MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #NTA311|生成型AIがAWSを通じ、リーガルテクノロジーをどのように変化させているか
How generative AI is transforming legal tech with AWS
セッション概要
- タイトル: How generative AI is transforming legal tech with AWS
- 日付:2024年12月4日(水)
- Venue:MGM Grand | Level 3 | Chairmans 355
- スピーカー:
- John Motz(CTO, NetDocuments)
- Olta Alushi(Sr SA leader, AWS)
- Pallavi Nargund(Principal Solutions Architect, Amazon)
- 業界:
- Cross-Industry Solutions
- Professional Services
- 概要:NetDocumentsは、法律分野のためのクラウドベースの文書管理におけるリーダーです。彼らのプラットフォームは、世界中の文書の保存、共有、およびコラボレーションを可能にします。 NDが革新的なソリューションと意味ベースの検索で文書管理をどのように進めるかを学びましょう。毎日何百万もの文書を処理します。法律産業、特に法律事務所および企業法務部門は、しばしば大規模で複雑な文書で困難にさらされています。生産的なAIが進化するにつれて、新しい生産性向上アプリケーションが登場しています。膨大な文書リポジトリの検索、ファイルの要約、Q&Aシステムのサポート、文書のドラフト作成。このセッションでは、生成されたAIが法務業務をどのように変え、効率性を高め、文書中心のワークフローを簡素化して職業を革新できるかを見てみましょう。
はじめに
生成AIは法律技術分野を急速に変化させており、法律専門家が退屈な作業を自動化し、効率性を大幅に向上させることができるようにしています。このセッションでは、AWS がこのテクノロジを統合して、よりスマートな法的研究とドキュメント処理を可能にする方法について説明します。主なテーマは、法の実務の不可欠な人間要素である共感と擁護を維持しながら生産性を向上させることに焦点を当てています。議論されたイノベーションは、自動化された予測と迅速な契約の作成につながる可能性がある生成AIが法産業の未来をどのように再構築できるかを示しています。 AWS で法律ワークフローを再定義する最先端のツールと戦略について、貴重な洞察を得ることができます。
法律業界と生成型AI

法律契約の作成時間を短縮したり、弁護士や法律専門家が事例を予測するのにかかる時間を短縮したい場合はどうでしょうか。研究によると、今日の法律業務の最大44%を自動化することができ、これは他の産業よりも高い数値です。
生成型AIの可能性は、法律の専門家が彼らの職業で最も人間的な側面、すなわち共感、人間性を発揮できるようにすることにあります。

法的技術が直面する主な課題も存在します。
- 第一に、大規模な非定型データを管理することが困難である。非定型データとは、きちんと整理されていないデータを意味し、法律文書のように複雑で多様な形式のデータを扱うことは困難です。
- 第二に、法律スキルの価値と実力バランスの問題があります。自動化は、実務経験の少ない初心者の弁護士に影響を与える可能性があります。
- さらに、データのプライバシーとセキュリティの問題も重要です。データがデジタル化されクラウドに移行される過程で、ヒューマンエラーや誤った設定によるデータ漏洩のリスクが高まります。
- 最後に、間違ったシステム選択は生産性の低下を引き起こす可能性があります。技術は人材を置き換えるのではなく、人間の要素を強化する必要があることを強調しています。
フライホイール(Flywheel)概念の文書処理システムを導入すると、投資コントラストパフォーマンス(ROI)が向上し、法律専門家が複雑なクエリを効率的に実行し、契約作成時間を大幅に短縮できます。
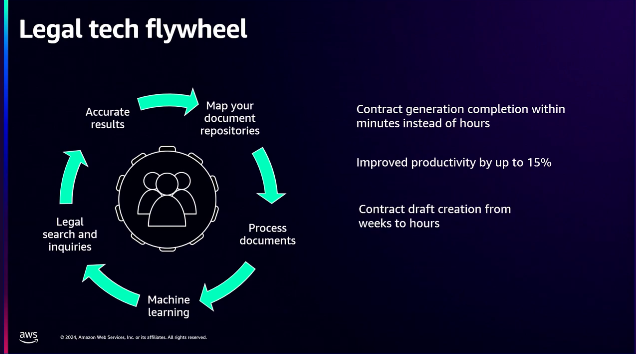
文書処理アプローチを使ってその概念を説明しましょう。まず、ドキュメントストアをマッピングします。
組織内の全員がこのデータを検索できるように集中し、自然言語処理で内容を分析します。
その後、メタデータを抽出してより整理します。 AIと機械学習機能を追加してパターンを分析し、データの意味を学習するシステムを作成します。
法律家の専門家がこのデータセットについて照会すると、数分で正確でコンテキストを考慮した応答が生成されます。
時間の経過とともに改善され、契約のドラフト作成は数週間から数時間で、契約の自動作成および完成に数時間から数分以内に完了するため、生産性が最大15%まで向上します。
NetDocumentsの歩み

NetDocumentsは法律文書管理分野で20年以上運営されている会社です。世界的に6つの地域で事業を運営しており、その地域の様々な国で事業を展開しています。 約5,000社が顧客であり、現在かなり急速に成長しています。
私たちは世界中で185,000人のユーザーを抱えており、彼らは法律の専門家、秘書などです。80億以上のドキュメントと200億以上のファイルがあり、21ペタバイトのデータを保有していますが、これはほぼ毎日変化しています。おそらく最も重要で印象的なのは、1日に約6億5千万件のトランザクションを処理していることです。
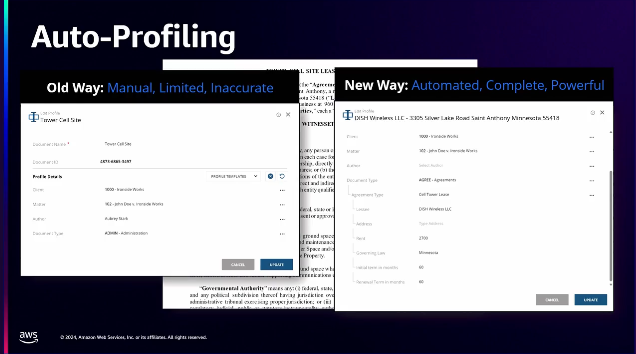
初期契約書のドラフトを自動生成する際に、いくつかのパラメータが必要です。
左のスクリーンショットのような方法は、典型的な古い方法であり、受動的で、制限的で、やや不正確です。
右側の新しい方法では、1つの会社に数千、場合によっては数万の契約がある管理会社があります。 彼らにはルールがあり、コンプライアンスがあり、パラメータがあります。
100,000件の契約のうち、この15件は本当に悪い解約条項があります。これらを確認し、潜在的に書き直す必要があります。 この簡単な例は、会社が掘り下げるのに数週間かかるかもしれないことを数分で処理することを可能にします。
リスクを合理化し、実際にフラグを立ててプロセスを自動化することで、企業内のリスクを劇的に減らすことができます。
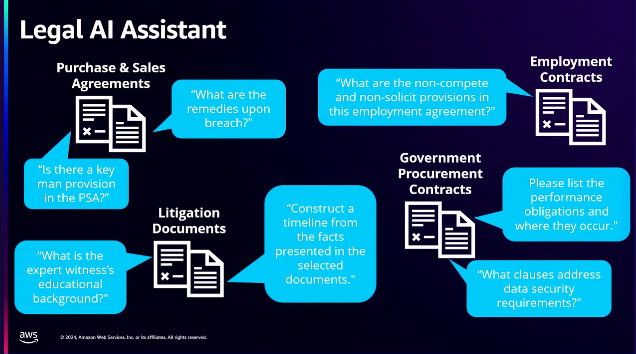
法律AIアシスタントを通じて、数多くの法律条項と事件、契約文書に質問と回答をLLMを通じてやり取りすることができます。
AWS Titanとセマンティックデータ、LLMサービスを活用した成果です。
法律技術のユースケースと参照アーキテクチャ

法律業界の課題と、特に法律業界内で文書や非構造化データが重要なオブジェクトであることについて多く取り上げました。 法律業界が扱う年間数十億件の文書が対象です。
顧客が求める多くのユースケースをまとめると、3つのカテゴリーに分類することができます。
1つ目は要約です。すべては文書から始まるので、事件および事案別の契約概要、事件概要、各条項の概要などが必要です。事件と事案を扱いながら、承認過程で添付されたコメントも要約が必要です。
文書の要約は法律研究分野では非常に重要なので、文書を要約し、生成AIがその文書を要約してユーザーにアクセスできるようにすることで、法律専門家が多くの時間を節約することができます。
2 つ目は、インタラクティブなQ&Aと検索です。膨大な文書セットに対するQ&Aが可能で、データに対して人と会話するような質疑応答システムが必要です。ここでのアイデアは、インシデント管理を知識管理に変えることです。 非構造化データやインシデントの量を把握し、それを分類し、整理し、検索可能にする必要があります。
3つ目のケースは、テキスト生成です。標準化されたテンプレートがあれば、標準化された契約書やRFIプロセスを起草することができます。自動化されたワークフローを通じて文書のドラフト版を生成できるようにすることです。
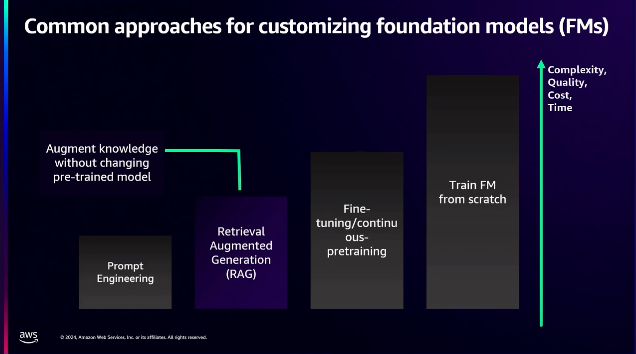
大規模言語モデル(LLM)は、テキスト生成またはテキスト関連作業のための特定の基礎モデルのサブセットです。基礎モデル、つまり大規模言語モデルをそのまま使用することはできないことは誰もが知っています。カスタマイズが必要です。
ここには、おなじみの4つのステップがあります。
最初のステップは常にプロンプトエンジニアリングから始まり、基礎モデルの出力をニーズに合わせて調整するための具体的な指示を指定します。
3 つ目の微調整段階があります。基礎モデルの重みを調整して、専門化されたタスクに特化したモデルを生成しながら、基本的な生成能力を維持することで、基礎モデルの微調整や事前トレーニングを行うことができます。 しかし、これだけでは不十分な場合もあり、基礎モデルがユースケースに適合しないバイアスを持っていたり、十分な学習データがない場合もあります。
最後に、このような場合は、モデルを最初からトレーニングすることを選択する必要があります。 このステップを踏むごとに、時間コストと複雑さが増えますが、精度も向上します。
結論として、ユースケースを検討し、さまざまなステップを評価し、適切な方法論を使用して基礎モデルをカスタマイズすることをお勧めします。
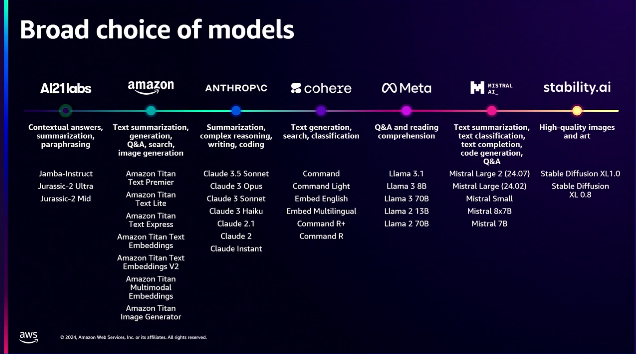
モデル選択の観点から、基本的にモデル間の競争があります。常に新しいモデルが登場しており、どのモデルもすべてのユースケースには適していません。したがって、最終的に顧客が選択するしかありません。
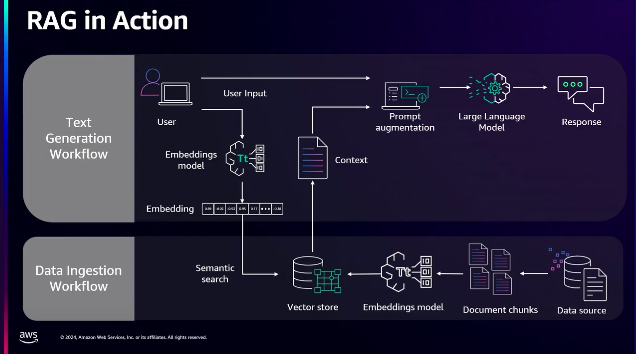
RAGには2つのワークフローがあります。
最初に準備する必要があるデータ注入ワークフローは、既存の保持データから文書を扱いやすい単位であるチャンクに分割し、埋め込みモデルを介してベクトルストアとして保存する必要があります。
したがって、文書のチャンク化、適切な埋め込みモデルの選択、ユースケースに合った適切なベクトルストアの選択は、決定すべき主な決定点になります。
入ってくる文書はさまざまな形式で入ってくるでしょう。 PDF、ワード文書、テキストファイルなどになり、スキャンしたPDFはレイアウトになっていません。したがって、これらの文書がどのようにチャンクに分割されるべきかを理解することが重要です。
ユーザーから要求が入ると、テキスト生成ワークフローが機能します。
ここでは、埋め込みモデルはそのクエリをベクトル表現に変換してベクトルデータベースを検索し、そこからコンテキストを生成します。そのコンテキストは、あなたが書くプロンプトで提供され、大きな言語モデルに渡され、結果が得られます。
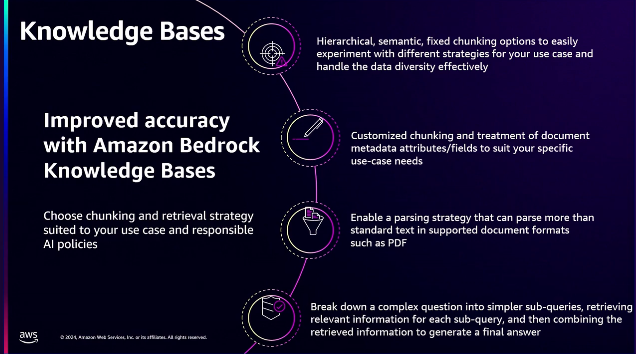
Amazon Bedrockはベクターリポジトリの本質的に統合されており、ドキュメントワークフローを理解するために管理されたRAGアーキテクチャを構築できます。知識ベースの重要な側面は、改善された精度です。
セマンティック検索関連機能を構築したい場合や、大規模な文書を理解して分析したい場合は、文書がどれほどうまくチャンク化されているかを理解することが重要です。
文書に親子関係がある場合は、文書のチャンクを自動的にグループ化して階層を維持するようにします。したがって、その文書を検索すると、階層が維持されるため、文書の正確性が向上します。セマンティック検索と同様に、セマンティックチャンク化機能は、文書に関連するテキストが散在しているため、非常に重要です。
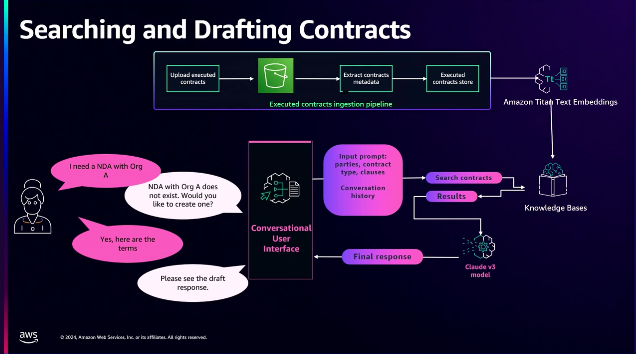
技術プロセスにおける契約処理に関連するアーキテクチャは、すべての組織が持っているものです。
事件が発生した場合、事件管理または契約管理を知識管理に移行することが不可欠です。私たちは、実行された契約をインポートして処理し、同時にメタデータを抽出してベクトルストアに保存するように設計しました。
実行された契約のリストをインポートして追加し、メタデータを抽出し、そのメタデータをベクトルデータベースにリンクして、知識ベースを作成しました。これを使用して対話型インターフェイスを構築できます。このインタフェースはクエリを受け入れ、要求が何であるかを理解し、それがNDAという特定のメタデータを抽出し、ユーザーが知識ベースを検索して正しい結果を構築し、最終的な応答を送信します。
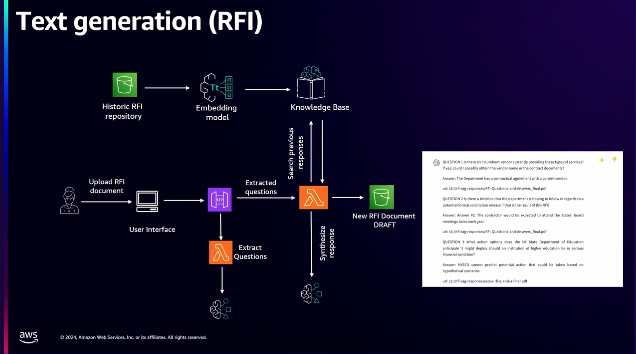
契約前情報要求書(RFI)プロセスを実装したアーキテクチャです。これにより、以前に実行されたRFIから新しいRFIを作成するのに数週間から数日が短縮され、従業員の生産性が向上します。

同様の方法で証言を含む多くのビデオファイルを処理する場合は、Amazon Transcribeを使用してテキストを転写し、それをS3に保存してからAmazon Q for Businessに配置してアクセス可能にすることができます。
それでは、あなたはすぐに見て、「誰が証言し、その内容は何でしたか?」 「この証言を要約できますか?」などの質問をすることができます。
クロージング

ビジネスプロセスやワークフローを改善できる上位3つのユースケースと状況について考えてみてください。 そして、生成型AIのユースケースで最も大きな価値をもたらすものを見逃してはいけません。 もう1つは、AWSコミュニティに参加することです。
まとめ
法律業界は技術採用に対して保守的であるという個人的な先入観を覆すようなセッションでした。
数多くの文書で構成された法律条項、事件、事案などの大規模な文書セットと、これらの文書が持つ共通性である非定型性をどのように扱うかをよく示しました。
膨大な文書セットを扱うためのワークフロー及びアーキテクチャ設計と、非定型文書をLLMのエンベッディングストアに保存するために文書をチャンク単位で細かく分割して保存する一連の過程は、法律技術だけに必要なプロセスではないでしょう。
そして、プロセスごとにワークフローを配置して生成型AIの助けを借りて効率を高める部分も印象的でした。
契約書の自動生成や法律AI-assistantも見逃せませんね。
セッションの内容がやや難解で、親しみにくかったのですが、生成型AIが本当に必要なところで価値を発揮する姿を見ることができて良かったし、これが実装された具体的な事例を確認できたので、よりやりがいのある時間でした。
記事 │MEGAZONECLOUD Strategic Technology Center(STC) CS1グループ CA1チーム イ・テフンSA
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び