MEGAZONEブログ

Use data catalogs to improve self-service analytics
データカタログを使用してセルフサービス分析を改善する
Pulisher : AI & Data Analytics Center チェ・スンヒョン
Description :Data Catalogを利用してデータ資産を検索し、理解する方法について紹介するwrokshopセッション
はじめに
プロジェクトを進めながらGlueとGlue Catalogを様々な面で使ってきました。データガバナンスが重要になってきて、最近追加されたData Zoneを実際にテストしてみると、今後のCatalog権限に関する業務を行う際に参考になりそうなので、このセッションを申し込みました。
セッションの概要紹介
このセッションはBuilders’ SessionでWorkshopセッションと似た形で行われました。 実際にカタログをどのように管理し、DataZoneを通じてアクセスし、Redshiftでどのように活用できるのか、テスト環境が与えられ、1時間の間その内容を進める形で構成されました。
1.データベースの生成:まず、Glueでカタログを利用するためにDatabaseを生成します。
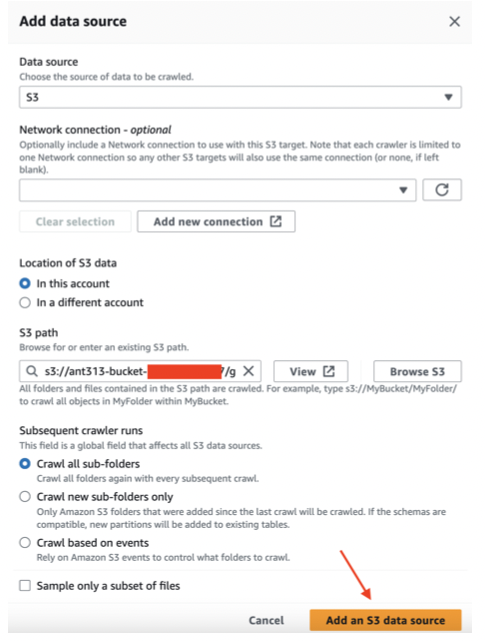
2.データソースの追加
Glue Crawlerを活用してS3に保存されているデータをカタログに登録することができます。
Crawlerを実行すると、S3にあるファイルを読み込んで内部でカラム、データ型、保存パスなどの情報をメタデータとして保存し、Athenaや外部からデータをクエリできるように構成してくれます。
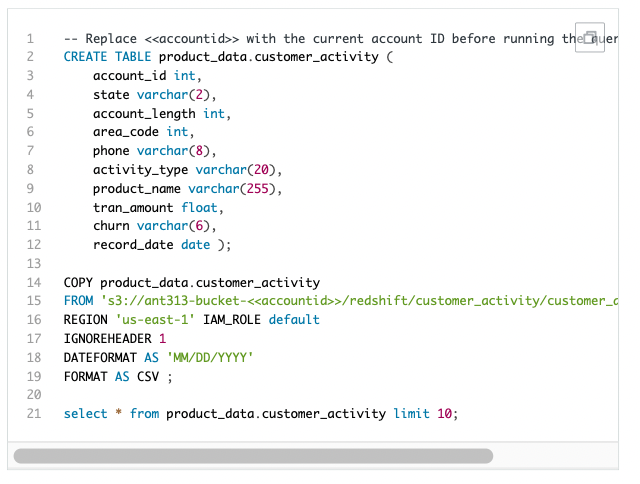
3.Redshiftにテーブルを生成した後、S3ファイルをCopy IntoS3にあるファイルをRedshiftにCopy intoしてデータを挿入することができます。代わりに先に生成したRedshift Tableのカラム構造とCopy into対象S3ファイルの構造が同じでなければなりません。
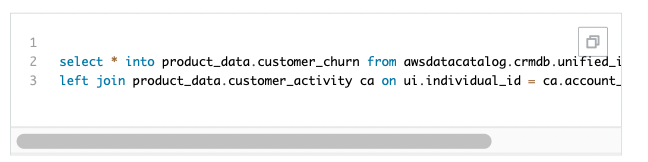
4.Glue Catalog Tableと結合して分析RedshiftでSpectrumを生成しなくても”awscatalog”を活用してGlue Catalogに構成されているテーブルを照会することができます。
DataZoneサービスは、データ生産者と消費者間のデータを公開、購読できる環境を作ります。 各権限と需要に合わせてDataZoneにアップロードされているデータを購読して活用することができます。
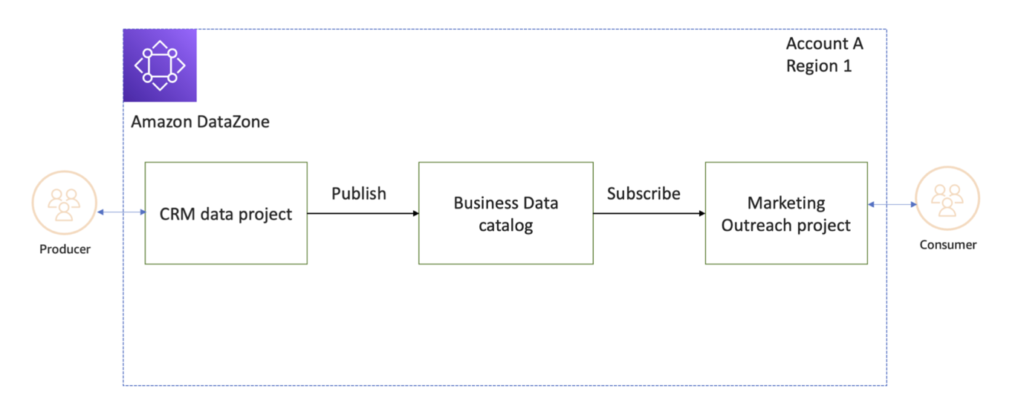
1.データをサブスクライブできる環境を作成
