MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #ANT405|AWSアナリティクスを活用したMLとAIのためのデータエンジニアリング
Data engineering for ML and AI with AWS analytics
セッション概要
- タイトル:Data engineering for ML and AI with AWS analytics
- 日付:2024年12月4日(水)
- Venue:Mandalay Bay | Level 2 South | Oceanside B
- スピーカー:
- Tim Kraska(Director of Applied Science / Professor, AWS)
- Uday Narayanan(Principal Solutions Architect, Amazon Web Services)
- Moe Haidar(Office of CTO, Nexthink)
- 業界:Cross-Industry Solutions
- 概要:AI と ML システムの性能と精度は、モデル学習やRAG(Retrieval Augmented Generation)に使用されるデータの品質、関連性、整合性に大きく影響されます。データエンジニアリングは、AIとMLの実装を成功させるために、高品質のデータを使用、アクセス、活用できるようにするために重要な役割を果たします。 これにより、AIモデルが効果的に学習、判断、行動できるようになります。 このセッションでは、AWSでどのようにデータを収集、保存、処理、統合し、これをAIチャットアシスタントやその他のAI/MLアプリケーションで使用できるようにするかについて説明します。
はじめに
今回のセッションでは、AI/MLアプリケーション向けのデータ戦略構築方法の紹介や、AWSでどのようにデータを収集、保存、処理、統合し、これをGen AIチャットアシスタントやその他のAI/MLアプリケーションで使用できるようにするかについての紹介したいです。また、これを適用したNextThinkのGen AIベースチケットシステムの構築事例を紹介します。
データエンジニアリングの重要性とデータパイプラインを構築するためのAWSサービス
AI/MLアプリケーションを構築する際のデータ戦略は非常に重要です。データ戦略を確立して、すべてのデータをアプリケーションの学習に使用できるようにする必要があります。さまざまな構造的、非構造的なデータをバッチ収集とストリーミング収集を介してデータレイクにデータを移動します。収集されたデータは、ETLツールを介してアプリケーションで使用可能な構造に変換されます。

AIモデル用のトレーニング/テストデータセットが準備されると、それに基づいてモデル学習が行われます。
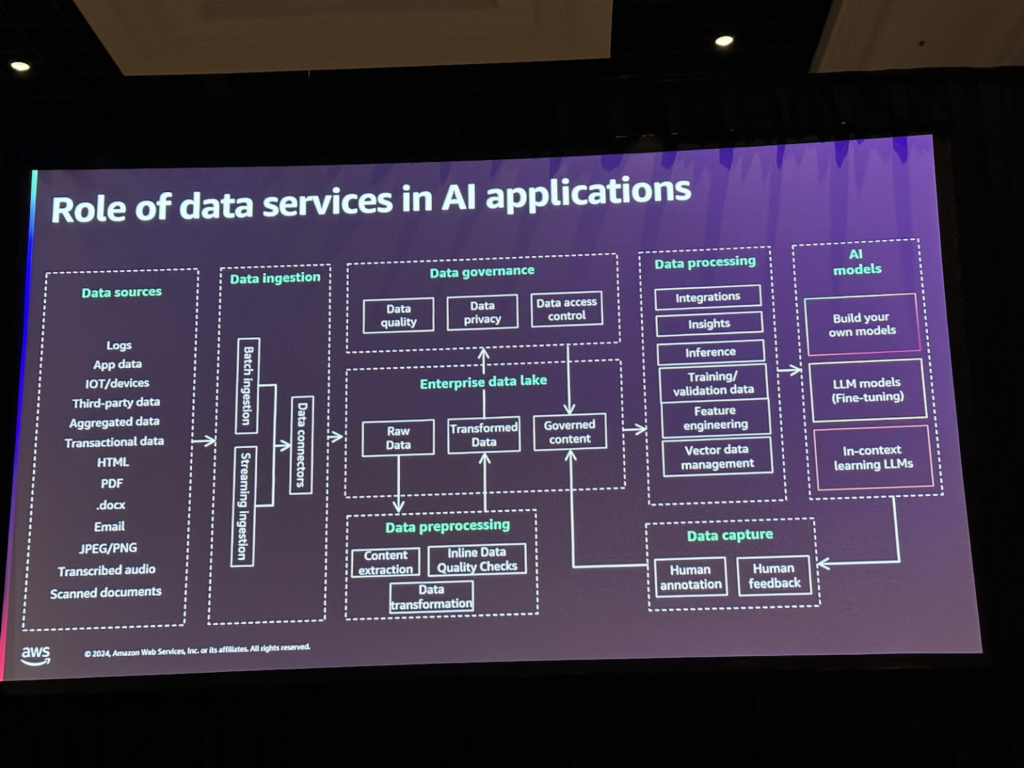
アーキテクチャは大きくデータソースからデータをインジェストし、データ前処理を経てデータガバナンスとデータレイクを構成し、それに基づいてAIモデルを学習し、そのモデルを通じて得たデータを再びデータレイクに適用してフィードバックループを構成する過程を表現しています。
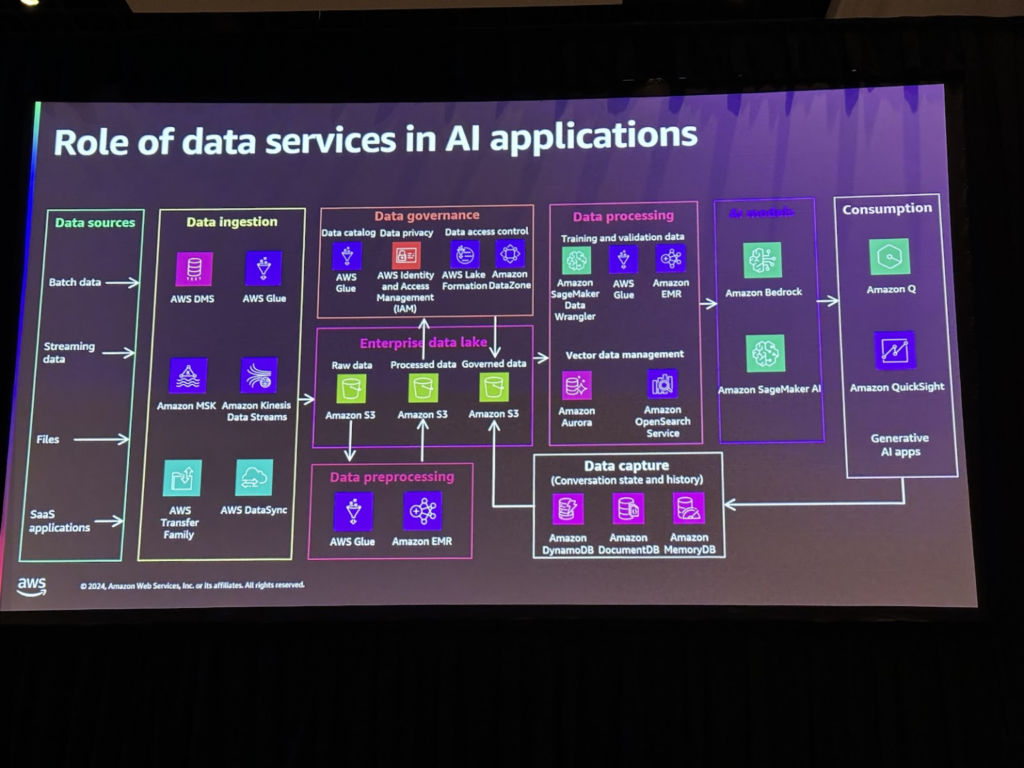
AWS Glueを使用すると、70を超えるデータソースをデータレイクに統合でき、データ処理パイプラインを使用してデータ検証、品質チェックなどが可能です。 Amazon Kinesis Data Stream は、1 秒あたりのギガバイトのデータをストリーミングできるサーバーレスソリューションです。
最後に、ユーザーフィードバックループを使用して、アプリケーションを使用しながら収集されたデータをモデルの改善に活用できます。
生成型AIアプリケーション構築のためのフロー
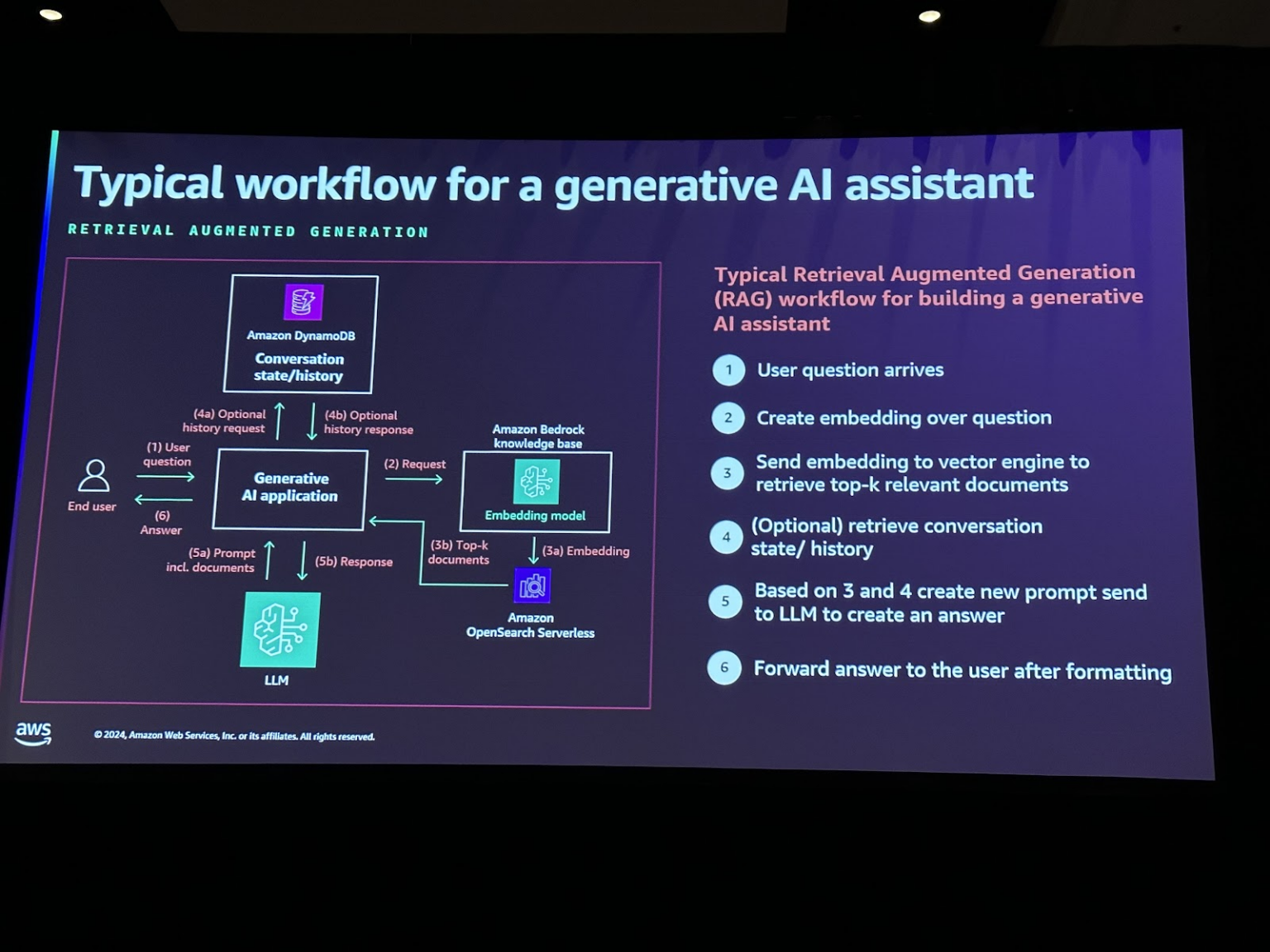
一般的なGen AIアシスタントフローは、次の画像のようになります。ユーザーが質問を入力すると、それをGen AIアプリケーションに送信し、このリクエストはAmazon Bedrockでホストされている埋め込みモデルにルーティングされます。埋め込まれた要求は、ベクトルストアに保存されている関連文書とデータを取得するために使用されます。このように検索されたデータは後続のプロンプトに含まれ、最終的な回答が生成されます。
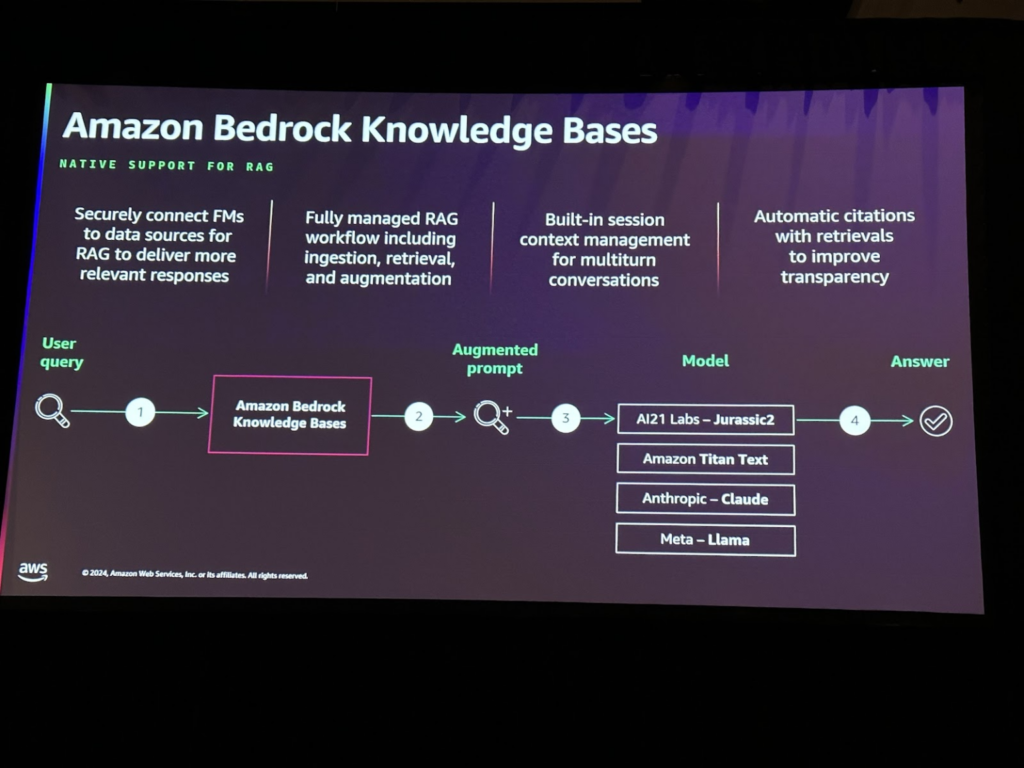
ベクターストアの保存されたドキュメントとデータは、Amazon Bedrock Knowledge Basesを使用してベクトル化されて保存されます。
NextThinkのGen AIアプリケーションケース:Autopilot
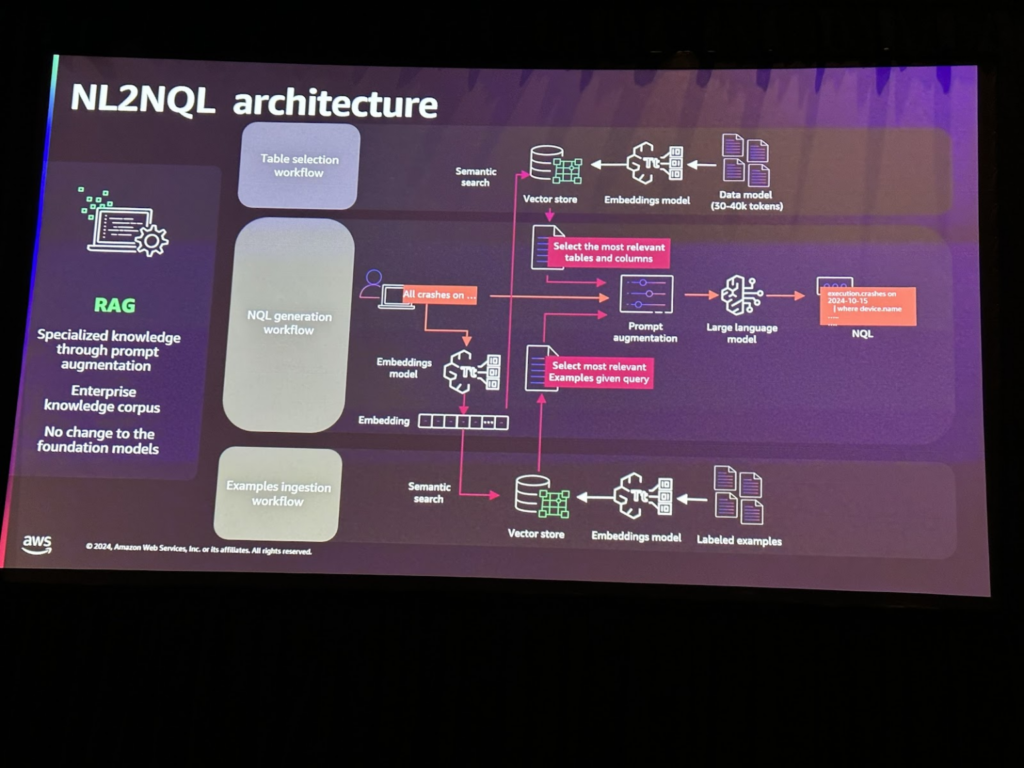
NextThinkは、従業員の技術経験を向上させるために、データプラットフォームを活用してAutopilotというGen AI製品を開発しました。 Autopilotは、サービスデスクオペレータとエンドユーザー間の対話をサポートするソリューションです。このサービスはIT問題を解決するプロセスを簡素化し、ユーザーがサービスデスクに要求を送信したときにシステムが自動的に問題の原因と解決策を提供します。このプロセスでは、整形データを照会するためにNL2SQLを介して照会を生成します。

NL2SQLは、自然言語要求をSQLクエリに変換することで、整形データであるデータベース内の情報を抽出するために使用する技術です。
システムは、自然言語要求をSQLクエリに変換するために自然言語処理(NLP)技術を利用しています。
NL2SQLのアーキテクチャは次のとおりです。ユーザーの入力が埋め込みモデルを介してベクトル化されると、セマンティックサーチを介して既に構成されているベクトルストアから最も関連性のあるクエリーが呼び出されます。一緒にLLMを活用して最終的にクエリを出力します。
まとめ
今回のセッションを通じて、データエンジニアリングは高品質で、関連性が高く、完全なデータ確保を通じてAIモデルの効率的な実装を可能にし、これがビジネス運営に大きな影響を及ぼす要因であることをもう一度確認することができました。 AIモデルが効果的に学習、推論、行動をするためには、どのようにデータを収集、保存、処理するかを知ることができ、その過程の重要性も確認しました。 RAGとGen AI技術が進歩する中で、このようなデータ管理と処理方法は、さまざまな場所で現在よりもさらに多様な方法で適用できるようです。
記事 │MEGAZONECLOUD AI&Data Analytics Center(ADC) Data Application Support Team オム・ユジンマネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び