MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #NTA401|AWSでの生成型AIのパフォーマンス改善策
Improving the performance of your generative AI application on AWS
セッション概要
- タイトル:Improving the performance of your generative AI application on AWS
- 日付:2024年12月3日(火)
- Venue:Venetian | Level 3 | Murano 3201B
- スピーカー:
- Anoop Talluri(Solutions Architect, Amazon Web Services)
- Akhil Melakunta(Senior Solution Architect, Amazon Web Services)
- 業界:Cross-Industry Solutions
- 概要:Amazon Bedrock を使用して生成型 AI RAG パフォーマンスを最適化する方法のセッションです。最適なモデル選択、ハイブリッド検索の実装、チャンキング戦略、 reranking、ネットワーク構成の改善などの技術を適用して、応答の効率と品質を向上させる方法について話します。
はじめに
今回のセッションでは、AWS で Gen AI アプリケーションを設定する際に、より良いパフォーマンスを作成するためのさまざまな方法についてお伝えしたいと思います。ご紹介します。
適切なモデルの選択
より良いパフォーマンスを持つGen AIアプリケーションを作成するには、最初に適切なモデルを選択する必要があります。最近、ほぼ毎日様々な特徴を持つ新モデルが出続けています。そのため、作成したいGen AIアプリケーションの目的に応じて、モデルのどの特性に集中する必要があるかを判断する必要があります。たとえば、ワークショップセッションの例であるClaude InstantとClaude 3 Haikuを比較した場合は、次のようになります。
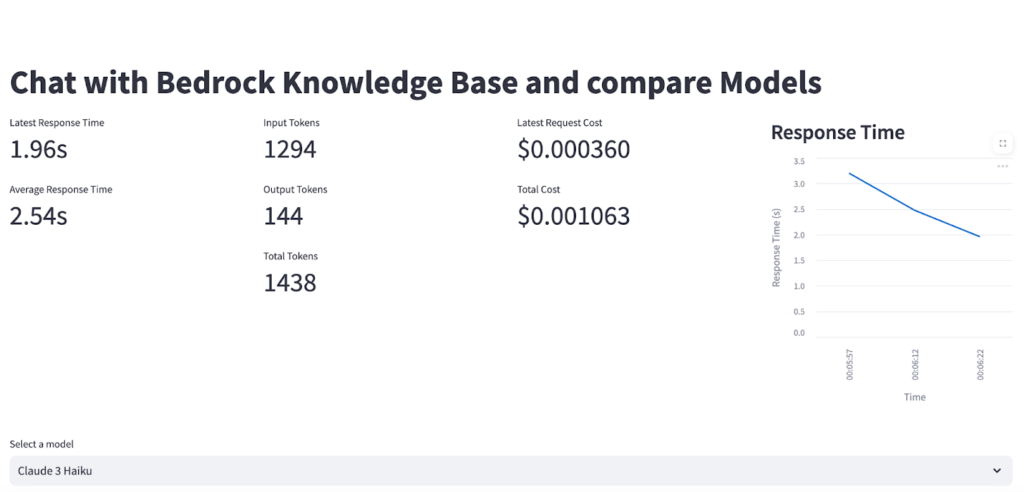
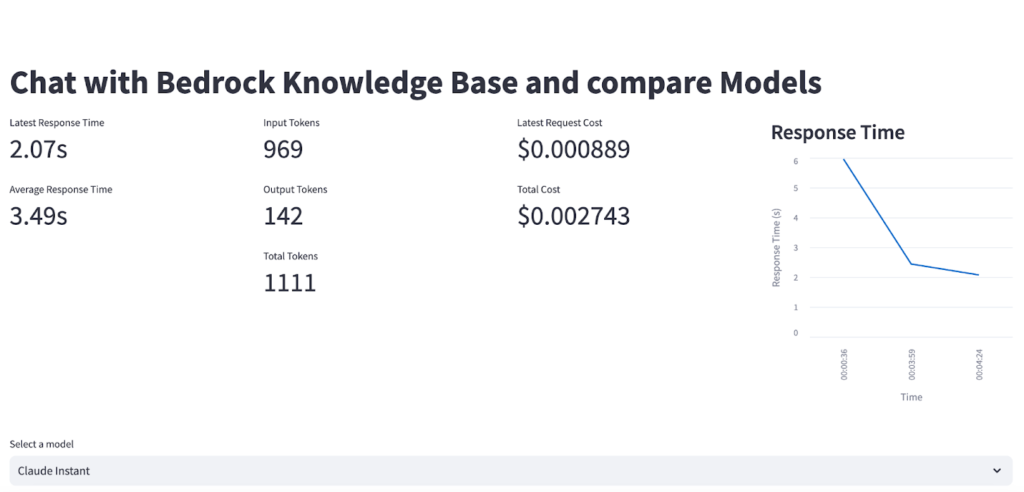
同じユーザーの質問(What is Mandatory Coverage insurance requirements in aurora State for young adults?)を2つのモデルにそれぞれ質問したときにベクトルデータを呼び出す同じプロセスを経た後、LLMを介して答えが出るまでの時間と最終出力トークン、コストを計算した結果です。
このように、モデルごとにレイテンシ、コスト、回答の品質に違いがあるため、それぞれの状況に適した適切なモデルを使用する必要があります。
Chunking戦略、RAG、ハイブリッドサーチ
LLMがユーザーの質問に答えるために正しいデータを読み込めない状況である場合は、RAGとハイブリッドサーチを適用して精度を向上させることができます。
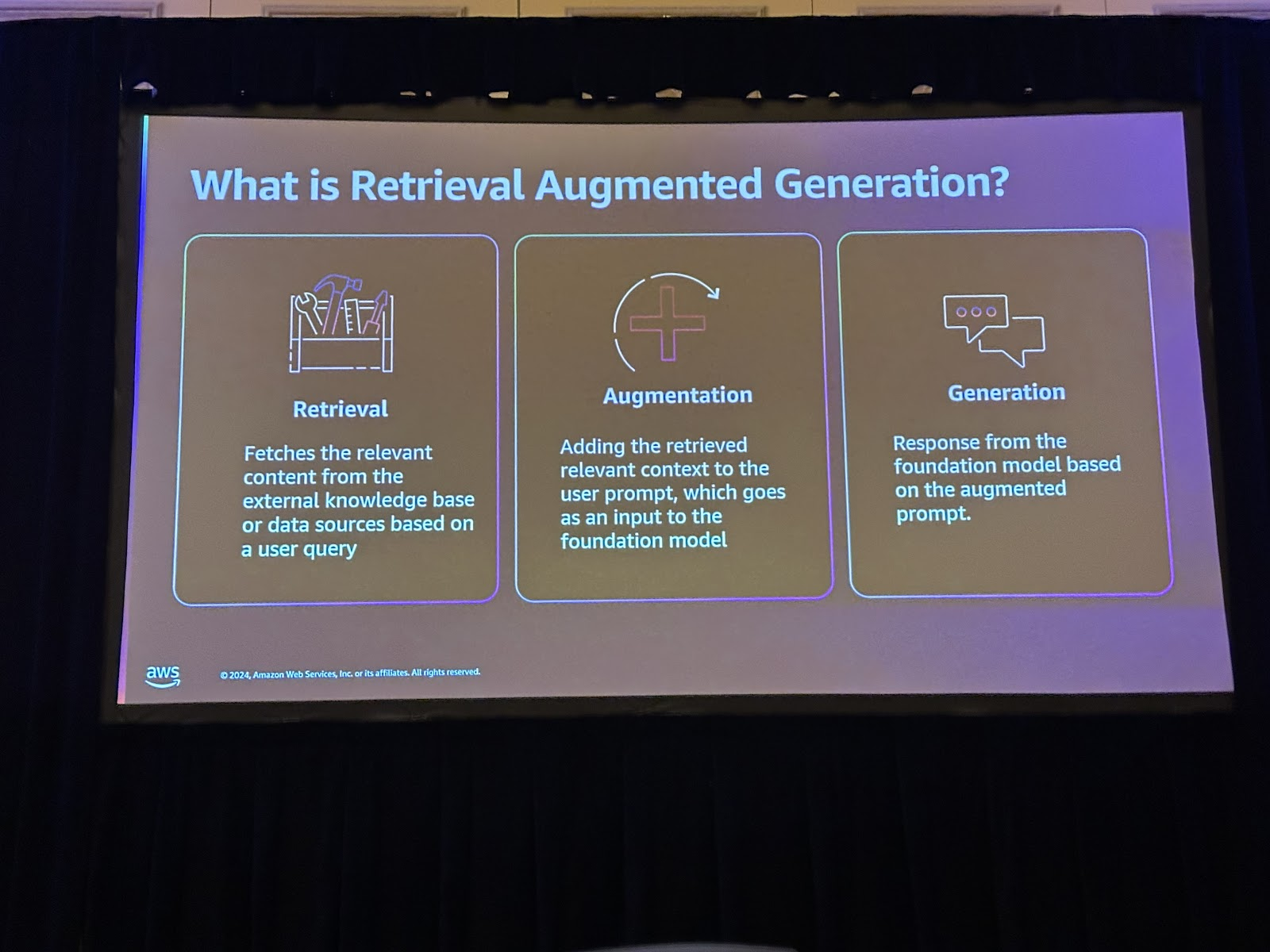
RAGとは、Retrieval Augmented Generationを使用してユーザーの入力として構成されたデータソースから関連するコンテキストを検索し、検索されたコンテキストを使用してLLM回答を生成する方法です。
RAGは次のワークフローで動作します。
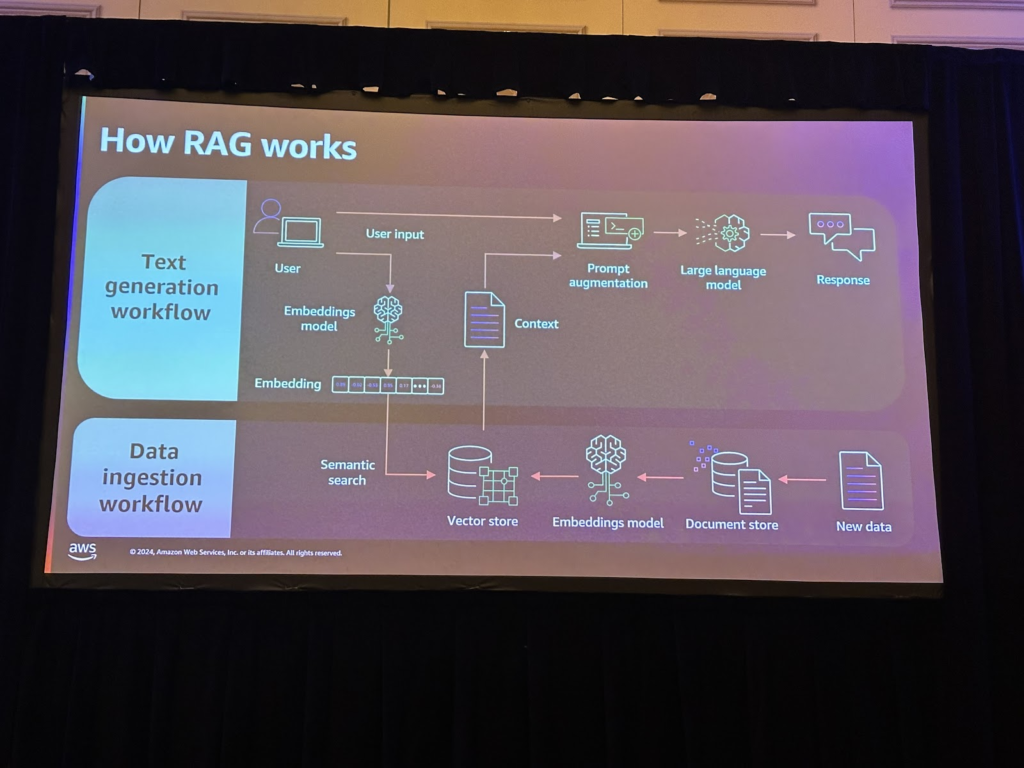
さらにRAGを構成するためには、持っている文書などのデータをベクトル化して保存する過程を経なければなりません。 Amazon Bedrock Knowledge Bases は、これらのチャンキングプロセスを実行するサービスです。ソースデータソースのS3位置と最終的にベクトル化されたデータが格納されるベクトルDBを指定しておけば、S3のデータを埋め込んで保存し、Gen AI ApplicationでRAGに使用できます。
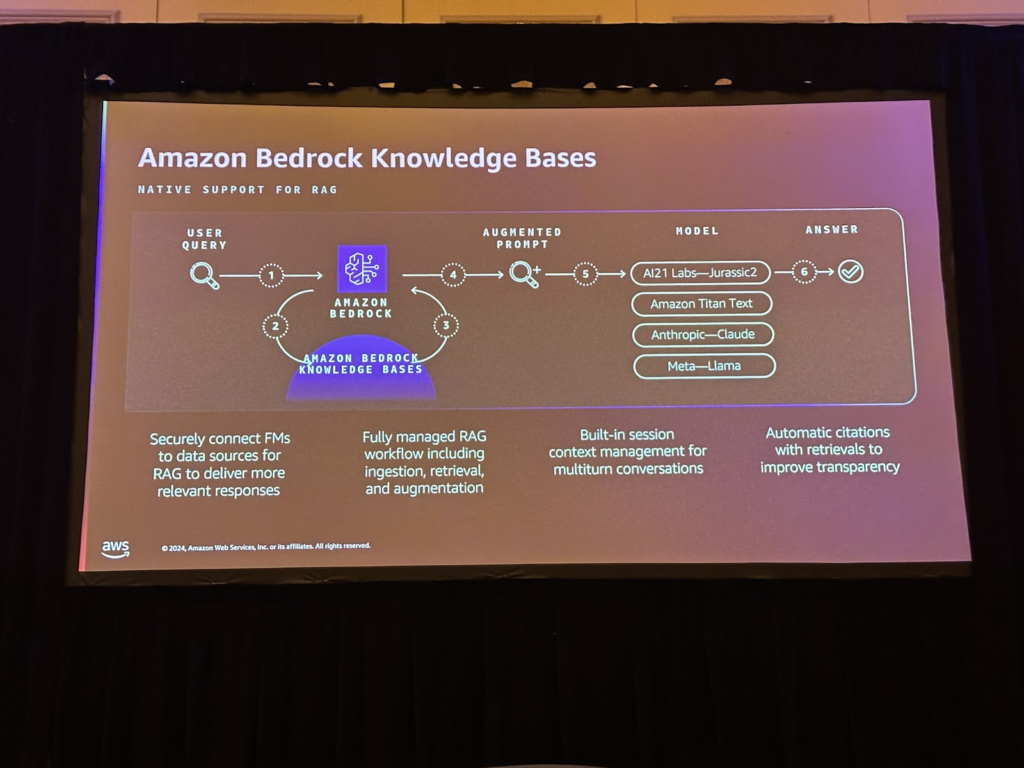
RAGベースのアプリケーションの場合、LLMによって生成された回答の精度はRAGになり、モデルに提供されるコンテキストによって大きく異なります。コンテキストはユーザーのクエリに基づいてベクトルデータベースから検索されます。検索を組み合わせたハイブリッド技術を使用すると、より良い結果が得られます。
Amazon Bedrock の新しくリリースされた機能

さらに、Amazon Bedrock は先週、次の新機能をリリースしました。
- RAG評価サポート
- RAGアプリケーションの精度を高めるためのAPIリランキング
- 検索機能を向上させるための自動生成クエリフィルタサービス
- カスタムコネクタとストリーミングデータの収集
新しくリリースされた機能を活用して、RAGの品質を向上させることができます。
ストリーミングチャット
ストリーミングを使用して出力を出力すると、答えを始める最初の単語が出る速度が一度に答えを出力するよりも速くなり、ユーザーが感じる時間が短縮されます。一般ユーザーを対象とする場合は、ストリーミングを適用するとユーザーエクスペリエンスが向上します。
次の図は、ワークショップセッションの例の1つとして、streaming形式で回答を出力するときと、回答が生成されたときに回答を出力する場合の2つの時間を測定した結果です。

まとめ
今回のセッションでは、Gen AIアプリケーションのパフォーマンスを向上させる方法についての洞察を共有しました。 Amazon BedrockのRAG評価のサポートやリランキングなどの機能は、Gen AIアプリケーションのパフォーマンスを向上させるのに役立ちます。
記事 │MEGAZONECLOUD AI & Data Analytics Center(ADC) Data Application Support Team アン・ユジン マネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び