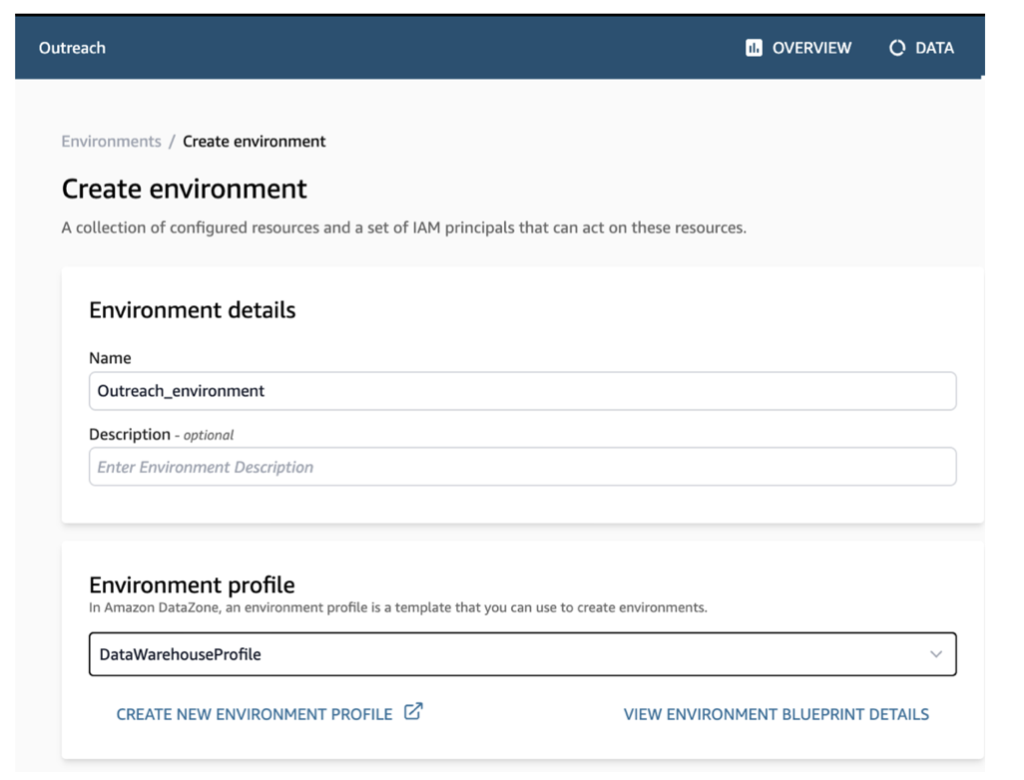
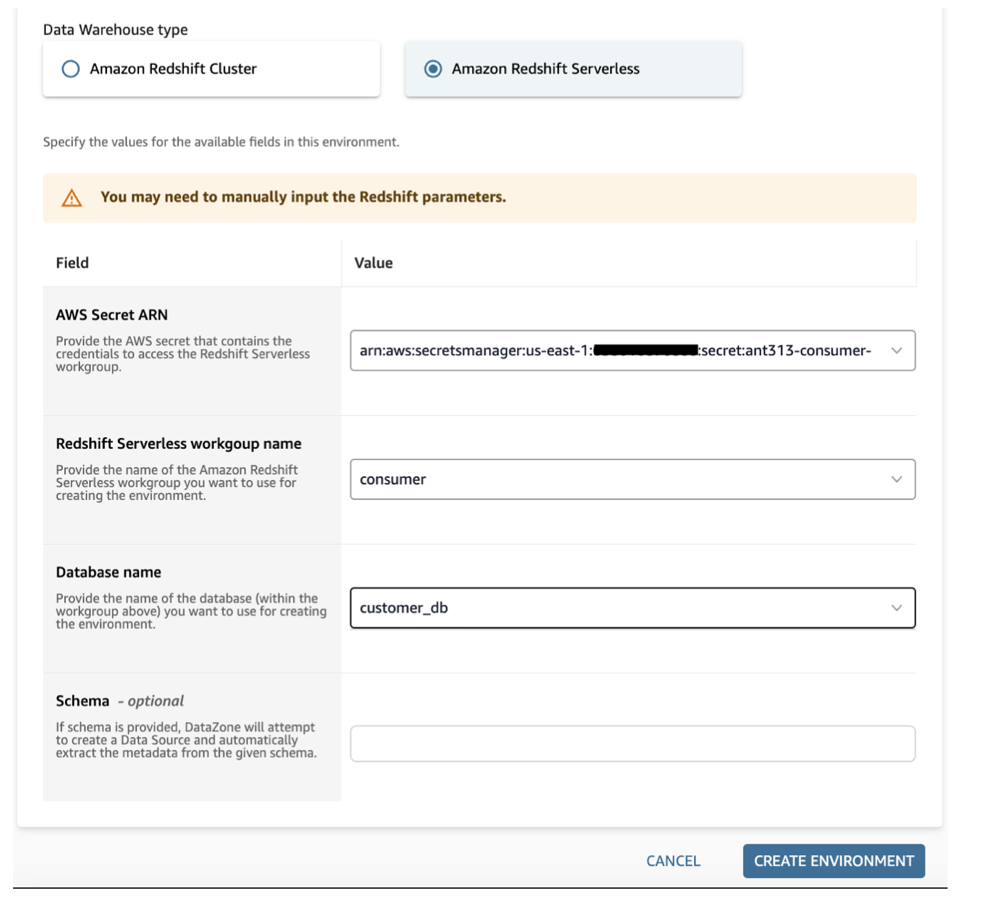
プロバイダの立場でデータが保存されているRedshiftを活用してDatazoneに環境を生成します。環境が生成された後は、DataZoneで該当データベースのサブにあるテーブルリストを照会することができます。
2.データ消費者の立場でサブスクリプションを要求する
データサブスクライバの立場で環境内に上がっているデータを活用するため、登録されているデータに対してサブスクリプションを要請します。
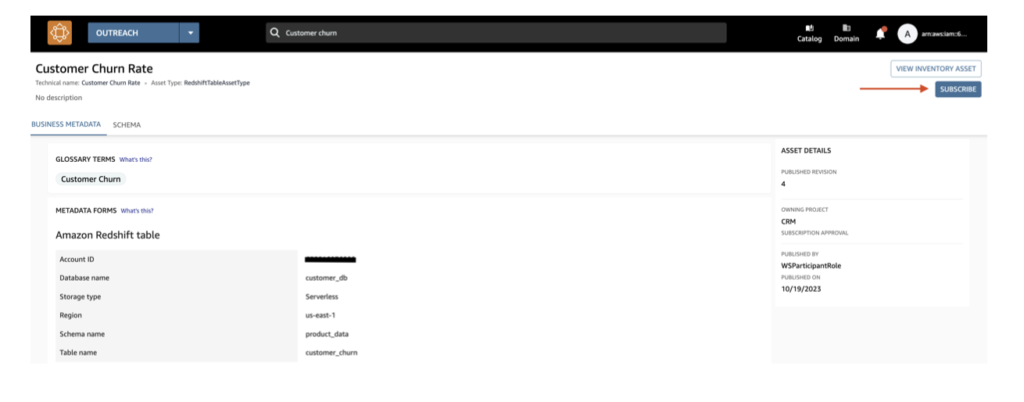
3.サプライヤーの立場でサブスクリプション要求を承認します
データプロバイダーが受信したリクエストを承認した場合、その後、消費者にアラームが送信され、そのデータセットを活用することができます。
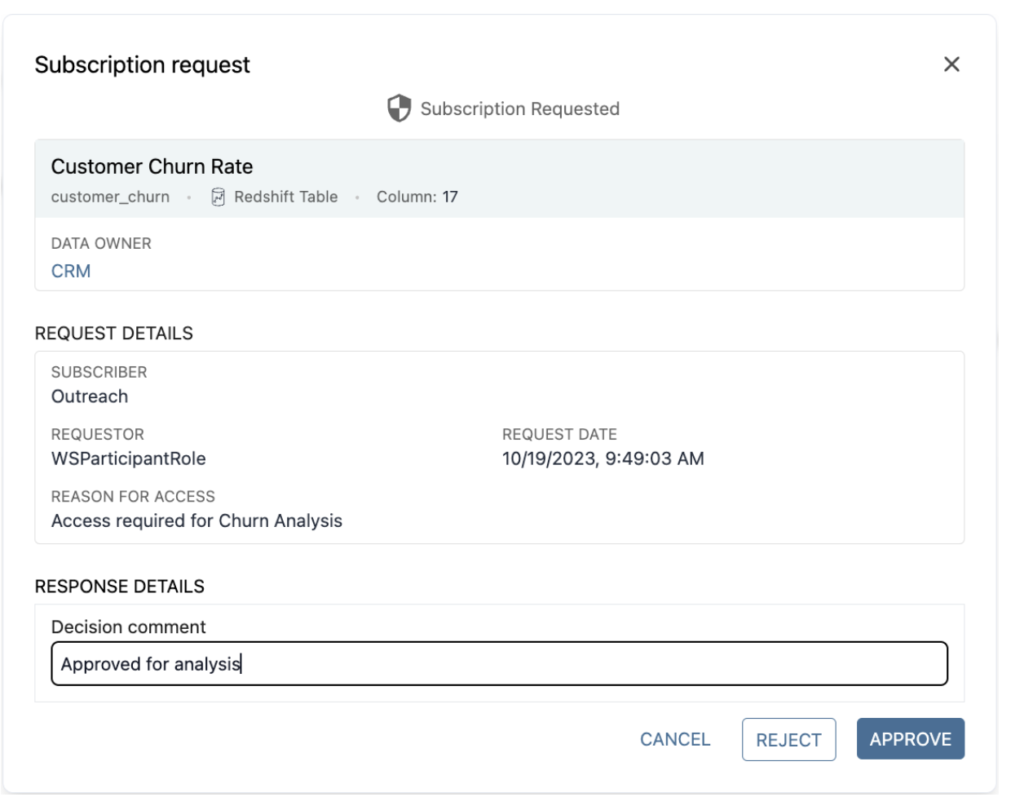
4.購読したデータを活用して分析します
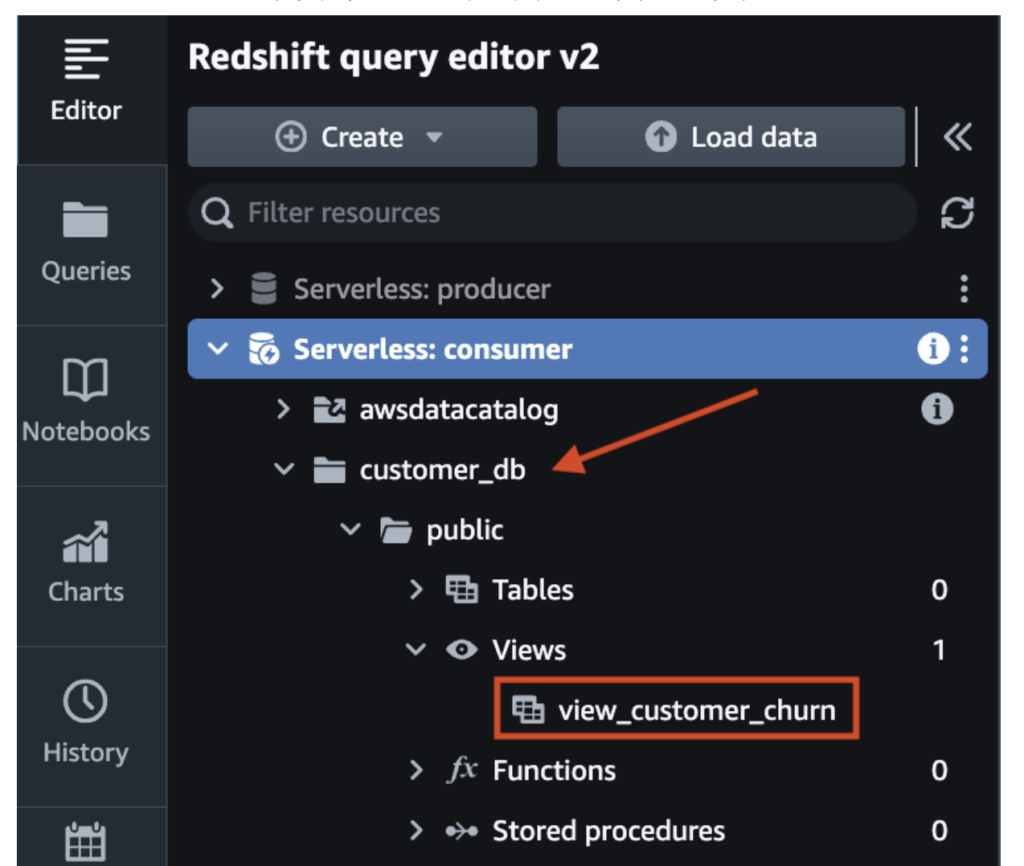
サブスクリプションが完了すると、Datazoneで下記のようにRedshiftに接続できるウィンドウが表示され、Redshiftに接続された後、サブスクリプションしたデータセットがViewの形で照会できる環境が構成されます。
セッションを終えて
最近リリースされたDataZoneを実際に実践できる環境を使ってみることができました。Data Meshアーキテクチャの観点から、データプロバイダーと消費者、データ商品の概念が溶け込んでいるサービスだと思いました。今後、活用する事例が増え、サービスが整理されれば、様々な面でaws内のデータガバナンスを整理するのに活用できそうです。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner