MEGAZONEブログ

Hybrid networking and HA edge infrastructure for manufacturing
製造業向けハイブリッドネットワーキングとHAエッジインフラ
Pulisher : Cloud Technology Center チュ・ジェビン
Description:エッジサーバーの多重化とエッジ-クラウドネットワーキングでHAを実装する方法についてのchalktalkセッション
はじめに
モノのデータをAWS IoT Coreに発行する構造で、AWS IoT Coreはマネージドサービスなので、このサービスの高可用性は私たちの管轄ではありません。 しかし、IoTモノと隣接する場所でデータの収集、変換、アップロードを行うゲートウェイソフトウェアが存在する場合、そのサーバーの可用性は私たち=担当エンジニアが責任を持つことになります。
エッジ領域で高可用性を構成する内容は、私がエッジ関連のIoT PoCを実施する中で考えていなかった部分ですが、この概念まで考えが及ばなかったからです。エッジサーバーの多重化とエッジ-クラウドネットワーキングでHAを実装する方法をこのセッションで紹介します。
セッションの概要紹介
エッジコンピューティング(Edge Computing)とは、IoTモノとより近い位置でデータ処理と保存を行うコンピューティング方式です。物理的な近接性は、より低いネットワーク遅延でデータをリアルタイムに処理することを意味し、処理結果のサイズが比較的小さいため、クラウドへの伝送帯域幅を節約できるなどの利点があります。
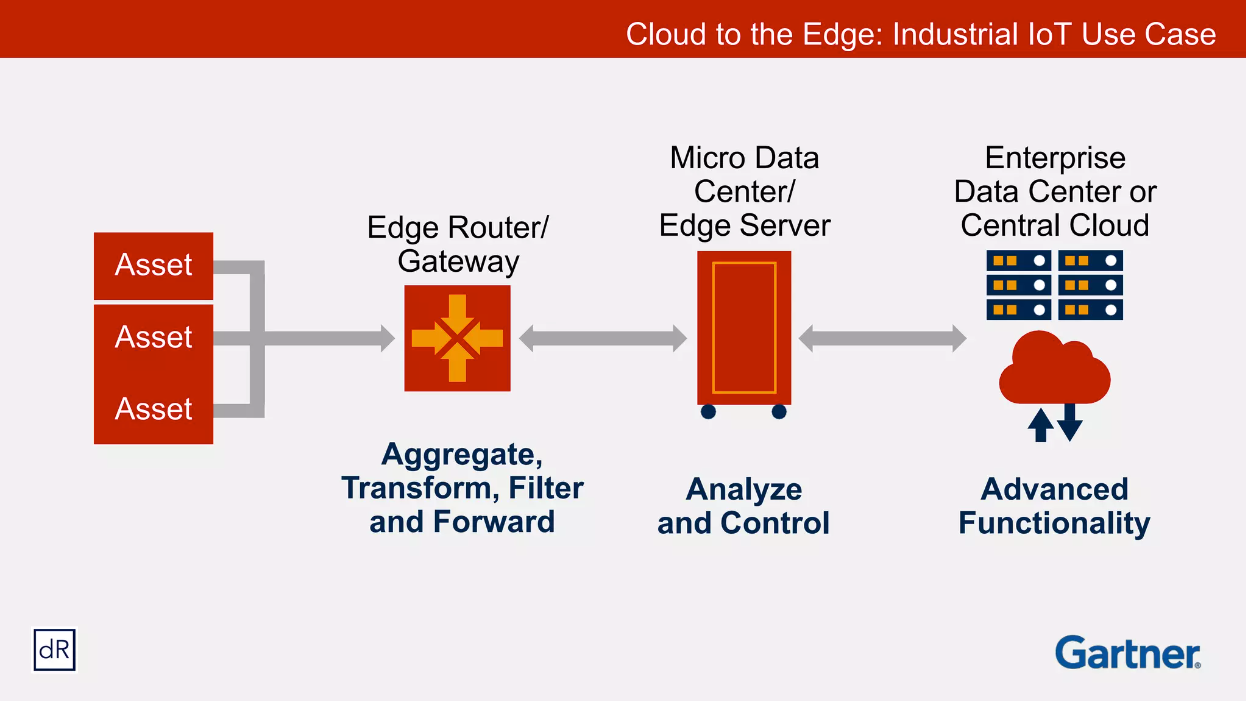
(出典: 2017 Gartner)
エッジサーバーでデータ収集と伝送に使用されるプロトコルやハードウェア構成は様々ですが、PLC機器、SCADA、EMQX程度を挙げることができます。 エッジ実行基盤は一般的なPCサーバーと考えてもいいですし、AWSのSnow familyに属するAWS Snowball、AWS Snowball Edge、AWS Snowcone、最後にAWS Outpostsを考慮することも可能です。
高可用性チャレンジ

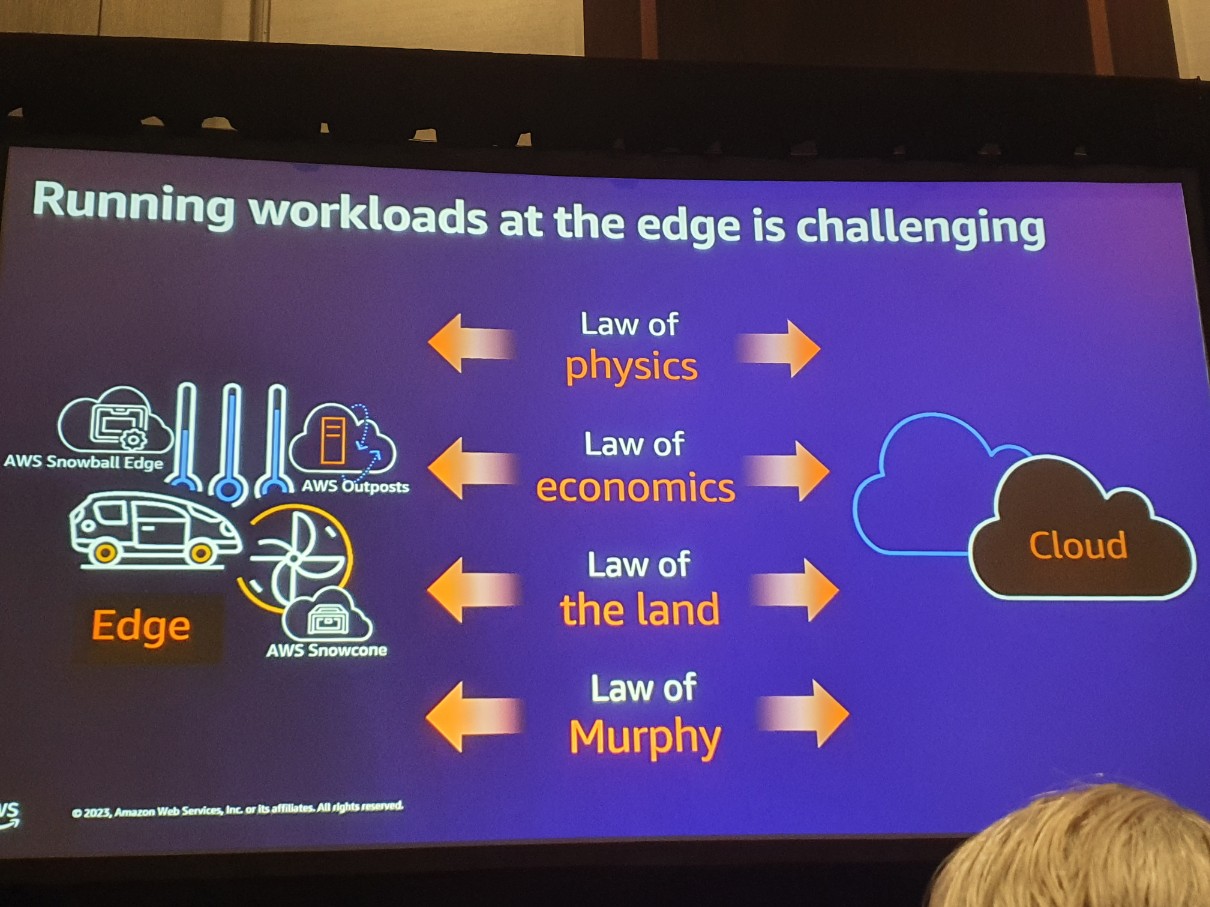
エッジでは、物理法則(データ伝送の物理的限界など)、経済的な理由、国が強制するコンプライアンス、マーフィーの法則(とても面白い冗談でした)などが作用し、アーキテクチャ構成時に解決すべき課題が存在します。このような状況で、サービスの高可用性を保証するためにサービスレベル契約(SLA)を設定することになります。

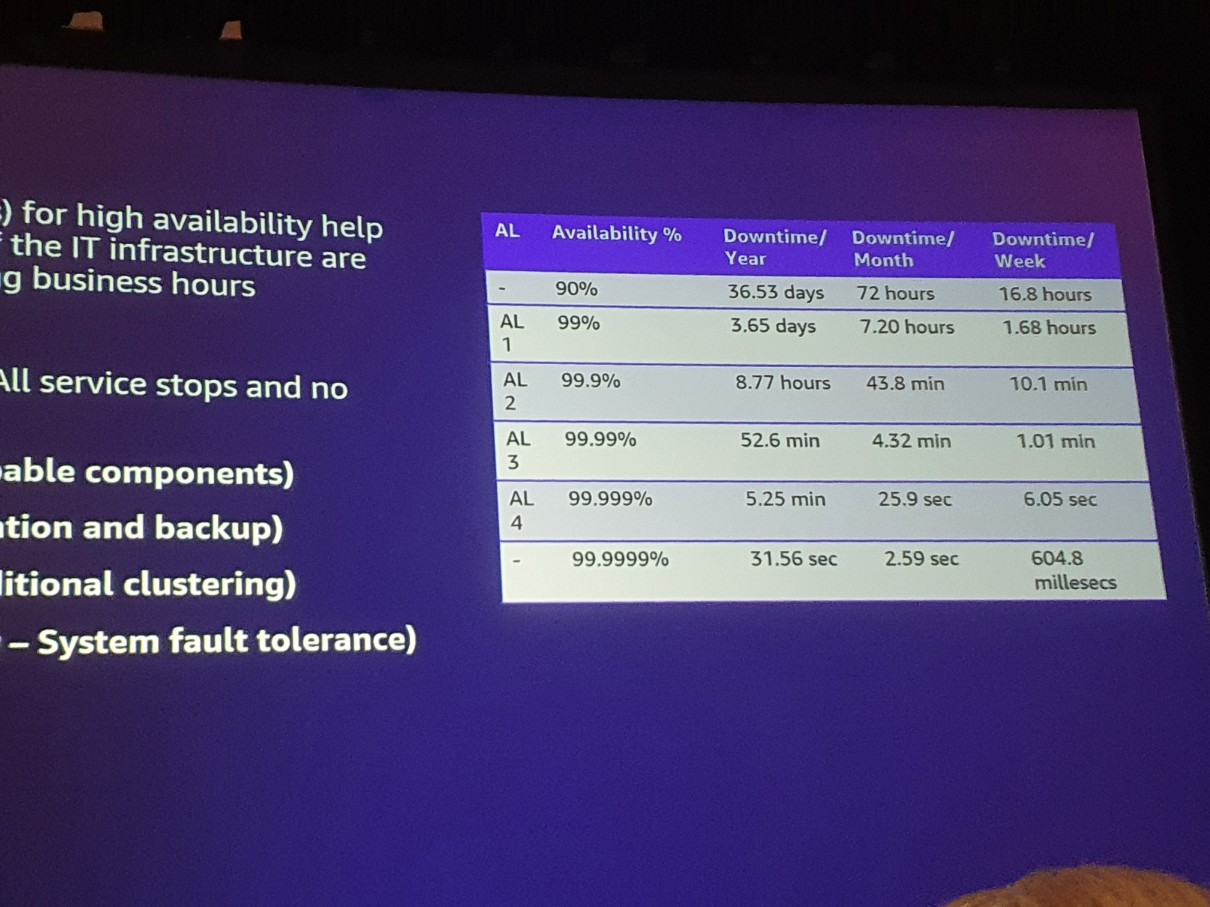
上記2章の表で、サービスレベル契約のAgreement Levelに応じて、1年、1ヶ月、1週間単位で予想されるサービスダウンタイムをご確認ください。
高可用性の実現

アーキテクチャに可用性を追加するために、1)同じSW、HWの予備を用意し、2)単一障害点として作用するコンポーネントを排除し、3)障害状況や反応をモニタリングする施設を用意し、4)復旧措置にかかる時間と復旧点が明確に識別されなければなりません。
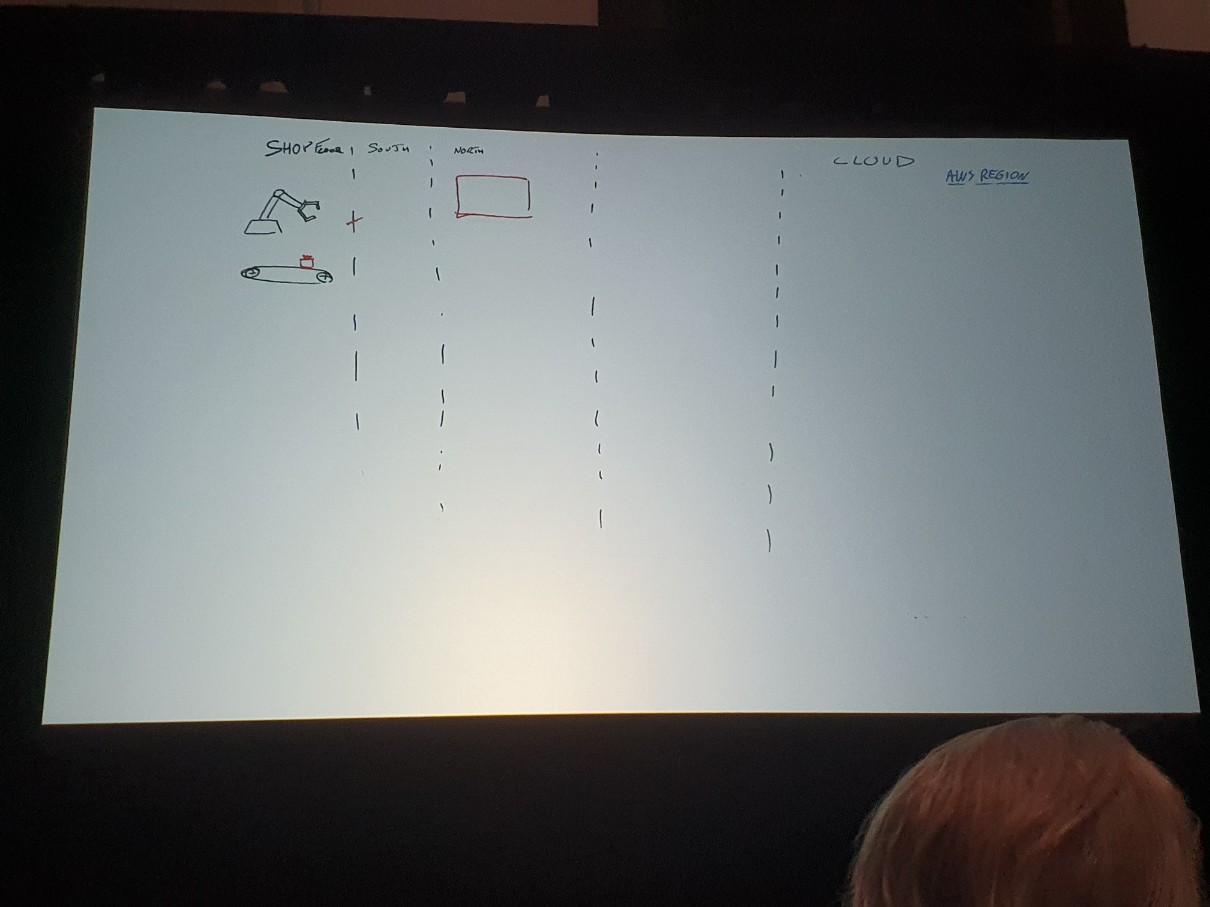
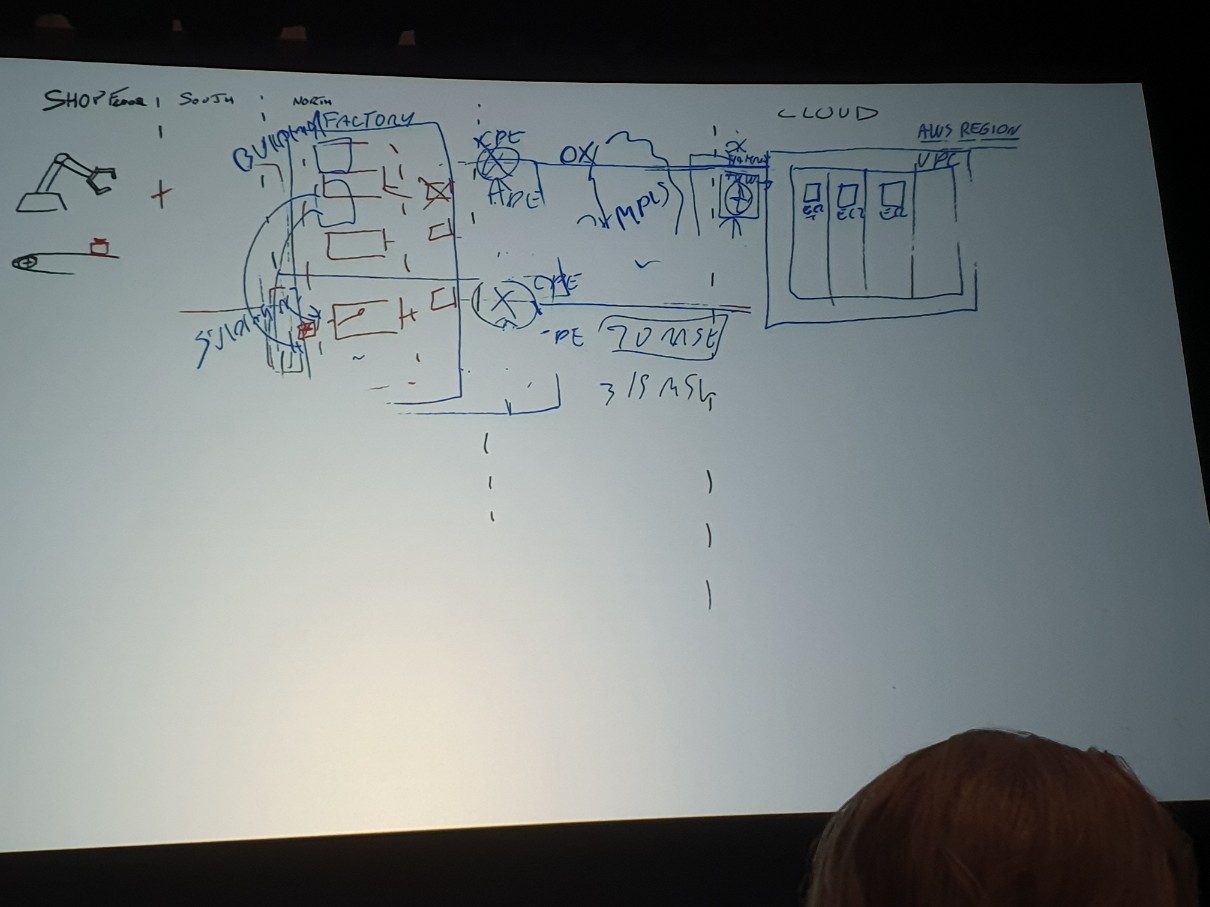
このような原則に触れながら、ホワイトボーディングが始まります。ロボットアームとコンベアはIoTモノであり、OPC-UAプロトコルでこれらから運用データを読み取ります。現在、赤いボックスがエッジサーバーでありOPC-UAクライアントであり、OPC-UAサーバーからデータを取得し、AWSクラウド(AWS IoT Core)にデータを送信する役割を担っています。 現在、単一障害点です。
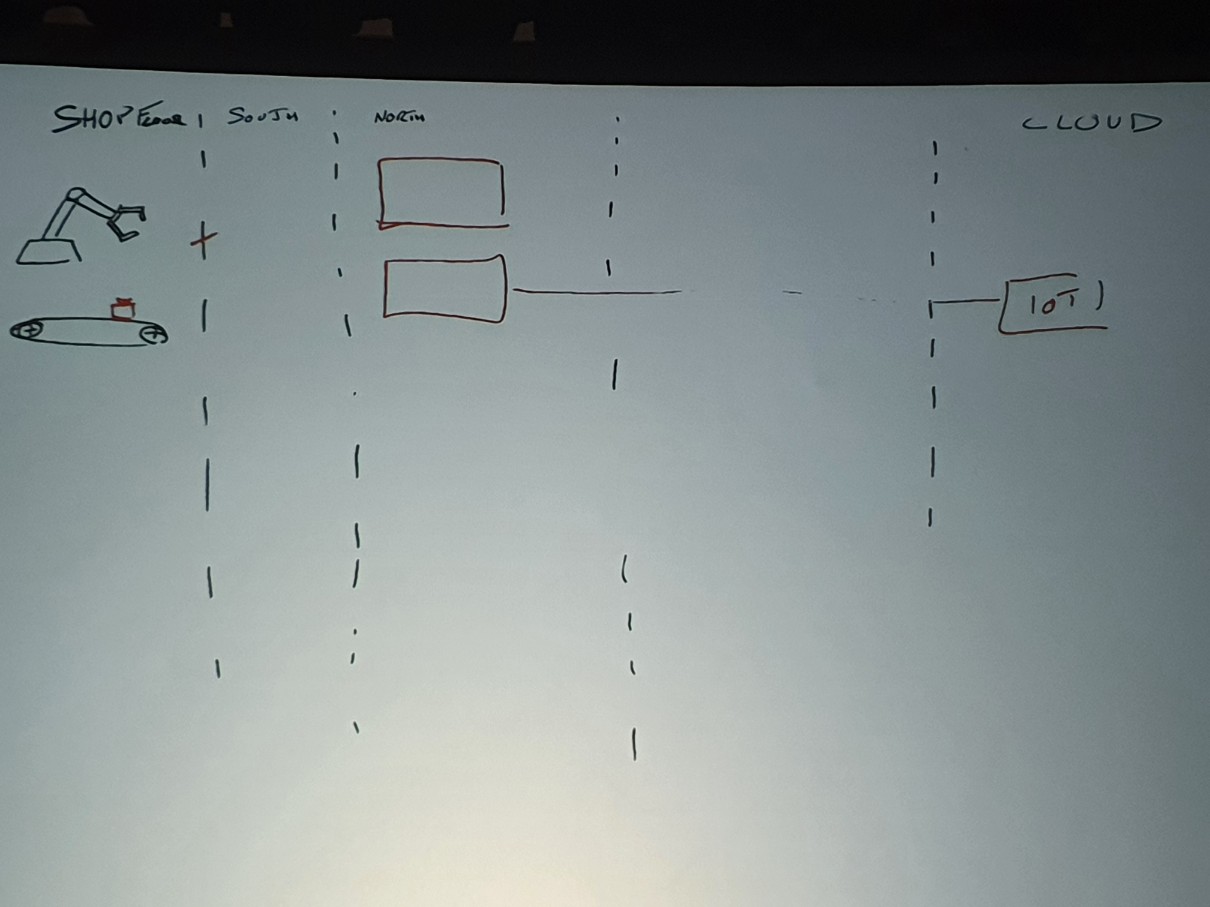
次の段階でエッジサーバーをもう1台追加します。この状況でAWS IoT Coreと接続するエッジは一つなので、Active – Passive設定です。私たちは現在のエッジサーバーのヘルスをチェックし、障害時にフェイルオーバーするように別途実装する必要があります。ただし、IoTデバイスはOPC-UAサーバーなので、クライアントの障害に無関心であることを認識してください。
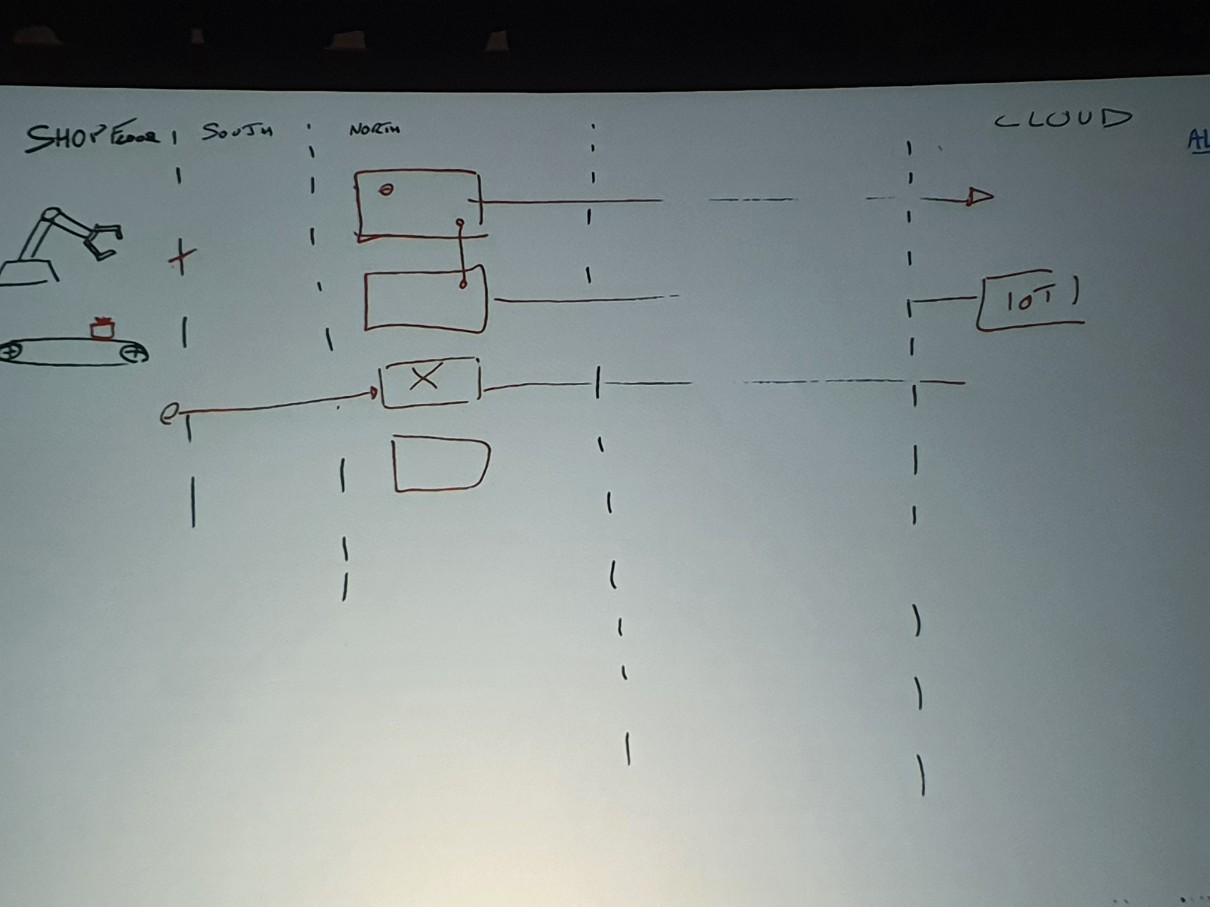
次の図です。上の2つのエッジサーバーに接続線が1本ありますが、この2つがActive-Activeとして動作していることを表示します。AWS IoT Coreと接続された2つのサーバーのためにメッセージが重複するため、メッセージ消費者はDe-duplicationロジックを必ず実装している必要があります。
注意点として、同図の3、4番目の四角いボックスからは、OPC-UAではなく、MQTTプロトコルでIoTデータを摂食するエッジサーバーを発表者が示したものです。
MQTTを利用する場合、OPC-UAの「サーバ-クライアント構成」とは逆の状況になります。IoTモノがMQTTブローカーであるエッジサーバーにメッセージを送信する仕組みです。 高可用性を実現するには、IoTモノは少なくとも2つの異なるMQTTブローカーのエンドポイントを知っている必要があり、障害時に正常なブローカーを選択するためのロジックが必要です。
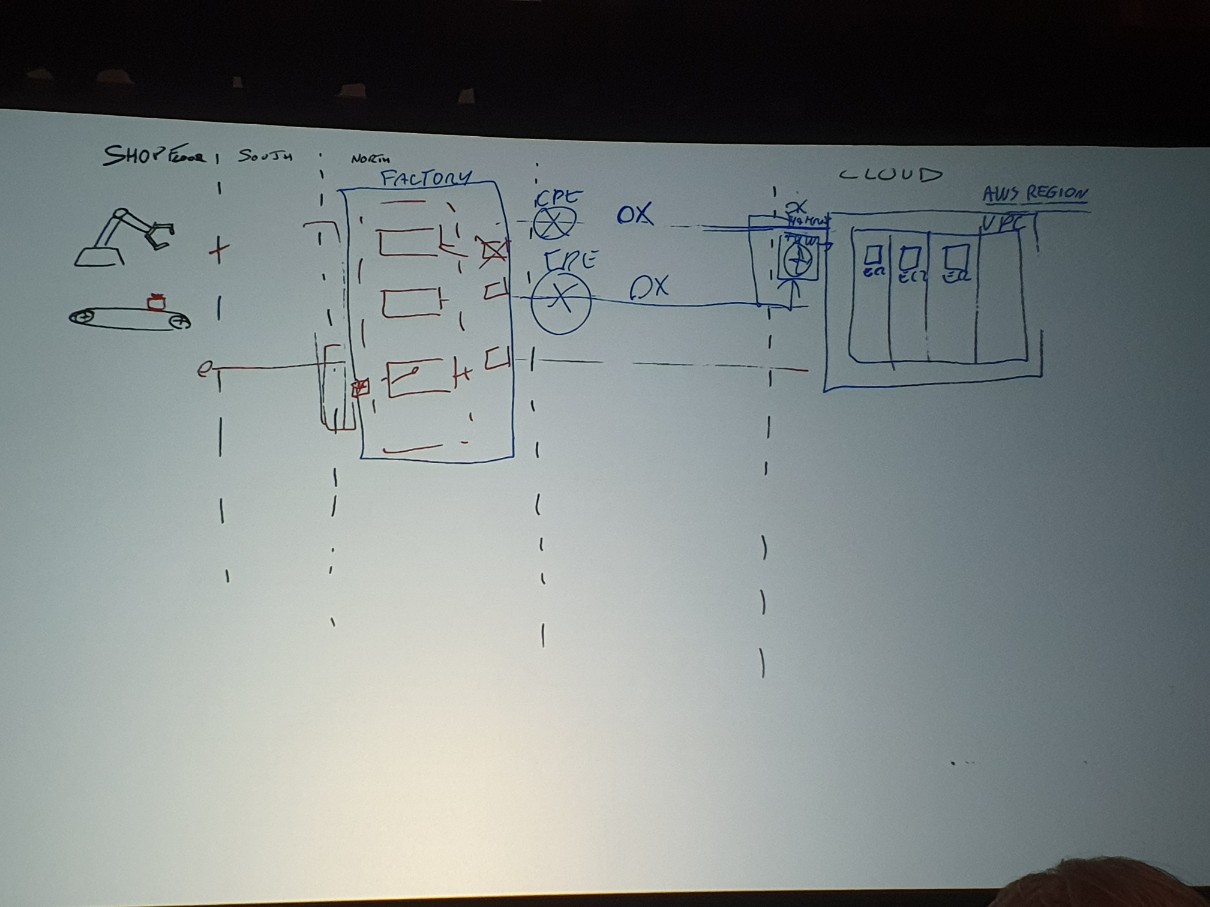
このようなロジック開発を排除する方法も紹介されました。 MQTTブローカーをグループ化し、MQTT5の共有トピックサブスクリプション(Shared Subscriptions)を使用することです。 