MEGAZONEブログ

Unlocking more efficient data processing with serverless
サーバーレスでより効率的なデータ処理を実現
Pulisher : Cloud Technology Center キム・ビョンジュ
Description : StepFunctionの分散処理機能の活用方法や、そのQ&AをChalkTalkで説明するセッション
はじめに
Step FunctionはサーバーレスWorkflowサービスで本当に多様なAWSサービスと連携が可能です。私がStep Functionを初めて導入を決めたきっかけは、DMSと連動してデータパイプラインを自動化するために悩んで導入した経験があります。 その当時は、Step Functionの魅力ポイント(?)については詳しく知らなかったので、よりメリットとなる機能を学ぶために当該セッションを申し込みました。
セッションの概要紹介
このセッションはChat Talk方式で行われました。ほとんどの人はStepFunctionの分散処理機能を活用し、これに関する疑問を解決するために参加し、発表資料をできるだけ見ずに質問と回答を通じて運営されるセッションでした。
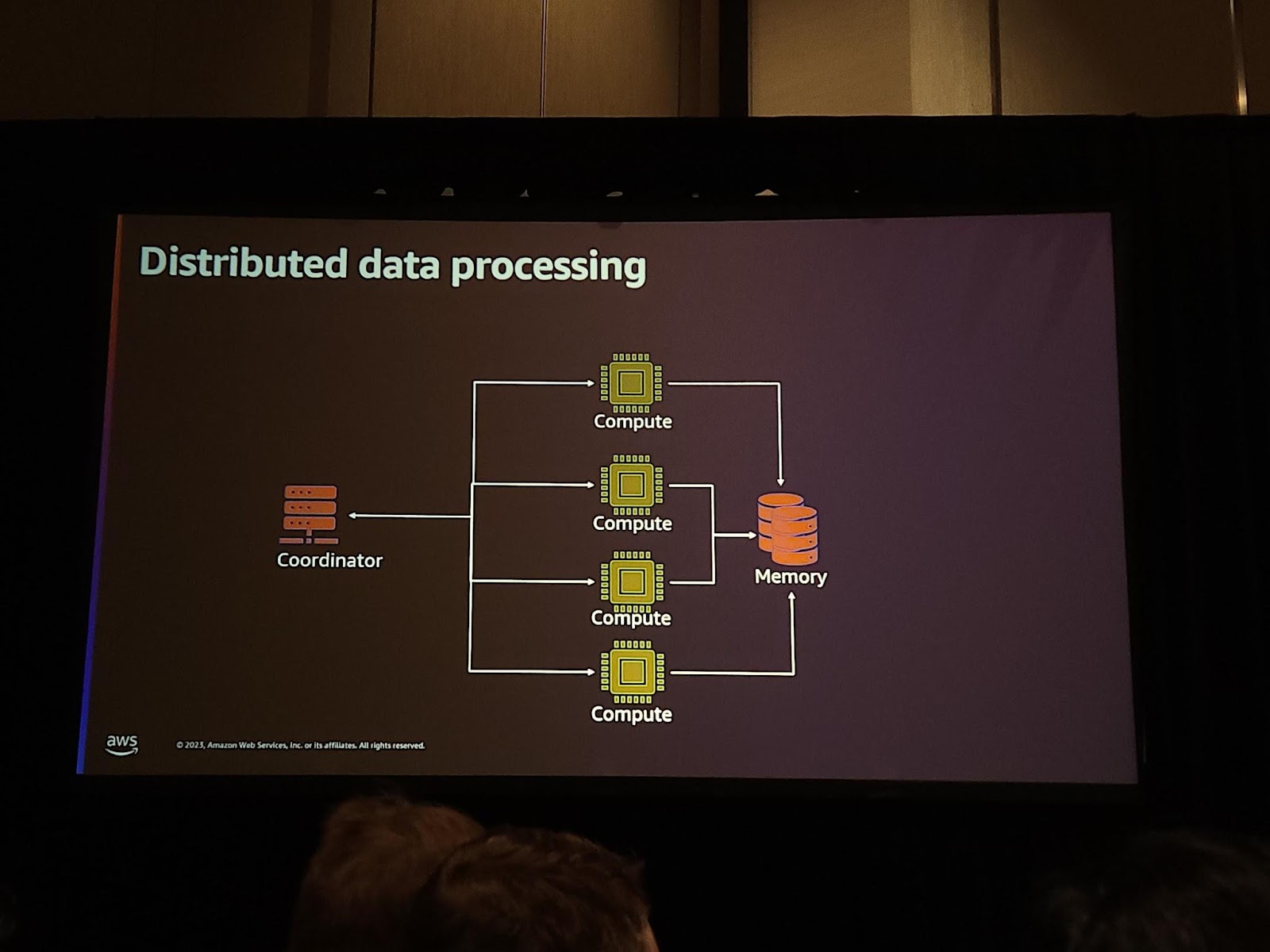
私たちは分散データ処理について話したいので、まず、分散データ処理の難しさを考えてみましょう。 分散データ処理は、ノートパソコンで大きなEC2サーバーで実行するだけでは解決できません。分散データ処理はノートパソコンでより大きなEC2サーバーで実行するだけでは解決することができません。 分散データ処理のために構成しなければならないことは次のとおりです。 タスクを管理するCoordinatorと計算を進めるCompute、そしてこれを保存するストレージまたはメモリが必要です。

このように分散処理システムを構築することで、様々なメリットがあります。市場発売時期を早めることができ、コストも削減することができます。 そして、Coordinatorのおかげで耐障害性を確保することができます。もし、一部のワーカーがデータ処理に失敗したと仮定した場合、Coordinatorがどのようなレコードを処理しているか知っているため、一部の作業を再実行することができ、これにより耐障害性、拡張性を確保します。

しかし、これらのソリューションは、場合によっては同時性を管理する必要があったり、Sparkのようなフレームワークの場合、追加のランニングカーブが必要だったり、コストが高くなることもあります。

しかし、この全ての作業をServerlessで出来たらどうでしょうか?AWSではこのような作業を短縮するためにStep FunctionにDistributed Map機能をリリースしました。この機能は、コードを書かなくても少ない管理でファイルやデータを分散処理することができる機能です。
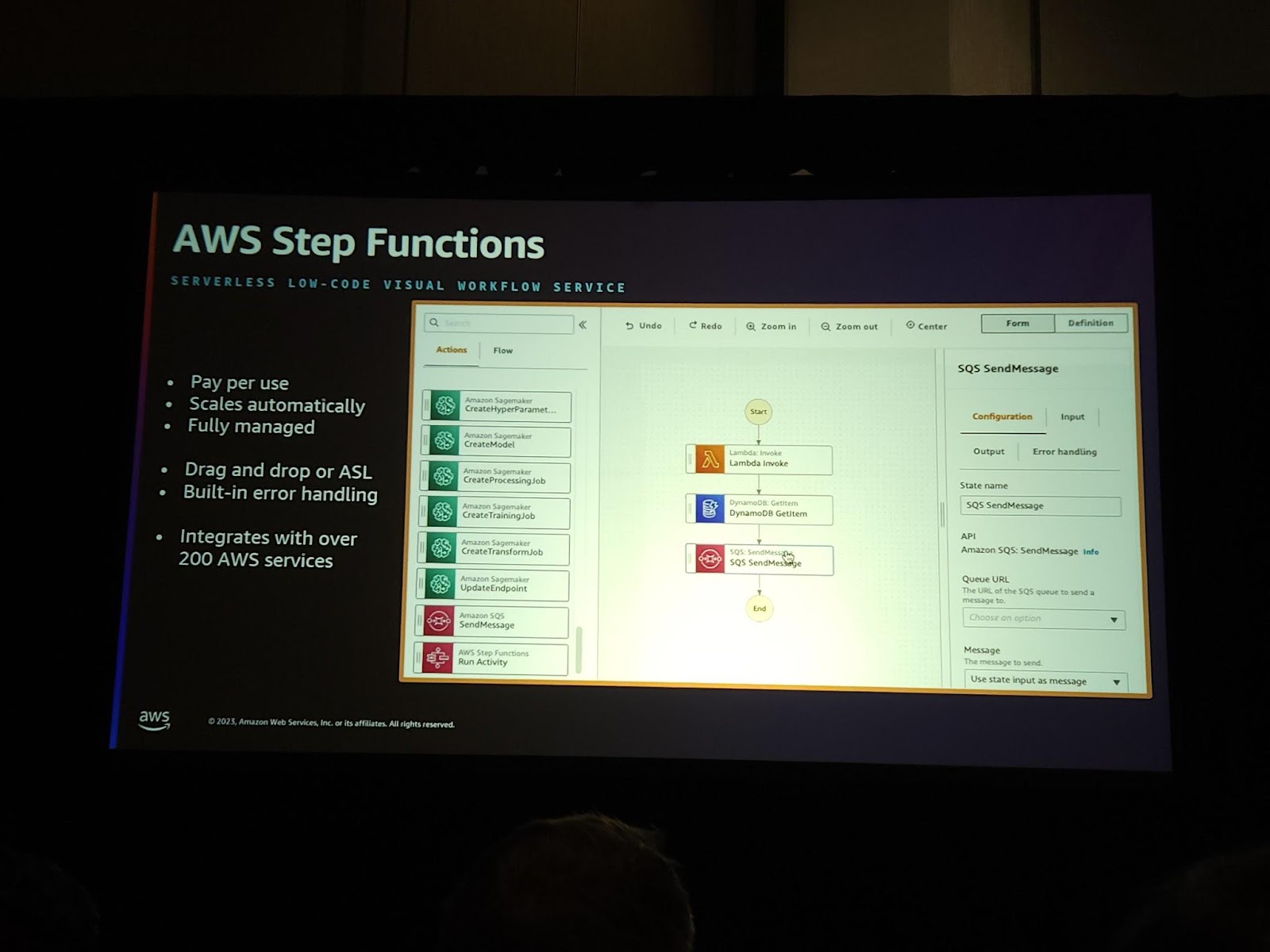
AWS Step Functionは様々なAWSのサービスがASL(Amazon State Language)で定義された使いやすいServerless Workflowの一つです。ラムダコードを書かなくてもDynamoDBにデータを入れたり、取り出したり…。本当に色んな機能をすることができます。

Step Function Distributed Map機能を使ってS3にあるファイルを素早く分散処理してみましょう。 次の説明は画像がないので、簡単なQ&A形式でStep Function Distributed Map機能についてまとめたいと思います。
Q. もし、シングルファイルに対する処理をするとしたら、どのように動作するのですか?
A. シングルファイルで入力が入ったとしても、Distributed Mapを使って分散してファイルを処理することができます。もちろん、最大10,000個まで拡張も可能です。
Q. では、RDSのデータを処理するようになったとき、そのように使うことができますか?
A. 分散マップはLambdaとの連携も可能です。この場合、RDSに1万個のConnectionが発生する可能性があります。 そうなると。ダメなので、分散マップで最大同時性を制御する設定値があるので、その設定値を使う必要があります。
Q. Step Functionの呼び出しデータを直接分散処理することはできますか?
A. はい!もちろん可能です。しかし、Step FunctionのAPI呼び出しあたりの最大ペイロードサイズが256KBであることに留意してください。 そして、このような使用パターンは、Step Functionを通じて取得するDynamoDBデータを分散処理するパターンにも使用できます。
Q. もし、Step Functionで処理中にエラーが発生した場合、ラムダでエラー関連のログを残して確認することができますか?
A.もちろんです。直接ラムダでログを作成して確認することもできますが、分散マップでは簡単にエラーをモニタリングして確認できるように作られています。 なので、できればその機能を活用してモニタリングしてみてください。
Q.データ処理中に一部が失敗した場合、全体のワークフローが失敗しますか?
A.良い質問です。 この分散マップ処理には、失敗処理する限界値%または数を指定することができます。もし1000個のファイルを処理しなければならないのに、そのうち5個が失敗したからといって、全体のワークフローを再実行することはありません。そのため、このような機能を活用することができます。
Q.では、一部のワークロードが失敗した時のログを別途見ることもできますか?
A.はい、可能です。
Q.では、ワークロードが失敗したときに例外処理もできるのでしょうか?
A.はい、可能です。基本的にStep Functionの基本機能を活用するので、Step Function自体の例外処理を使うことができます。ここでもう一つお伝えすると、分散マップはサブワークロードの一つであり、まるでサブステップ関数が動くのと同じようなものです。
Q.Step Functionの分散マップがサポートする入力タイプにはどのようなものがありますか?
A.単一ファイルを読み込む場合、一つの大容量ファイルを一行ずつ読み込む場合、CSVをサポートし、JSONもサポートします。JSONの場合、JSON LISTでなければならず、そのオブジェクトを繰り返します。 あるいは、先に説明したように、以前の状態の入力をそのまま使用することもできます(256kb)。
Q.では、S3でデータを処理する時、すべてのデータの形式がCSV、JSONでなければならないのですか?
A.良い質問です。 分散マップはラムダと連携が可能で、S3のファイルを直接取り込む方式ではなく、ファイルリストを受け取る方式でも処理することができます。このようなS3 list object方式でデータを処理する場合、Lambdaはどこからデータを読むべきかをコーディングすることなく、受け取った位置を処理する単純なコーディングで作成することができます。
Q.もし処理中に失敗したら、失敗した位置からやり直すことができますか?
A.2週間前までは、難しいか…独自に処理しなければならないと答えなければなりませんでしたが、最近Redriveという機能が追加されました。複雑なワークフローを処理する上で、失敗した場所からやり直すことができます!
Q.個別ファイルの場合、最大何GBまで処理できますか?
A.この分散マップ基準で処理は最大10GBまで処理できます。これはラムダのメモリ制限と同じ制約事項と理解していただければと思います。
Q. もし、大きなデータが入ってきて分散マップ(ラムダ)で処理ができない場合はどうしたらいいですか?
A.S3イベントを使ってみると分かると思いますが、そのイベントにはオブジェクトのサイズまで一緒に渡されます。このようなオブジェクトのサイズを基準に分岐処理をしてECS Fargetを連携したり、他のサービスにそのファイルを処理するように要請する分岐処理をStep Functionでは簡単にすることができます。
セッションを終えて
Step FunctionはWorkflowの機能以外にも、Distributed Map機能を通じて本当に簡単にデータを並列に扱うことができます。場合によっては、一般的にデータを処理するために使うGlue, EMRより小さいファイルデータや複数のデータを処理する上で大きなメリットがあると感じました。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner