MEGAZONEブログ

アプリケーションの地域認識による回復力の自動化
Automating resilience with regional awareness for your applications
Pulisher : Managed & Support Center キム・ソンド Description : サーバーレスフレームワーク全体のワークロードをモニタリングする方法について紹介したChalk Talkセッション。
はじめに
AWS Step Function, Amazon Simple Notification Service (SNS), Amazon EventBridge, Amazon Simple Queue Service (SQS), AWS Lambdaなどサーバーレスフレームワークで構築されたビジネスの継続性戦略を管理し、サーバーレスフレームワーク全体のワークロードをモニタリングする方法を確認するためにセッションに参加しました。
セッションの概略紹介
アプリケーション内で高いレベルの復元力を持つためにどのような方法があるかを確認するセッションです。

アーキテクチャではRTO、RPO、SLAなど考慮すべき事項がたくさんあります。
RTOはRecovery Time Objectiveで、何らかの事故が発生した時、システムやデータを復元するのにかかる時間を指します。
RPOはRecovery Point Objectiveで、何らかの事故が発生した時、業務中断時点からデータを復旧できる基準点を意味します。
SLAはService Level Agreementで、サービスプロバイダーから提供されるように結んだ契約を意味します。
DRは大きく4つに分けることができます。
- Backup and restore
- Pilot light
- Warm standby
- Multi-side active-active
長表の右側に行くほど、より多くの費用が課金され、より迅速な復旧が可能になります。
Pilot Lightは点火用の火種という意味で、追加の段階が実行されるまで(リソース生成)リクエストを処理することができません。 Warm Standbの場合は、運用リージョンより少ない量のワークロードを処理できるようにリソースを生成しておくことを意味します。
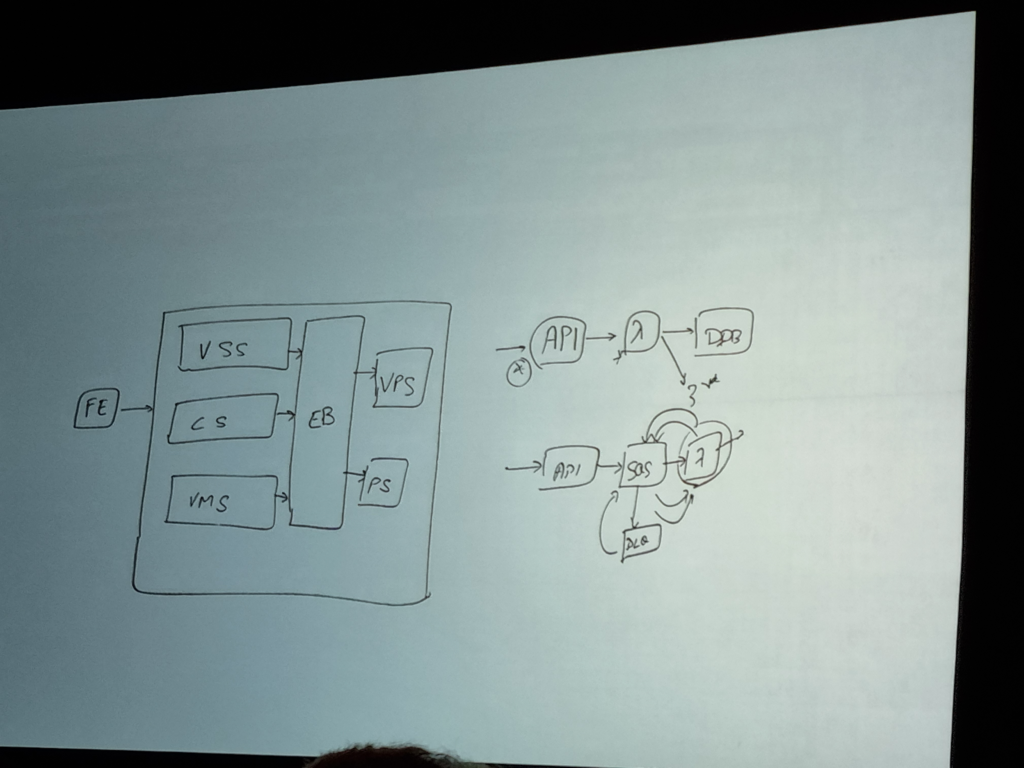
用語説明
・VSS: Video Streaming Service
・CS: Channel Service
・VMS: Video Managed Service
・EB: AWS Event Bridge
上記の全てのマイクロサービスはAWS Event Bridgeで統合(Bus)されると例示します。
サービスは単一Regionあるいは復元力のためにマルチRegionで使うことができます。
サービスはそれぞれのAPIで構成されていてAWS Lambdaに直接統合することができますが、DLQ(Dead Letter Queue)やBackendの失敗(Lambdaコード障害、断続的なコード障害、一時的なネットワーク問題、データベース接続問題など…)に備えてSQS(Simple Queue Service)を追加することができます。
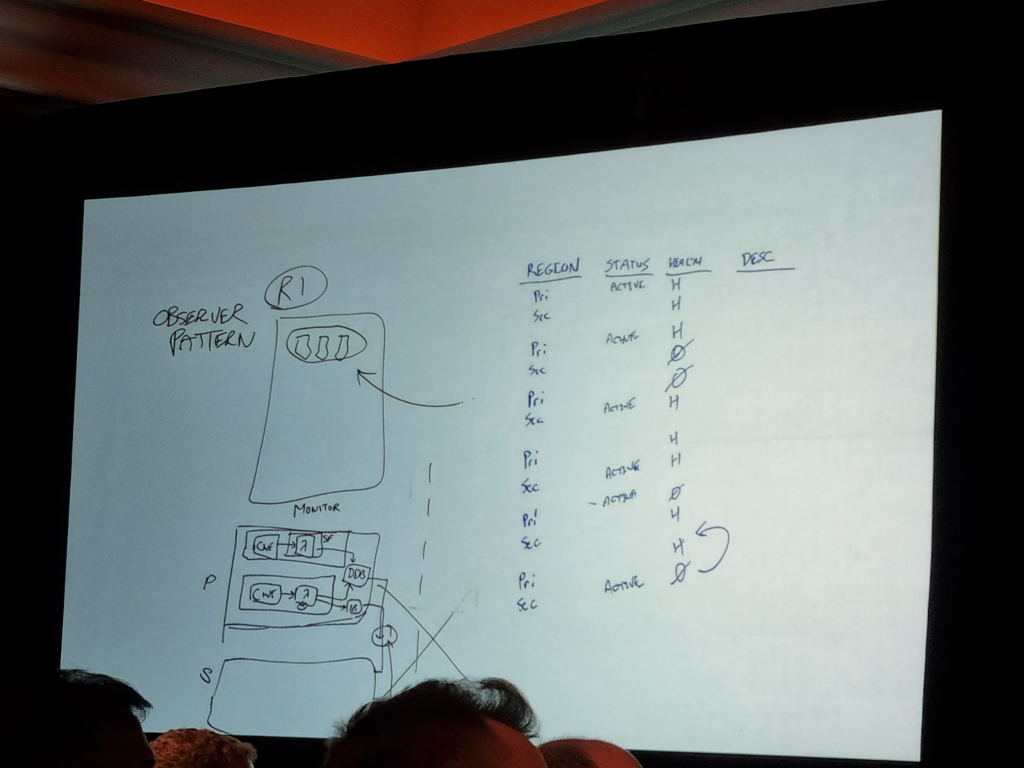
Primary RegionとSecondary Regionがあると仮定した時、Region障害が発生したとします。
まず、Primary RegionでSecondary Regionをモニタリングし、Secondary RegionでPrimary Regionをモニタリングするアーキテクチャを採用する必要があります。
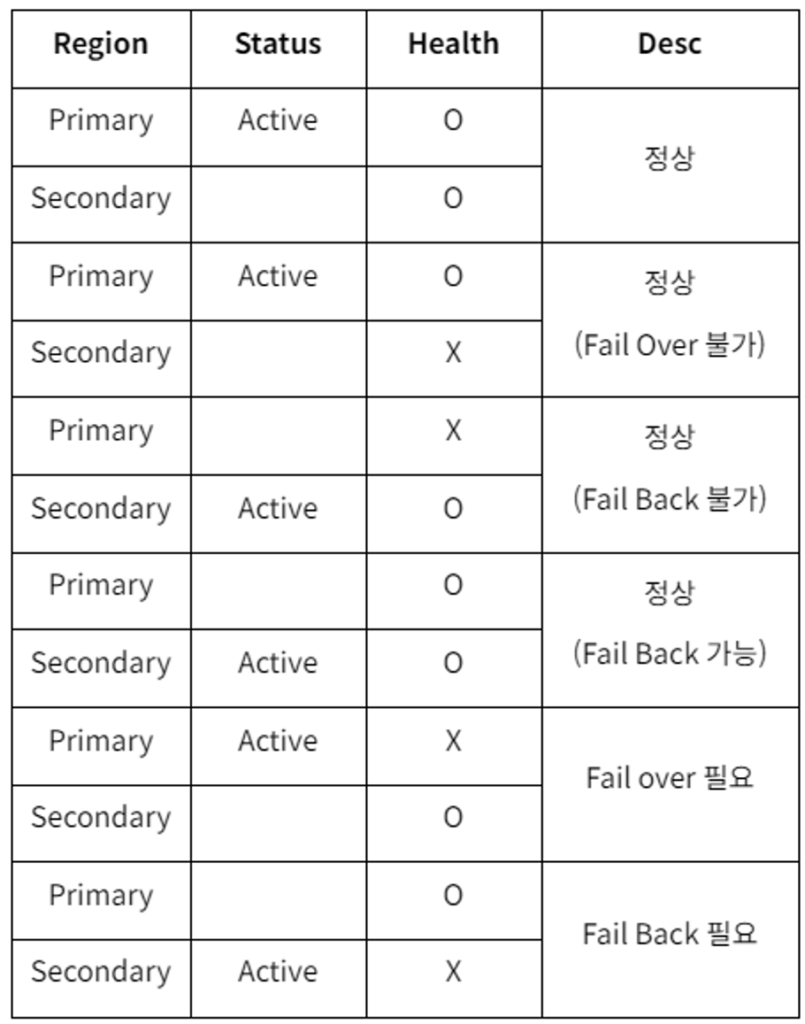
下記の表のようにFailover / Failbackを進めることができます。
(Primary Regionを主に使用する顧客の例です)

セッションを終えて
様々なFail OverとObserver Patternの理解に役立ちました。
Chalk Talkの特性上、多くの議論をすることができ、様々な人の意見を聞くことができるセッションでした。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner