MEGAZONEブログ

What’s new with AWS observability and operations
AWSのオブザーバビリティとオペレーションの新機能
Pulisher : Strategic Tech Center チャン・セジョン
Description : AWSを通じて様々な環境でアプリケーションとインフラを管理・運営しながら、どのような目標を持って取り組むべきかについて紹介するセッション。
はじめに
今回のリインベントでAWSの運営に関するモニタリングについて、最近新しくリリースされた機能についてまとめて説明してくれるセッションがあり、今まで知らなかったモニタリング機能があれば参考になるのではないかと思い、登録して参加しました。
セッションの概要紹介
クラウドで運営したり、既存の運営をAWSにマイグレーションするなどのAWSを通じて様々な環境でアプリケーションとインフラを管理・運営しながら、どのような目標を持って運営・モニタリングをすべきかについて説明します。
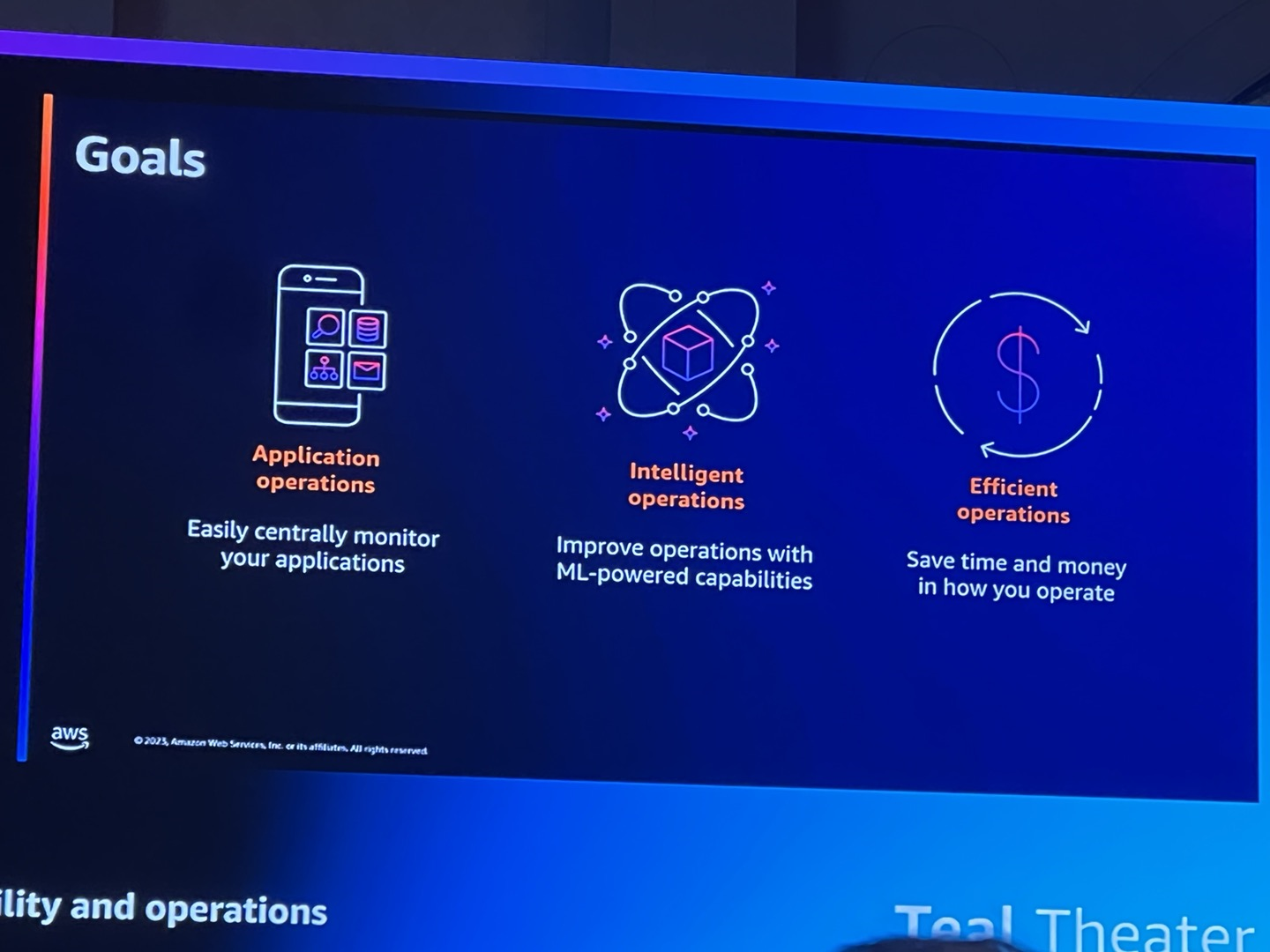
私たちがAWSでサービスを運営する上で、持っていくべき目標があります。
1.アプリケーションを中央で簡単にモニタリングできるようにすること
2.MLベースの運用改善
3.運営にかかる時間とコストの削減
この3つです。

上記の目標を達成するためには、3段階の繰り返しサイクルが必要です。
異常兆候を検出し、検出された異常兆候に対して状態調査及び根本原因分析を行い、その事案に対して対策を講じます。さらに、このような運用障害から学習を通じた自動化された措置が行われるようにします。

運用とモニタリングをより簡単に行えるように、新しく追加された機能についてご紹介します。
その一つが、Cloudwatchですぐに使用可能なアラームの推奨事項を提供します。推奨事項では、設定するアラートしきい値も提案します。これらの推奨事項に従うことで、AWSインフラストラクチャの重要な監視を見逃さないようにすることができます。

運用とモニタリングをより簡単に行えるように、新しく追加された機能についてご紹介します。
その一つが、Cloudwatchですぐに使用可能なアラームの推奨事項を提供します。推奨事項では、設定するアラートしきい値も提案します。これらの推奨事項に従うことで、AWSインフラストラクチャの重要な監視を見逃さないようにすることができます。
Amazon CloudWatch Application Signalsは、アプリケーションパフォーマンスのベストプラクティスに基づいてアプリケーションを自動的に計測するのに役立ちます。アプリケーションパフォーマンスの要求量、可用性、待ち時間など、最も重要な指標を示す標準化された事前構築されたダッシュボードを取得できます。 また、アプリケーションにSLO(サービスレベル目標)を定義して、ビジネスにとって最も重要な特定のタスクを監視することもできます。

