MEGAZONEブログ

A deep dive on AWS infrastructure powering the generative AI boom
ジェネレーティブAIブームを支えるAWSインフラを深掘りする
Pulisher : AI & Data Analytics Center チョ・ミレ
Description:実際の産業インフラにGenerative AIがどのように適用されてきたかを紹介するセッション
はじめに
最近、generative AIが興行中の環境で、実際の産業インフラにどのように適用されてきたかを知ることができると思い、申し込みました。 このセッションを通して、産業別にどのように開発されてきたのか、どのような側面から深く分析できるのか学ぶことができそうです。
セッションの概要紹介
AWSは、クラウドでモデルを教育し、デプロイするのに最適な場所です。 このセッションでは、AWSインフラストラクチャ全体のイノベーションを詳しく見て、AWSのお客様から、さまざまな製品やサービス全体で大容量テキストおよび画像生成モデルをどのように構築、デプロイ、拡張したかを知ることができます。
DL acceleration

- ASICはGPUよりも専門的です。 なぜなら、GPUは依然として数千の計算ユニットを備えた大規模な並列プロセッサであり、さまざまなアルゴリズムを実行できるのに対し、ASICは非常に小さな計算セット(たとえば、行列のみを実行できるように設計されたプロセッサ)であるためです。 しかし、それは非常にうまく機能します。
- しかし、ここで説明するASICのいくつかは、さまざまなタスク(AIにはニューラルネットワークだけでなく、さまざまな複雑なタスクがあります)を解決できるが、一般的ではない(現時点では)アーキテクチャを備えた汎用コンピュータです。
Nitro Systemの応用
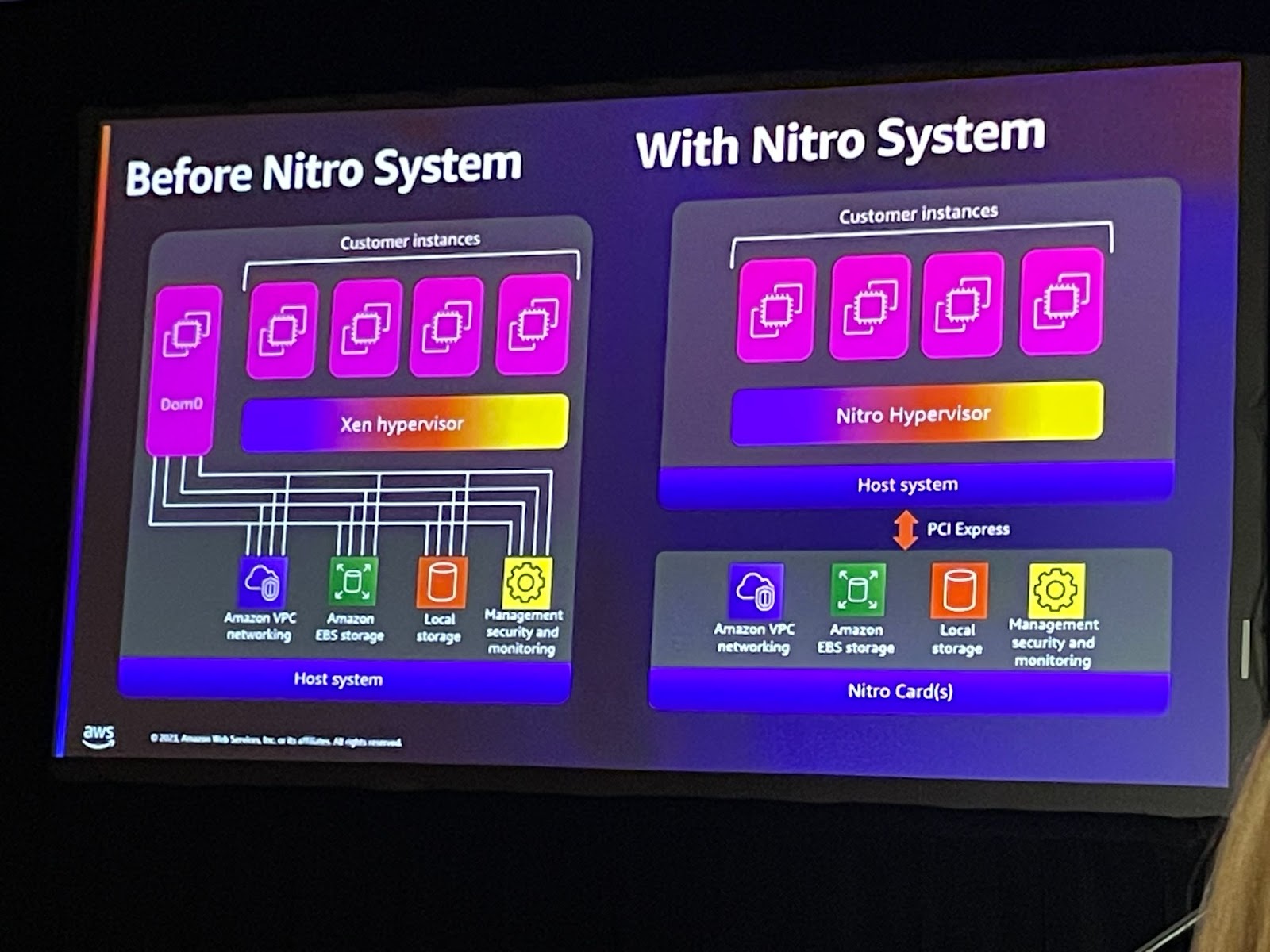
Nitro Systemは、さまざまな構成が可能な豊富なビルディングブロックのコレクションであり、幅広いコンピューティング、ストレージ、メモリ、およびネットワークオプションを選択することで、EC2インスタンスタイプを柔軟に設計し、迅速に提供することができます。 このイノベーションにより、お客様が独自のハイパーバイザーを構築したり、ハイパーバイザーを使用しないベアメタルインスタンスも実現します。
クラウドで最もパワフルなGPUインスタンス

最新のNVIDIA H100 Tensor Core GPUを搭載したAmazon Elastic Compute Cloud (Amazon EC2) P5インスタンスは、ディープラーニング(DL)およびハイパフォーマンスコンピューティング(HPC)アプリケーション向けに、Amazon EC2で最高のパフォーマンスを提供します。P5インスタンスは、ソリューションの反復を高速化し、市場投入までの時間を短縮するのに役立ちます。P5インスタンスは、最も要求の厳しい生成型人工知能(AI)アプリケーションをサポートする、ますます複雑化する大規模言語モデル(LLM)および拡散モデルのトレーニングと展開に使用できます。
Purpose-build accelerators for Gen AI(ML Accelerator)

inferentia : AWS Inferentiaは、クラウドで低コストで高性能なML推論を提供するためにAWSが設計したML推論アクセラレータです。AWS Inferentiaアクセラレータ基盤のAmazon EC2 Inf1 インスタンスは、比較可能なAmazon EC2 インスタンスに比べ、推論当たり最大70%低いコストで最大2.3倍の処理量を提供します。
Trainium
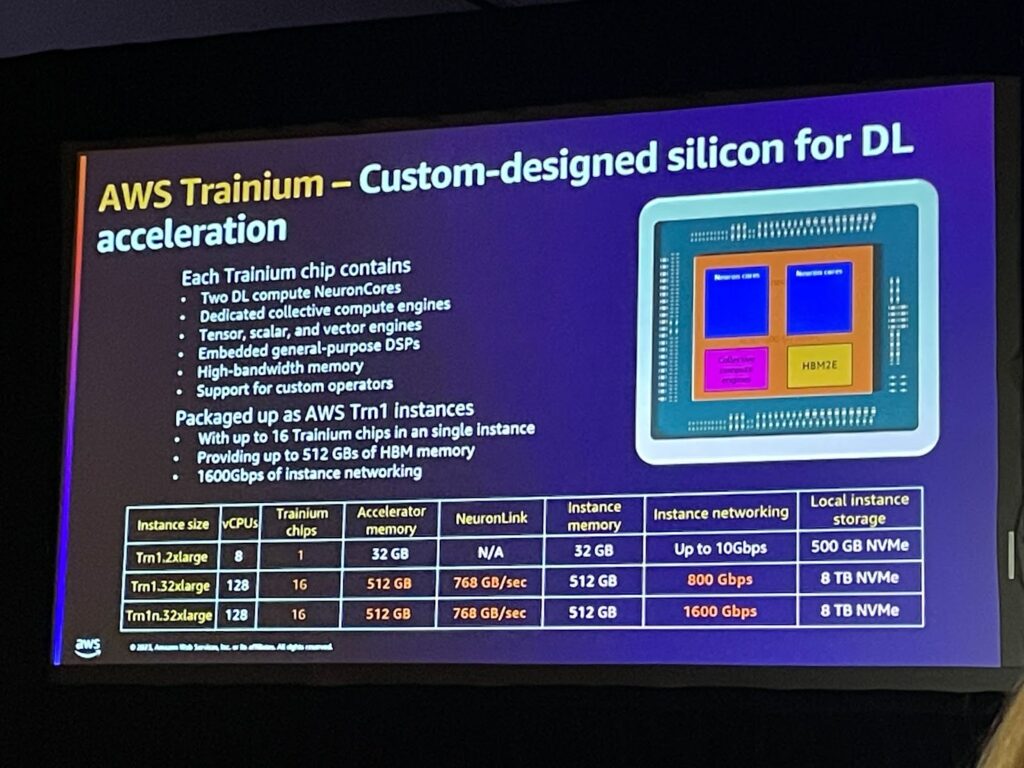
AWS Trainiumは、AWSが1,000億を超えるパラメータモデルのディープラーニング学習用に構築した目的別第2世代機械学習(ML)アクセラレータです。 Amazon Elastic Compute Cloud(EC2)Trn1インスタンスは、最大16個のAWS Trainiumアクセラレータを展開し、クラウドでのディープラーニング(DL)学習のための高性能ソリューションを低コストで提供します。
大規模で高レベルのノード間通信が必要な場合 : EFA

Elastic Fabric Adapter(EFA)は、Amazon EC2インスタンスのネットワークインターフェースです。 このインターフェースを使用すると、AWSで大規模かつ高レベルのノード間通信を必要とするアプリケーションを実行することができます。EFAは、カスタムオペレーティングシステム(OS)バイパス技術を使用して、インスタンス間の通信性能を強化します。これは、このようなアプリケーションをスケーリングする上で非常に重要です。EFAを使用すると、メッセージ転送インターフェース(MPI)を使用するハイパフォーマンスコンピューティング(HPC)アプリケーションや、NVIDIA Collective Communications Library(NCCL)を使用する機械学習(ML)アプリケーションは、何千ものCPUまたはGPUに拡張することができます。 これにより、オンプレミスのHPCクラスターのアプリケーション性能に加え、AWSクラウドのオンデマンドの弾力性と柔軟性を得ることができます。
Gen AIと連携するストレージとマネージドサービスをご紹介します

・storage:EBS(使いやすく拡張性の高いブロックストレージサービス), EC2, S3, Fsx(file server)
・manage : sagemaker(mlパイプラインの実装)、EKS, ECs, ParallerCluster, Batch
セッションを終えて
その結果、Gen AIを実装するためのコンピューティングコンポーネントについてdeep diveをしたような気がしました。 何度も話は聞いたことがありますが、サービスに対する概念が定立されていなかったのですが、リソースの構成や適用しようとするコンピューティングの処理内容がどの程度なのかを知ることができました。 今後もアップグレードされたバージョンがリリースされるでしょうが、コンピューティングリソース要素を無駄なく効率的に使えるようにスペックの内容を認識しておきたいと思います。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner