MEGAZONEブログ

Curate your data at scale
大規模なデータのキュレーション
Pulisher : AI & Data Analytics Center チェ・スンヒョン
Description:収集したデータをどのように収集、活用、保管、管理するのか、Data Curationの重要性と事例を紹介するセッション
はじめに
先に聞いたSTG313(Building and optimizing a data lake on Amazon S3)セッションでは、大規模なデータをS3にどのように効果的に保存するかを受講した後、そのデータを整理して管理する方法を一緒に聞けば、収集、処理、整理の観点が整理できそうなので、そのセッションを申し込みました。
セッションの概要紹介
収集したデータをどのように収集、活用、保管、管理するのか、Data Curationの重要性と事例を話してくれたセッションでした。

多くの企業がData Curationが難しいのは大きく3つの理由があります。
Challenge1 : your data is siloed
データのサイロ化により、ドメイン間のデータ活用及び分析に困難があります。
Challenge2 : ETL is hard
データパイプラインを作成し、接続し、収集することに難しさを感じ、継続的にモニタリングをしなければならないことに難しさを感じています。
Challenge3 : Data governance is complicated
データの量が増えるたびに、メタデータの量も一緒に増えるため、継続的にガバナンスを取るのに苦労しています。
How to Think out data curate?

・クローラー/カタログを活用してメタデータを管理し、カタログ化して使用することができ、カタログでメタデータを確認して見ることができます。
・データにマーカーを付けて管理し、自動化することができます(DataZoneでサポート)。
・データガバナンス、アクセス制御のためにlake formationを確認することができます。
Choose a simple architecture and evolve Choose a simple architecture and evolve.
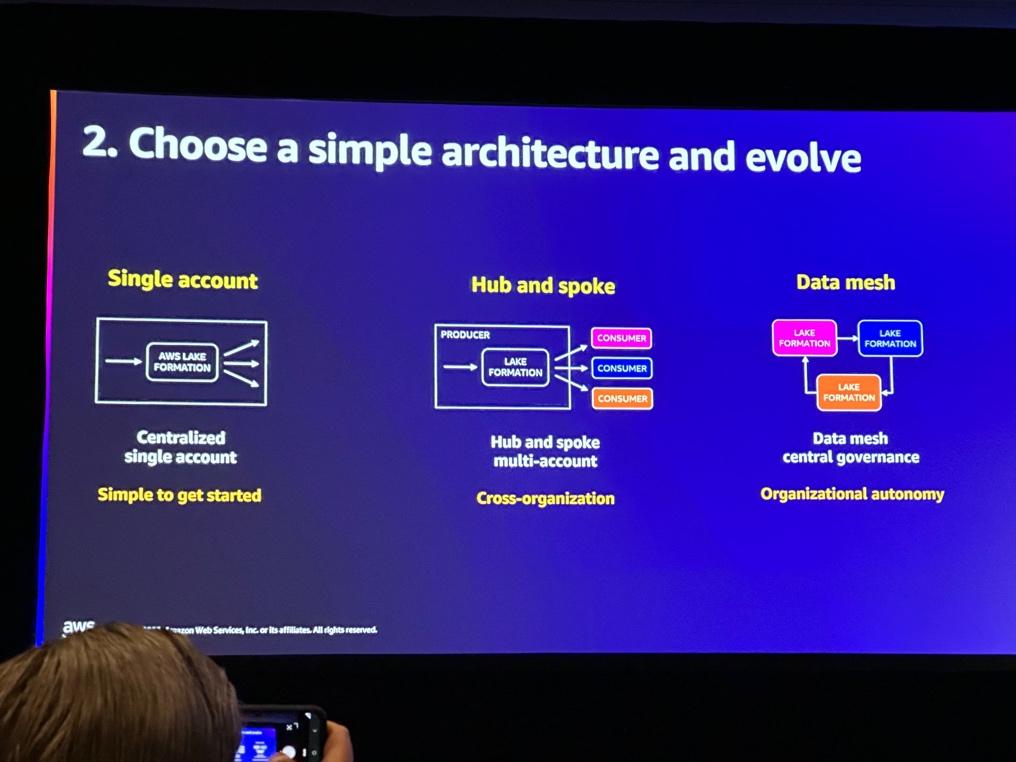
・single account : 一元化して一つのアカウントで管理する。
・hub and spoke : Producer、Consumerなど複数のアカウントを活用
・Data Mesh : lake formationを活用し、中央でデータマッシュを活用

Data governance for store, devieces, and other data lake data lakeの事例
Complianceに従うことは義務であり、データへのアクセス権を管理することは必須でした。

写真のようにデータを管理するためには3つのデータコピーが必要で、管理/コストに問題がありました。 また、S3データをRedshiftに載せて使いたかったのですが、ETLで収集すると、データのシンクを継続的に合わせるのも一つの問題でした。
これをGlueとLake Formationを活用してCatalog Metaベースで権限を付与し、Data Sharingを通じて他のアカウント内のデータを収集することができました。
しかし、Data Type Mapping、Performance、Permissionに関するいくつかの問題がありました。
1.Type mapping
・データタイプが多様だったので、それを合わせる作業が必要でした。
2.Performance
・データ量が多かったので、パフォーマンスが重要でした。
・パーティションを活用してPredicate pushdownで指定されたパーティションだけ読み込むように構成しました。
3.Permission debugging
・権限が間違って入ってデータが照会されましたが、権限付与のエラーでした。
セッションを終えて
データの量が増えれば、メタデータも一緒に増え、このメタデータを管理できなければ、事前に決めたガバナンスも揺らぐ可能性があるというスピーカーの言葉が印象的でした。データ収集と同じくらい重要なのがデータ保管や管理だと思います。Lake Formationと様々なサービスを一緒に構成してaws内のガバナンスを構築する方法について興味を持ちました。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner