MEGAZONEブログ

Lessons learned using generative AI in banking and shopping services
銀行業務やショッピング・サービスにおける生成AI活用で学んだこと
Pulisher : Mass Migration & DR Center キル・ジュンボム
Description : 韓国における生成型AI適用事例の紹介セッション
はじめに
国内生成型AI適用事例を確認するためにセッションを聞いてみました。
セッションの概要紹介

Amazon Goと似た韓国の「Uncommon Store」の事例です。最も重要な3つは「どのような物を」「誰が拾って」「どこに置くか」を認識することです。しかし、棚に商品がしわくちゃになっていたり、置いたのに他の場所に置いた、パッケージが似ていて商品を正確に識別するのが難しいなどの問題が発生することがあります。

生成型AIは架空のデータを作ってモデルを学習させます。実際のデータを人が作り出すよりも多くのデータを素早く生成して学習させるので、上記のような主なポイントを重点的に学習させることができます。
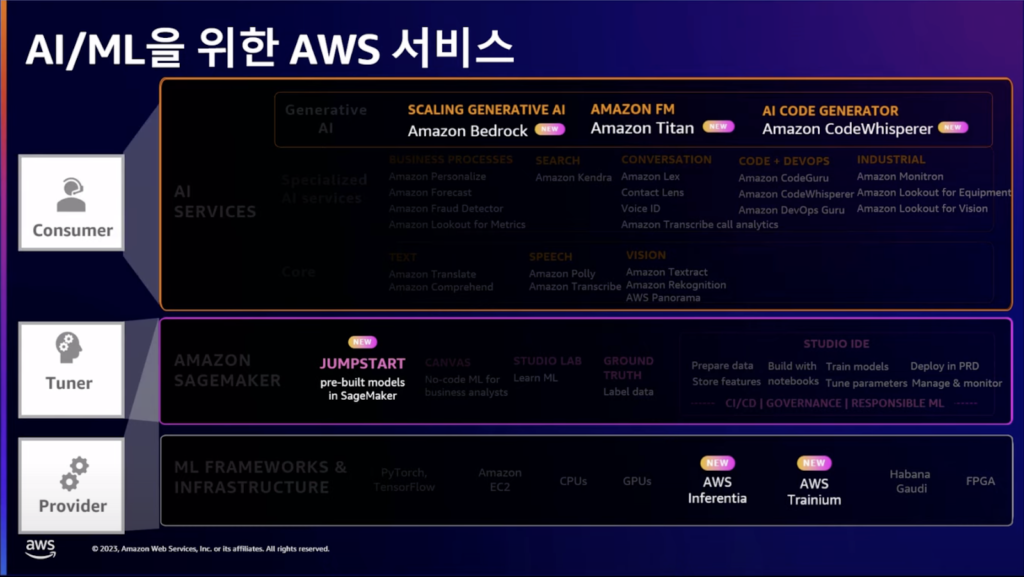
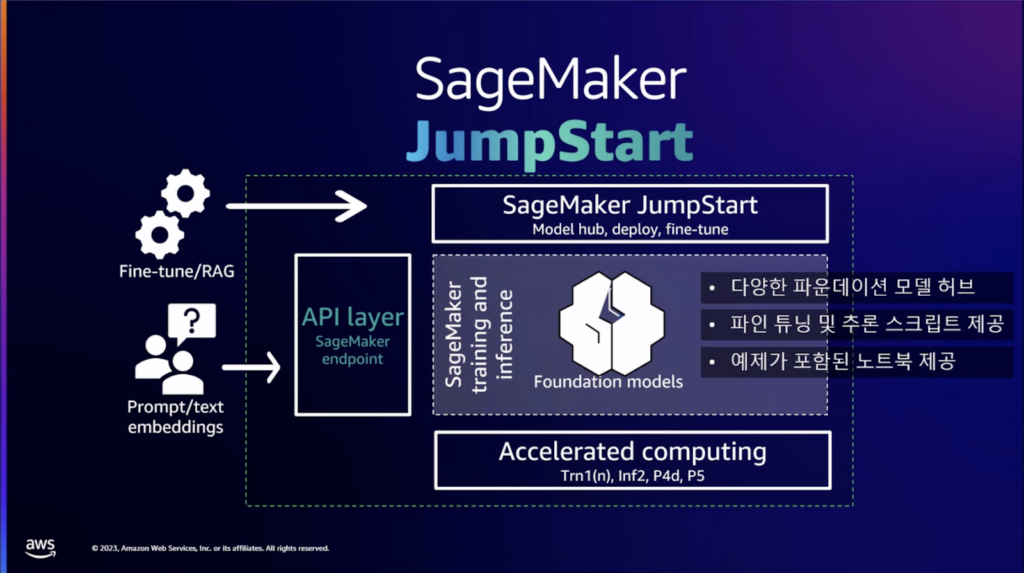
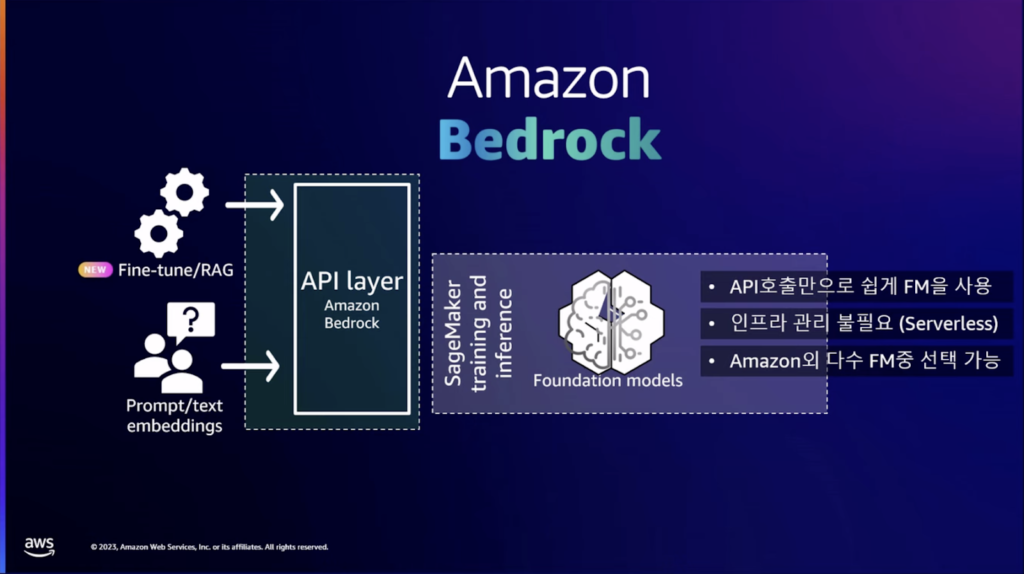
AWSは生成型AIをサポートするインフラ、ツール、サービス層で構成して様々なサービスを提供しており、様々な目的に合わせて選択して使用することができます。JumpStartはSageMakerに含まれる基盤モデルのハブとして機能します。 複数の基盤モデルの中から、選択して微調整し、ビルド後に推論型インスタンスを使用することができます。Bedrockは、Amazonで厳選したモデルを呼び出すAPIサービスだと言えます。
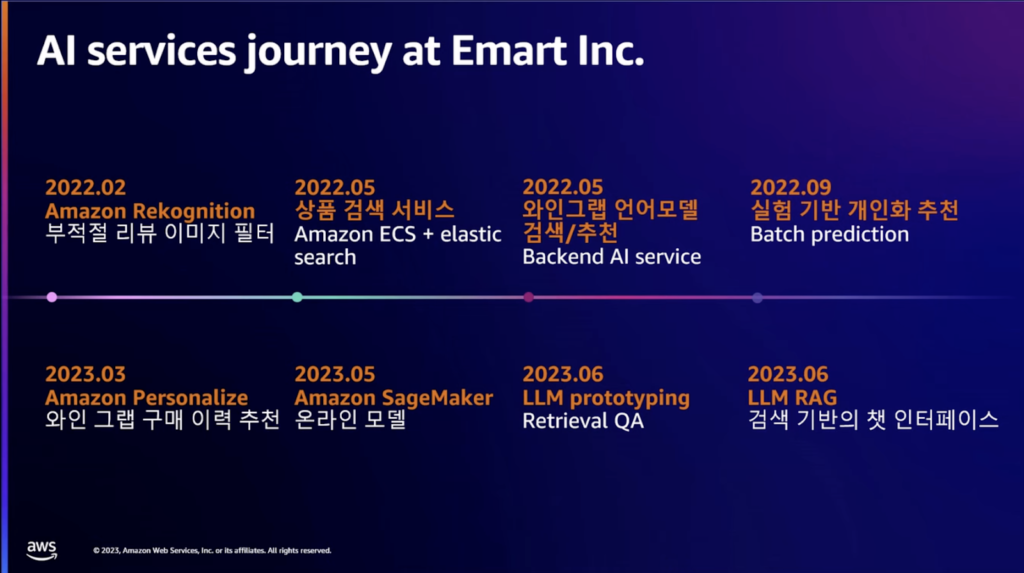
AWSのAI関連の紹介の後、イーマートのAI導入事例について共有されました。 イーマートは1年半の間、AIを活用したサービスを継続的に適用し、現在はAWSプロトタイピングチームと専門家と一緒にLLM RAGプロジェクトを進行中です。

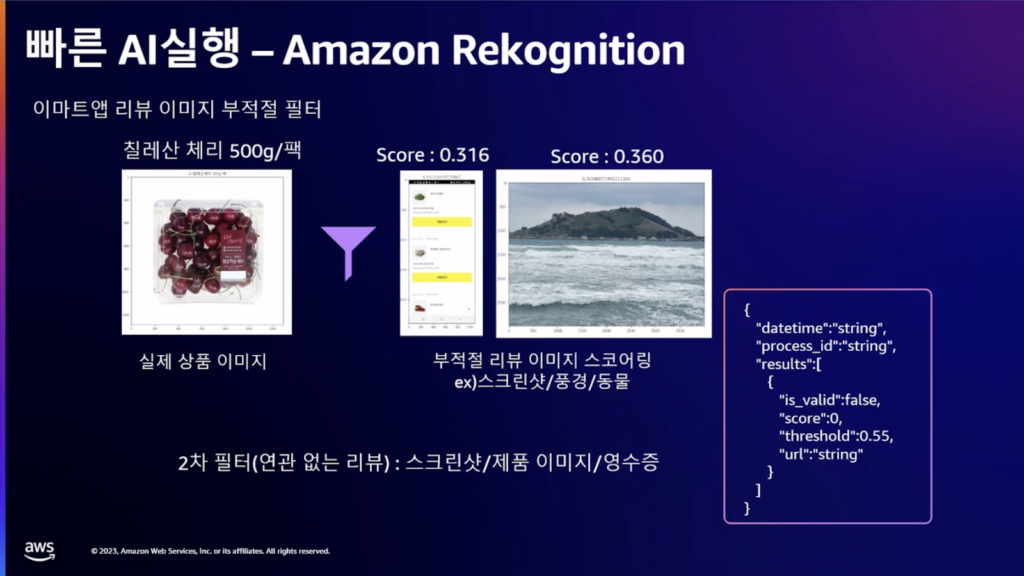
人がレビューサービスの画像をレビューすることができますが、不適切な画像やテキストをアップする場合、AIを通じてより迅速に認識し、処理することができる効果を期待して適用しました。 扇情的な暴力性がある場合は、迅速に削除が必要な画像であり、画像レビューリワードが高いため、任意の写真をアップする場合があり、これを検討し、削除するための領域で使用中です。
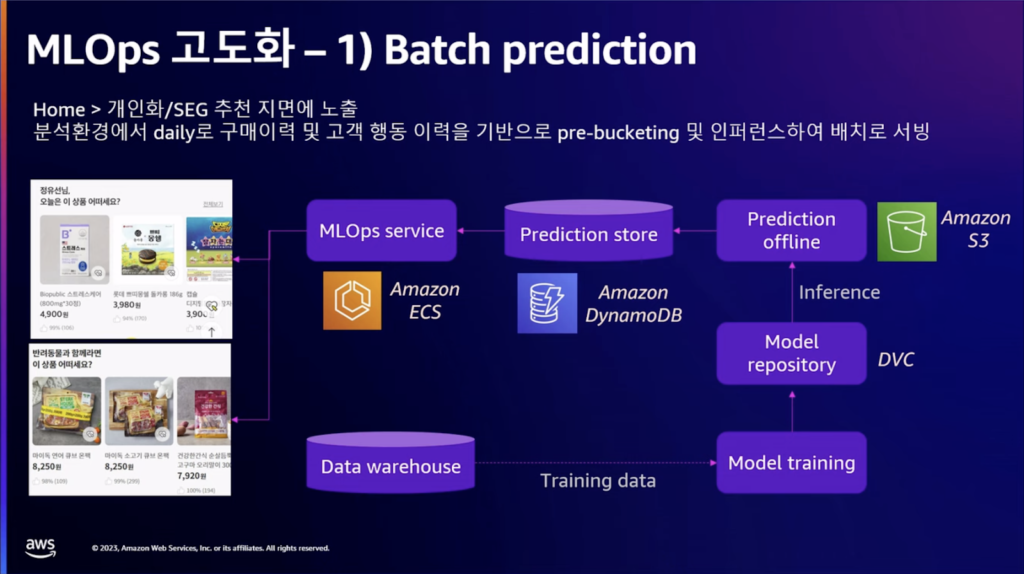
パーソナライズされたレコメンデーション領域があり、モデルを作成して配置して使用するようにしました。顧客の購買履歴や行動履歴を通じて、パーソナライズされた推薦とペット用品の推薦を行いました。
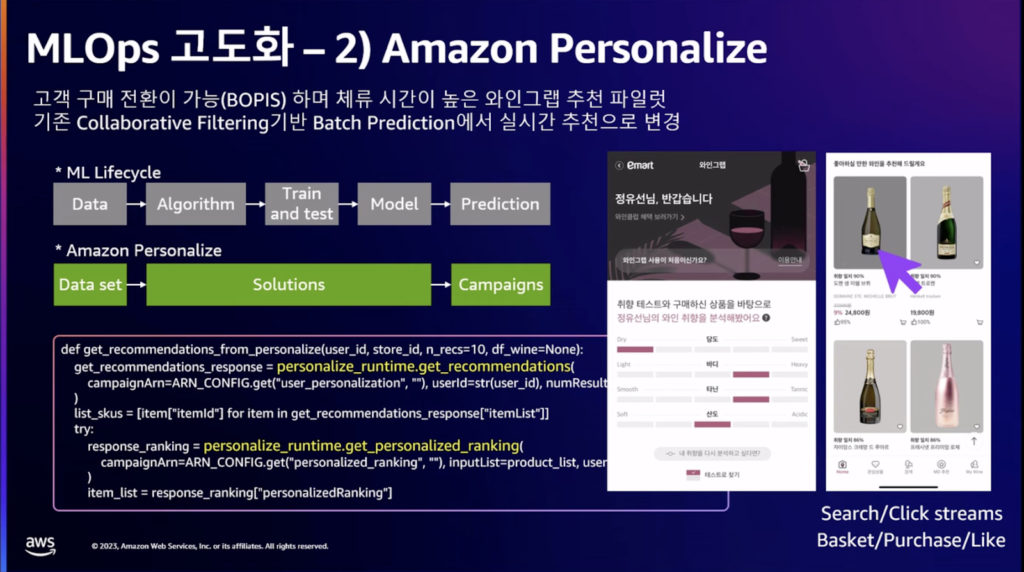
「ワイングラブ」という購入、決済、店舗受け取りまで可能なサービスを利用しながら、動的にレコメンドが継続的に変更される必要がありました。 これを解決するために、パーソナライゼーションを使用して準備されたデータセットにキャンペーンを設定するだけで、パーソナライズされたレコメンドサービスを上げることができました。 このような顧客のオンライン活動を反映したレコメンドサービスを簡単に作成することができました。
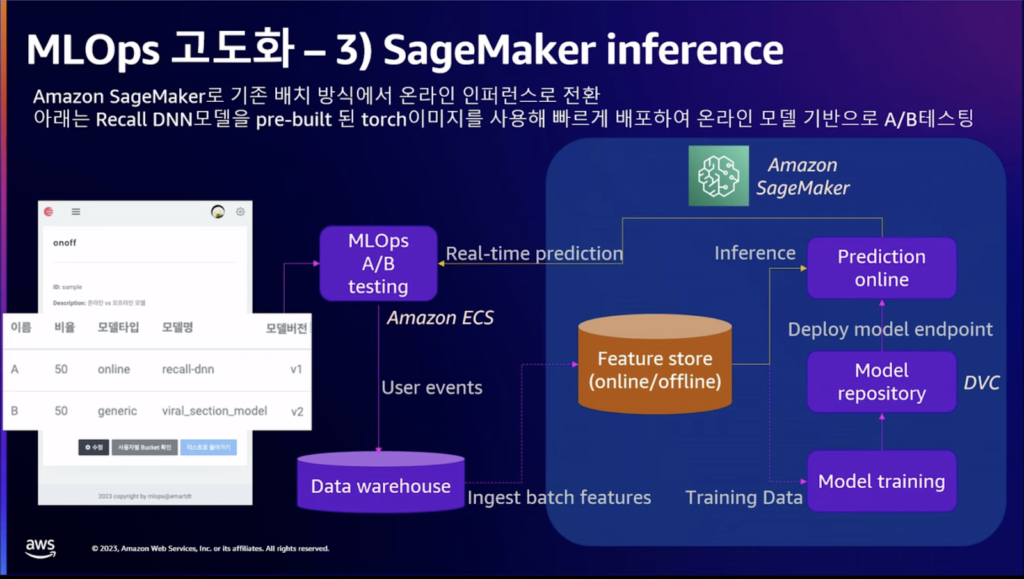
顧客の行動、購買などのイベントデータをリアルタイムでオンラインモデルに変換する作業を行いました。 オンラインモデルをベースに作成するために、フィーチャーストアとSageMaker Infernoを使用しました。
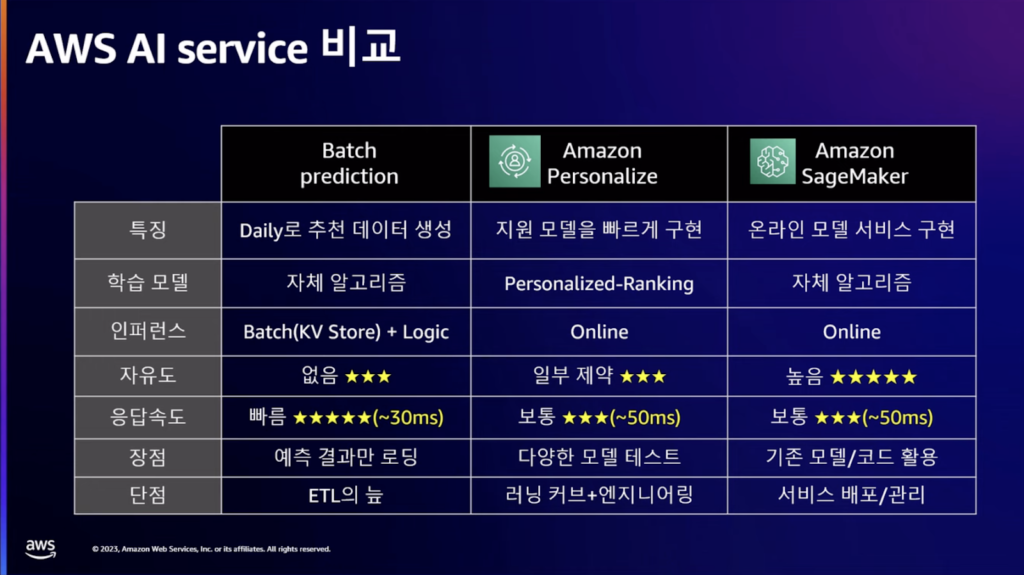
迅速に適用しなければならない時は諦めなければならない部分があるので、バッチプリディクションを適用しました。 バッチプリディクションはモデルサーブするのにおすすめの領域は簡単でしたが、データセットが準備されていて、迅速にモデルを実装しなければならないのにモデラーが不足している場合は、パーソナライズの使用を検討してみることができそうです。 既存にモデルを持っていて、オンラインモデルに対して新規開発する場合は、セージメーカーを検討してみるのがいいと思います。
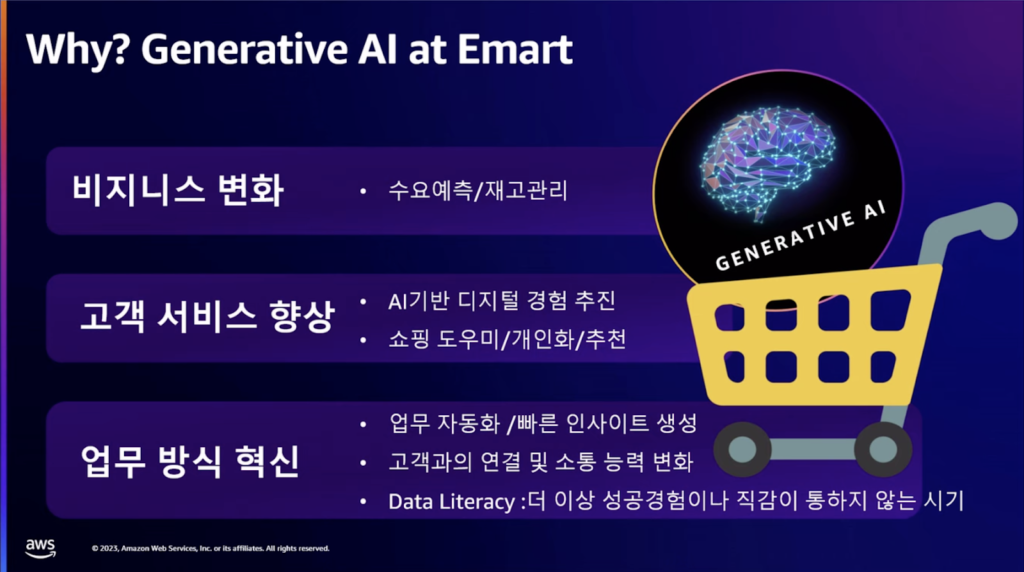
Eマートで生成型AI基盤のアルゴリズムを活用する理由は、第一に顧客サービス経験の向上という側面があり、第二に内部の従業員の業務方法の変化のためでした。
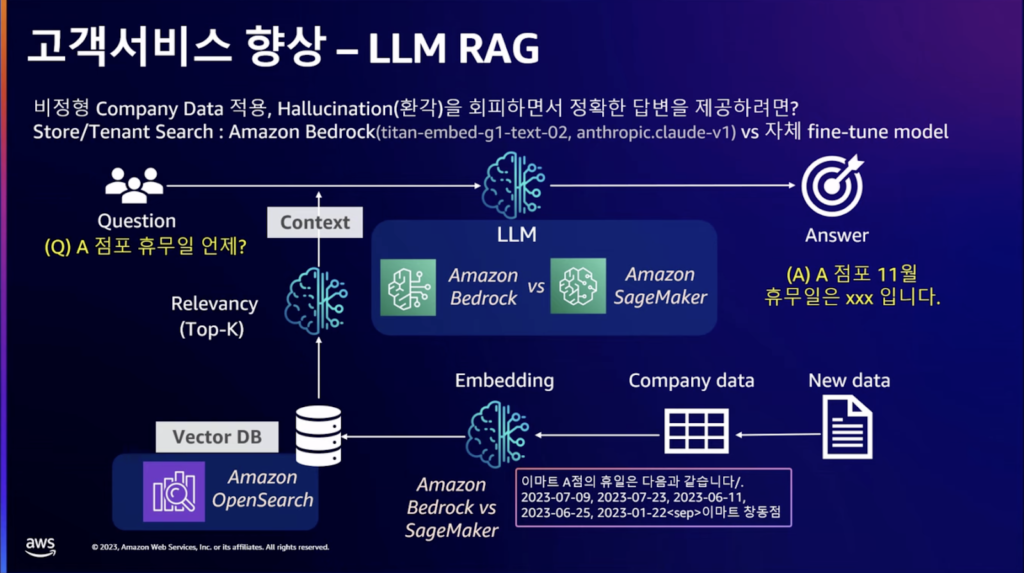
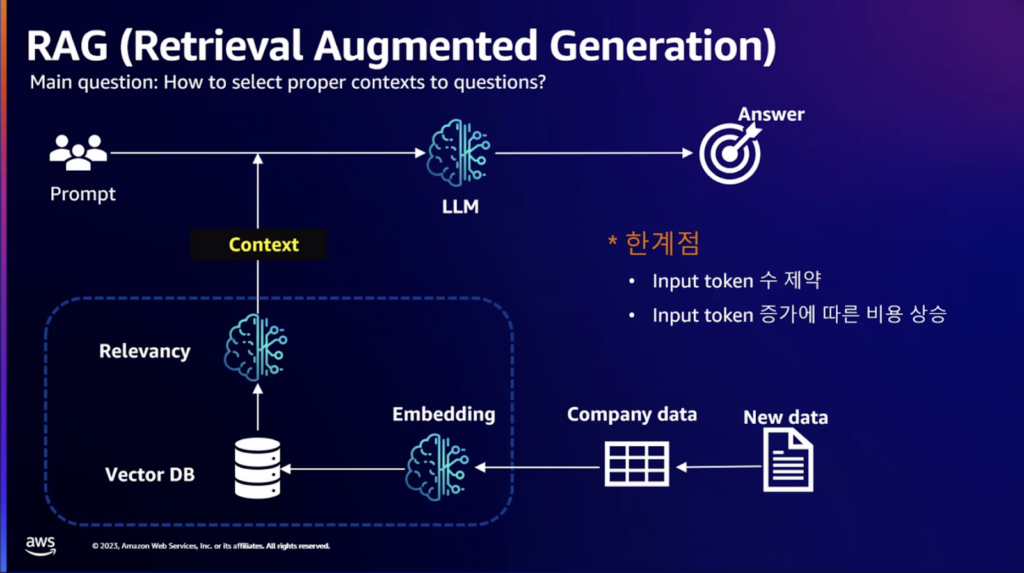
会社で持っているデータに基づいてLLMを活用する目標を立てました。 非定型の会社データ、例えば、店舗別休館日情報がテキストになっているデータを質問したときに結果を出すプロセスです。LLMの幻影を最小化するために、別のベクターDBをオープンサーチで構築して使用中です。
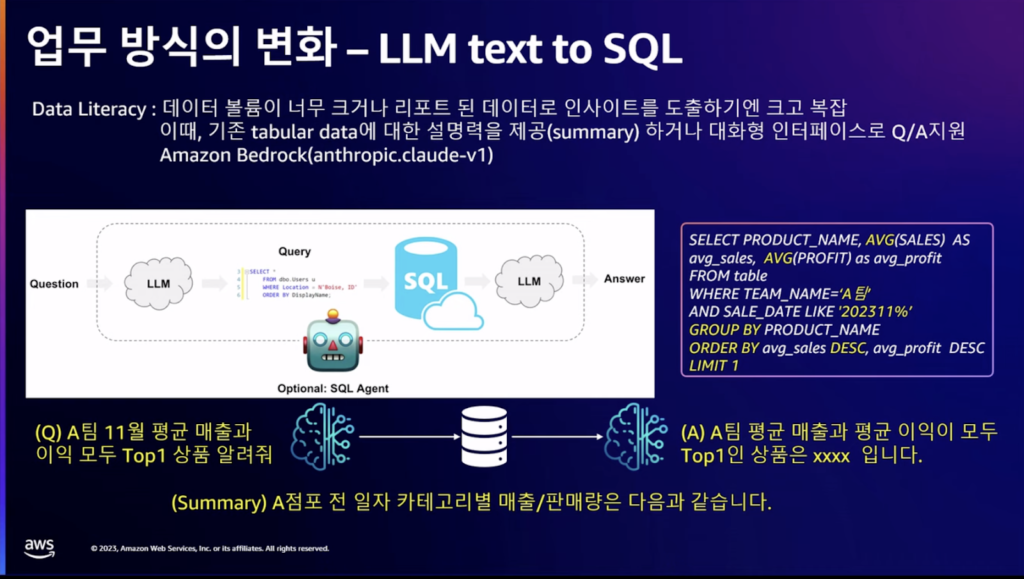
内部従業員のためには、Text to SQLを構成しました。 システムも、データも、BIも多すぎるので、表形式のデータについて説明をしたり、インタラクティブなインターフェースで質問と回答をサポートしています。DBMSにあるテーブルをLLMがクエリに変換して結果値でテキストを作成する形式で構成しました。テーブルに対するスキーマ情報が準備されなければならないし、質問に対してプロンプトでSQLに変更するように言った時、バックエンドでDBに問い合わせて結果をテキストの形で回答することになります。

生成型AI技術の発展により、技術の内在化よりもSaaS型AIの導入をまず迅速に検討し、awsのMLOpsをレファレンスとして活用して適用し、従業員の働き方の変化を支援する起爆剤として使用するつもりです。 このような形式を継続し、デジタルトランスフォーメーションを加速する計画です。


セッションを終え、AWSによく質問する内容をまとめました。
1.AWSのAIアプリケーションサービスはAmazonQ(対話型質疑応答)、PartyRock(アプリケーション生成)
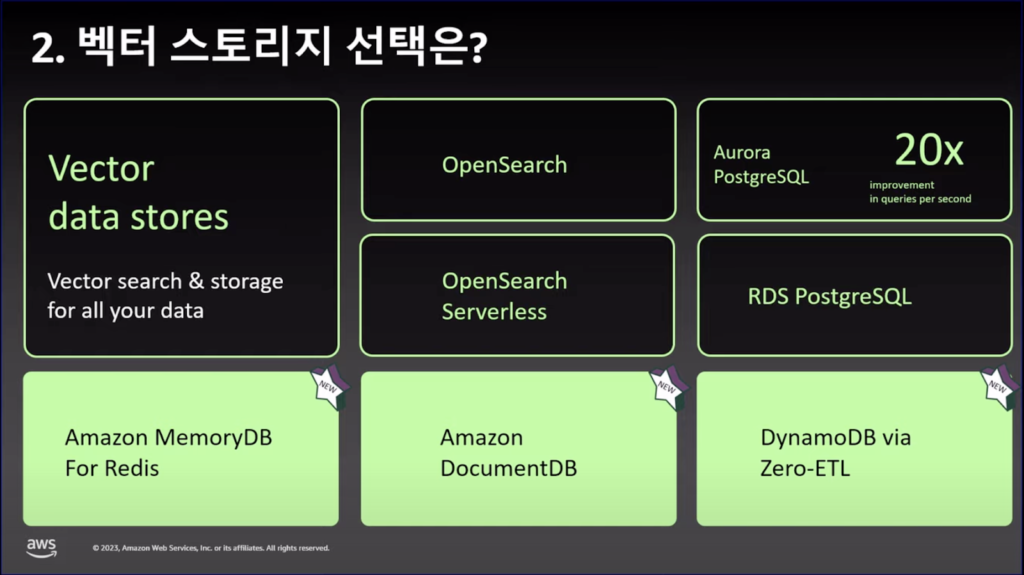
2.VectorDBが追加発表され、使用が可能。
3.ハングルモデルはBedrockではClaudeをよく使うし、オープンソースはMetaで作ったLlama2が一番スコアが高い。SLMを使う場合はKULLM、KoAlpaca、KoVicunaを多く使用中。
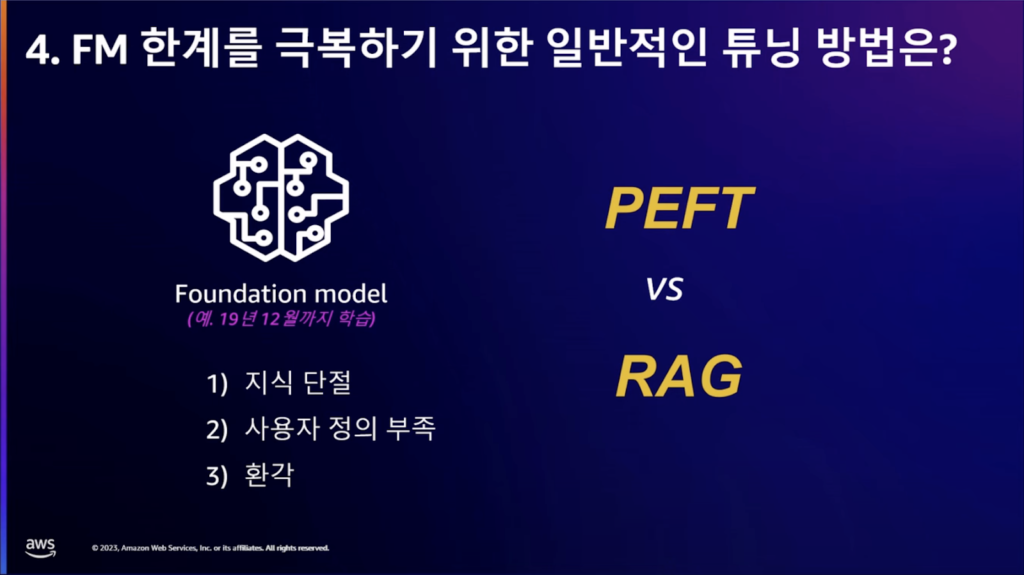
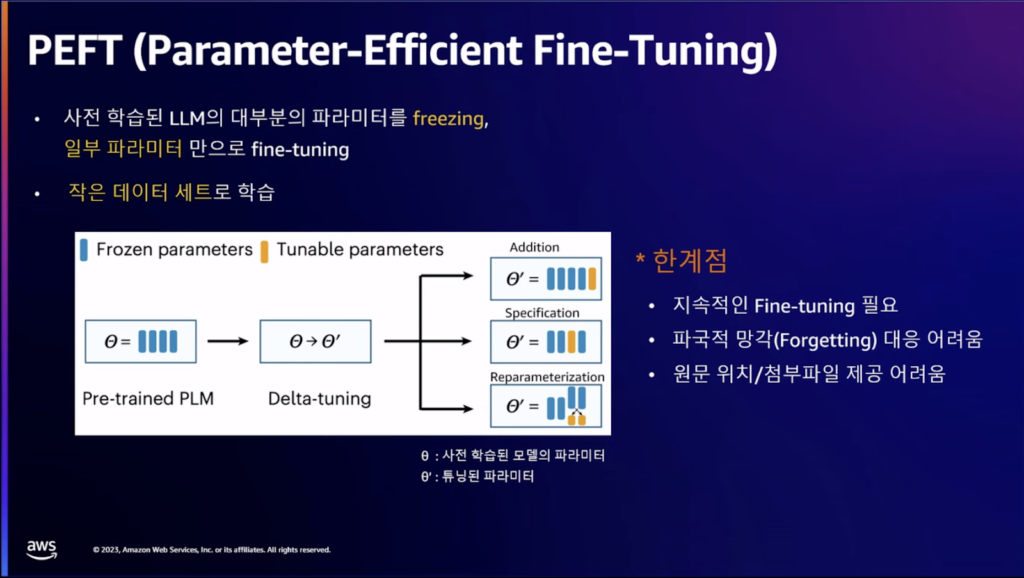
4.ファウンデーションモデルの限界を克服するためにRAG、Fine-Tunningを行うが、RAGはトークン数が増えるとコスト増加の懸念があり、検索エンジンを利用するため、レイテンシーも考慮しなければならない。Fine-Tunningはモデルを毎回ビルドして使わなければならない限界がある。
セッションを終えて
AIは発展し続けており、様々な産業群、企業への応用事例が出てきています。最近2ヶ月の間に速いスピードで発展していました。試行錯誤が急速に改善されているので、迅速な適用による活用が必要だと思います。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner