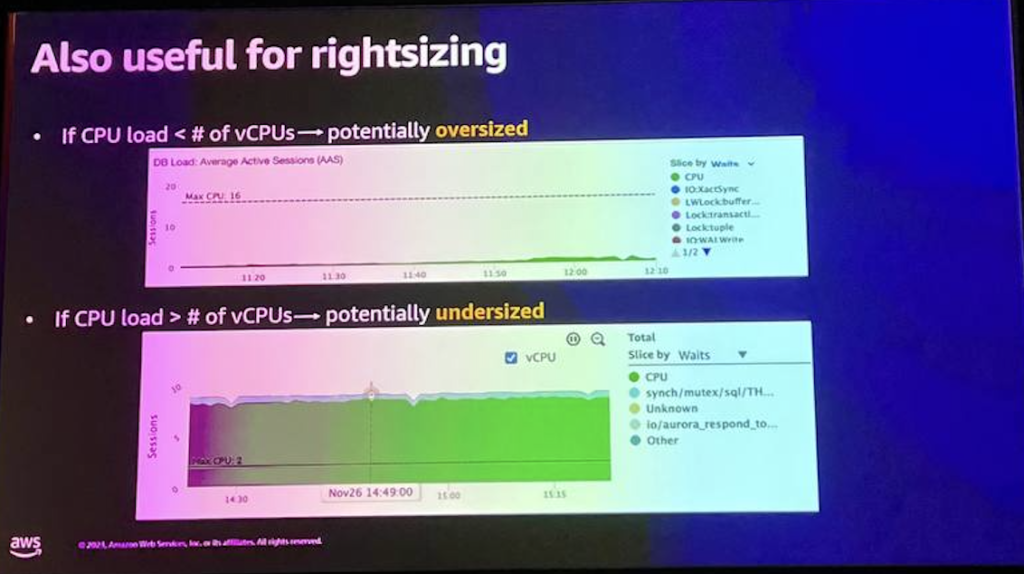
しかし、この場合、2番目のチャートはもっと多くのことを示しており、1000を超えるやや興味深い数字で直線的または停滞しています。この場合、データベースは実際にEBSボリュームを使用しており、このボリュームにはそのボリュームに割り当てられたジョブ数が設定されています。
グラフを拡大して、誰もがここで何が起こっているのかをはっきりと見ることができるようにします。 そして、この場合、私たちは特にそれを越えようとしているように見え、それが結果として私たちの問題になり、それが理由です。
これが私たちが見ることができる唯一の興味深い測定パターンでしょうか?答えは「いいえ」です。
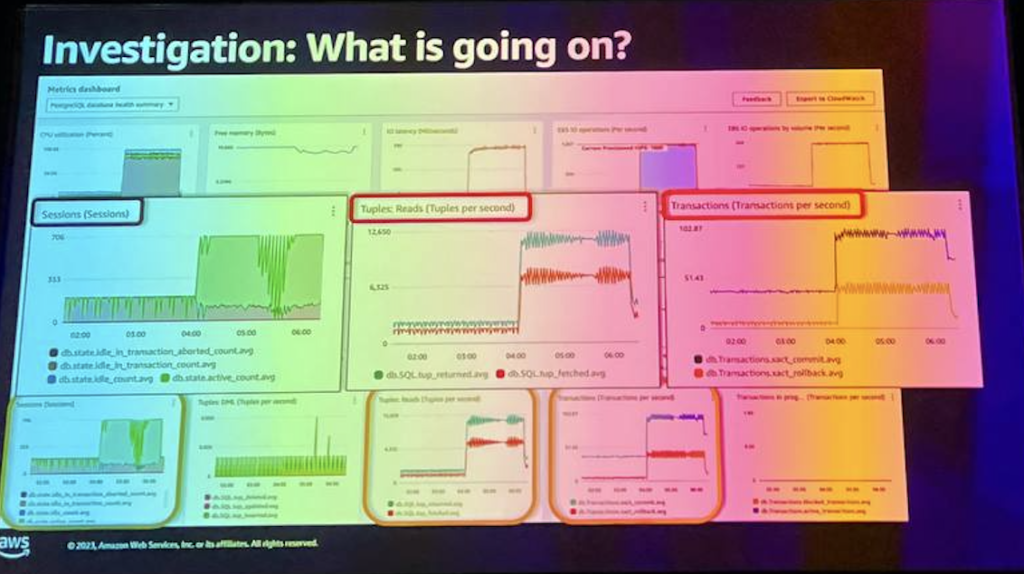
このチャートを理解する最善の方法は、指標の名前を読んで、その指標で何が起こっているのかを文章にまとめることだと思います。 そこで、この時間帯に急増したアクティブセッションの数から始めてみましょう。

注文ページを更新すると、そのクエリが右側に来るようにするクエリではなく、ご覧のとおり、この正方形は実際に問題を引き起こしている正方形とはかなり異なることがわかります。 したがって、データベースのパフォーマンスを低下させるように見える追加のワークロードがありますが、この新しいワークロードはどこから来るのでしょうか?
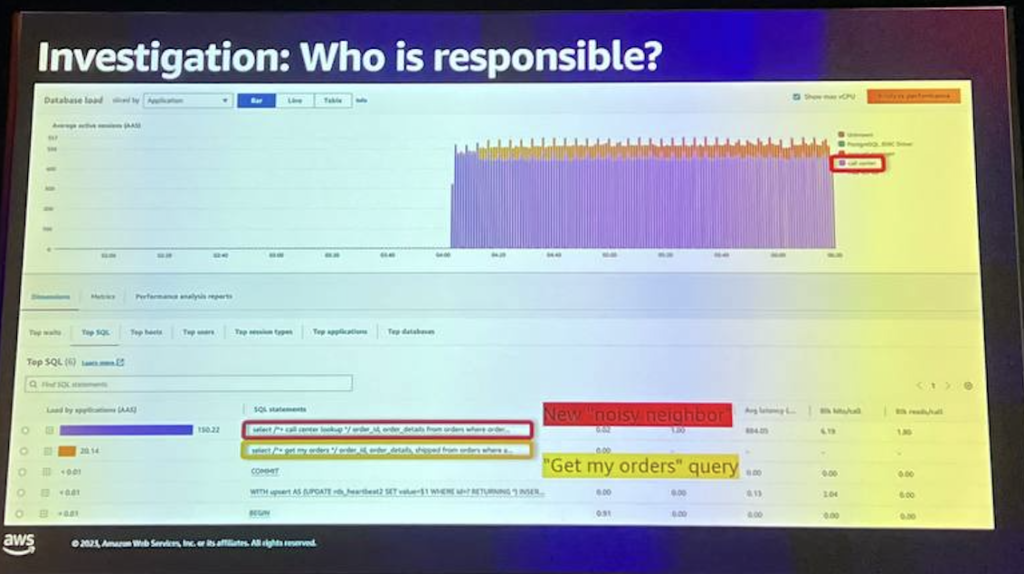
これまでにわかっていることを簡単に要約すると、EBSボリュームイオンが枯渇しているという事実に関連する非常に深刻なIOの問題があり、その原因も見つかりました。
これは、データベースで多くのアクティビティを開始および実行する追加のコールセンターアプリケーションであり、これがそもそもスパイクを引き起こした可能性が高いです。
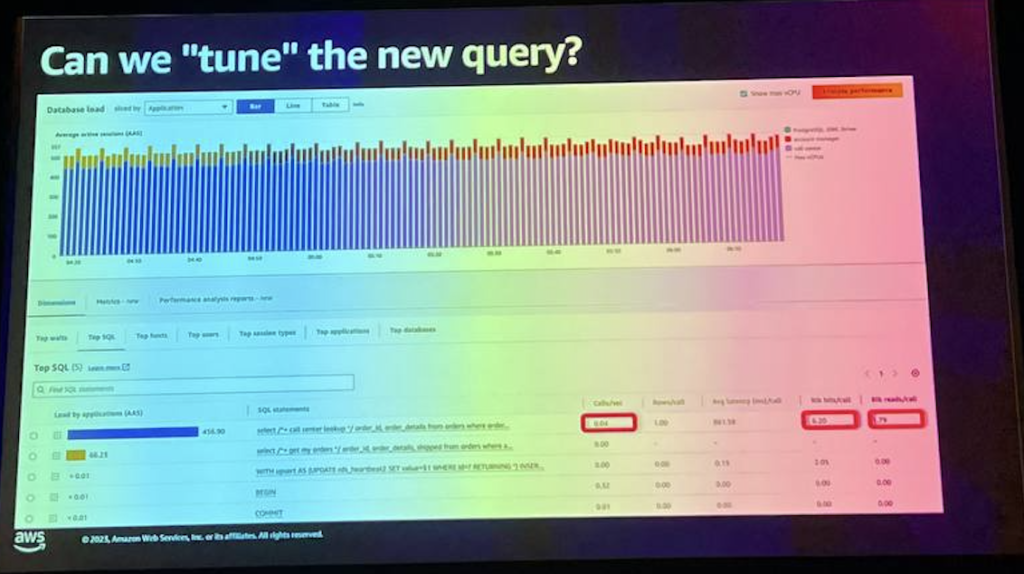
幸いなことに、Performance Insightsは、クエリのパフォーマンスを評価するために使用できるSQL統計を提供します。しかし、ここでの悪いニュースは、私たちが見ている数字が非常に小さいということです。 そして、これが意味することは、正方形が可能な限り効率的である可能性があるため、そこには主要なツールがないということです。
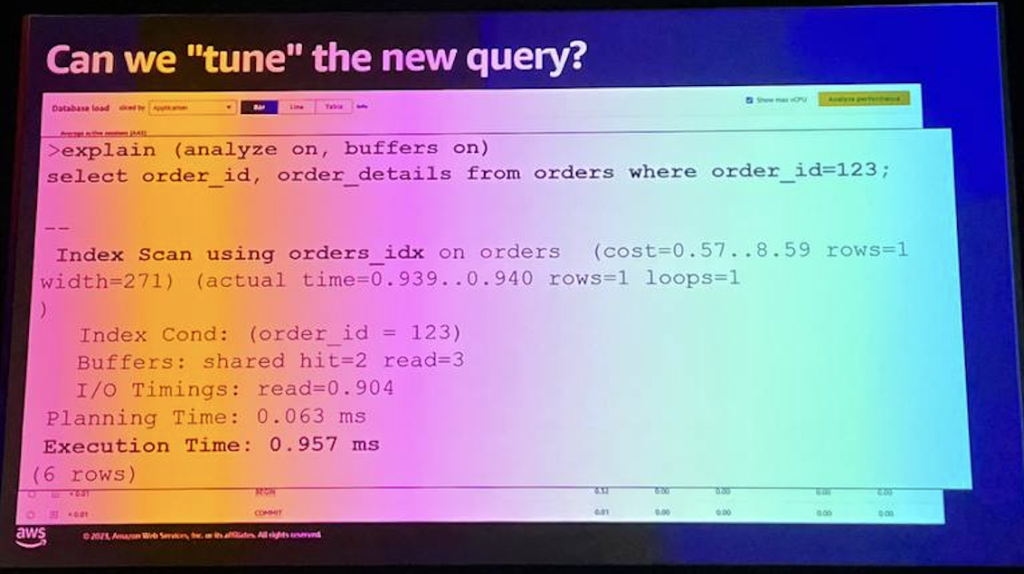
もう少し詳しく見て、この方法で実行計画を確認することができます。ここに郵便番号の専門家がいる場合、このタイプの質問に対して、これはすぐに使用できるほぼ完璧なものであり、改善する大きな機会がないことを確認することができます。
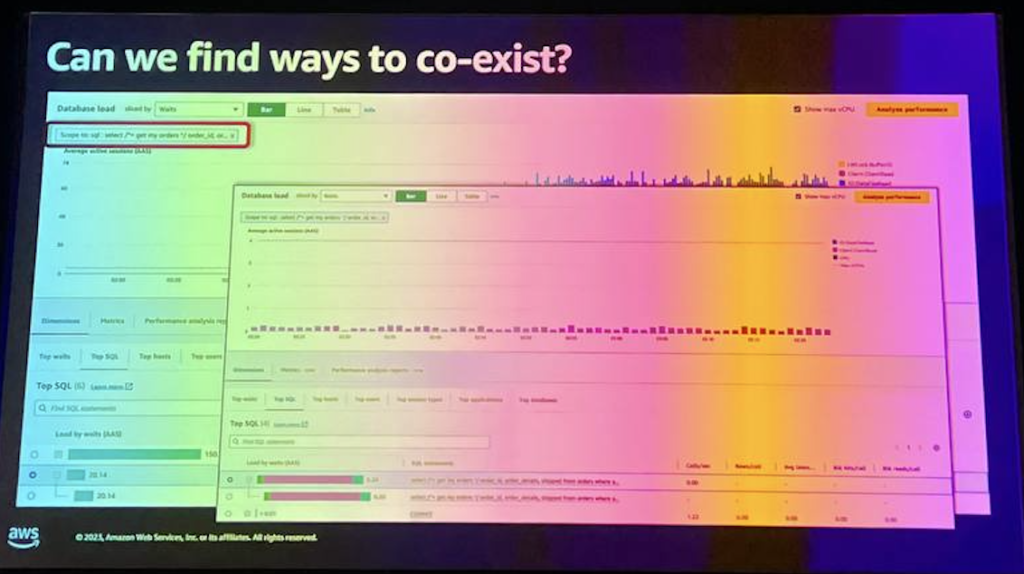
クエリ、特に表現式の状態とサイズのパフォーマンスの観点からクエリを見てみましょう。 データベースの負荷チャートを再構成して、特定のアクティビティのみを表示したり、単一の基準のみに対応するアクティビティを表示することができます。
下部のクエリをクリックすると、内部パフォーマンスが表示され、そのクエリに対してのみグラフが再配置されます。
ここで見ることができるのは、QUに対するデータベースの負荷スパイクが私たちのデータベースに対するデータベースの負荷スパイクとほぼ同じであることです。 私たちは、query統計を通じて、私たちのクエリに対するこのクエリの実行速度が実際に適切に変更されていないことを確認することができます。
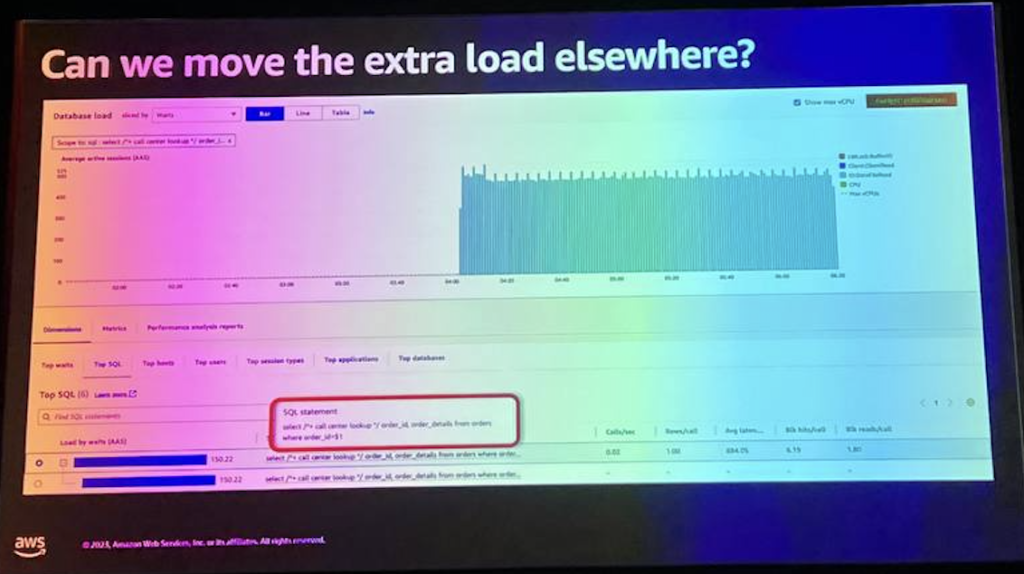
この場合、クエリが確実にメモリで実行されていたため、この図にはほとんど重み付けが適用されていないことがわかります。 では、何が変更され、このグラフを見てどのような結論を導き出すことができるのでしょうか。

“noisy neighbor”の問題を解決するには?
・調整できますか?
いいえ、新しいクエリは可能な限り効率的です。
・私たちはそれと共存できますか?
・短期的には、IOPSの容量を使い果たしたので、IOPSを追加することができます。
・短期から中期的に: より大きなボックスに移動して、より多くのメモリを使用することができます!
・他の場所に移動できますか?
・短期/中期:読み取り専用ワークロードです。読み取り専用レプリカで実行するか、Amazon ElastiCacheにキャッシュすることができます。
セッションを終えて
AWS RDS DBA業務を遂行する上で、Amazon CloudWatch、Performance Insightsは必ず必要な存在です。この2つを通じてRDSのモニタリングやトラブルシューティングを行うのですが、セッションで上記の2つを使って原因を把握して対策することまで詳しく説明してくれて良かったです。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner