MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #SVS304|サーバーレスコンテナとRAGを活用した生成型AIの機能拡張
Extend generative AI capabilities with serverless containers and RAG
セッション概要
- タイトル:Extend generative AI capabilities with serverless containers and RAG
- 日付:2024年12月2日(月)
- Venue:Caesars Forum |レベル1 |サミット232 | Content Hub | Builder’s 2
- スピーカー:
- YoungJoon Jeong(Sr. Container Specialist SA、AWS)
- Doruk Ozturk (Senior Solutions Architect, AWS)
- Jooyoung Kim (Senior Containers Specialist Solutions Architect, AWS)
- Jungseob Shin(Solutions Architect、AWS)
- Chance Lee (sr. container specialist solutions architect, AWS)
- 業種:Cross-Industry Solutions
- 概要:Amazon ECS と AWS Fargate、Retrieval Augmented Generation (RAG)、Opensearch Serverless を使用して、サーバーレス環境にコンテナベースのジェネリック AI アプリケーションを構築する方法、および考慮すべき事項、ベストプラクティスをご覧ください。
はじめに
今回のセッションでは、サーバーレスインフラだけを活用してGen AIアプリケーションをデプロイし、RAGを通じてLLMの性能を強化する実習を進めました。 Gen AIアプリケーションを完全なサーバーレス環境にデプロイする際のインフラストラクチャーの構成とともに、サーバーレスの特徴がGen AIに組み込まれた場合、どのような利点があるかをお届けします。
RAGの概念と実施方法
お客様は、Gen AIを導入する前に、次のプロセスを経ています。まず、use caseを定義し、Gen AIアプリケーションが既存のサービスよりも価値があるのか、投資に十分な価値を提供するのかを判断します。また、どのモデルが適切か、どの環境が適切か、セキュリティが必要なデータはどのように使用するかなどを考慮します。
このセッションでは、これらの顧客の要件を解決するための実用的な方法としてRAG(Retrieval Augmented Generation)を提案します。
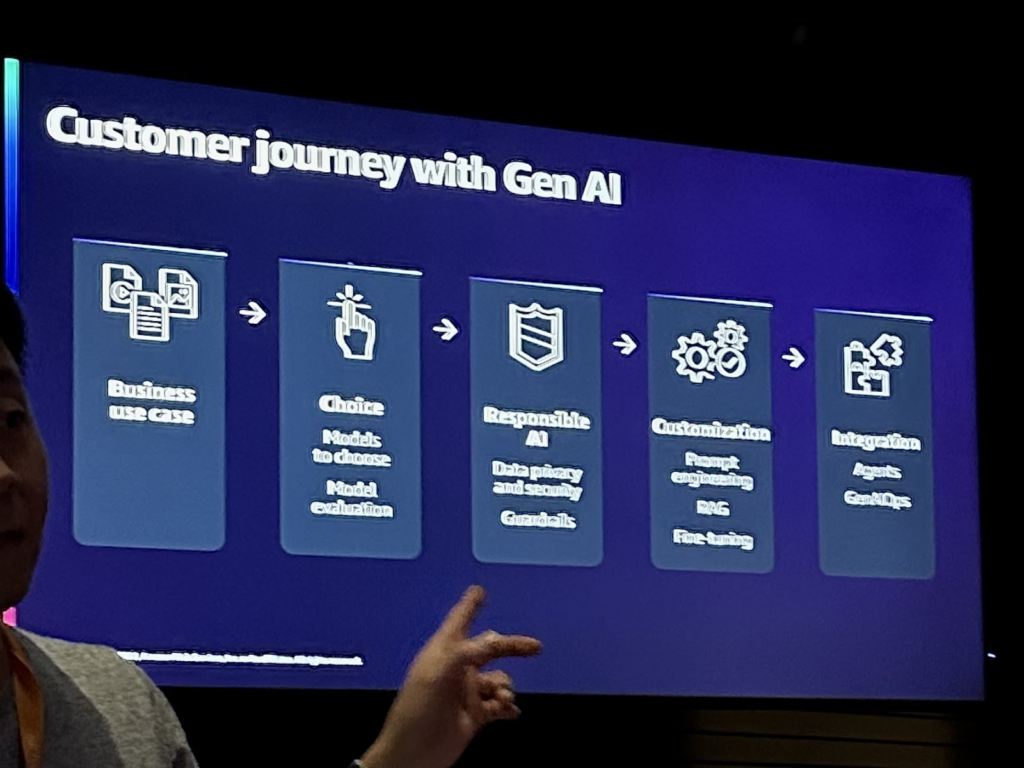
RAGは、LLMを再学習せず、fine tuningせずに最新のデータソースを活用して柔軟性を高め、モデルの偏りを最小限に抑えることができます。
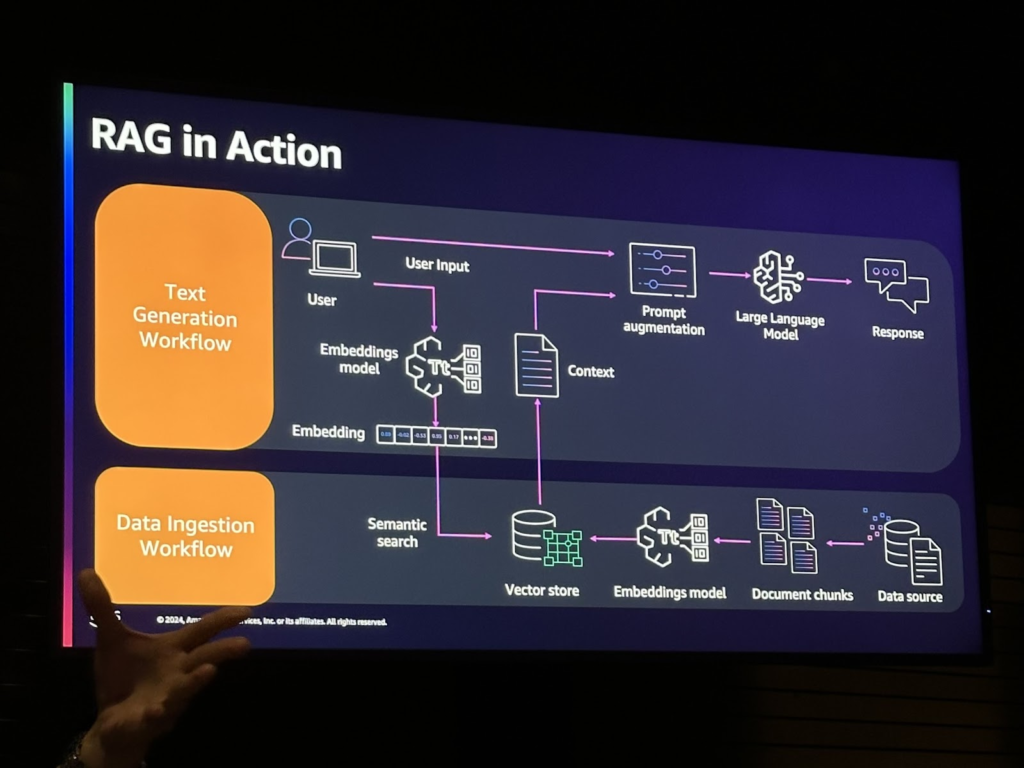
次の画像はRAGを実行するプロセスのワークフローです。データソースを埋め込みベクトルストアに保存すると、ユーザーの入力があるときにセマンティックサーチを介してコンテキストを検索できます。検索されたコンテキストとLLMを使用すると、ユーザーの意図に応じた回答を提供できます。
コンテナベースの展開
コンテナはアプリケーションを独立してパッケージ化して実行でき、スケーリングなどを適用するのに役立ち、AWSではAmazon ECSを使用して効率的に管理できます。また、サーバーレス環境はインフラストラクチャの管理を最小限に抑え、自動化を可能にするという利点があります。したがって、サーバーレスとコンテナベースのデプロイ方法をGen AIアプリケーションに適用する際に、それぞれの強みを使用して迅速かつ効率的なデプロイが可能です。
Fargateを活用したサーバーレスGen AIアーキテクチャ
サーバーレス環境は、迅速かつ簡単に展開できるという利点があります。この利点をGen AI展開に適用すると、より革新的な機能をより迅速に展開でき、管理の負担を軽減できます。

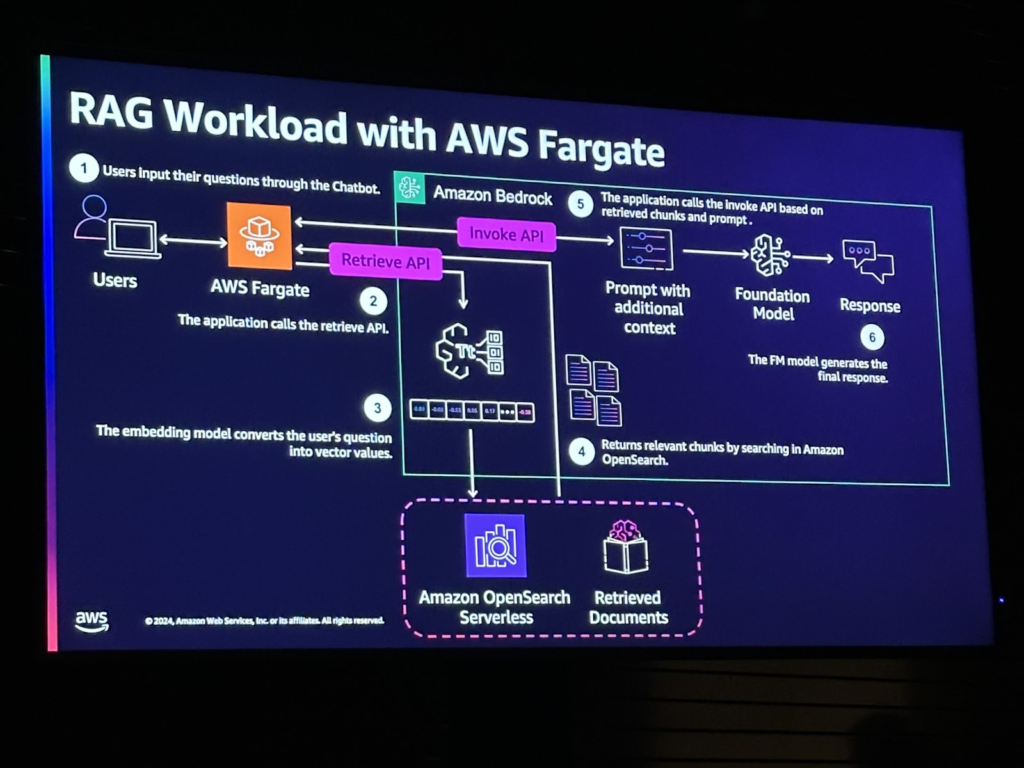
AWS Fargate を使用した RAG のワークロードは、次のイメージのようになります。 RAGデータは、Amazon BedrockのKnowledge Baseを利用して、前述のRAGのデータソースを埋め込み、Opensearch Serverlessサービスに保存します。保存されたベクトルデータは、ユーザーの入力が入るたびにRetrieve APIを使用してコンテキストを取得できます。
全体的なフローは次のとおりです。ユーザーが質問をしてAWS Fargateを介してAPIを呼び出すと、そのユーザーの質問を使用してRetrieve APIを使用して関連RAGデータを取得します。そして、検索されたデータとユーザーの質問、システムプロンプトを一緒にFoundationモデルに入れて、受け取った最終回答をユーザーに伝えます。
まとめ
このセッションでは、完全なサーバーレス環境でGen AIを構築する方法とともに、そのような環境を構築することの利点について学びました。 Gen AIなどのアプリケーションは、効率的なリソース管理とスケーラビリティが重要であり、コンテナベースとサーバーレス環境を使用すると、より柔軟に展開および管理できるという洞察を得ることができました。
コンテナベースのGen AIアプリケーションだけでなく、完全にサーバーレス形式でAWS Fargateを使用してデプロイするアーキテクチャについて直接実践してみることができ、以後、コスト効率などの理由でサーバーレス環境を使用するようになった場合、このアーキテクチャを適用してみることができるそうです。
独自のモデルを構築する企業が増えるにつれて、モデルトレーニングのための正しいデータ処理の重要性が日々高まっている状況で、MWAAによるデータオーケストレーションの自動化を活用すると、ビジネスに大きな利点があると期待されます。
記事 │MEGAZONECLOUD, AI&Data Analytics Center(ADC)、Data Application Support Team、オム・ユジンマネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び