MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #SMB401|Amazon Bedrock、LangChain、RAGASを使用したRAGパイプラインの高度化
Evaluate your RAG pipeline with Amazon Bedrock, LangChain, and Ragas
セッション概要
- タイトル:Evaluate your RAG pipeline with Amazon Bedrock, LangChain, and Ragas
- 日付:2024年12月4日(水)
- Venue:MGM Grand | Level 1 | Terrace 151
- スピーカー:
- Justin McGinnity(Solutions Architect, AWS)
- Francesco Cerizzi(Solutions Architect, Amazon Web Services)
- Deepthi Paruchuri(Sr.Solutions Architect, Amazon Web Services (AWS))
- Alfredo Castillo(Sr Solutions Architect, AWS)
- Ozan Talu(Sr Manager, Solutions Architecture, AWS)
- 業界:Cross-Industry Solutions
- 概要:Amazon Bedrock、langchain、RAGASを使用してレスポンスとRAGパイプラインのパフォーマンスを評価する方法に関するワークショップセッション。 RAGとLLMの精度、安定性などの性能を測定する方法を共有します。
はじめに
このセッションでは、Amazon Bedrock、Langchain、RAGASを活用してRAGパイプラインを高度化する方法に関するワークショップを実施しました。 RAGを使用してGen AIアプリケーションを構成するときに発生する可能性のある問題と、RAGASを活用してそのような問題の原因を解決する方法を共有します。
RAGを活用したGen AIアプリケーションの失敗要因
RAGを使用してコンテキストを検索して使用するGen AIアプリケーションを構成するときに発生する一般的な障害要因は、次のようになります。
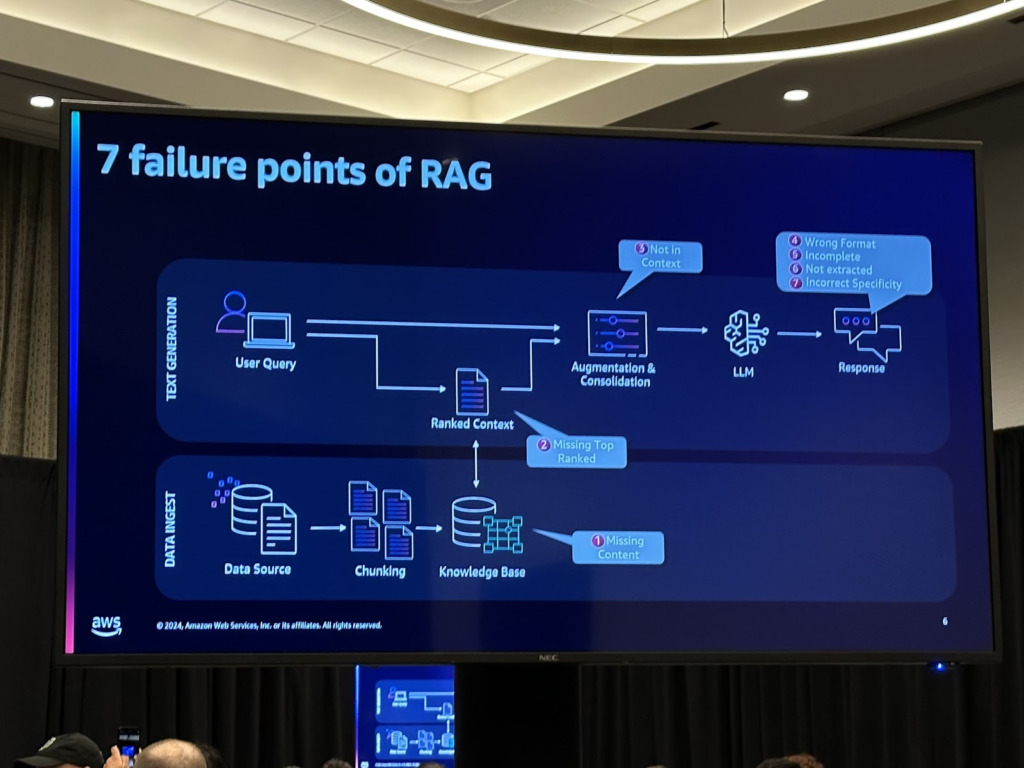
RAGパイプラインのプロセスごとに発生する可能性がある問題は異なりますが、主にコンテキスト検索がうまくいかない場合、LLMを介して生成された最終回答が適切でない場合は2つに分けられます。
その中でも、コンテキスト検索がうまくいかない場合は、問題の原因が埋め込みがうまくいかなかったときとチャンキングがうまくいかなかったときの2つに分けることができます。今回のワークショップでは、これら3つの問題の状況にRAGASを活用して、複数のモデル、複数の案を比較分析する方法を共有しました。

RAGASを活用した埋め込みモデルの比較
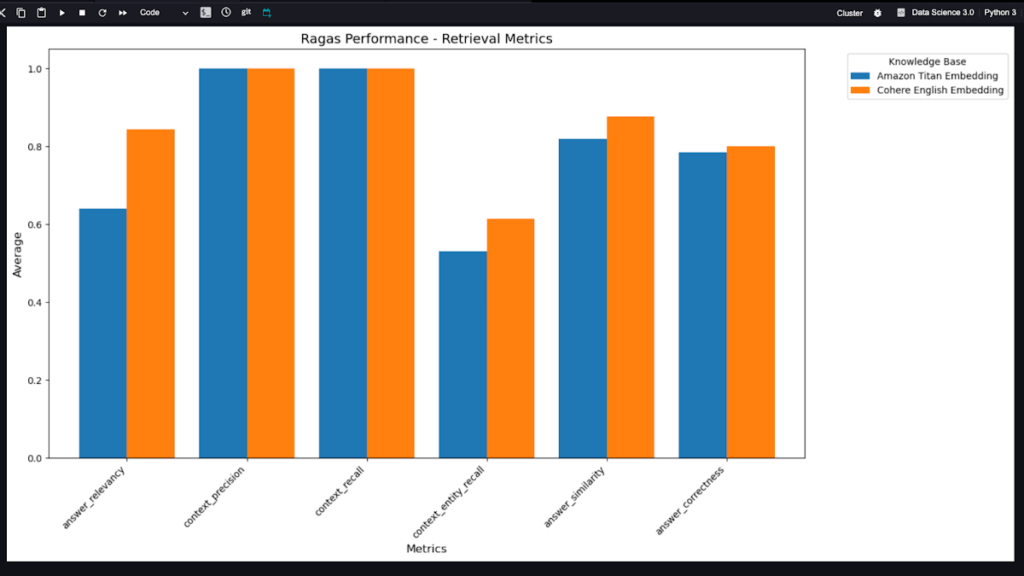
RAGを使用するには、埋め込みモデルを使用して文書をベクトル化し、ベクトルデータベースに保存する必要があります。ここで埋め込みモデルによってベクトル化される性能が異なりますが、RAGASを活用して各埋め込みモデルごとにどのモデルがどの部分でより性能が良いかについての比較ができます。
ワークショップでは、Amazon Titan EmbeddingモデルとCohere Endlish Embeddingモデルを使用し、Answer relevance、context precision、context reall、context entity recall、answer similarity、answer correctness基準を使用して比較を行います。
2つの埋め込みモデルを比較したグラフは次のとおりです。
RAGASを活用したチャンキング戦略の比較
文書をチャンキングする方法にはさまざまなものがあり、状況によってはどのようなチャンキング方法を使用するのが良いかが異なります。文書をチャンキングする方法はRAGのパフォーマンスに大きな影響を与えますが、チャンクのサイズによっては、チャンクの内容が段落単位であるのか、文単位であるかに応じて、チャンキングの重複をどれだけ許可するかによって結果が大きく異なる場合がありますあります。
RAGASを活用して質問と期待する答え(ground truth)を使って異なるチャンキング戦略を使用した場合、どのように結果が変わるのか、その結果がanswer relevancy、context precision、context entity recall、answer correctnessという指標で評価したときは各指標にどれだけ満足しているかを評価できます。
ワークショップでは、Hierarchical、Semantic、Fixedの3つの方法の指標を比較しました。
Hierarchicalチャンキング方式は、文書を階層構造に分割する方法で、文書>セクション>段落>文のように文書を階層的に細分化します。一般に、検索された情報の一貫性は高いが階層構造を設計することは困難であり、検索範囲が広がるほどパフォーマンスが低下する。セマンティックチャンキングは、意味的にリンクされたコンテンツに基づいてチャンキングを行う方法であり、検索された情報がユーザーのクエリと関連が高いことをもたらし、精度は高いかもしれませんが、チャンクのサイズが一定ではないという欠点があります。固定チャンクは、定められた一定のサイズにチャンキングする方法で検索が高速ですが、指定されたサイズにチャンキングされ、コンテキストが途切れたり消えたりする可能性があるという欠点があります。
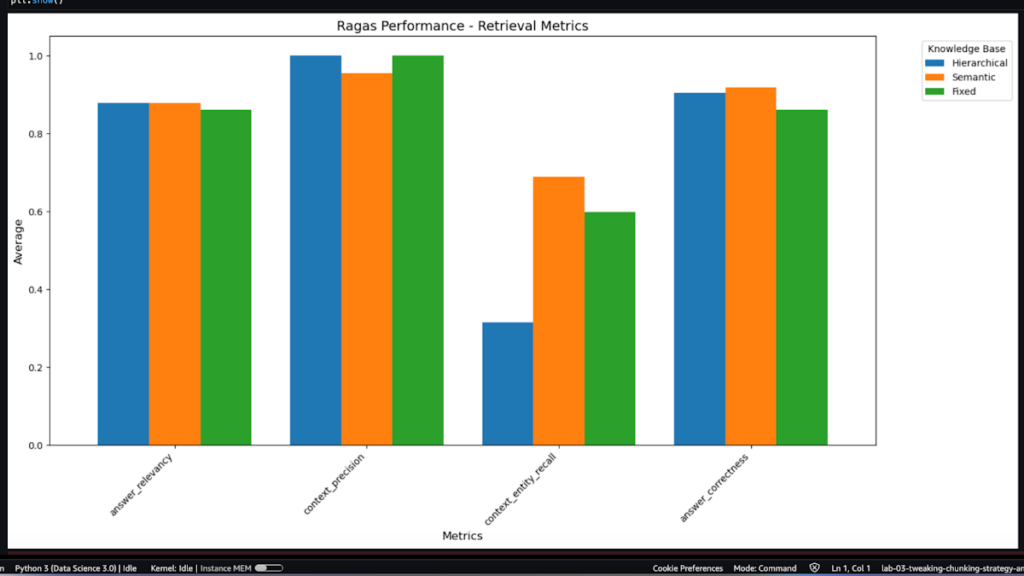
上の表を見てみると、Hierarchicalチャンキングの場合、コンテキスト内のエンティティを正確に見つける能力(context_entity_recall)が著しく低いが、その他のanswer_relevancy(回答関連性)、Context_precision(文脈の精度)、answer_correctness(回答の正確性)少しずつ高いですできます。
RAGASを活用したLLMモデルの比較
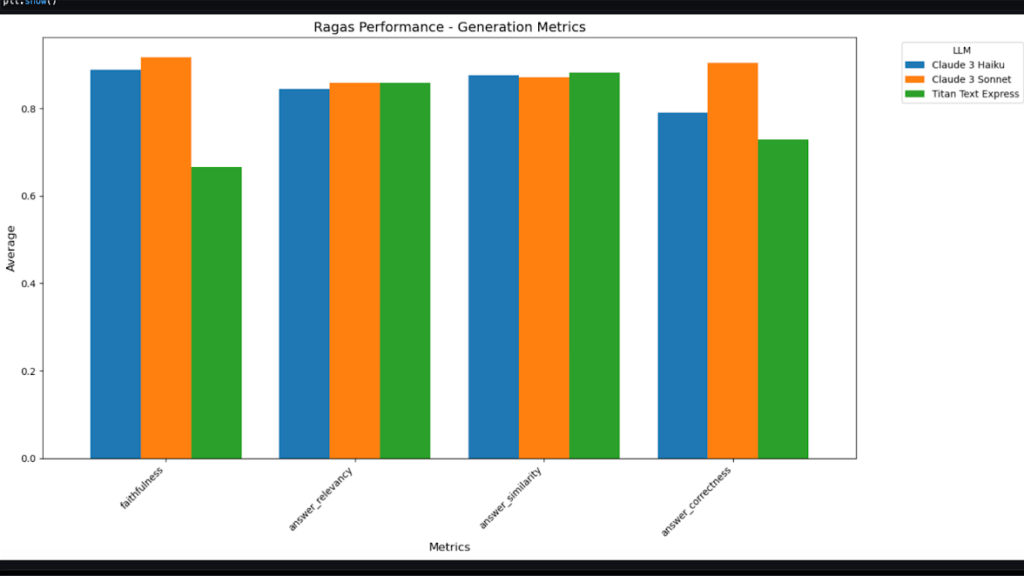
最終的に答えを生成するLLMモデルのパフォーマンスによっても、結果の値が大きく異なる場合があります。 RAGAS で質問に期待する回答をまとめると、比較したいモデルごとに、faithfulness、answer relevancy、answer similarity、answer correctness の一部が ground truth 回答と比較したときにどれだけ満たされているかを指標として確認できます.
ワークショップでは、Claude 3 Haiku、Claude 3 SonnetとTitan Text Empressの3つのモデルを比較し、これを比較したグラフは次のとおりです。
まとめ
今回のセッションでは、RAGを使用するGen AIアプリケーションで発生する可能性のある問題と、そのような問題を解決するための方法、考慮すべき事項を比較する方法について説明しました。特に、RAGを活用したGen AIアプリケーションで発生する可能性のある障害要因と問題点を診断し、これを解決するためにRAGASを活用した埋め込みモデル、チャンキング戦略、LLMモデル比較分析方法を共有しました。セッションを進めて参加者が進めてみた様々なプロジェクトの事例を通じて、業界によって重要に見える部分が異なることを共有できる時間でした。
記事 │MEGAZONECLOUD AI&Data Analytics Center(ADC) Data Application Support Team オム・ユジンマネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び