これにより、障害のあるブローカーはグループから除外されるため、正常なブローカーのうちランダムな1つにメッセージが転送され、最終的にAWS IoT Coreに到達させることができます。
エッジとクラウド間のネットワーク多重化には、DX接続多重化で実現します。社内ネットワーク網を分離し、すべてのMQTTブローカーを同じ社内網に置かない状態で、それぞれAWSクラウドとDXリンクを確立し、SiteLinkを適用し、社内網の通信問題時、AWSクラウドを経由してトラフィックの流れが引き続き維持できるようにすれば、高可用性アーキテクチャを構築することができます。
。
セッションを終えて
このセッションは、SLAの概念と、可用性の4つの満足フィラーを紹介し、High Availabilityアーキテクチャ構成が要求される理由と対応策を簡単に紹介することから始まりました。
エッジサーバーを多重化して可用性を確保しつつ、プロトコル特性によってメッセージの摂食構造が異なり、それによって障害対策に必要なロジックが異なる可能性があることを説明しました。 (OPC-UAサーバーとクライアントの構造と、MQTTの発行/購読構造)一方、エッジとクラウド間のネットワーク接続に可用性を付与する方法についても説明しました。
アプリケーションが送信するデータが当該ビジネスで占める重要度に応じて、HA構成に対するSLAレベルが要求されるでしょう。 このセッションで学んだ高可用性アーキテクチャと悩みどころを熟知していれば、関連要件に対応することができそうです。
このセッションは、発表者が徐々に要件を拡大しながら、聴衆との質疑応答を基に進行したホワイトボード(チョークトーク)セッションだったので、非常に良い学習構造を有していると感じ、最も記憶に残りました。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner