MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #CMP207|AWSアクセラレーションコンピューティングが生成AIでカスタマーサクセスを導く方法
AWS-accelerated computing enables customer success with generative AI
セッション概要
- タイトル:AWS-accelerated computing enables customer success with generative AI
- 日付:2024年12月3日(火)
- Venue:Venetian | Level 3 | Murano 3304
- スピーカー:
- Dave Salvator(Director Accelerated ComDvij Bajpai, Senior Product Manager(Technical, Amazon Web Services)
- Samantha Pham(Principal Product Manager, AWS)
- Kirmani Ahmed(AI Engineering lead, Meta Platforms)
- 業界:Cross-Industry Solutions
- 概要:AWS が大規模で生成された AI モデルを構築および拡張するための、最も優れたパフォーマンスと低コストのインフラストラクチャをどのように提供するかをご覧ください。 GPU ベースのインスタンスや AWS AI チップベースのインスタンスを含む、高速化コンピューティング ポートフォリオの新機能について学び、このポートフォリオが顧客に提供するさまざまな学習と推論の活用例を紹介します。大規模な言語モデルやマルチモーダルモデルなど、さまざまな顧客のニーズをサポートします。このセッションに参加して、大手企業がAWSを活用して、生産的なAI分野で革新的な成果を上げた実践的なケースを見てください。
はじめに
このセッションでは、AWSがGPUや独自のAIチップベースのインスタンスを含む高速化コンピューティングポートフォリオを介して大規模で生成されたAIモデルを構築および拡張するために必要な優れたパフォーマンスとコスト効率を提供する方法を学びます。このセッションでは、LLMモデルとMultimodalモデルを含む、さまざまな顧客ニーズをサポートする学習と推論の使用例を紹介します。また、大手企業がAWSを活用して、生産的なAI分野で革新的な成果を上げた実例を紹介します。
部門で SA として働きながら、GenAI プロジェクトで EC2 を主に使用するという観点から、セッションを通じて AWS インフラストラクチャが AI および ML ワークロードにどのように最適化されているかを理解し、実際の適用事例で顧客に提案するソリューションを構想する上で大きな支援を与えるという期待を持ってきた
UseCase of GenAI
まず、GenAIがさまざまな産業でどのように使用されているかについての例を説明しました。これらのいくつかのケースを共有します。

- HealthCare&Life Sciences
– Proteinの設計と新薬の開発:機械学習モデルを使用してタンパク質の言語と生物学的構造を学習することで、新しい治療法を設計できました。
– EMR(電子医療記録):自然言語処理モデルにより、医療データをより簡単に文書化して処理することができ、医療スタッフの行政業務負担を減らすことができました。 - Industrial, Automotive & Manufacturing
– 製造ラインの最適化: Generative AIベースのロボットは、周囲の環境を検出しリアルタイムで反応し、製造プロセスをより安全かつ効率的にすることができます。
– 車両設計:Ferrariなどの企業は、3Dレンダリングを活用して、顧客が車両を生産する前に視覚的に体験できるようにします。 - Retail
– AI ショッピング ヘルパー: Amazon.com では、「RUFUS」という AI アシスタントを使用して、ユーザーがショッピング中に質問をしたり、製品の紹介を受けることができます。
Trends of GenAI
続いて、最近AI技術のトレンドの内容を伝えてくれました。特に、2023年と2024年を分ける主な変化を中心に説明し、AI技術が発展していく方向性を具体的に示しました。

- LLM拡張
– 大規模な学習クラスターが登場しながら、最大10,000以上のGPUを動員して1つのタスクを実行できます。これにより、次世代大規模モデルの開発が可能になります。
– 効率性と安定性は、大規模な学習環境の必須要件として浮上しました。 - グローバルなリアルタイムモデルの使用増加
– 世界中で、Generative AIモデルをアプリケーションに統合するための需要が急増しました。
– AWSは、コンピューティングのスケーラビリティと経済性を強化し、リアルタイムで強力なAIモデルと対話できる環境を提供します。 - マルチモーダルモデルの発展
– 2023年がテキストベースのLLMの年である場合、2024年はMultimodal Modelの年と見なされます。
– マルチモーダルモデルはテキストだけでなくビデオ、オーディオも理解し、この技術は新しいコンピューティングインフラストラクチャの要件を伴います。
Key Customer Needs
Generative AIの多様な活用事例と技術的なトレンドを紹介した後、お客様が共通して求める4つの主要事項について説明しました。これは、AWSがGenerative AIインフラストラクチャを設計および最適化するための最も重要な基準点として機能していました。

- Performance
AIモデルをLow Latencyでより速くトレーニングし検証し、製品化までの時間を短縮したいと思います。 - Cost
LLMは学習と推論のコストが高いため、コストパフォーマンスに優れたソリューションが必要です。 AWS は、最新の EC2 インスタンスを使用して、顧客が同じコストでより多くのパフォーマンスを得ることをサポートしています。 - セキュリティ(Security)
データとAIモデルには機密情報が含まれているため、高レベルのセキュリティが必要です。 - 使いやすさ
大規模なAIワークロードを管理するのは技術的に複雑ですが、顧客はこれを最小限に抑える簡単なソリューションが必要です。 AWSは、EC2などのサービスを通じて、これらの「非差別的な高強度作業」を削減することに集中しています。
About AWS EC2
AWS EC2 は、Generative AI モデルのトレーニングとデプロイに必要な高性能コンピューティング環境を提供します。 EC2インスタンスに関連するいくつかの技術的サポートは、顧客がAIモデルを効率的かつ迅速に訓練し、リアルタイムの推論を行うのに役立つ重要な要素です。
Accelerated Computing Architectureは、3つの主なカテゴリに分けられます。Accelerators、Switching Layer、Host。このアーキテクチャは、ハードウェアアクセラレータから始まり、データ転送を最適化するスイッチング層を経て、最終的にコンピュータのCPUがホスト環境を管理する構造です。
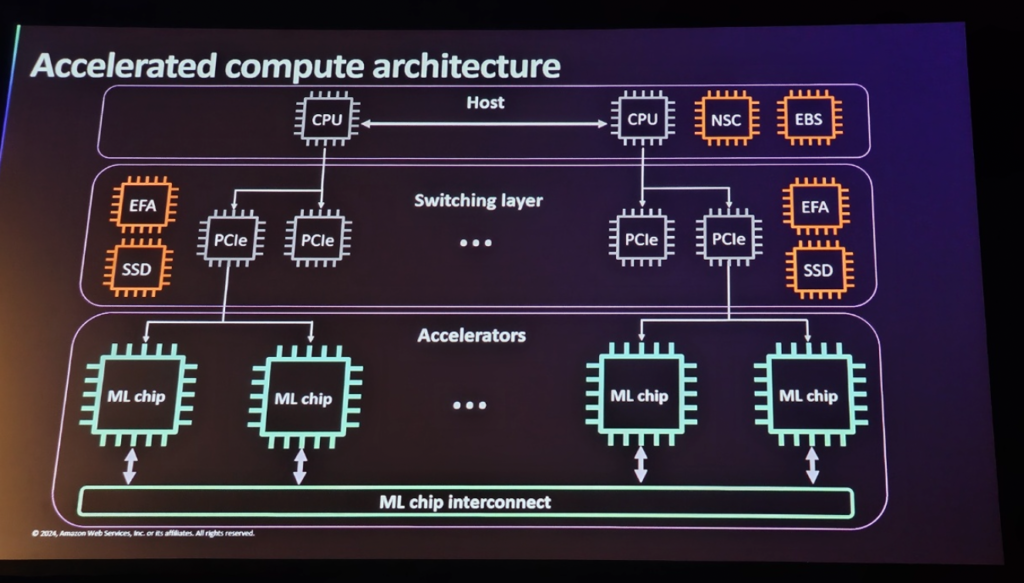
1. Accelerators
AcceleratorsはAIモデルのトレーニングと推論を加速するためのコアハードウェアです。さまざまなワークロードをサポートする複数のアクセラレータが用意されています。
[ NVIDIA GPUs ]
AWSはNVIDIA A100、V100などの高性能GPUを提供しています。これらのGPUは大規模な並列演算を可能にし、AIモデルのトレーニングに非常に適しています。特に大規模モデルの訓練に優れた性能を発揮します。
[ AWS Custom AI Chips (Trainium) ]

AWSが設計したTrainiumチップは、AIトレーニングを最適化してパフォーマンスを最大化します。大規模なモデルトレーニングに適しており、パフォーマンスとコストの面で優れた効率を提供します。
2. Switching Layer
Switching Layerは、さまざまなアクセラレータが協力して大規模なモデルトレーニングと推論を効率的に処理できるようにするネットワーク層です。このレイヤは、GPUなどのアクセラレータ間でデータを迅速かつ確実に転送する役割を果たします。
[ EFAv3 (Elastic Fabric Adapter) ]
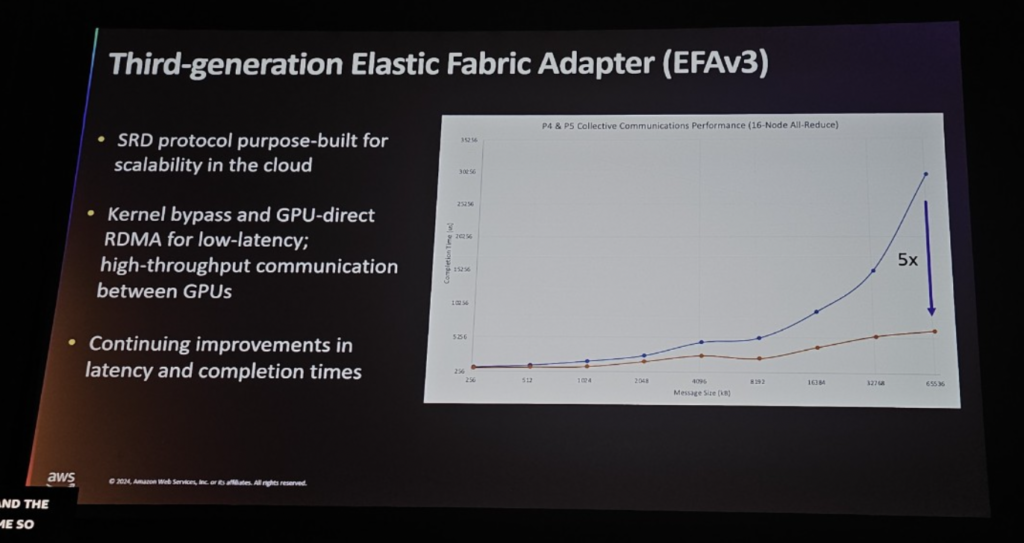
EFAはAWSの高性能ネットワークインターフェースで、大規模なAIトレーニング環境で複数のGPU間の同期とデータ処理を迅速かつ効率的にサポートします。 EFAは高い帯域幅と低い遅延時間を提供し、複数のGPUが同時に作業できるようにします。
EFAv3はEFAの進化したバージョンで、クラウド環境でのスケーラビリティのために特別に設計されたScalable Reliable Datagram(SRD)プロトコルを内蔵しています。 SRDはネットワークトラフィックのスケーラビリティをサポートし、大規模なクラスタ環境でも安定したパフォーマンスを提供します。これは、モデルトレーニングのための分散作業をより効率的に処理するのに役立ちます。
[ EC2 Ultra Cluster ]
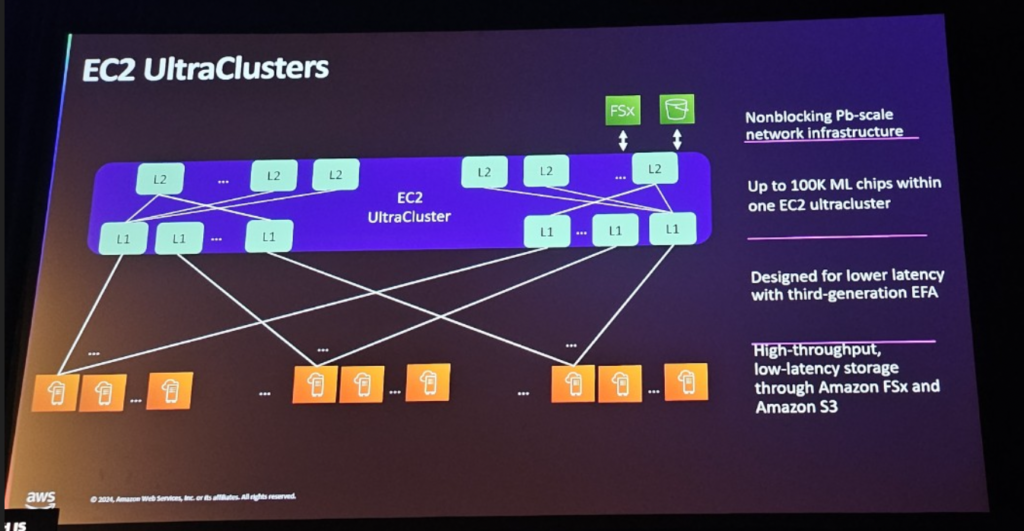
EC2 Ultra Clusterは、何百ものインスタンスと数千のGPUを接続できる、AWSの高性能ネットワークインフラストラクチャです。このクラスタはEFAv3などの高速ネットワーク技術を活用して、データ転送速度と処理性能を最適化します。これにより、大規模なAIモデルのトレーニングに必要な帯域幅を拡張し、データ処理の遅延時間を最小限に抑えることができます。 EC2 Ultra Clusterは、特に数千のGPUを使用した大規模なトレーニング作業に不可欠なパフォーマンスを提供します。
3. Host
HostはEC2インスタンスを実行する物理サーバーであり、CPUとメモリリソースなどを管理します。
[ Storage Service ]
ストレージサービスを使用すると、モデルトレーニング中に生成される「ML Model Weights」は重要な資産であるため、データがトレーニング中に破損しないように保護できます。
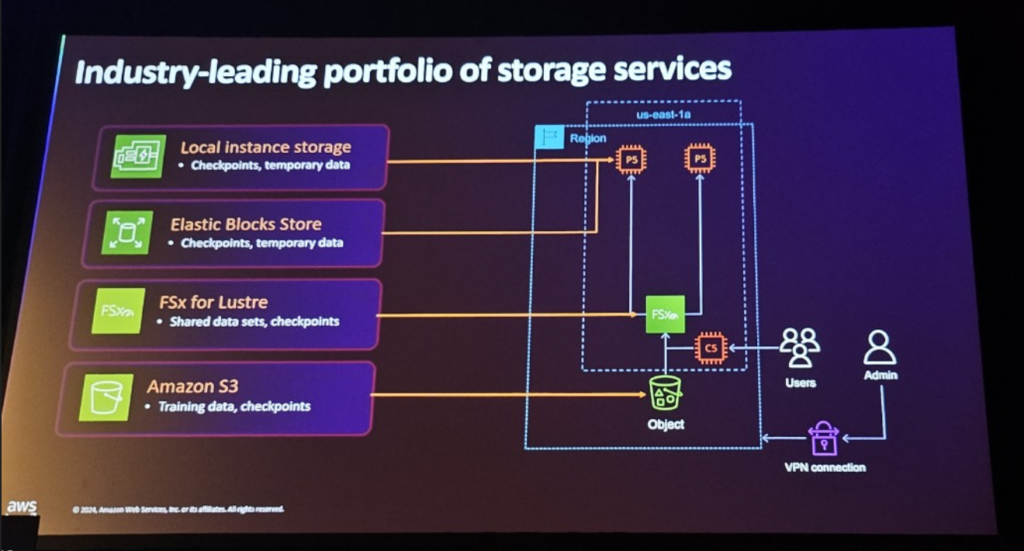
S3:オブジェクトストレージを使用すると、大規模なデータセットを安全に保存できます。
EBS:EC2インスタンスと組み合わせてブロックストレージサービスを提供し、AIモデルのトレーニング中にチェックポイントデータまたは一時データをすばやく確実に保存できます。あるパフォーマンスを提供します。
FSx:FSxは高性能ファイルシステムで、AWS EC2インスタンスで実行されているアプリケーションと効率的にデータを共有できます。 AIトレーニング中のデータボトルネックを最小限に抑え、大規模ファイルシステムを処理するのに理想的なオプションです。
[ AWS Nitro System ]
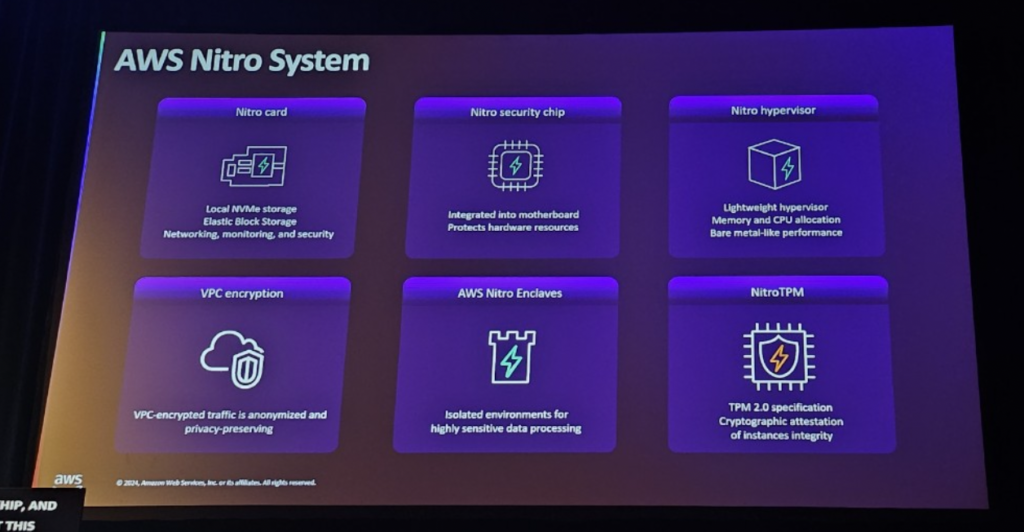
AWS Nitro Systemは、AWS EC2インスタンスのセキュリティを担当する技術で、ハードウェアとソフトウェアを組み合わせてお客様のデータを安全に保護します。すべてのEC2インスタンスでデータを保護し、セキュリティが重要なモデルトレーニング環境を提供する上で重要な役割を果たします。
Series of EC2 Instances
先に見たアーキテクチャに基づいて、AWSはさまざまなEC2インスタンスシリーズを提供し、顧客は自分のニーズに合った最適なインスタンスを選択して、General AIモデルをトレーニングして推論できます。各インスタンスシリーズは特定のワークロードに最適化されており、顧客のさまざまなニーズを満たすためのパフォーマンスと効率性を提供します。以下では、AWSの主要なEC2インスタンスシリーズについて説明します。

1. G-Series Instance (NVIDIA GPUs)
GPUベースのコンピューティングおよびグラフィック操作に最適化されたインスタンス。 NVIDIA GPUを使用してAIトレーニングと高性能コンピューティングワークロードを処理するのに適しており、さまざまなインスタンスサイズを提供して柔軟性を提供します。

- Compute and graphics optimized GPUs : コンピューティングやグラフィック処理作業に最適化されており、ゲーム開発、シミュレーション、AIトレーニングなど様々な用途に活用されます。
- Flexibility with multiple instance sizes: 複数のサイズのインスタンスを提供することで、顧客は自分のワークロードに最適なリソースを選択できます。
- Great for single GPU or single node workloads : 単一 GPU または単一ノード操作に最適化されており、高性能 GPU を一度に処理できる作業に非常に有利です。
Gシリーズインスタンスは、NLP、コンピュータビジョン、強化学習、グラフィック、シミュレーションなどに適しています。
2. P-series Instance – ( Newly Announced in re:Invent 2024 – P5en Instance )
AIトレーニングと推論に最適化されたインスタンスシリーズです。 P4dのようなインスタンスはNVIDIA A100 GPUに基づいており、大規模なAIモデルのトレーニングと推論を加速します。特に、EC2 Ultra Cluster内に配置され、分散トレーニングとスケーラブルな環境で優れたパフォーマンスを発揮します。
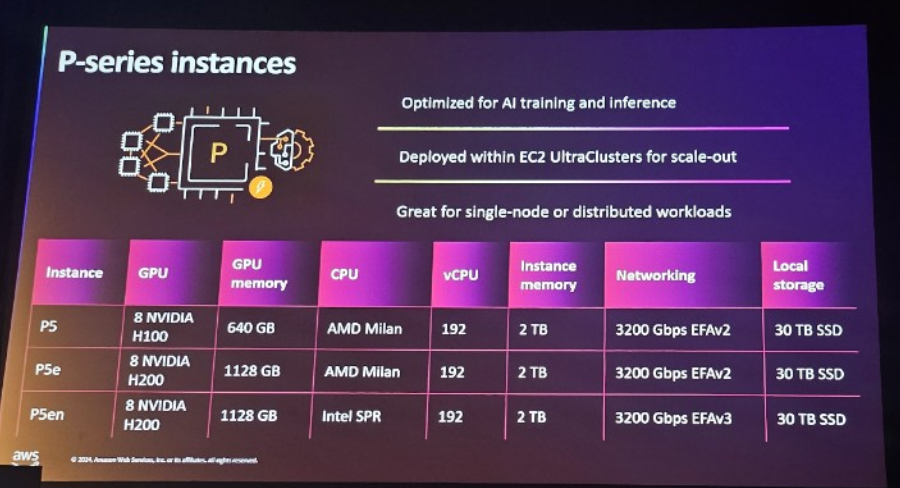
Optimized for AI training and inference : ディープラーニングトレーニングと推論に最適化されており、NLP(自然言語処理)、コンピュータビジョン、強化学習など、さまざまなAIモデルトレーニングを迅速かつ効率的に処理できます。- Deployed within EC2 UltraCluster for scale-out: EC2 Ultra Cluster内に配置され、数千のGPUを接続して大規模なAIトレーニングと推論をサポートします。
- Great for single node or distributed workloads: 単一ノードと分散ワークロードの両方に適しており、大規模モデルのトレーニングやリアルタイム推論の実行時に高いパフォーマンスを提供します。
Pシリーズインスタンスは、大規模なAI/MLトレーニング(NLP、コンピュータビジョン)やリアルタイム推論などに適しています。
3. Inf -series Instance (推論性能を最大化)
AWS Inferentia チップに基づいた AI 推論最適化インスタンスシリーズです。このシリーズは、ジェネラティブAI(GenAI)モデルの推論性能を最大化し、コスト効率とパフォーマンスを同時に提供します。 Inferentiaチップは、特に大規模なAI推論作業で高いパフォーマンスを提供し、NeuronLinkテクノロジをサポートして、超大型GenAIモデルも効率的に処理できます。

- Powered by AWS Inferentia custom ML chips: Inf シリーズは、AWS Inferentia チップを使用して AI 推論性能を最大化します。 Inferentiaは機械学習モデルの推論に最適化されたハードウェアで、低コストで高性能の推論を提供し、TensorFlow、PyTorchなどの主要なディープラーニングフレームワークと互換性があります。
- High Performance at the lowest cost for GenAI models:GenAIモデルに最適化された高性能を提供しながら、費用対効果の高い推論環境をサポートします。このシリーズは、特に大規模なAIモデル推論を経済的に処理できます。
- Support for ultra-large GenAI models using NeuronLink : NeuronLink テクノロジーにより、超大型 GenAI モデルを分散処理できます。これにより、非常に大きなモデルも効率的に推論して処理できます。
- 9.8TB/s aggregated accelerator memory bandwidth : 9.8TB/sの集積加速器メモリ帯域幅を提供することで、大規模モデル推論を迅速かつ確実に処理できます。この優れたメモリ帯域幅は、AIモデルを訓練し推論する際にボトルネックを最小限に抑える上で重要な役割を果たします。
Infシリーズは大規模なAIモデル推論を経済的かつ効率的に処理することができ、大型GenAIモデルを活用するサービスに適しています。
4. Trn -series Instance (推論性能を最大化)
AWS Trainiumチップを搭載したAmazon Elastic Compute Cloud(Amazon EC2)Trnインスタンスは、大規模言語モデル(LLM)や潜在拡散モデルなど、生成型AIモデルの高性能ディープラーニングトレーニングをサポートする目的別サービスです。 Trnインスタンスは、他の同様のAmazon EC2インスタンスと比較して低コストのトレーニングコストを提供します。
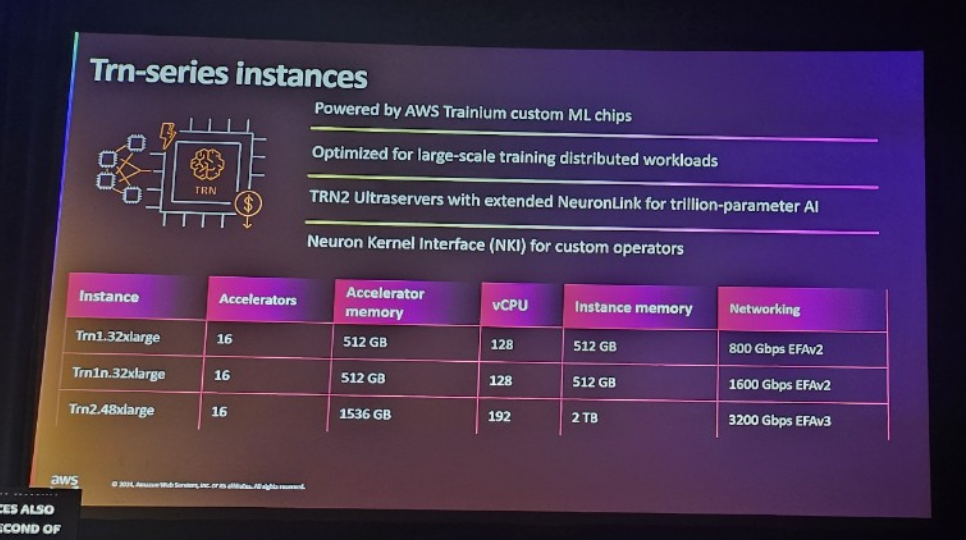
- Powered by AWS Trainium custom ML chips: AWS Trainium チップを使用して、大規模な AI トレーニングに最適なパフォーマンスを提供します。 TrainiumチップはAIトレーニングに必要な高性能コンピューティングを提供し、費用対効果の高いAIトレーニングを可能にします。
- Optimized for large-scale distributed workloads: 大規模な分散トレーニングに最適化されています。 AIトレーニングの際に、データとモデルを複数のノードで分散して処理できる環境を提供し、これによりトレーニング速度とスケーラビリティを最大化します。
- TRN2 Ultra Servers with extended NeuronLink for trillion-parameter AI: TRN2 Ultraservers は NeuronLink 拡張を使用して trillion パラメータ AI モデルを訓練するパフォーマンスを提供します。このシステムは大規模なモデルトレーニングをサポートし、NeuronLinkを使用して数百のノードを接続して効率的な分散トレーニングを実行します。( Newly Announced in re:Invent 2024 )
- Neuron Kernel Interface for custom operators: Neuron Kernel Interfaceはカスタムオペレータをサポートし、カスタムAIモデルのトレーニングに柔軟性を提供します。これにより、TensorFlow、PyTorchなどのフレームワークでカスタム演算子を簡単に実装できます。
Trnシリーズは、超大型AIモデルトレーニング、分散トレーニング、カスタムトレーニング作業が必要な作業に適しています。
まとめ
今回のセッションでは、NVIDIAとAWSの協力を通じて、生成型AIと高性能コンピューティング技術がどのように企業の問題を解決し、ビジネス成果を創出できるかを示したと考えられます。 BlackwellアーキテクチャとAWSの統合は、AIのパフォーマンスと効率性を最大化し、持続可能な方向に進んでいるようです。
特にOmniverseのような技術はデジタルツイン環境を通じて運用効率と革新の可能性を高めており、AI技術の実質的な導入を支援するために今後もNVIDIAとAWSは新しい技術とプラットフォームで企業がAIをより効果的に活用できるように協力続くと期待されます。
記事 │MEGAZONECLOUD Cloud Technology Center (CTC) Cloud FSI SA 3チーム チョン・ハフンSA
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び