MEGAZONEブログ

Building next-generation sustainability workloads with open data
オープンデータによる次世代サステナビリティ・ワークロードの構築
Pulisher : Cloud Technology Center キム・ジホ
Description : Open Data on AWSを活用し、イノベーションを加速する方法を3つ紹介しています
はじめに
このセッションは、AWSのお客様がOpen Data on AWSを活用してイノベーションを加速する方法を学び、AWSのさまざまなサービスを活用してクラウドで持続可能な作業を構築する方法を学ぶために選ばれました。
セッションの概要紹介
未来の持続可能なデジタル技術はデータによって推進されますが、持続可能性データセットへのアクセスが難しいという問題を、Open Data on AWSのようなプログラムが解決しています。本セッションでは、AWSの顧客がクラウド上で持続可能な作業を構築するためにオープンデータとAWSのさまざまなサービスをどのように活用しているか、また、Natural History Museum Planetary Knowledge Baseによる世界的な生物多様性の変化に関する研究ツールについて説明します。
本セッションの内容は以下の通りです。

1.持続可能性とオープンデータ
オープンデータの重要性とサステナビリティについて説明します。
2.惑星の知識ベースへの道 – NHMのデータデジタル化の道のり
Natural History Museum (NHM)が実施したデータデジタル化プロセスの旅を紹介します。NHMがどのように情報を収集し、デジタル化するかについて説明します。
3.技術探検:惑星の知識ベース(ナレッジグラフ)
ナレッジグラフの技術的な詳細が取り上げられ、どのように構築され、活用されるのかについて説明します。

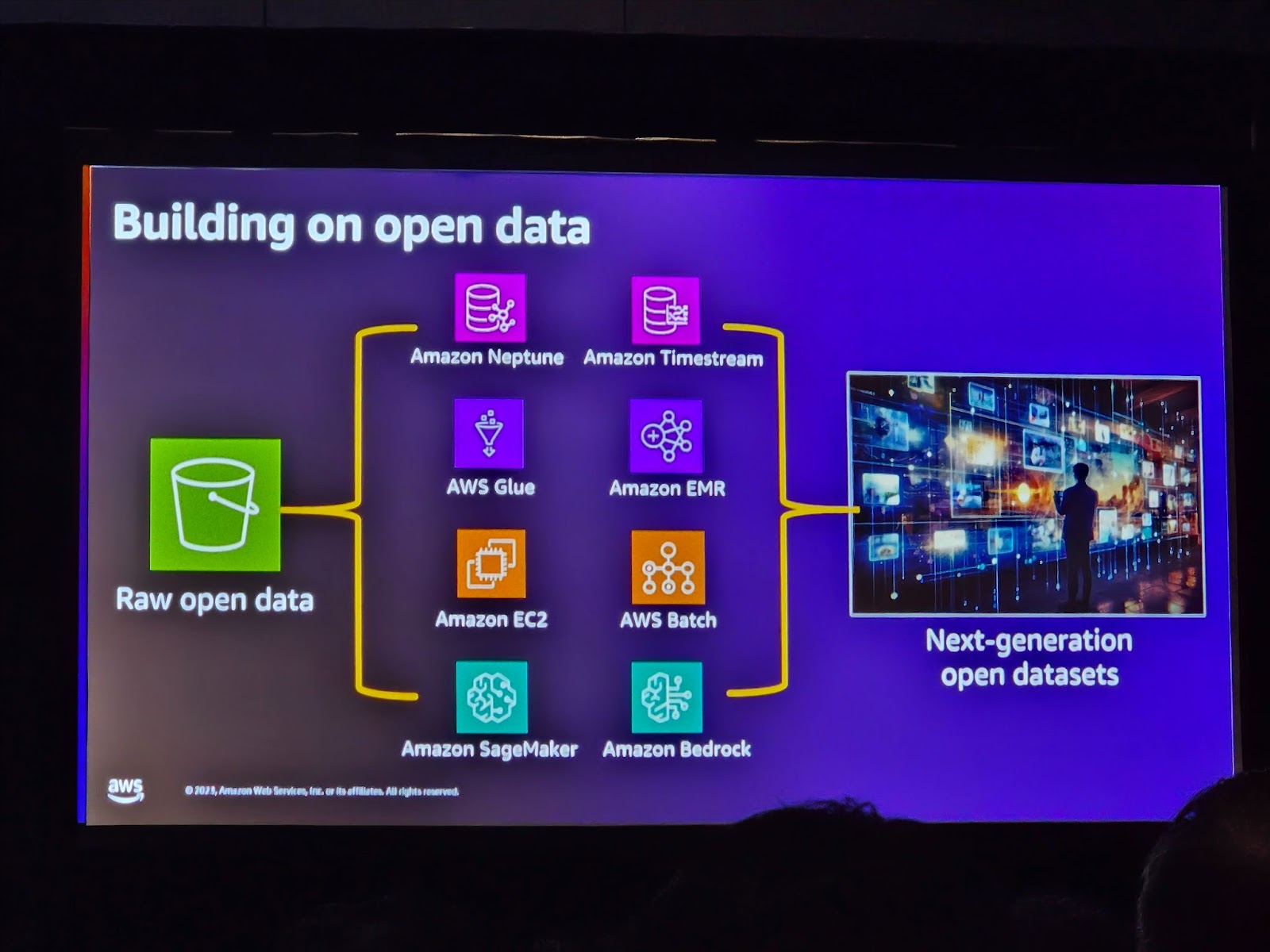
持続可能性の課題を解決するには、データが必要です。このプロセスには、データの検索、データの支払い、データの共有、そして十分なストレージとコンピューティング能力が必要です。 つまり、持続可能なソリューションを開発・実装するためには、さまざまなデータ関連の課題を解決することが不可欠です。

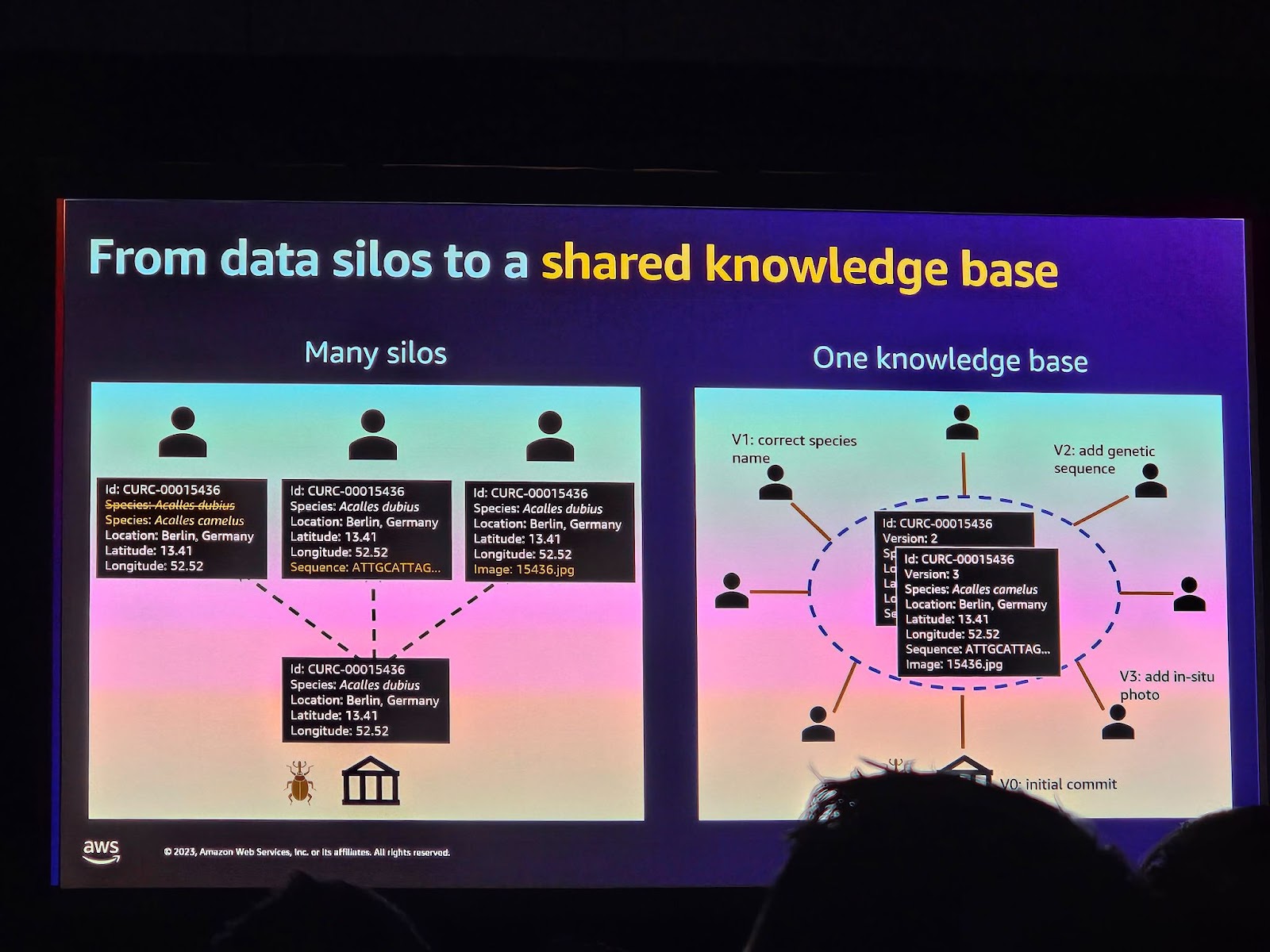
上の画像は、データサイロから共有知識ベースへの進化過程を示しています。初期には複数のデータサイロが存在し、それぞれのバージョン(V1、V2、V3)が個別の情報を持っています。例えば、CURC-00015436は初期にはAcalles dubiusとして記録されていましたが、V2ではAcalles camelusに修正されました。 また、遺伝子配列や位置情報、画像などもバージョンによって追加または修正されました。
これらの変化は、共有知識ベースへの進化を表しており、各バージョンにはより多くの情報が統合され、更新され、精度と品質が向上しています。最後に、”initial commit”を通じて、新しい情報が初めて追加されたことを確認することができます。このようなプロセスは、データの進歩と共有知識の増加を視覚的に表しています。

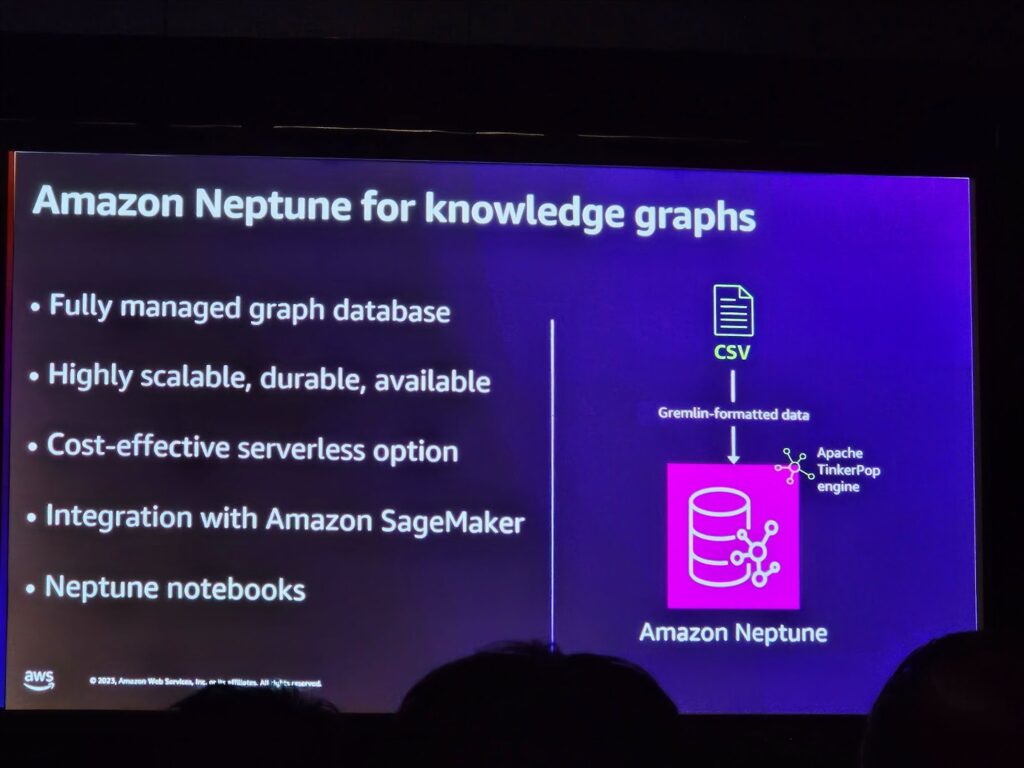
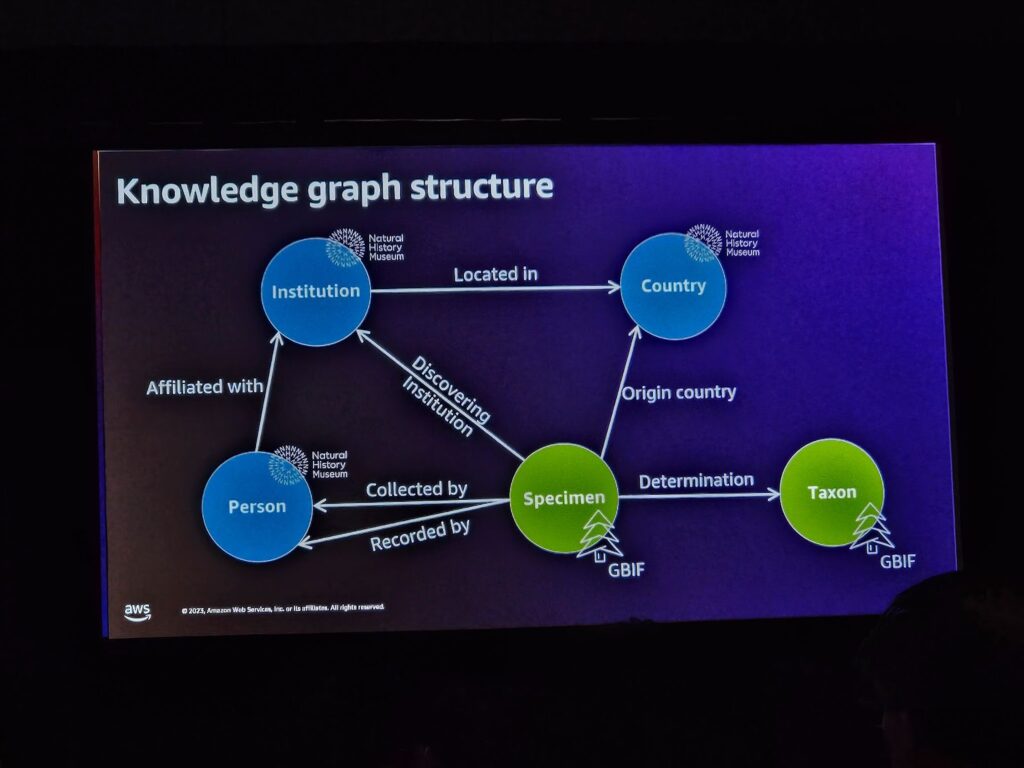
Amazon Neptuneを活用した知識グラフ。
・マネージドグラフデータベース: Amazon Neptuneは完全に管理されたグラフデータベースで、ユーザーがデータベースインフラストラクチャを管理することなく、グラフデータを効果的に保存し、クエリすることができます。
・高性能と耐久性:高いスケーラビリティ、耐久性、可用性を提供し、大規模なグラフデータセットを処理することができます。
・費用対効果の高いサーバーレスオプション:Amazon Neptuneは費用対効果の高いサーバーレスオプションを提供し、必要に応じて拡張可能なリソースを使用しながらコストを最適化することができます。
・CSV形式とGremlin形式のデータ: NeptuneはCSV形式とGremlin形式のデータをサポートし、柔軟なデータロードとクエリの実行を可能にします。
・Apache TinkerPopエンジン: TinkerPopエンジンをベースにして、グラフのクエリと操作をサポートします。
・Amazon SageMaker Neptuneノートブック統合:Amazon NeptuneはAmazon SageMaker Neptuneノートブックを統合し、機械学習モデルとグラフデータ間の統合を容易にします。
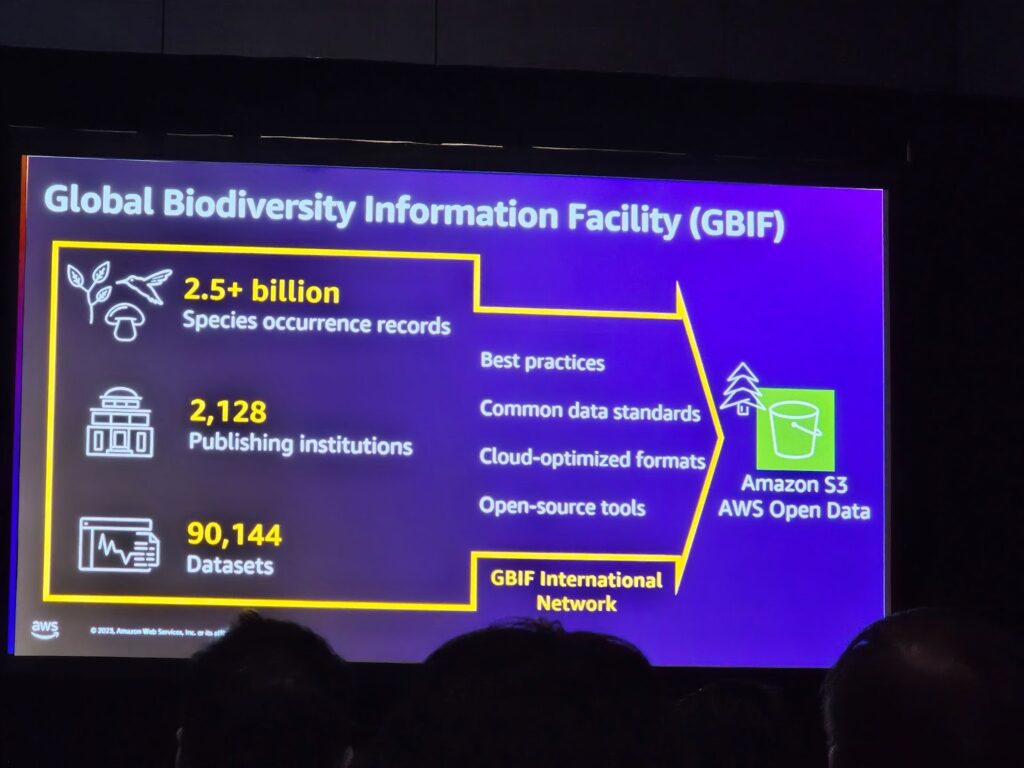
グローバル生物多様性情報施設(GBIF)
・25億件以上の種発生記録:GBIFは2.5億件以上の種発生記録を保有しており、生物多様性に関する幅広い情報を提供しています。
・2,128の発行機関:GBIFは2,128以上の発行機関と協力し、さまざまなソースから収集されたデータを統合しています。
・共通のデータ標準とクラウドに最適化されたフォーマット:GBIFは、データの一貫性と効率的な処理をサポートするために、共通のデータ標準とクラウドに最適化されたフォーマットを採用しています。
・90,144個のデータセット:90,144個の多様なデータセットを保有しており、生物多様性に関連する様々なテーマを扱っています。
・オープンソースツール及びAWS Open Dataの活用:GBIFはオープンソースツールを活用してデータを管理し、Amazon S3などのAWS Open Dataを通じてデータの公開とアクセシビリティを強化しています。
・GBIF国際ネットワークへの参加:GBIFは国際的なネットワークに参加し、生物多様性情報の国際標準化及び共有に貢献しています。
セッションを終えて
サステナビリティデータセットへのアクセスの制限と高いコストは、ビルダーにとって大きな課題ですが、AWSのオープンデータを活用することで、これらの課題を克服する方法を学びました。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner