MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Accelerating auditing and compliance for generative AI on AWS
セッション概要
- タイトル:Accelerating auditing and compliance for generative AI on AWS
- 日付:2024年12月2日(月)
- Venue: Mandalay Bay | Lower Level North | South Pacific E | Mint Green
- スピーカー:
- Andrew Kane(WW Tech Lead – GenAI Security and Compliance, Amazon Web Services)
- John Fischer(Sr Specialist Solutions Architect, Amazon Web Services)
- 業界: Professional Services
- 概要:生成型AIは革新をもたらしますが、責任ある使用に関連する課題があります。このセッションでは、Amazon Bedrock と Amazon S3、AWS Lambda、Amazon VPC などの AWS サービスを活用した生成型 AI アプリケーションの使用方法について説明します。また、コンプライアンスとガバナンスのためのAWS Organizations、AWS Audit Manager、AWS CloudTrailを活用して、インフラストラクチャの監査と証拠収集の自動化による監査準備レポートの作成方法を紹介します。
はじめに
セッションは、ジェネリックAIと伝統的なAIの監査とコンプライアンス活動に対処し、ジェネリックAIアプリケーションのライフサイクルに焦点を当てます。
生成型AIの規制準拠活動は、非決定論的特性のために複雑であり、これは従来のAIモデルの予測可能な出力とは異なります。ここで、非決定的特性とは、同じ入力に同じ結果であることを保証する従来のAIモデルとは異なり、学習データによって同じ入力であっても異なる結果を導き出す生成型AIが持つ制御しにくい性質をいいます。
LLMなどの生成型AIモデルは、膨大な非構造データで訓練されており、従来のAIの有限データセットとは異なり、インターネット全体を含めることができます。生成型AIの出力は予測が難しく、技術的な消費者だけでなく、さまざまな消費者を対象とすることが多いです。生成されたAIを介した出力に偏りがないことを保証するのは複雑で、S3バケット暗号化検証などの従来のAIの直感的な作業とは異なります。
生成型AIはさまざまな産業分野で使用されており、その使用はますます増加しています。しかし、生成型AIは、既存のソフトウェアとは異なり、データに基づいて学習して予測するため、既存の監査とコンプライアンス方法では十分ではありません。
このセッションでは、AWSが生成されたAIの監査とコンプライアンスへの取り組みがどのような基準と方法で行われているかを見てみましょう。
Agenda

このセッションの主なアジェンダは次のとおりです。
- 伝統的なAIと生成型AIの監査と規制準拠の観点からの主な違い
- 生成型AIアプリケーションの近況
- 生成型AIのAWSが提案するBest Practice
- 主な事項
生成型AIが従来のAIと異なる点
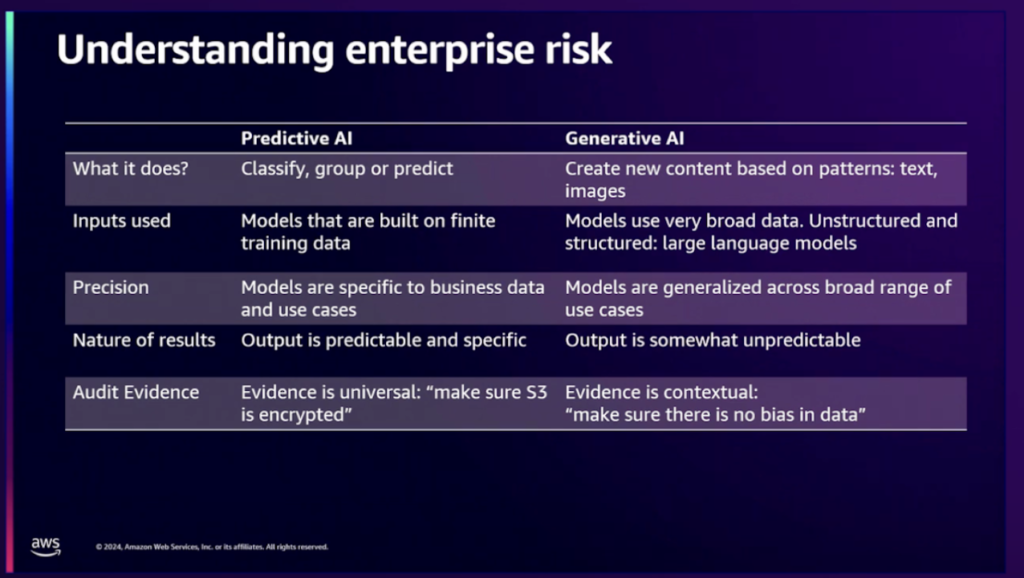
アジェンダで伝統的なAIと紹介されている予測型(Predictive)AIと生成型AIの比較です。
予測型AIは有限なデータセットを持っており、私たちが質問する前にある程度答えを推測して期待できると言います。しかし、生成型AIは大規模言語モデルに基づいて動いており、結論が決定的ではなく結果がわからないという。同じ入力をしても同じ出力を保証できないという。
生成型AIアプリケーションの近況

生成型AIの助けを借りて効率性と生産性が向上するにつれて、ユーザーエクスペリエンスが向上し、コストも削減され、新しいサービスを提供しています。競争でも優位を占めており、創造性と革新が現れています。
いずれも生成型AIがもたらす利点であり、これを責任を持って製品を作るために努力しているそうです。
生成型AIのAWSが提案するBest Practice

生成型AIを監査するベストプラクティスであり、8つの領域に分けられ、正確性、正しい、プライバシー、回復力、責任、安全、セキュリティ、持続可能性についての内容で構成されています。私たちはこれを見たことがあります。
既存のITシステムとも関連があり、AIとは無関係のAWSシステムでも強調していたベストプラクティス特性があります。 (https://aws.amazon.com/architecture/well-architected)
後半にこれを扱いたいです。
正確さ

生成型AIが不正確な回答を出す状況を防ぐにはどうすればよいですか?
実際に作業しているドメインに基づいてシステムが正確であることを、テスト記録を介した監査および規則に従って証明することができるはずです。学習データに関しては検証も必要です。
データはどこで取得したのか?データを購入した後に改ざんされたことがありますか?組織内に役立つためにデータを処理した人がいますか?それとも一部のデータが気に入らず、最近1週間以内に変更した人は誰ですか?
この質問に答えるためのトレーサビリティが必要であることは言うまでもありません。
不正確な回答はシステムの信頼性に影響を与え、評判と金銭的なダメージ、さらに軍事、財務システムに影響を与えると、より深刻なダメージをもたらす可能性があります。

これを解決するには、Amazon Bedrockモデル評価を使用できます。生成されたデータセットを呼び出してモデルを自動的にテストできます。さらに、Audit Managerを使用して整合性チェックを行うことができます。学習データが改ざんされていないことを監視し、手動入力が必要な場合はその項目を追跡する方法まで提供されます。
公平性

生成型AIを提供する際には、多様性、平等、人種、性別、宗教、年齢、政治的見解など、さまざまな観点から公平性を取らなければなりません。大規模モデルを購入して使用する場合、微調整などでデータセットを制御できないため、購入前に使用したいモデルか、ライセンスや説明を確認する必要があります。さらに、提供されたデータセットに偏りが検出された場合、これを修正して微調整を実行して、公平性の観点からより良いデータセットを得ることができます。
個人情報保護

生成型AIで詳細な情報を取得するには、詳細な学習データが必要です。これを扱う人は生成型AIを通じて詳細な情報を得るが、リバースエンジニアリングを通じて学習データへのアクセスが不可となるように暗号化され、類推できないように差分個人情報保護を通じて個人情報のアクセスを防ぐことができます。
個人データが必要な場合は、モデルにデータが入ったり出力されたりするときにセキュリティ処理が必要です。個人情報に対する配偶者の同意処理、生成型AIが実行される位置に対する法律の反映と修正された法律に対応できることが必要です。また、個人情報の流出に対する拡大手続きに対する準備も迅速な事故対応のために必要です。
これを追跡するための例として、S3バケットのデータイベントをCloudTrail Lakeで照会して、ソースデータにアクセスしたりデータ作業を監査したりできます。
回復力

回復力は生成型AIでも主要な項目です。 AWSは、AIではなくITシステムでも達成しなければならない主な項目であり、Region-setという地理的に近いRegionを束ねてグループを作成し、グループ内の負荷急増に対してワークロードを配布して処理するように構成しています。特定のRegionの問題発生時にRegion-set内の他のRegionが対応するのはもちろんです。
責任

今生成型AIの8つの項目のうち責任を言う順番です。責任は、残りの7つの項目から帰結する最後の項目です。すべての項目の最後は責任で帰結するということです。
生成型AIを構築し、運営する人はすべて結果に対して責任があり、生成するすべてのものに対して責任を負う必要があります。
責任を負うために内部検討等の監査及び規定遵守等の業務を遂行しなければなりません。
IT世界に存在する多数の規制準拠を実施するために、AWS ConfigのConformance packの助けを借りて入手できます。これにより、世界の規制が現在のシステムの設定を満たしていることを確認できます。
安全

生成型AIが提示する結果の範囲は制御可能でなければなりません。さらに、顧客に提供したくない情報を提供しないようにすることも重要です。
これを解決するために、Amazon Bedrock GuardRailsが用意されています。これはAIモデルから分離されており、顧客が直接制御できます。コンテンツや特定の単語をフィルタリングしたり、特定のトピックを拒否したり、個人情報をマーキング処理するなどの提供情報のフェンスを設定できます。
セキュリティ

すべてに最優先する最初の作業(Job Zero)セキュリティについての話です。すべてのデータは転送中でも保存中でも暗号化され、顧客のデータはモデルの学習データと共有されるべきではありません。そして、Amazon Bedrockはそれをやっています。
転送中の暗号化は少なくともTLA1.2以上であり、保存中の暗号化はAES-256を使用します。顧客が望むときは、KMSキー暗号化も可能です。また、20以上の規制準拠基準を適用しています。 Bedrockの使用に対するアクセス権の調整のためにControl Towerが用意されています。学習データとモデルの作成とアクセスを承認されたアカウントに制限できます。これを監視するためにSecurityHubが提供されています。
クラウドセキュリティ態勢モニタリングを提供するために、Config、Guardrailなどで検出された Findingsを外部セキュリティソリューションに渡して連動することも、外部ソリューションからも提供することができます。
持続可能

すべてのことが持続可能であることは、AWSにとって非常に重要な点であり、そのためにインフラストラクチャを効率的に変え、Graviton、Trainiumなどを開発し、消費エネルギー単位当たりより多くの処理能力を得ています。
その可視化のために、AWSコンソールのビリング部分でCustomer Carbon Footprint Toolを提供します。使用しているサービスに応じて炭素排出量を見積もることができます。地域の予想炭素排出量を特定し、高い炭素排出源を特定するのに役立ちます。これは、AIの責任ある使用を拡大し、炭素排出権などを活用するのに役立つでしょう。
まとめ
やや退屈ですが、やらなければならない話でいっぱいのセッションでした。生成型AIはどのようにすべきか、AWSはどのような準備をしているのかを確認することになりました。冒頭で生成型AIの主な項目8つについての見方を申し上げました。それで、その2つを一度比較してみました。
- 生成型AIのベストプラクティス8項目
– Accuracy
– Fair
– Privacy
– Resilience
– Responsible
– Safe
– Secure
– Sustainable - AWS Well-Architected Framework 6 項目
– Operational Excellence
– Security
– Reliability
– Performance Efficiency
– Cost Optimization
– Sustainability
何か重ねてみませんか?おそらく重複する部分はITシステムとして当然持たなければならない徳目なのかもしれません。
- 生成型AIの領域のうち、既存のAWSと重複または対応する項目
- Resilience (回復力) ←→ Reliability (信頼性)
- Secure (セキュリティ) ←→ Secure (セキュリティ)
- Sustainable (持続可能) ←→ Sustainability (持続可能性)
それでは、彼から抜け出す5つの項目はどんなものでしょうか?
- 生成型AIの領域のうち、既存のAWSと重複または対応していない項目
- Accuracy(精度)
- Fair (プロセス性)
- Privacy (個人情報保護)
- Responsible (責任)
- Safe(安全)
やや技術的なもので達成しにくいテーマでありながら一面道徳的なテーマではないかと思います。
逆にそうなので、生成型AIが備えなければならない主要項目になったのかもしれません。
AIは私たちの社会をどのように変貌させるのかまだ分からず、ただ私たちはこうしてドリムン術するが弱いフェンスでも打って、私たちの社会が約束した線を越えないよう警告しているのかもしれません。
記事 │MEGAZONECLOUD Strategic Technology Center(STC) CS1グループ CA1チーム イ・テフンSA
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び -
 Compliance & Identity Kubernetes re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #KUB315|Amazon EKSでKubernetesワークロードを保護
Compliance & Identity Kubernetes re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #KUB315|Amazon EKSでKubernetesワークロードを保護