MEGAZONEブログ

生成AIの革新を導くAWSインフラ
Speaker : AWS Solutions Architect ジョン・ユジン / AWS Solutions Architect キム・ジェボ
Pulisher : ジェユン
はじめに
以下の内容を紹介します。
・最新の生成型AIをサポートするために、AWSが展開しているインフラの核心要素
・MLと生成型AIを活用しているAmazon.comの顧客事例について
生成型AIの未来:ChatGPTから始まる新たな時代
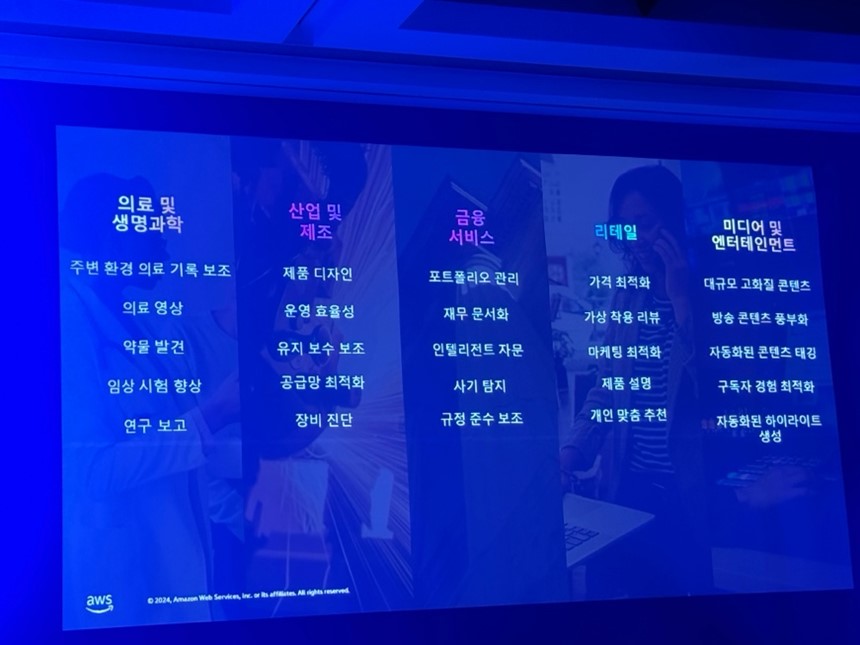
皆さんの生成型AIのすべての出発点はChatGPTだと思います。
実際、このようなGPTのようなモデルはすでに4、5年前から存在していました。
現在のGPT段階はこの技術を理解して、今後どのように活用していくのかという段階です。
ゴールドマン・サックスによると、2、3年後には生成型AI市場が約7兆ドルに増加すると言われています。
そのため、生成型AI市場は産業全般にわたる魅力的な成長の機会となるでしょう。
医療および生命科学、産業および製造、金融サービス、小売、メディアおよびエンターテインメントなど、すべての産業での使用事例が増えています。
例えば、医師や健康管理専門家が利用する医療記録保護ツールや薬物発見およびコールセンターなどに生成型AI技術を活用し、大きな価値を生み出しています。
このように高い価値を持つ生成型AIについて、AWSはどのような戦略を持っているのか注目してみましょう。
AWSの戦略:モデルサイズにおける変化の推移
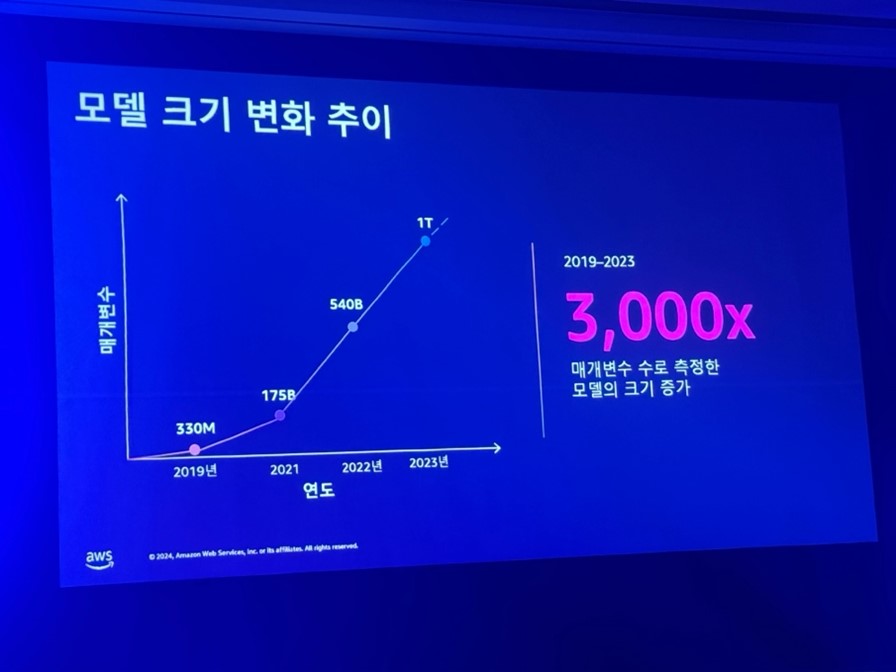
このグラフ(Y軸: Parameter, X軸: Years)はモデルサイズの変化推移を示しています。 Parameter数によるモデルサイズは2019年から2023年までに約3000倍以上増加しました。このようにモデル開発にこだわる理由はなんでしょう。
AWSの戦略:高性能なComputeが求められる理由
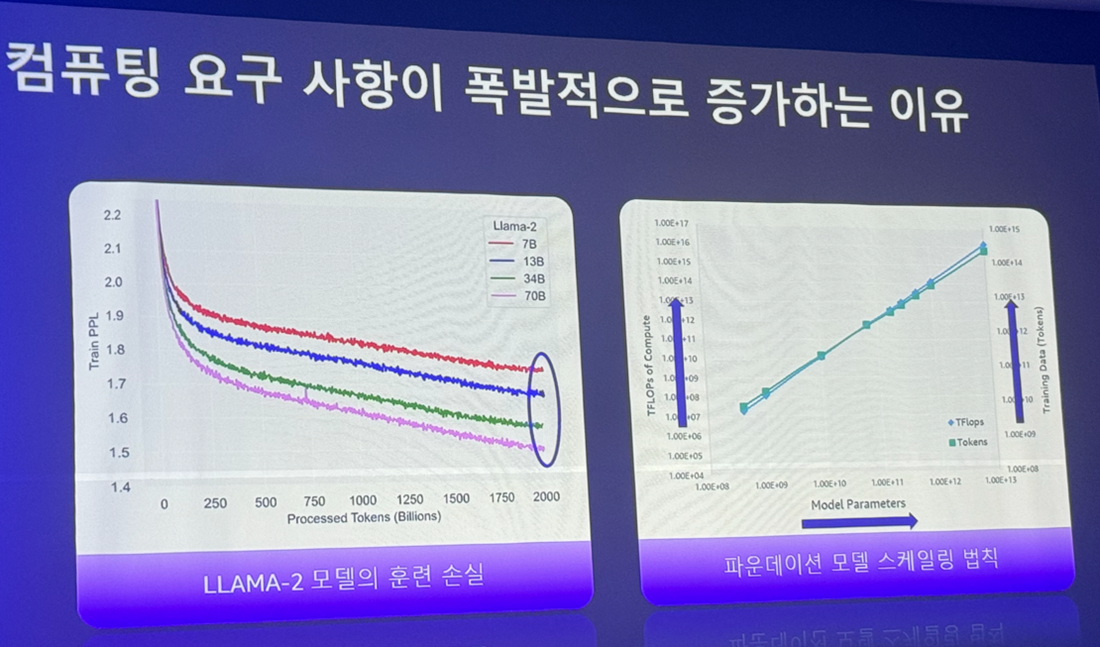
モデル開発にいて、高性能なComputeが必要な理由を2つのグラフから説明します。
左のグラフは、Llama-2論文にあるグラフです。各軸の説明は、
・Y軸(Train PPL)は言語モデルの性能を評価する指標であり、値が低いほどモデルがテキストをよりよく予測することを意味する。
・X軸(Processed Tokens)はモデルが訓練や推論過程で処理したテキスト単位(Tokens)の総数を意味する。
Processed Tokensの数が70億、130億、700億個の時にTrain PPLが徐々に低くなるグラフは、モデルがより多くのデータを学習するほど性能が向上することを示しています。
これは言語モデルが十分なデータを学習する時、より正確な予測ができることを意味し、学習データの量がモデル性能に重要な影響を与えることを示しています。
右のグラフはファウンデーションモデルスケーリング法則の二重Y軸グラフです。
モデルのパラメータ数が増加するに従い、モデルを学習させるためにより多くの計算資源(TFLOPs)とより多くの学習データ(Tokens)が必要であることを意味します。
また、モデルがより複雑になるほど、つまりパラメータ数が増加するほど、これを学習させるためにより多くの資源とデータが必要です。
これはファウンデーションモデルスケーリング法則に従うもので、モデルの性能を向上させるためにはモデルのサイズ(パラメータ数)、学習データの量、そして計算資源の量がすべて増加しなければならないことを示しています。
そのため、高性能なComputeが必要であることがわかります。
モデルの性能を最適化するためには十分な学習データを提供し、これを処理できる十分な計算資源を持つサーバーが必要です。
したがって、Llama-2のような大規模言語モデルを効果的に学習させるためには高性能のサーバーが必須です。AWSは生成型AIを支援するために、コストが低く、性能のあるインフラサービスに力を入れています。
AWSの戦略:高性能なComputeサービス
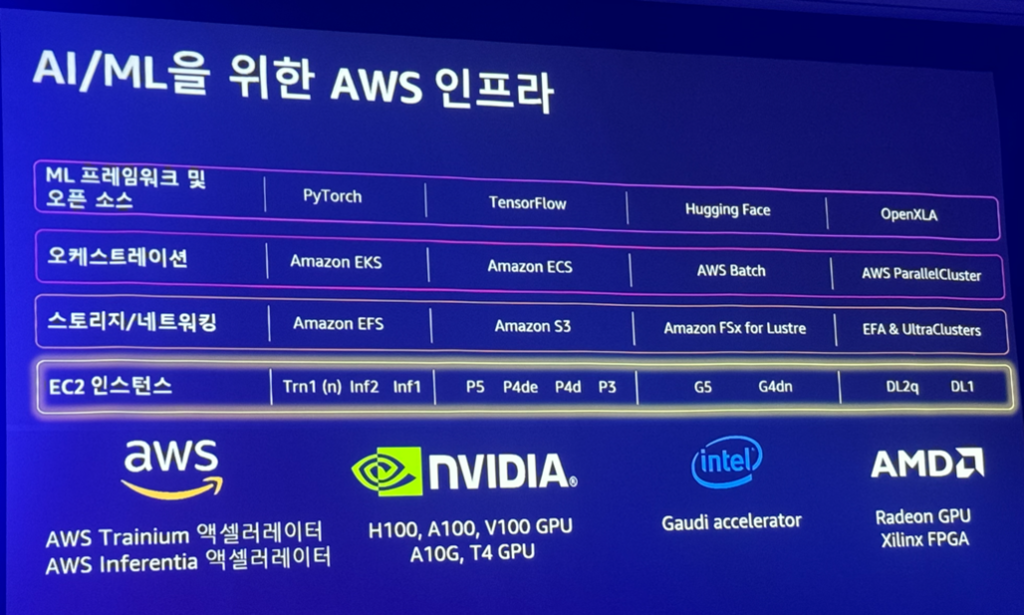
AWSは、H100、A100、V100 GPUを基盤としたインスタンスをクラウド事業者の中で初めてリリースしました。そのほかにもIntelなどのパートナーと提携しています。また、この5年間、ディープラーニングアプリケーションを加速するために、AWS自身のソリューションを構築してきました。
AWSの戦略:AWS Nitro System

AWS Nitro Systemは、高性能なインスタンスを速やかにリリースできるように支える技術です。
メイン構成は次の3つがあります。
・Nitro Card: Local NVMeストレージ、NW、Monitoring、Security
・Nitro Security Chip: Motherboardに統合、ハードウェアリソースを防御
・Nitro Hypervisor: 軽量なHypervisor、メモリとCPUの割当て、ベアメタルのような性能
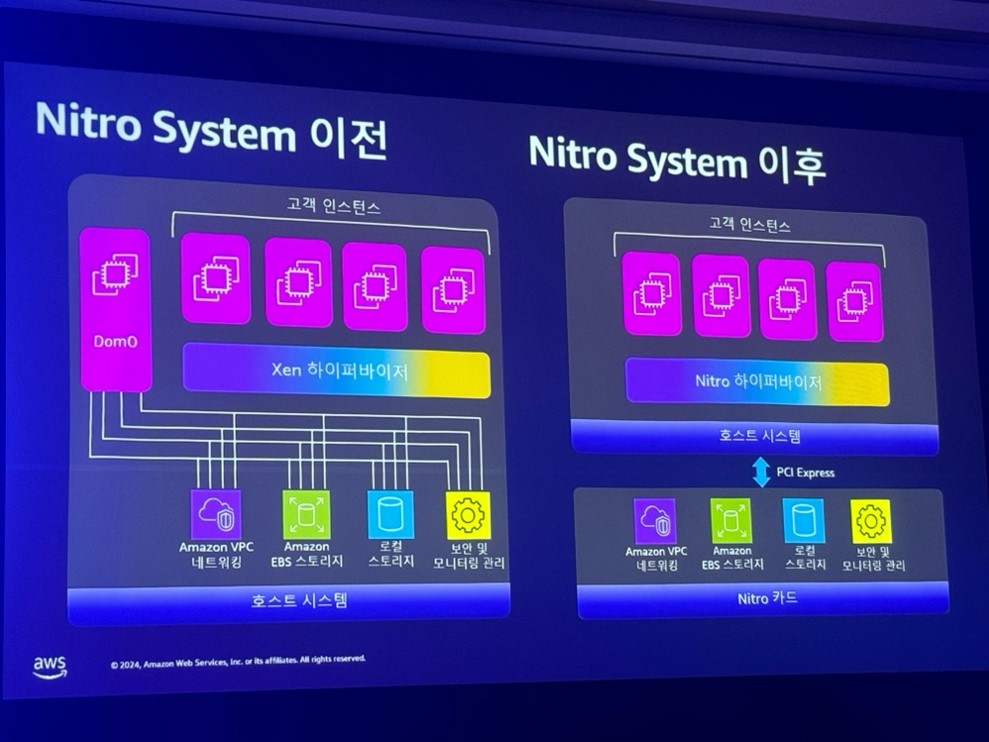
以前のNitro System(左図)は、2014年から2015年頃には、単一システムでした。
サーバーには顧客のインスタンスがあり、管理はXen Hypervisorが行っていました。
Dom0のリソースを活用し、ネットワーク、EBS、ストレージ、モニタリングを管理していました。
しかし、性能が上がることにより、 ホストマシンの一部を仮想化基盤の制御を行うDom0が占有して、カスタマーに提供ができないことや、 ホストマシン上での密結合で新しいインスタンスタイプの提供時に負担となるなどの理由で、現在(右図)に解決しまし。
構成は、ネットワークやストレージの仮想化などを専用ハードウェアにオフロードし、ホストと分離しています。ホスト上では、Nitro Hypervisorが管理を行っています。

こちらは、Nitro1から5世代のNitro Chipです。
このように、AWSは10年以上にわたり、Chipの作り方やインスタンス拡張に関する専門知識を培ってきました。
Amazon.comの顧客事例:Amazon M5

Amazonの生成型AIとAWSの使用事例について説明します。
Amazonの中心となる製品は、Amazonで購入する商品や、商品を検索する際に入力するクエリなど、ECサイトに関するオブジェクトを意味論的に表現したものです。
意味論的には、大規模な言語モデルを活用して、データの意味を把握することを指します。
このように効果的にデータを利用するためには、膨大なデータが必要です。
右のイメージは、Amazonにある製品のページです。
ここには、タイトル、製品詳細、レビューなどのデータがあります。
このような製品ページが約10億あり、100億以上のパラメータを用いて、大規模な言語モデルに学習させることができました。

Amazonはこの意味論を表現するために、次の5つの要素を識別しました。
- Multi-modal: Amazonのデータは、非構造化データなどの様々な形式で提供
- Multi-lingual, Multi-locale: 異なる文化を考慮し、該当する地域に特化したものを提供
- Multi-task: 様々な顧客の問題に対応するために、製品の多様な観点を把握
- Multi-entity: 異なるオブジェクト関係を把握
Amazon.comの顧客事例:スペルチェック

では、このモデルがAmazonにどのような変化を与えたのかを見てみましょう。
まずは、スペルチェック(多言語対応)です。
Amazonは顧客が簡単に検索できるようにサービスを提供しています。正確なスペルがわからなくても、スペルを入力するだけで該当する製品を見つけることが可能になります。
Amazon.comの顧客事例:イメージ生成

これは、生成型AIを利用したイメージ生成の例です。
Promptを使用して、浴室のイメージを生成したケースです。
例えば、Promptは次のようにします。
「この浴室には、洗面道具とアクセサリーが収納できる2つのバスケットがある木の棚があります。洗面台は白色の陶磁器で作られており、蛇口はクロムメッキの優雅なデザインでブラックとよく調和します。」
なお、上下のイメージを比較してみます。
上のオープンソースモデルで生成したイメージを見ると、いくつかのイメージには収納できる木の棚が見えないようです。
一方で、下のAmazonモデルで生成したイメージを見ると、すべてのイメージに収納できる木の棚が見えます。これは、Amazonカタログデータを基盤として学習しています。
顧客が興味を持っている製品に対し、より近いイメージを生成することに役立ちます。
Amazon.comの顧客事例:課題と目標
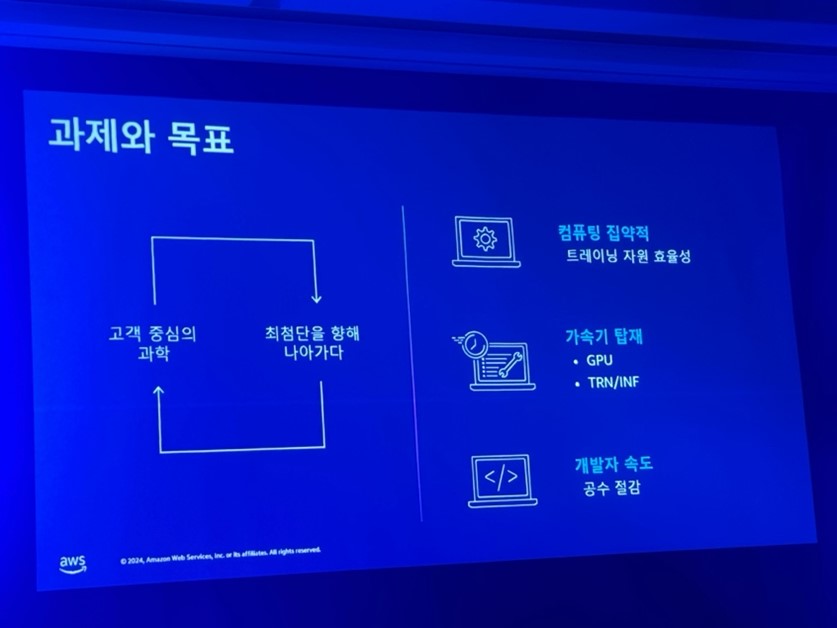
Amazonがこのようなアプリケーションモデルを構築するために、どのような課題をどのように解決したのかを見てみましょう。
Amazonは顧客に集中する科学的な循環構造を持っています。
顧客中心の科学を追求し、それを通じて顧客にショッピングの楽しみを提供しています。
これは最先端の技術の限界を継続的に開発することで、結果的に顧客の満足度を向上させることができました。この過程には3つの課題がありました。
| 区分 | 課題 | 対策 |
|---|---|---|
| コンピューティングの集約的 | Amazonは毎月数千件以上のテストを行うが、チーム単位で手動管理 | AWS Batchを利用して自動的に作業順位全体を管理し、 効率性を向上させることができた |
| 高速計算の搭載 | AmazonはAWSのGPUのような高速計算が必要 | AWS Trainium、Inferentia2を使用して、 確立モデルの最も費用効率的(最大50%削減)で高性能なトレーニングを行うことができた |
| 開発者の速度 | 開発者の工数を管理することはビジネスの成功に大きな影響を与える | AutoResumeの非同期式分散チェックポイントが可能なアーキテクチャを設計し、 開発者がモデル開発および学習作業において中断なく開発を行えるアーキテクチャを実施 |
Amazon.comの顧客事例:結果

AWSを利用したら、毎月数万件のテストを実施でき、すべてのAWSリージョンでワークロードを進行できます。
中央集中的なロギングやダッシュボードを通じて、開発者が簡単かつ深くデータを分析することができます。このような取り組みにより、約100億個以上のモデルを推論することができ、約500個のモデルをアプリケーションに搭載することができました。
また、Amazonは130個のアプリケーションを向上させ、50個以上の顧客向けアプリケーションをリリースしました。
セッションを終えて
多くの人々がAmazon.comを利用していることは知っていましたが、実際にAWSをどのように活用しているのかをセッションを通じて知ることができ、とても有益でした。
また、AWSは生成型AIを構築するための最適なプラットフォームであり、生成型AIは選択ではなく必須であると感じました。


