MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #ANT406-R|Amazon OpenSearch Serviceで生成型AIベースの検索を構築
Generative AI-powered search with Amazon OpenSearch Service
セッション概要
- タイトル:Generative AI-powered search with Amazon OpenSearch Service
- 日付:2024年12月3日(火)
- Venue:Wynn | Convention Promenade | Lafite 2
- スピーカー:
- Arun Lakshmanan(Sr. WW SSA OpenSearch, AWS)
- Jianwei Li(Principal Specialist TAM, AWS)
- 概要:Amazon OpenSearch Serviceを活用して、生成型AIベースの検索およびチャットボットアプリケーションを作成するプロセスをご紹介します。 このセッションでは、コードの作成とデプロイメントから、OpenSearch Serviceの基本的な実装、データのインデックス作成、ベクター検索クエリの実行、完全な機能を備えた生成型AI検索アプリケーションの構築まで、ステップバイステップで解説します。このセッションに参加して、OpenSearch Serviceを使用したAIベースのプロジェクトに取り組むために必要な実践的な経験と知識を得ることができます。
はじめに
このセッションはAWS BedrockとOpenSearchを中心に行われました。検索技術の理論的な概念に基づいて、Generative AI時代にどのように進化したかを説明し、セッションの後半では、OpenSearchとBedrockを連携させたコード例を見て、大規模なデータを効果的に検索して管理する方法を深く探求しました。
Agendaは、Search Methodの理論を整理した後、Coding(Code Talk)を通じて実際にコードの簡単な説明をする時間を持ってQnAを受け取る順序で進行されました。
コードベースのRAG Pipelineを使用していますが、GenAI Powered Search方式という用語も不慣れで、Agentを使用したRAGも慣れていないため、セッションで学ぶことができるという期待とともに参加しました。
検索方法
セッションでは、検索技術の発展過程についてまず説明してくれました。
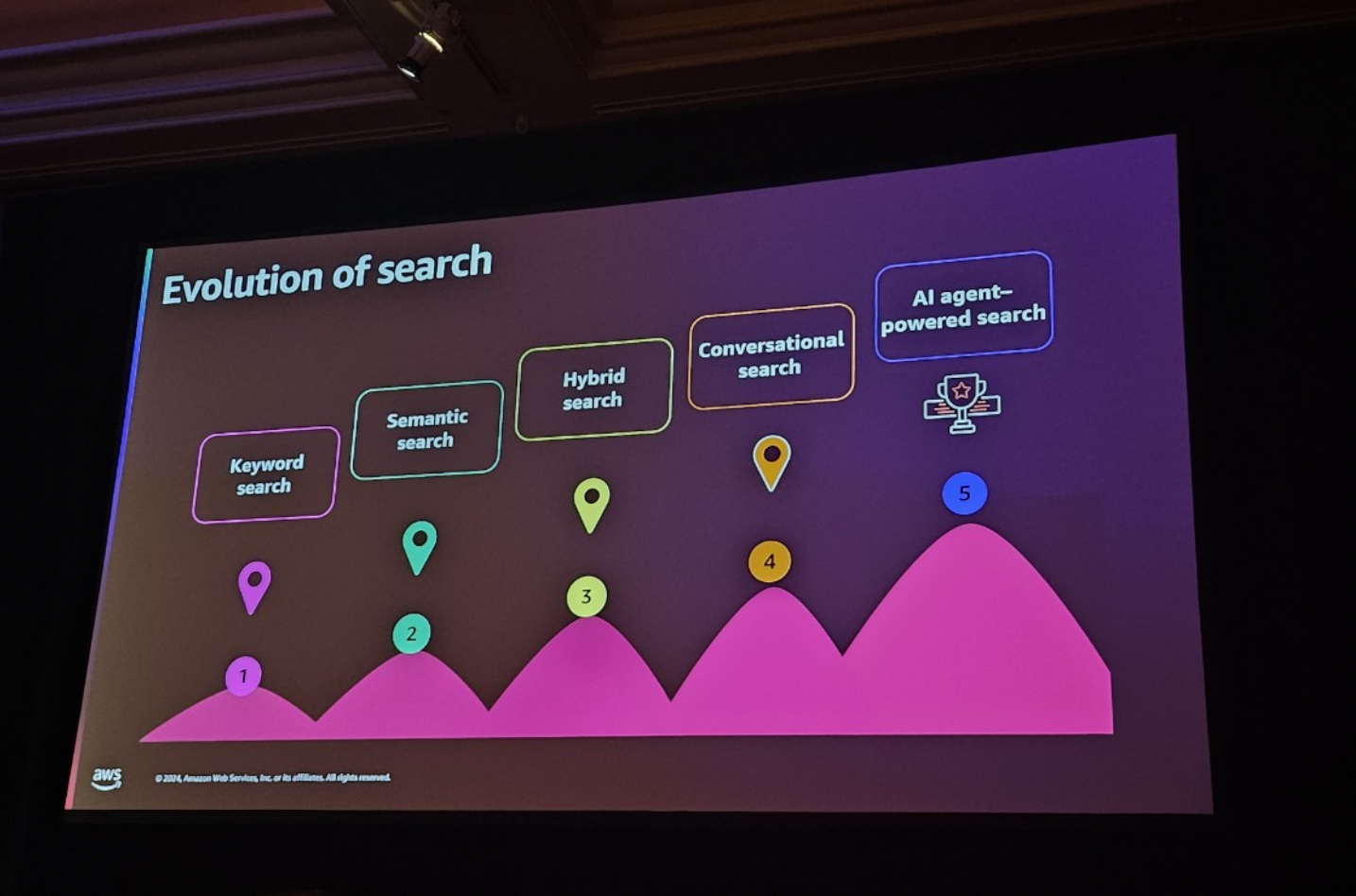
- キーワード検索
- テキストをTokenに分割してインデックスに保存する方法です。
- 検索クエリと比較して、頻度とドキュメント内の重要度に基づいて結果を並べ替えます。
- Synonyms(同義語)の活用と古典的なテキスト検索アルゴリズムに依存します。
- Semantic Search
- テキストの意味に基づいています。
- 埋め込みモデルを使用して文書をベクトル化して類似度を取得します。
- Vector Search
- 埋め込みモデルを使用して文書をベクトル化して、データ間のベクトル距離を計算します。
- Hybrid Search
- キーワード検索とベクトル検索を組み合わせて、関連性の高い結果を生成します。
- AI agent-powered Search
- 対話型検索方式です。
- 前のコンテキストを覚えて、その後の質問により良い答えを提供します。
GenAI Powered Search Pipeline
前のSearch Methodに簡単に作成したように、対話型検索を意味するSearchでした。その検索方式のパイプラインは次のとおりです。

パイプラインについて説明すると、以下の手順で進みます。
- ユーザークエリ (User Query)
- ユーザーは自然言語で質問または要求を入力します。
例:「先月私たちの会社で最も売れている製品は何ですか?」
- ユーザーは自然言語で質問または要求を入力します。
- 検索(Search)
- Knowledge Baseを活用して、ユーザーのクエリに適した文書を検索します。
- Knowledge Baseは、事前に索引付けされた構造的および非構造的なデータで構成されています
- OpenSearchなどの検索エンジンを使用してクエリを処理し、検索方法を選択します。
- その結果、最も関連性の高い文書を返します。
- 関連文書の抽出
- 検索エンジン(OpenSearch)によって返された文書に基づいて標準ランキングアルゴリズムを適用します。
- ユーザーの質問に最も関連性の高い文書を優先順位で並べ替え、
- 不要な文書をフィルタリングして最適化されたデータのみを残します。
例:「先月の販売データ」に関連するレポートとデータを返します。
- LLM によるコンテキストベースの処理 (Context Processing with LLM)
- 関連文書がLLMに入力され、追加処理になります。
- 文書の内容を分析し、質問の文脈に従って必要な情報を抽出し、応答形式に再構成します。
- BedrockなどのLLMを活用して、文書の要約、重要な情報の抽出、回答の生成を行います。
- 最終応答の生成 (Generate Final Answer)
- LLMが処理したデータに基づいて最終応答を生成し、結果を自然言語形式でユーザーに渡します。
例:「先月私たちの会社で最も売れている製品はAで、合計10,000個が販売されました」
- LLMが処理したデータに基づいて最終応答を生成し、結果を自然言語形式でユーザーに渡します。
Code Talk
コードの簡単な説明とともにフローを説明します。1. Ingest unstructured data into OpenSearchCloudformation Stackを介してデータの流入 →OS Clientを結び、データに基づいてIndexを生成
→Query: Does this work with xbox?
→ Keyword Search (すべて同じ場合のみ True)
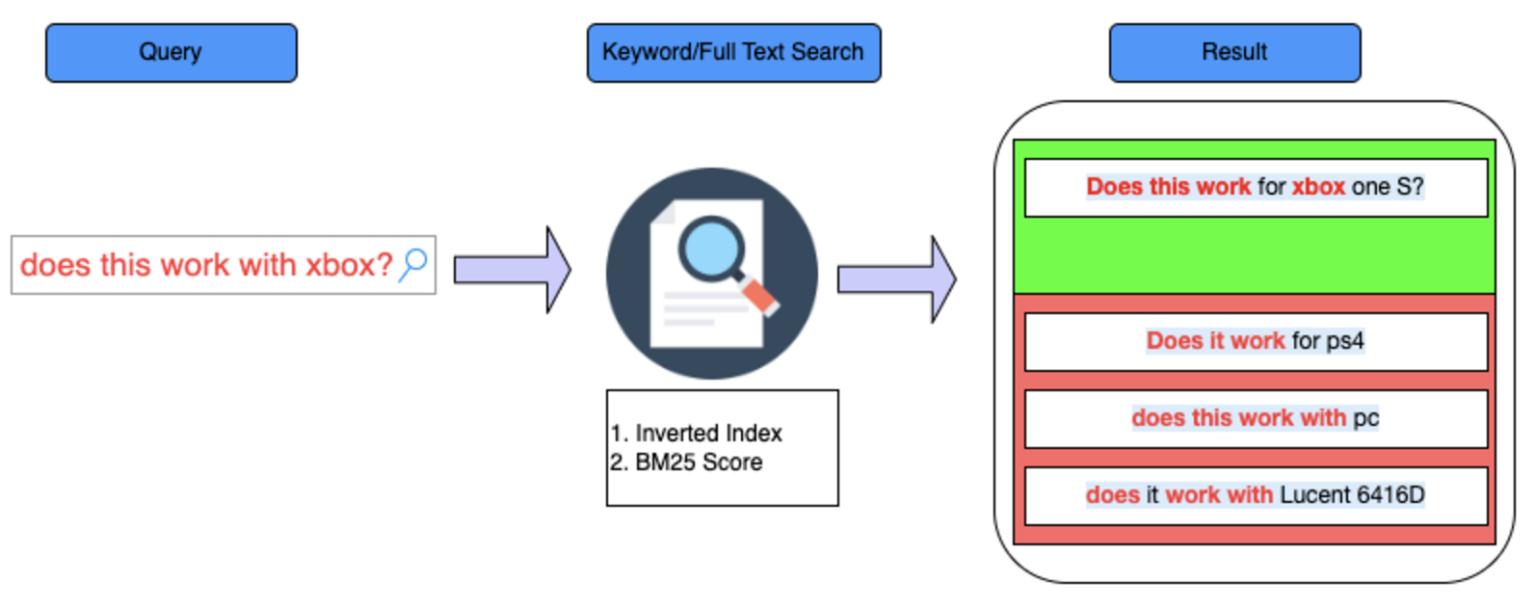
→Semantic Search(実際の単語が使われなくても意味が似ている場合はTrue)
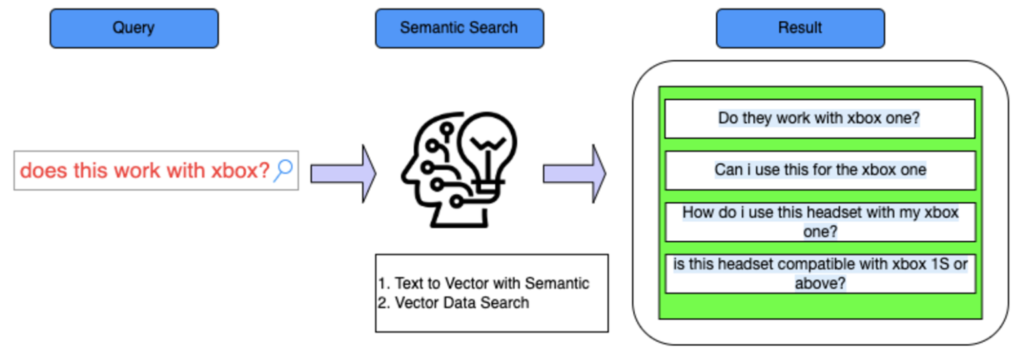
1回のコースでは、古典的な検索方法を確認できます。
2. Standard RAG
RAG Pipelineのアーキテクチャは以下の通りです。
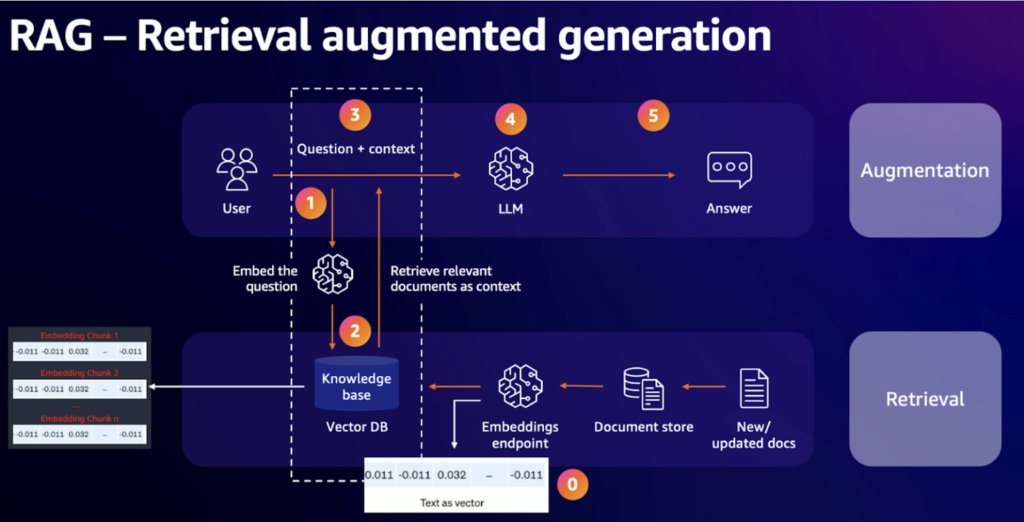
このプロセスで実行されたコードトークは次のとおりです。
OpenSearch 接続設定
→ 読み込まれたデータを Text Splitter にテキスト分割
→ OS にドキュメントインデックスを付けた後 OpenSearchVectorSearch オブジェクトを作成
→ Vector 検索のための Retriever 設定
→ RetrievalQA チェーンの生成とクエリ
→ ユーザークエリへの応答の生成
3. AI agent powered search
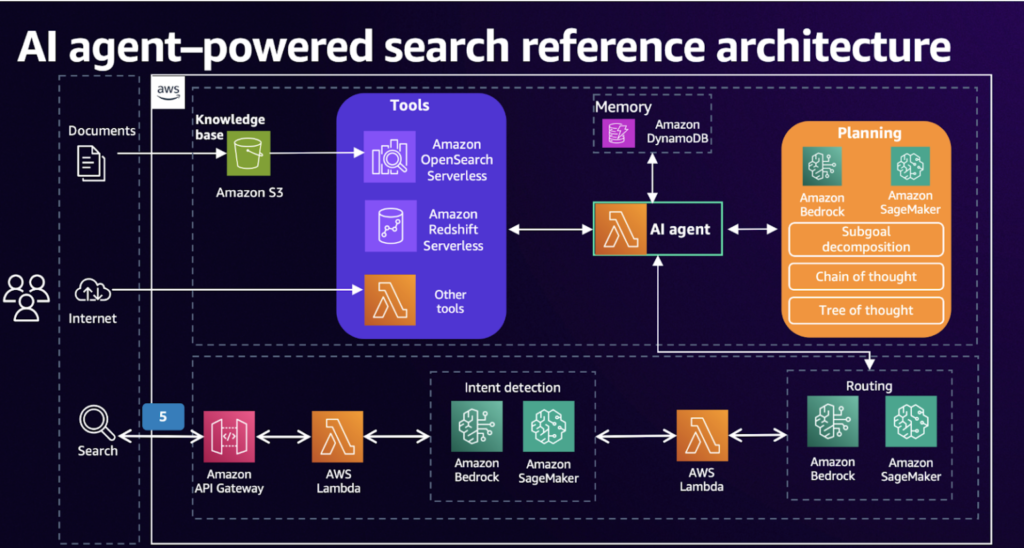
Standard RAGで検索する方法は、リアルタイム情報、外部情報が入ったときに限界があります。
したがって、AI Agent-Powered Searchはエージェントモデルを活用してこれらの制限を克服します。
ユーザークエリを受信
→Chain-of-Thought(事故プロセスで問題を分解し、必要に応じて外部リソースを検索する)
→外部ツールを使用する(検索エンジン、APIなど)
→結果を生成する
インタラクティブなチェーンは、「Chain-of-Thought」の関数でCacheをキャッチすることで、コンテキストの流れを理解できます。
その部分に重要な部分だけをまとめてみると以下のようになります。
- Create_new_memory_with_session (会話メモリの作成)
- ConversationBufferMemory (会話履歴+コンテキストを維持)
- Create_xml_agent (Agent 生成)
- AgentExecutor (Agent 実行)
まとめ
このセッションでは、AI Agent-Powered SearchとRAGモデルを活用した検索システムの構築について説明しました。まず、OpenSearchなどの検索ツールを使用した古典的な検索方法を見て、それからStandard RAGを使用して検索結果を生成し、ベクトル検索に基づいてより正確な答えを導き出す方法を学びました。最後に、AI Agent-Powered Searchを通じてリアルタイム情報と外部ツールを活用する方法で、知識ベース以外の情報をどのように活用できるかを見てきました。
AI Agent-Powered Searchでリアルタイム情報を検索して処理する方法は非常に印象的でした。この技術を活用すれば、単に情報を探すことを超えて、動的な応答を生成できることがわかりました。既存のプロジェクトでうまく使用できなかったエージェントの使い方を学ぶのに有益な時間でした。
記事 │MEGAZONECLOUD AI&Data Analytics Center(ADC) Data Architecture Team チョ・ミンギョンマネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び