MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #SMB302|Gen AIのためのディープディフェンスアーキテクチャーによるビジネス強化
Empower your business with defense-in-depth architecture for gen AI
セッション概要
- タイトル:Empower your business with defense-in-depth architecture for gen AI
- 日付:2024年12月5日(木)
- Venue: Wynn | Level 1 | Lafite 9
- スピーカー:
- Henrique Trevisan(Sr Solutions Architect, AWS)
- NS Sabah(Solutions Architect, AWS)
- Priyanka Sadhu(Sr. Solutions Architect, Amazon Web Services)
- John Lee(Solutions Architect, AWS)
- Archana Ambavane(Sr Solution Architect, AWS)
- 業界:Cross-Industry Solutions
- 概要:生成型AIは変革的なイノベーションを約束し、SMBがますます生成型AIアプリケーションを導入するにつれて、実用的で費用対効果の高い戦略でこれらのテクノロジーを保護することが重要です。このビルダーセッションでは、ディープディフェンスを使用してセキュリティ態勢を強化する方法を学び、信頼の限界を越えた冗長的な防御を備えたアーキテクチャをご紹介します。回復力を高めながらイノベーションを行い、安全なAWSインフラストラクチャの上に構築し、AI/ML専用のセキュリティを統合する戦略を学びましょう。ガードレール、オブザーバビリティ、責任あるAIプラクティスなど、AIベースのソリューションの安全性と整合性を確保し、生成型AIを活用しながらリスクを軽減する方法をご紹介します。
はじめに
さまざまな生成型AIを活用するケースが増えていますが、活用されるデータの管理は依然として課題となっています。LLMが私のデータを使用しているのか、またはデータが漏洩して問題が発生しないか心配ではないでしょうか? このセッションでは、このようなイノベーションと信頼のバランスを取り、心配を解決する方法について説明しました。
生成型AIのセキュリティに関する注意事項
調査によれば、多くの企業は「最近2年間生成型AIの急速な発展があったが、依然として危険因子がある」と判断しています。
- 企業は、生成型AIのData Privacy、Data Security、Hallucinations、Toxicityについて疑問を抱いています。 自社のデータをどのようにセキュリティを保つのか、幻想的な答えや 怪しい答えを生成することはないのかなどです。
- AI に関する保証と検証に関するグローバルな基準がまだないため、コンプライアンスが困難です。
- AIのリスク管理ガイドラインや規制が迅速に登場していますが、これらは従来のワークロードのガイドラインとは異なります。

ワークショップの紹介
今回のセッションはワークショップの形で行われました。

そのシナリオを実行するために使用される技術のリストとアーキテクチャは次のとおりです。
1) インフラセキュリティ
A.アクセス制御
IAMを積極的に活用して権限を管理します。
B. モニタリング
CloudTrail と CloudWatch を活用してモニタリングを強化します。
C. モデル呼び出しの数の制限 モデル呼び出しが増加するにつれて、コストが発生するという性質上、特定のユーザーが悪意を持って質問を繰り返し行うと、
問題が発生する可能性があります。
これを防ぐために、WAFを使用して短時間の呼び出し数を制限する方法を使用します。
D. プライベートネットワーキング
すべてのトラフィックを AWS バックボーン経由で設定します。

2) Bedrock セキュリティ
Bedrock Guardrail を使用して有害コンテンツブロック、プロンプトインジェクション攻撃ブロック、個人別予民情報など個人識別情報 (PII) 漏洩ブロックなど多様なセキュリティ装置を用意します。

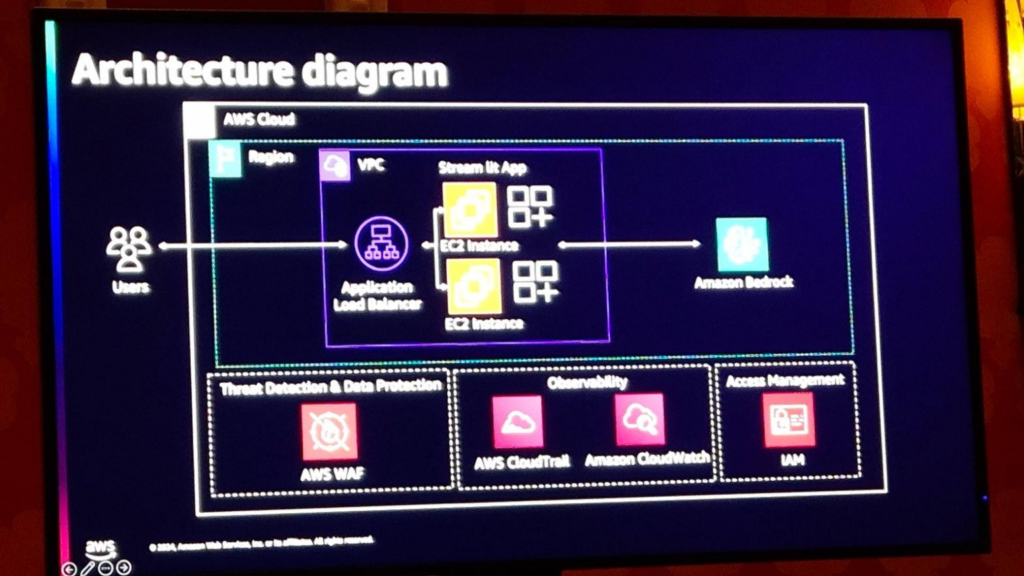
3) インフラストラクチャアーキテクチャ
ユーザがアプリケーションに接続して質問をすると、ALB(ロードバランサ)を介してEC2サーバに分散処理されます。この過程で、WAFによる通話回数の制限、監視、アクセス制御が活用され、最終的にBedrockでGuardrailなどの安全装置を経て最終的な回答を生成します。
ワークショップ
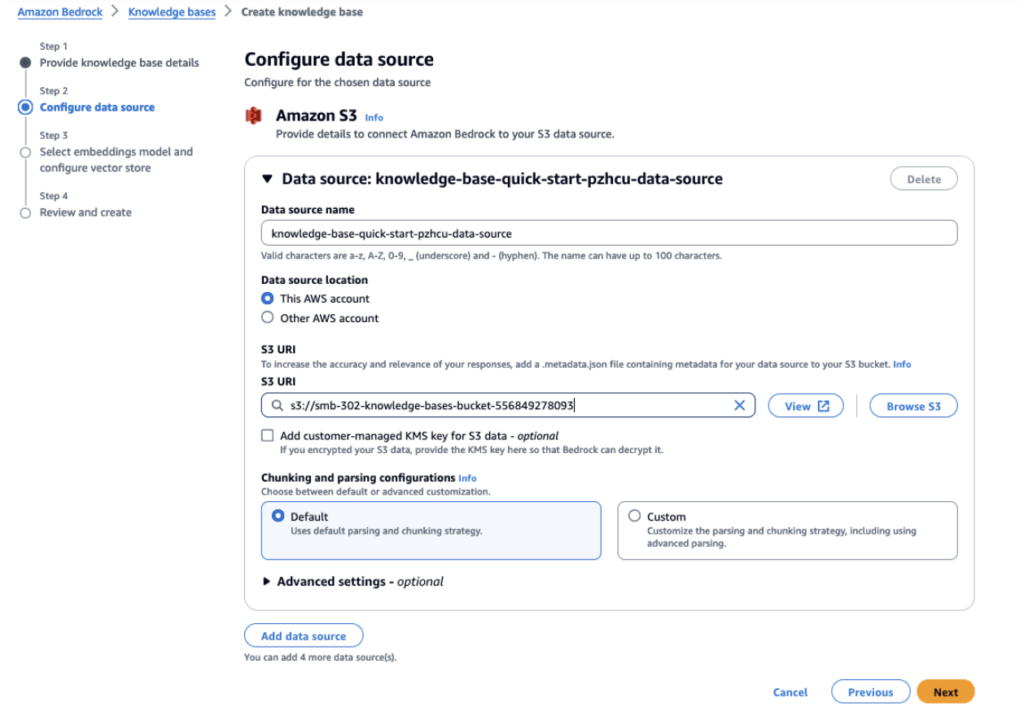
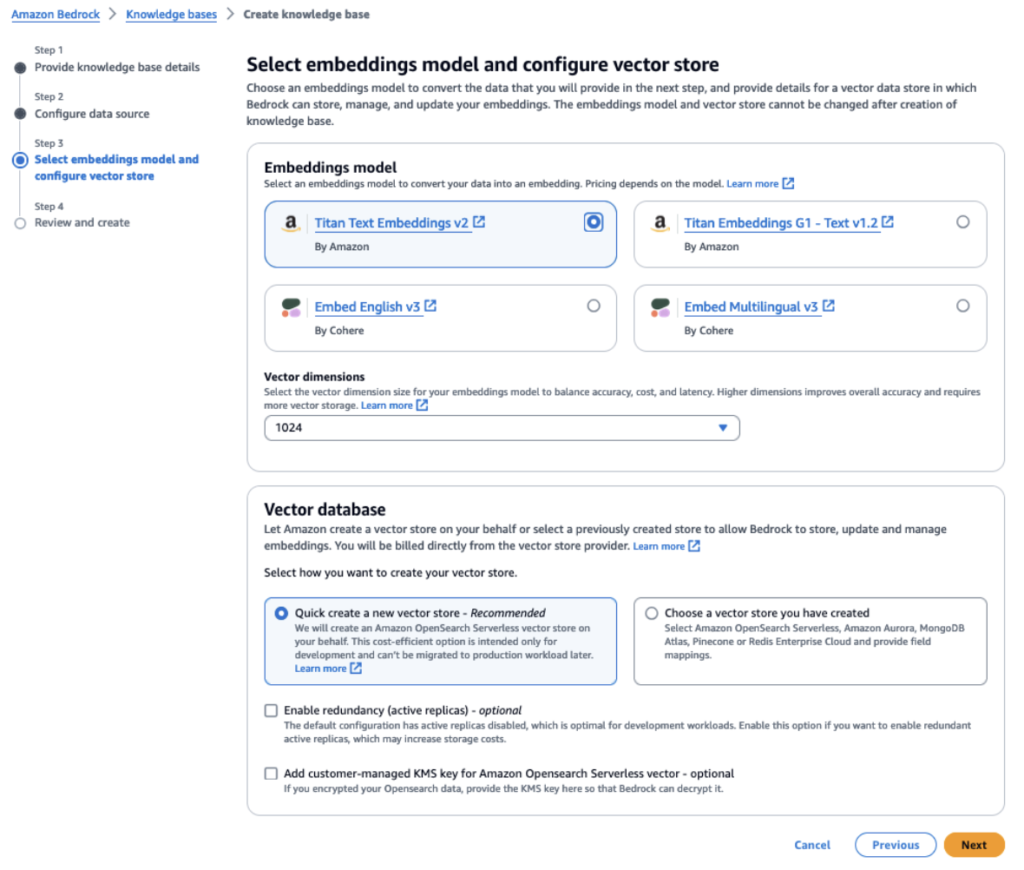
1.回答の作成時にRAGに必要なデータをソースとして指定してBedrock Knowledge Baseを作成します。全体のプロセスで使用される埋め込みモデルは同じでなければならず、このプロセスではTitan Text Embeddings v2を使用します。
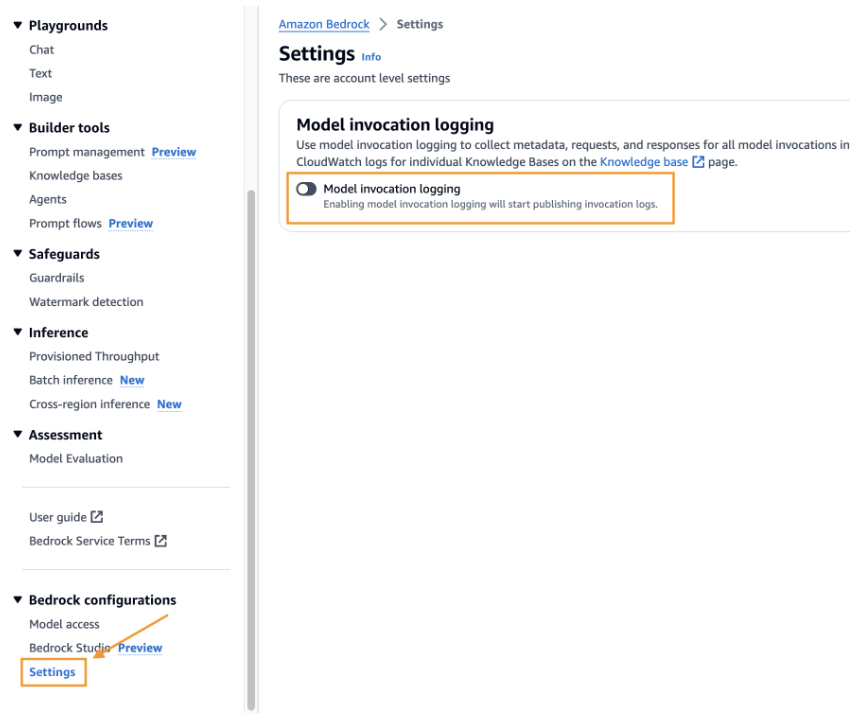
2. 使用状況およびその他のモニタリングのためにデフォルトで無効になっている Bedrock モデル呼び出しロギングをイネーブルにします。 CloudWatch Log Onlyを選択します。
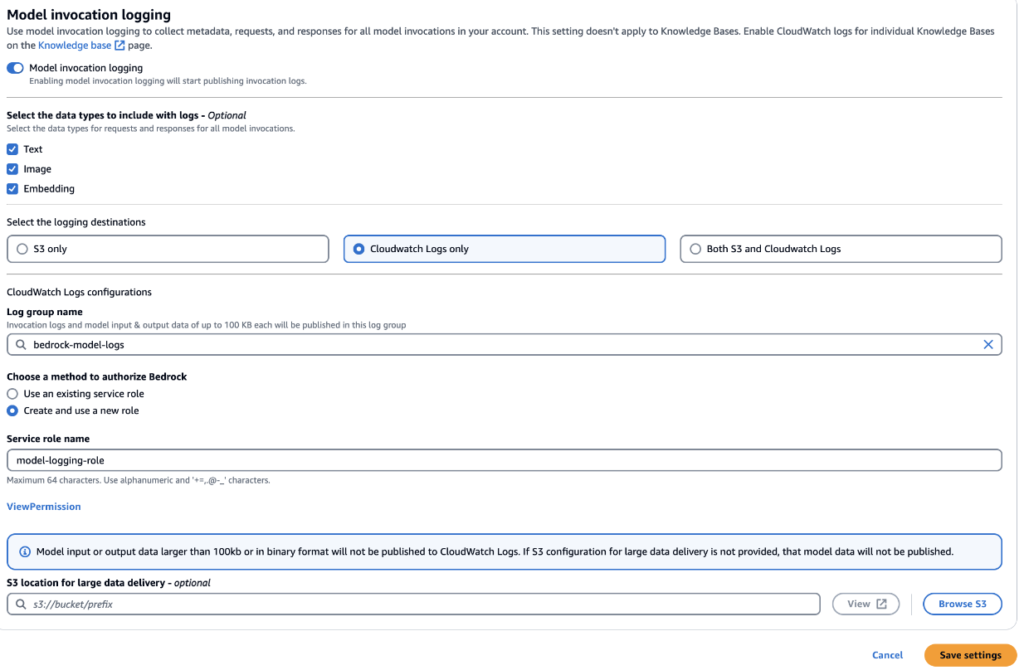
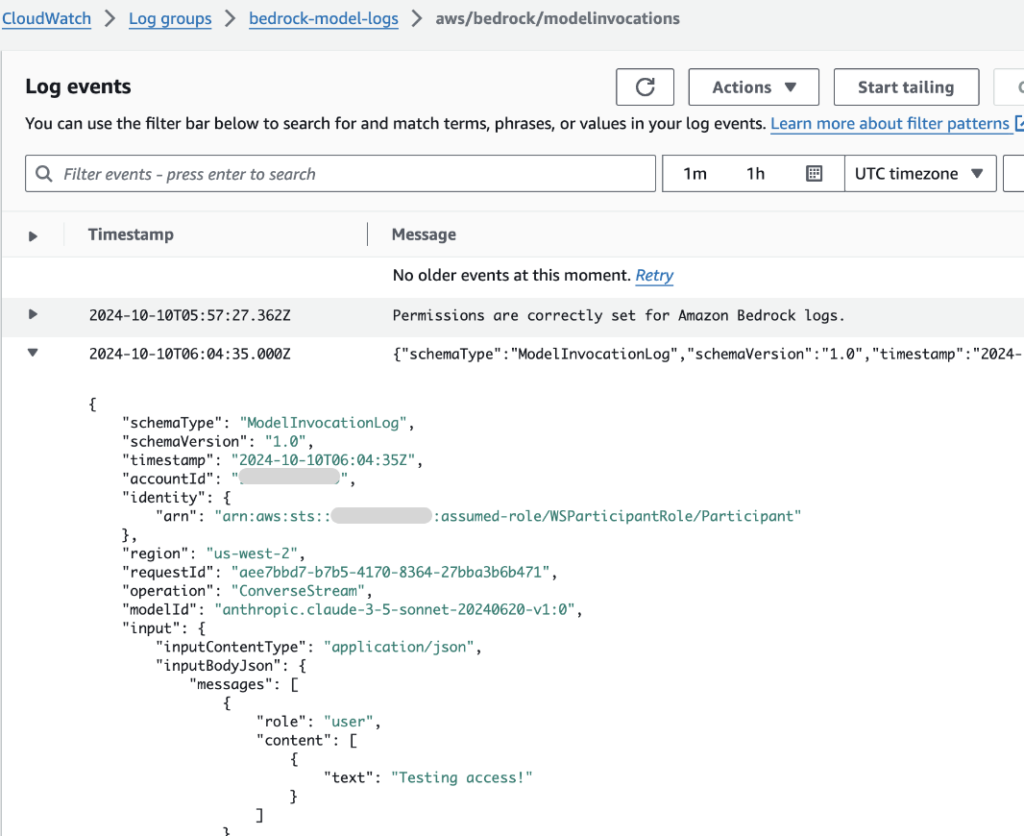
これで、直前に設定したLog group名でBedrackモデルの呼び出しログを確認できます。
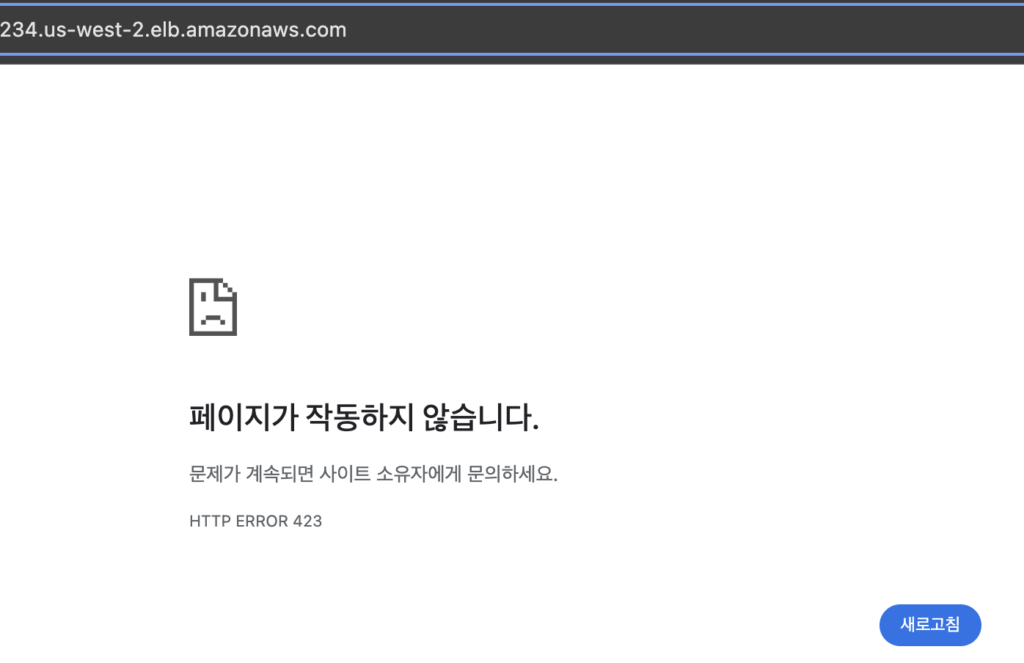
3. WAFを設定します。 Rate-based ruleに設定し、1分あたり10回の制限に設定します。そのルールを適用した場合、1分あたりの制限を超えると、次のように接続がブロックされます。時間が経つと、ブロックは解除されます。
まとめ
今回のセッションでは、生成型AIアプリケーションでさまざまなセキュリティ脅威に対処する方法を学びました。生成型AI関連PoCやプロジェクト業務を進行する場合、常に最も優先的に考えられる重要な部分がセキュリティまたは安全性に関する部分でした。ガードレールによる有害なコンテンツのブロックがサポートされていないときは、プロンプトやその他の方法で特定のケースがある場合は、回答を生成しないか、プロセスを中断する方法を使用する必要がありました。この他にも、大客プロダクション段階の業務を進行する場合、有害コンテンツの遮断に加えてシステムを異常に利用する場合に対する対応も必要でした。このような場合、先に紹介したBedrock GuardrailとWAFを活用したトラフィック制御などの方法を活用して、伝統的なセキュリティ方法と生成型AIに特化した戦略を併せて適用すれば、イノベーションと信頼のバランスをとり、インサイトの発掘に大きく役立つと考えるします。
記事 │MEGAZONECLOUD AI & Data Analytics Center (ADC) Data Engineering 2 Team チョン・ジソン マネージャー
チョン・ジソン マネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び