MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #FSI320|Bloomberg:AWSでのLLMの構築と教育から学んだ教訓
Bloomberg: Lessons learned from building and training LLMs on AWS
セッション概要
- タイトル:Bloomberg: Lessons learned from building and training LLMs on AWS
- 日付:2024年12月3日(火)
- Venue:MGM Grand | Level 1 | Grand 116
- スピーカー:
- Phil Vachon(Head of Infrastructure, Bloomberg)
- Vadim Dabravolski(Team Leader, Bloomberg)
- Vasu Chari(Principal Solutions Architect, Amazon AWS Inc)
- 業界:Financial Services
- 概要:安全で効率的なモデルトレーニングは、生成AI機能を構築し、投資収益率を高めたいすべての組織にとって不可欠です。金融サービス分野におけるAI/MLのリーダーであるブルームバーグは、AWSを活用して大規模な言語モデルだけでなく、小規模な言語モデルの構築とトレーニングを行った経験から得た教訓を共有します。ブルームバーグがモデル開発過程で、大規模なGPUノードネットワークを通じて大規模なデータボリュームを管理し、自動化、標準化し、データセキュリティを維持しながらトレーニングプロセスをより安全に進めることができた方法をご紹介します。また、モデルトレーニング時のインフラストラクチャ、データ保存および転送手順の自動化が、モデルトレーニングのエラーを減らすためにどのように役立つかについてもご紹介します。
はじめに
AI/MLを先駆けて導入しているようですが、大規模モデルを構築する会社はほとんどありません。これは、GPUインフラストラクチャの運用とモデル学習に多くの費用と実力のあるチームが必要なためです。より重要な高品質の大規模な資料も条件になります。グローバル金融サービス業の先導的なデータ提供会社であるBloombergは、このすべての条件を備え、独自の大規模な言語モデルを教育しました。
このセッションで、彼らがBloombergGPTを作るために直面した課題について学んでください。
Agenda

Bloomberg は、AWS を活用してそのモデルを訓練する過程で得られた教訓と経験を共有しています。このプロセスでは、大規模なGPUネットワークを介して膨大なデータを管理し、インフラストラクチャを自動化およびテンプレート化することでデータの保存と転送の問題を解決し、データセキュリティを維持しながらエラーを減らすトレーニングプロセスを構築しました。これにより、モデルトレーニングプロジェクトを迅速に開始し、革新と製品開発を加速することができました。
Bloombergは、2009年からAIを活用して顧客に市場をリードする洞察を提供してきました。これらの技術は、金融データから重要な情報を見つけるのに役立ちます。
- In the beginning…(最初にしたこと)
- The training process
- Managing training infrastructure
- The results
- Applying out research in get AI-enhanced products
- If we had to do it again today?
In the beginning…

ブルームバーグは、大規模言語モデル(LLM)の可能性を認識し、顧客に価値を提供するために2009年から研究を進めてきました。彼らは信頼できる要約と効率的な検索機能を改善することに焦点を当てています。
主な評価要因としては、学習データの量とGPU時間が考慮されました。金融分野の専門用語を活用して、金融サービスに適した特化したモデルを開発する可能性を探りました。これには、顧客の高いレベルの期待にどのように応えることができるのか、継続的な疑問が続きました。また、モデル学習に必要なコンピューティング容量の確保は高質な問題であり、特にGPU資源の確保はグローバル半導体危機でさらに困難でした。
The training process
GPUの需要に噛み合い、コロナによるチップ供給不足によりGPU資源の確保が新たな障害となりました。
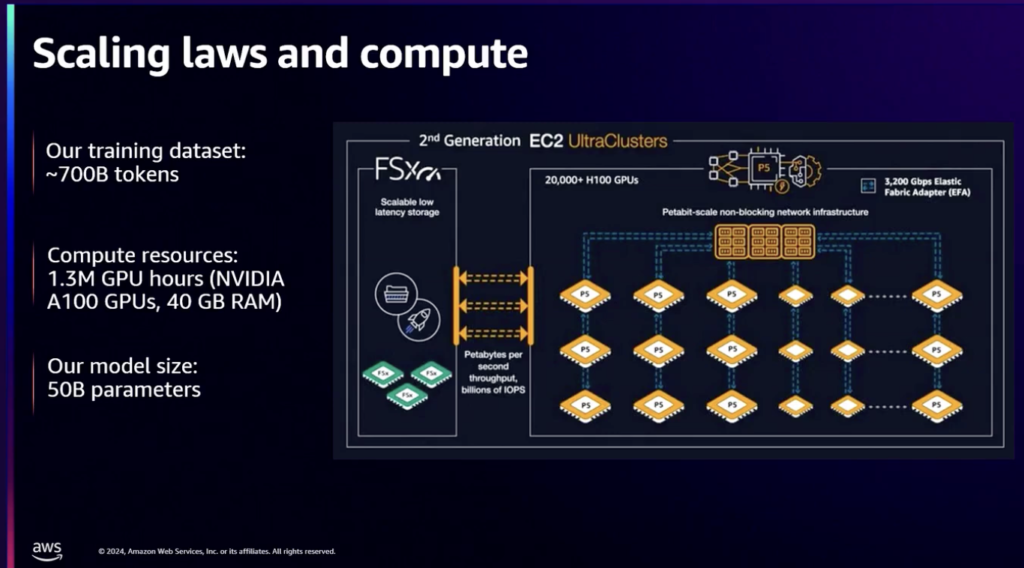
資源コストの検討のためにBloombergが保有する学習データを計算した結果、7000億個のトークンで識別され、
500億個のパラメータモデルとNvidia A100 GPUで130万時間が必要であることを確認しました。 AWSの予約により、P4 EC2 UltraClusterを選択してGPUリソースを確保できました。
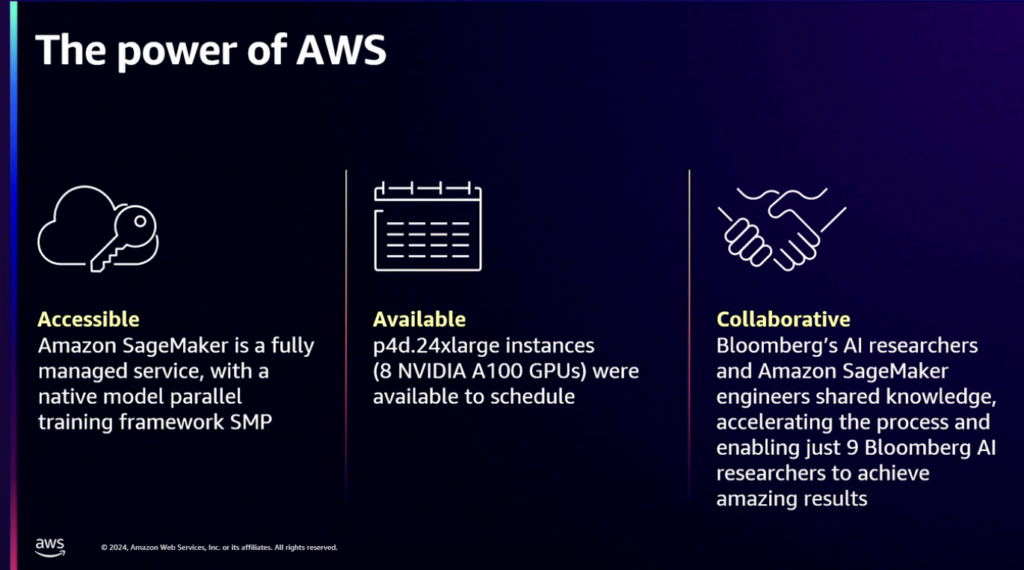
Amazon SageMakerでモデル学習を進めるのは簡単な決定でした。たとえば、当時の最新のハードウェアで発生したハードウェアの欠陥やドライバの問題などをデバッグすることなく、AWSを介してモデル学習に集中することができました。 AWSとの緊密な関係と専門家のサポートのおかげで、9人のAI研究者だけがモデル学習を実行できました。
Managing training infrastructure
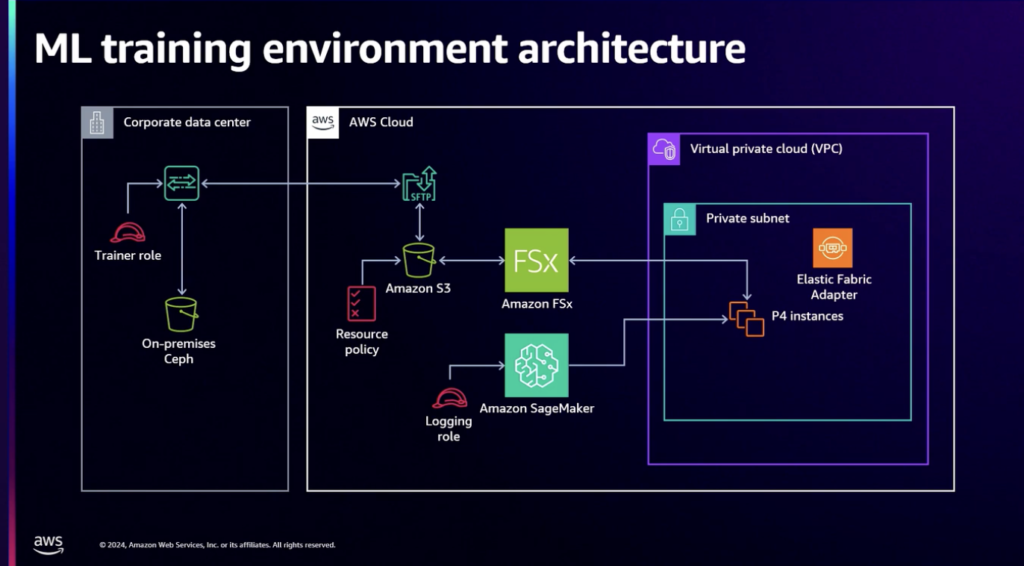
データセンターのデータをAmazon SageMakerと関連付けるのは、当時の標準であるテラフォームを適用することで簡単に構成されました。 AWSを介してSageMakerを学ぶことは主な課題であり、クラスターがインターネットへのアクセスを隔離することを保証するために長い間ボールを上げました。
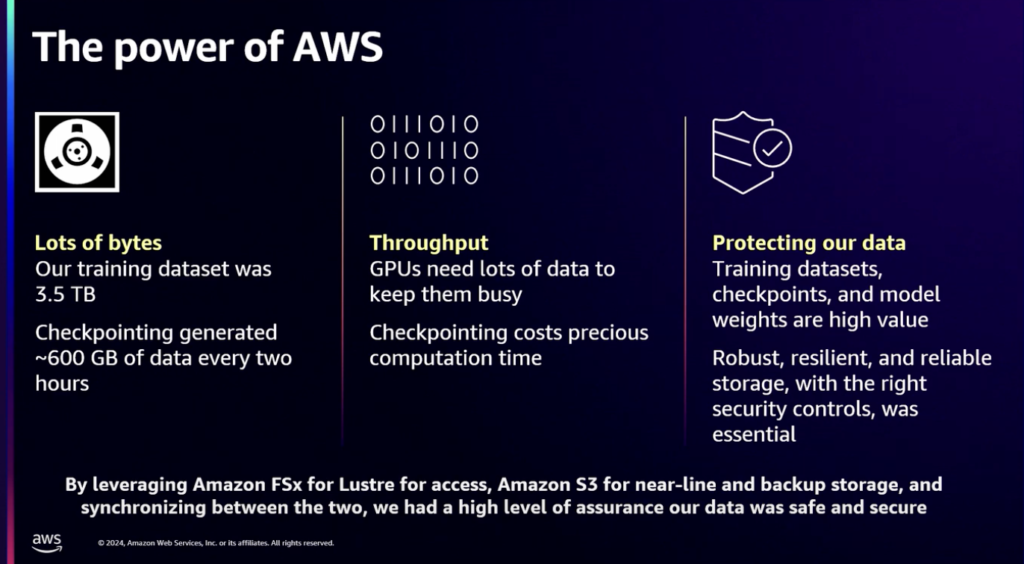
保有した学習データは3.5TBで、2時間ごとに発生するチェックポイントは600GBでした。パフォーマンスの面では、GPUは多くのデータを扱うことができ、チェックポイントもすばやく処理する必要がありました。
データ保護のためのバックアップ、もちろん、高価値データへのアクセスは、保護された要件を満たすためにAmazon FSxを使用しました。これにより、学習データが簡単にアクセスできるだけでなく、低レイテンシと必要なセキュリティが適用されていることが保証されます。
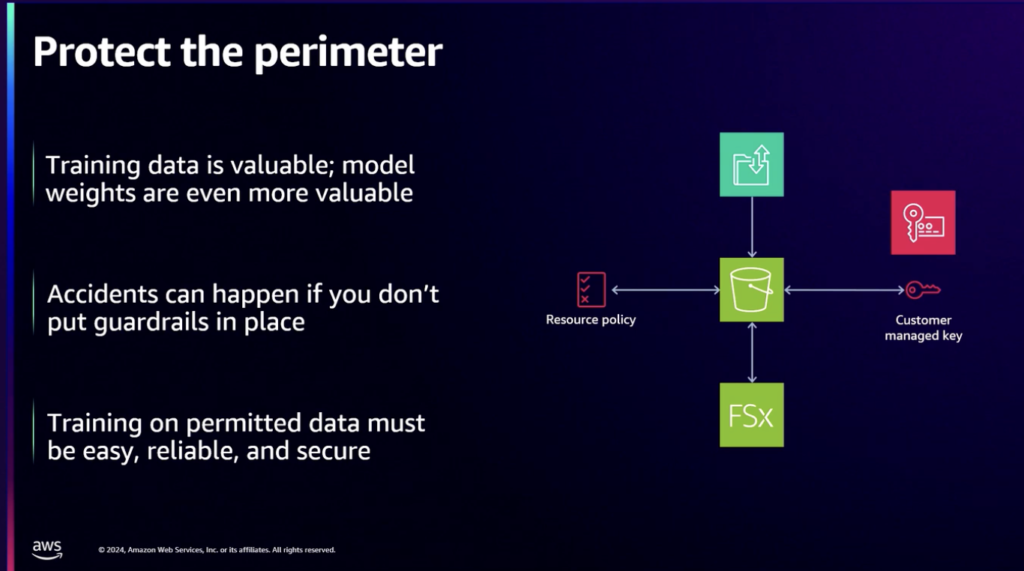
学習データは貴重なので、公開されないように学習データを読み書きする権限を持つサービスだけがアクセスできるようにすることが重要です。 GPU資源も無駄や消臭を避けるために権限とアクセス制御が必要であり、リソース使用のモニタリングが重要でした。 LMは当時と今でも急速に発展する分野で、研究者が実験を容易に始め、大規模な訓練作業で収集された学習を通じてコンプライアンスを維持できるようにします。

大規模な言語モデルの学習は、分散型の高コストな作業であり、数百の複雑な計算を数百のノードにわたって分けて実行し、これを数ヶ月間進めます。
単一ノードでの避けられない障害はエレガントに処理し、可能であれば自動的に処理する必要があります。
コストと研究効率が最も重要なので、最初の大規模な学習を始める前に、運用アーキテクチャの計画に時間を費やしました。この目的のために、回復可能なエラーと非回復可能なエラーの概念を導入し、エラーの種類に応じて異なる修正制御を実装しました。修正作業を実装するために、CloudWatch LogおよびMetricsとのネイティブ統合を広く使用しました。
The results

その結果、BloombergGPT研究モデルという論文で導出される成果がありました。
財務に特化したモデルとして、当時使用可能だった一般モデルよりもはるかに多くのパラメータを持つモデルです。
重要なのは、このモデルをあらゆるアプリケーションで使用することを意図したものではなく、大規模な言語モデルを統合するアプリケーションを探索するのに役立ちました。当時、多くの人はモデルがユーザーエクスペリエンスとワークフローにどのように合わせるべきかを深く心配していませんでした。 ChatGPTが普及したエージェントベースのモデルが最も効果的かどうかは未知数です。
Applying out research in get AI-enhanced products

構築したモデルを使用して製品とアプリケーションをどのように構築するかを活用する方法の3つの原則を開発しました。
- まず、モデルのすべての出力が信頼できるソースから出るべきです。
- 第二に、ユーザーはシステムとアプリケーションを使用するコンテキストでモデルを評価する必要があります。ユーザーが使用できるように、空白を提示するプロンプトインターフェイスではなく、ガイドするステップのインターフェイスを使用する必要があります。また、ユーザーが簡単にフィードバックを提供する方法を提供し、得られたフィードバックを製品にすばやく反映する必要があります。
- 第三に、最も重要な原則である透明性は、モデルがデータのソースに対して透明に提供する必要があることです。
ユーザーは特定の出力の理由と元のソースを見ることができ、そのソースにアクセスできる必要があります。

このように装備されているモデルについて何かを照会したいときは、BQL(Bloomberg Query Language)を通じて売上、株価情報などを照会することができます。より詳しく見たい場合は、より多くの関数を組み合わせて洗練されたデータを取得できます。
BQLの専門家でなければならず、モデルをより深く理解しなければならないので効率的に見えません。

BQL作成の代わりに自然言語照会を通じてBQLを生成し、答えを得ることができれば、より良いでしょう。
このモデルは、BQLの自動生成と理解のために微調整されています。自動生成で得られたBQLをさらに発展させて活用することもでき、ユーザーがデータにアクセスしやすくなります。
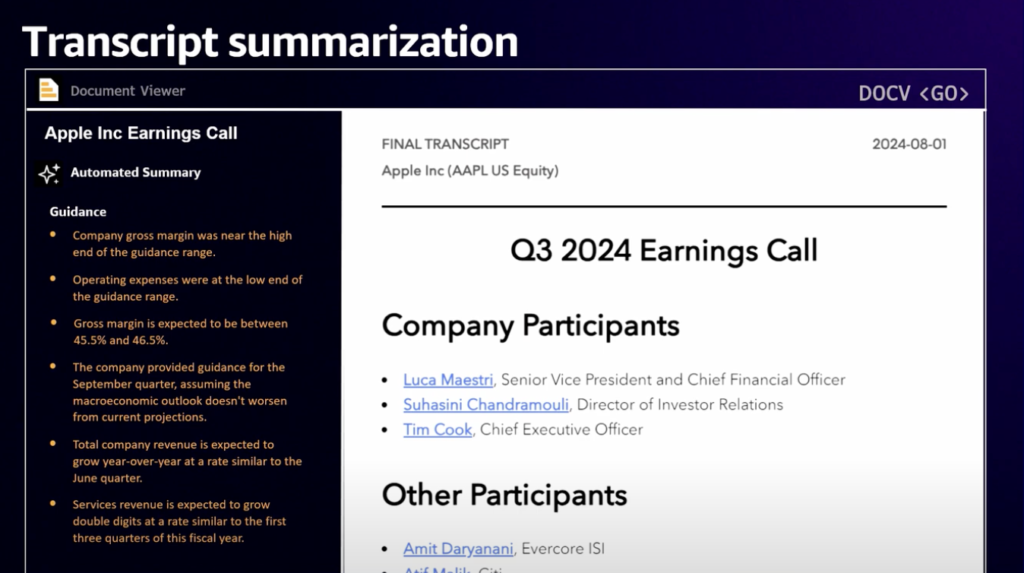
金融家の収益シーズンになると、数百ページに及ぶ金融報告書が分析対象となり、アナリストはできるだけ早く洞察力を発揮して全体を見ることができなければなりません。実際、この特定の2024年第3四半期のApple収益通貨で自動サマリーとして生成されたいくつかの発見と主要なガイダンスを見ることができます。
私たちの目標は、収益通貨の完全な要約を提供するだけでなく、アナリストがこの通貨について持つことができる質問に答えることです。
そのために、検索強化生成(RAG)パラダイムを使用することを選択しました。金融サービス顧客の質問に答える専門家である内部分析家が顧客の運営方法、アナリストが一般的に答えるような質問リストに答えてモデルを訓練し、高品質の要約サービスを提供することができました。
If we had to do it again today?

2年前にやったこと、今やったら?
すべてがSageMaker Hyperpodを介してターンキートレーニングとツールとライブラリをすぐに使用できます。基盤を提供することも非常に生産的です。
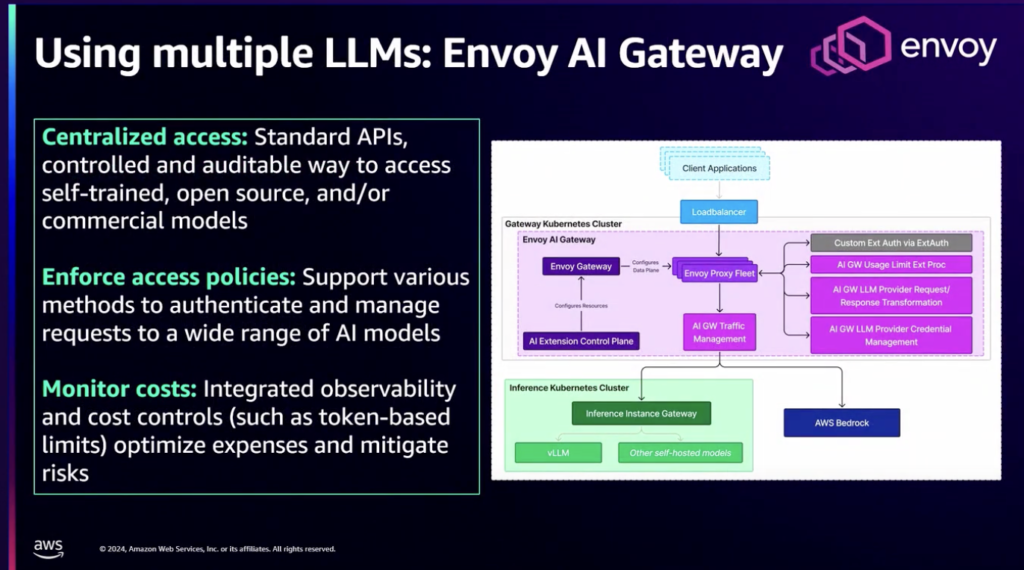
大規模な言語モデルの作業を運営するための旅を始めながら、LLMにアクセスするためのゲートウェイ機能を提供する既存のオープンソースソリューションのいくつかは、強力な傾向分離、分岐管理、コスト帰属などの不可欠な企業機能が不足していることを示しています気づきました。そして、異なる推論プロバイダ間の高度なルーティング機能も欠けていました。
このギャップを解消するために、ブルームバーグはエンボイコミュニティと協力してエンボイAIゲートウェイを構築しました。
Nvoy AI GatewayプロジェクトはBloombergチームとTatrateチームによって開発されており、集中型API管理、強力なアプローチとコンプライアンス管理、コストと容量管理などの主な機能を持っています。
まとめ
自分たちが持つ膨大な良質の学習データで大規模な言語モデルを構築して学習させ、その結果物を論文に出し、照会する言語を開発し、インターフェースと価値ある自動要約まで到達しました。
それから、こう尋ねます。この時間と費用をかけても自分だけのモデルを構築するのは正しいでしょうか?
むしろ、すでに装備されているモデルを活用して微調整するか、RAGを使用して追加のコンテキストを提供することがより重要であるという意見を述べます。私もその考えに同意しますが、最後まで推進してモデルとアプリケーションでまで完成した突っ込みに拍手を送りたいと思います。
記事 │MEGAZONECLOUD Strategic Technology Center(STC) CS1グループ CA1チーム イ・テフンSA
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び