Amazon Managed Service for Prometheus Collectorは、クラスター内でAgentを実行することなく、Amazon EKSアプリケーションとインフラからメトリックを検索・収集することができます。自動的にサイズを調整し、拡張してAmazon EKSアプリケーションを安定的に監視することで、メトリック収集を最適化することができます。
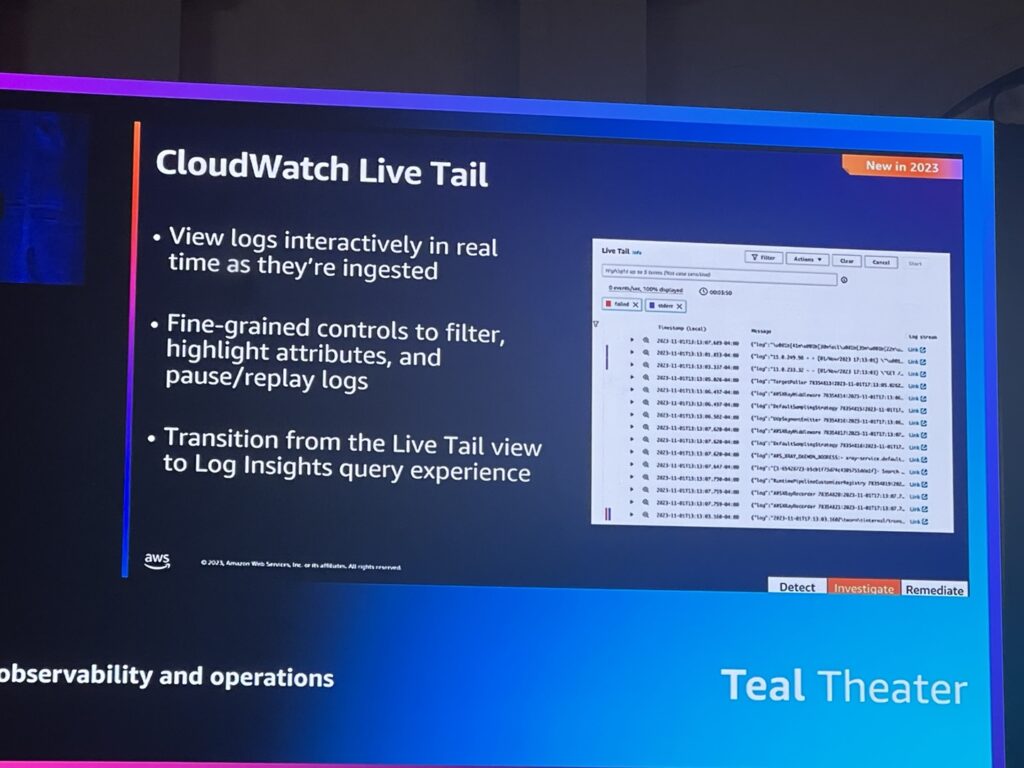
CloudWatch Logs Live Tailを使用すると、収集された新しいログイベントのストリーミングリストを表示し、インシデントを迅速に解決することができます。収集したログをほぼリアルタイムで表示、フィルタリング、強調表示することができるため、問題を迅速に検出して解決することができます。指定した項に基づいてログをフィルタリングし、指定した項を含むログをハイライト表示することで、目的の項目を素早く見つけることができます。
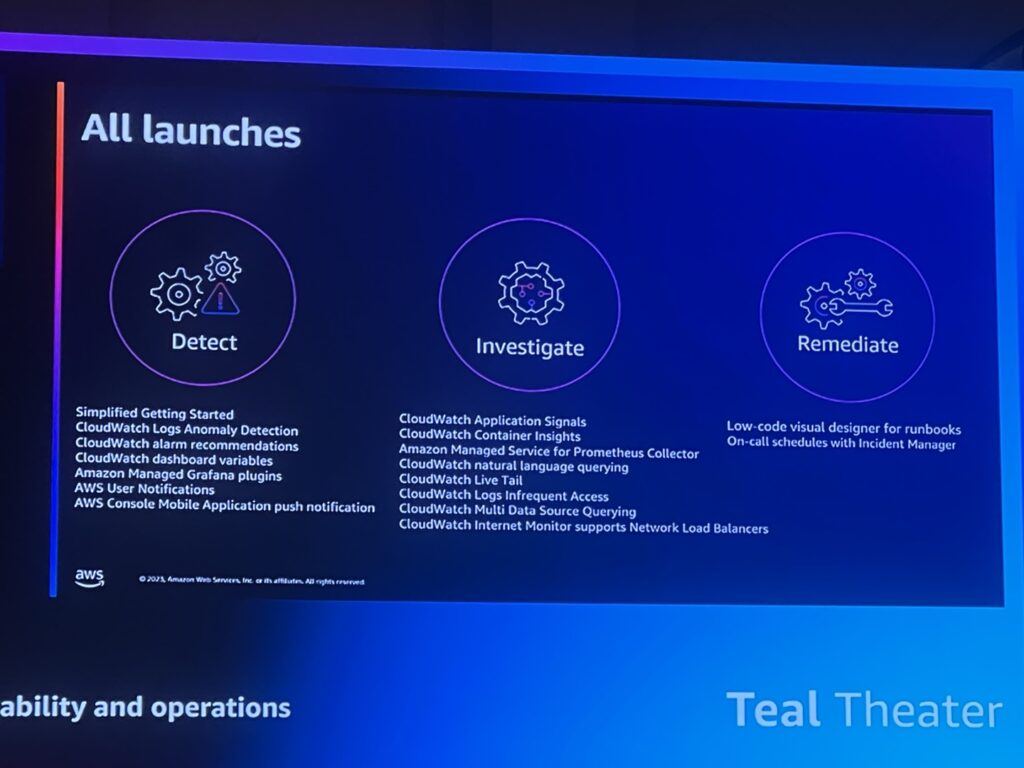
異常兆候検出、原因分析、障害措置の各段階ごとに新規に立ち上げたサービスをまとめてみると、この文書のようになります。 これらの新規サービスを該当段階に適用すれば、私たちが先に目標としたモニタリングの集中化、ML基盤の運営改善、運営にかかる時間とコストの削減を実現することができるでしょう。
セッションを終えて
新しいプロジェクト構築をしてからロギングやメトリックモニタリングについて毎回手動で構築していましたが、セッションで紹介してくれたサービスを使うと初期に素早くダッシュボードなどを構築することができそうで良さそうです。 また、AWSを使用していますが、このような新規サービスがリリースされたことをよく知らなかった自分を反省して振り返るきっかけになるセッションだったようです。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner