MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #CMP331-R|AWS TrainiumとAWS InferentiaでLLMを構築し、Rayを使用して高速化
CMP331-R | Build and accelerate LLMs on AWS Trainium and AWS Inferentia using Ray
セッション概要
- タイトル
- CMP331-R | Build and accelerate LLMs on AWS Trainium and AWS Inferentia using Ray
- スピーカー
- Chakravarthy Nagarajan, Principal Solutions Architect AWS
- Aniruddha Deodhar, Principal Specialist, Gen AI Accelerated Computing AWS
はじめに
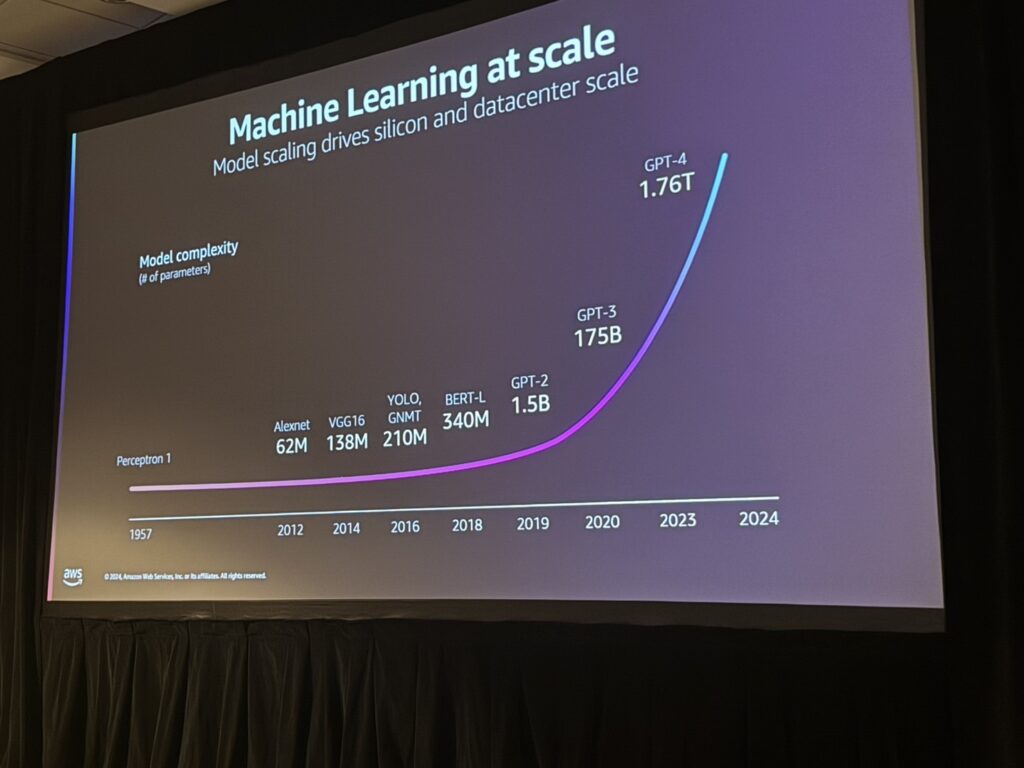
AWSが提供するLLM(大規模言語モデル)開発・運用環境は、最新のTrainiumとInferentiaチップを活用し、大規模なAIモデルをより効率的かつコスト効果の高い形でトレーニングおよび推論可能にしています。
背景と重要性:
現在、LLMの規模は爆発的に増加しており、GPT-3からGPT-4に至るモデルのパラメータ数は175Bから1.76Tと約10倍に拡大しています。このような進化に伴い、開発および運用におけるスケーラビリティやコスト効率、性能がこれまで以上に重要視されています。
本セッションでは、AWS独自のAIチップとRayフレームワークを利用して、この課題をいかに解決したかを、事例とともに具体的に掘り下げます。
解決すべきLLMOpsの課題

LLMの開発・運用(LLMOps)において、以下の4つの課題が一般的に直面する問題として挙げられます。
- スケーリングの困難さ:モデルサイズの増加に伴い、スケーリングの効率化が難しい
- 計算ノードの停止への対応不足:ノードが停止すると運用が容易に中断される
- リソースとコンテナの非効率的なスケジューリング:最適化されていないリソース利用がコスト増加を招く
- 観測性の欠如:異なる抽象レイヤー間でのトラブルシューティングが困難
AWSはこれらの課題に対して、LLMOps全体を効率化する独自のツール群を提供しています。
AWSが提供する解決策
1.AWS AIチップ(Trainium & Inferentia)

AWSのAIチップは、コスト効率が高く、ハイパフォーマンスを発揮します。Trainiumは特にLLMのトレーニングに特化し、Inferentiaは推論ワークロードで高い効率性を提供します。
- Inferentia: 推論コストを最大70%削減
- Trainium: トレーニングコストを最大50%削減
2.Ray + KubeRay

分散トレーニングや推論をシンプルにするためのフレームワーク。以下の特徴があります。
- 柔軟なスケーリング戦略
- Kubernetesとの統合
- 分散スケジューリングと動的スケーリング
3.Neuron SDK

Neuron SDKは、AWS AIチップのパフォーマンスを最大化するためのツールであり、PyTorchやTensorFlowといった主流のMLフレームワークとシームレスに統合できます。これにより、トレーニングと推論プロセスを簡素化しつつ、効率的に進めることが可能です。
具体的なアーキテクチャ例
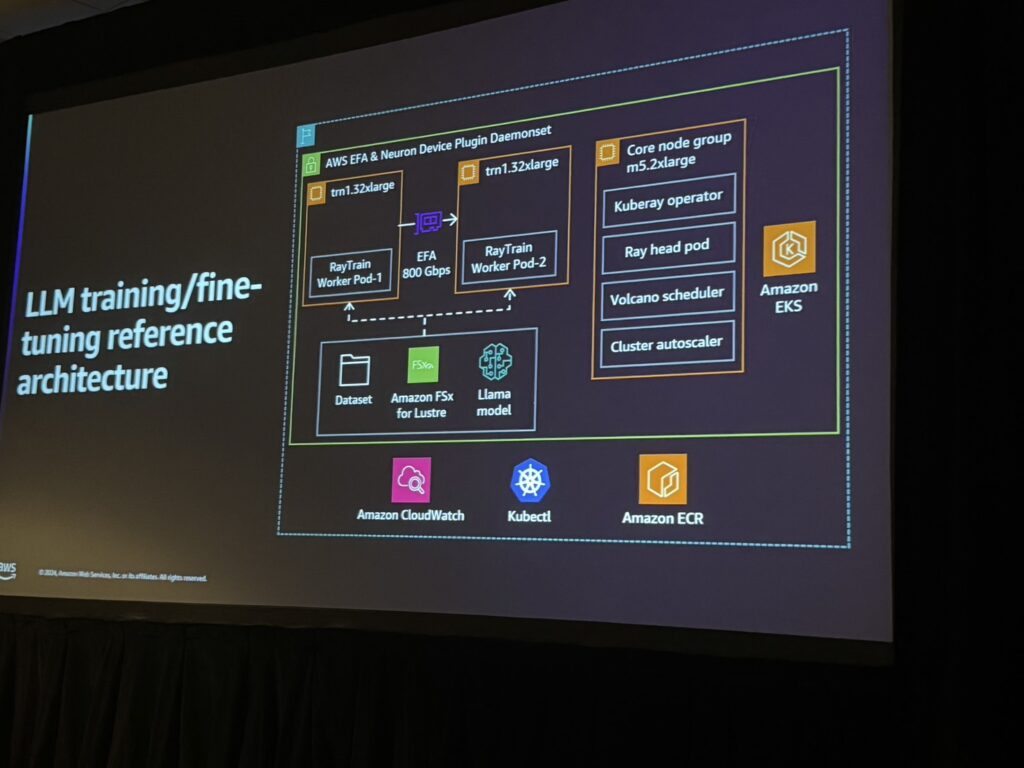
Ray Trainを中心に構築されたトレーニング・ファインチューニングアーキテクチャは、Amazon FSx for Lustreのデータセットストレージと連携し、高速かつスケーラブルなトレーニング環境を実現しています。
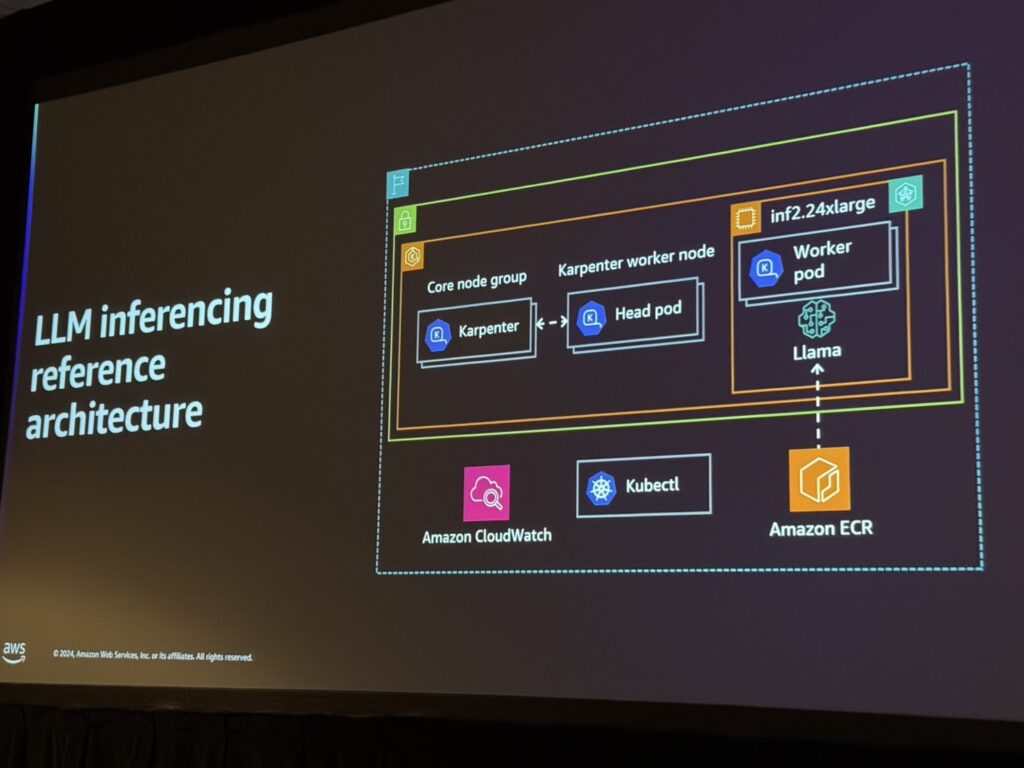
Inferentia2チップを活用した推論アーキテクチャは、Karpenterによる効率的なリソースプロビジョニングと連携し、高スループットの推論を可能にしています。
成果
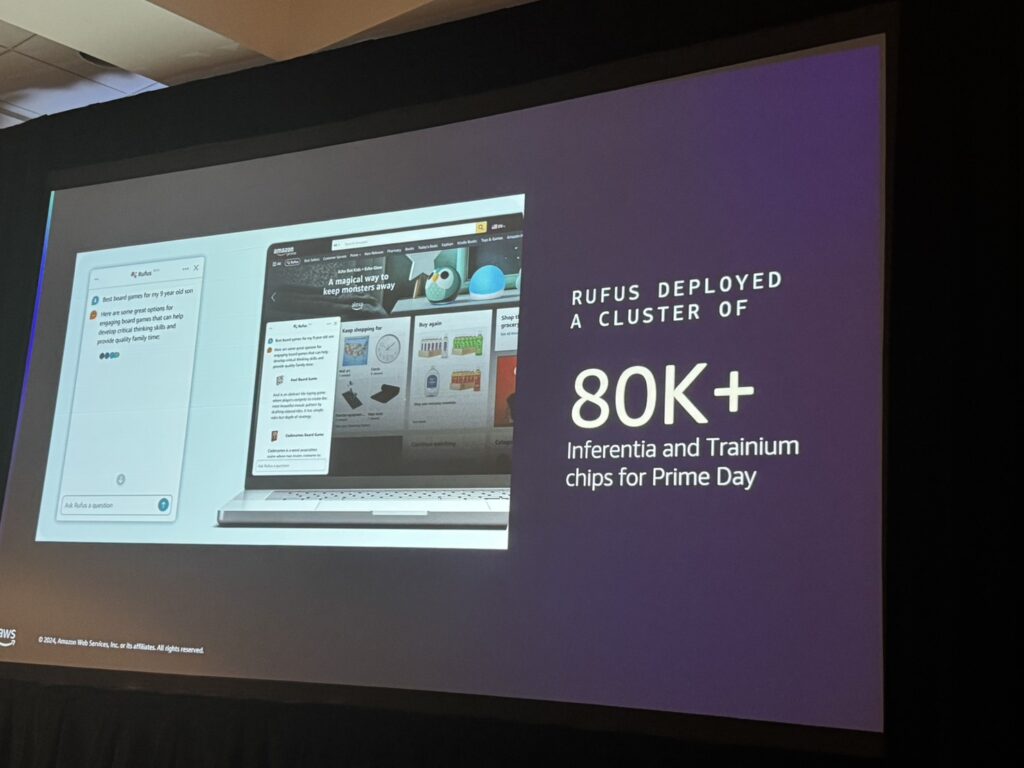
AWSのTrainiumとInferentiaを用いることで、AmazonはPrime Dayにおいて80,000以上のAIチップを活用し、大規模な需要に対応しました。これにより、運用コストを削減しつつ、高い信頼性を実現しました。
セッションを終えて

AWSが提供するLLMOpsツールは、LLMのトレーニングと推論において、コスト削減と効率向上を実現します。特に、TrainiumやInferentiaといったAI専用チップやRayフレームワークの活用は、企業の競争力を大幅に強化する重要な要素となります。また、Neuron SDKを試すための情報も提供されており、これらのツールを実際の運用に取り入れるハードルを大幅に下げています。
このセッションを通じて、AWSのAIスタックがLLM開発を効率化するための強力な基盤を提供していることが明確に示されました。特に、AIチップとNeuron SDK、Rayの組み合わせは、性能とコストの両面で大きな利点をもたらします。
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び