MEGAZONEブログ

Simplify working with data acrosss multicloud with AWS analytics
AWSアナリティクスでマルチクラウドでのデータ処理を簡素化
Pulisher : Cloud Technology Center キム・ビョンジュ
Description:AWS Data分析サービスがマルチクラウド上でどのように運用されるかについてのセッション
はじめに
マルチクラウドは最近になってかなり注目されているテーマであると同時に、避けて通れない課題です。AWSには多少多様で良いサービスを保有していますが、残念ながら顧客の使用事例がこれに適していない場合が存在します。 そのため、顧客は外部サービスやオンプレミス、他のクラウドベンダーにデータを保管して使用しています。
このような問題をどのようにアプローチして解決するのか確認するためにこのセッションを申し込みました。
セッションの概要紹介
このセッションでは、AWSの代表的なデータ分析サービスであるサーバーレスサービスであるGlue, Athenaを使ってこのような問題を簡単に解決できることを示しています。このセッションでは実際にsnowflake、google bigqueryのデータをAthenaで照会し、GlueではAzure Lake storageからデータを追加で取得して統合するプロセスを紹介します。

一般的にマルチクラウドアーキテクチャーで悩むポイントは、レイテンシー、データ複製、ソースデータ分析の3つが挙げられます。 最終的には、データの複製がなくても、他のソースのデータを分析してAWSで使用できるようにすることが私たちの目標です。

Amazon AthenaはAWSの代表的なサーバーレスSQL分析システムです。Athenaを使用するためには、特別な設定が必要なくすぐに使用することができ、複数のデータタイプやフォーマットをサポートし、AWSでインフラを管理するため、性能に対する設定も必要ありません。 また、クエリに対する費用は、データのスキャン量に比例して請求される構造で、ファイルを圧縮して使用すれば、より低コストでAthenaを利用することができます。

Athenaは30+以上のデータソースコネクタを提供し、これにはAzure Data Lake Storage Gen2, Azure Synapse, SAP HANA, Oracle, Snowflake, Teradata, DB2,…など様々なオプションを提供すると同時に簡単に設定できるようになっています。

GlueはOpen Source Sparkベースのサーバーレス分析サービスで、ノートブックベースのソースコード開発およびテスト環境をサポートし、Glue Studioを通じてNo CodeベースでSparkコードを作成することができます。 また、サーバーレスで使用した分だけ課金され、パフォーマンスを簡単に調整することができます。

Glue notebook環境で最近話題になっているAI関連技術も一緒に使ってみることができます。Glue notebookはAmazon CodeWhispererと結合されており、これはnotebookでコードを書く時、単純にコメントを書くだけでサンプルコードを作成してくれます。
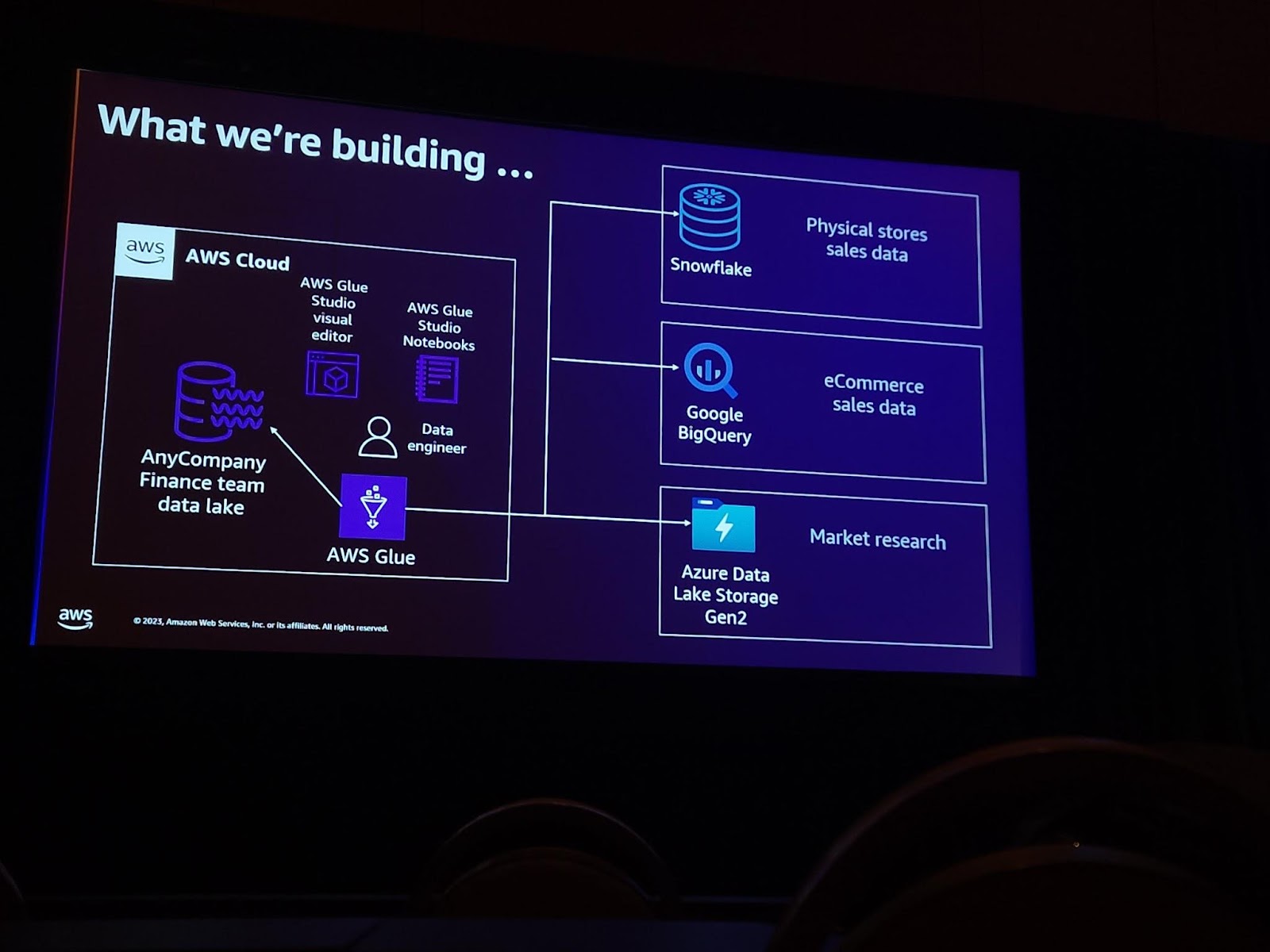
解決したい状況を想定してみましょう。 当社のデータ分析チームはAWS Cloudの使用に慣れており、様々なデータを一箇所に集めて分析したいと思っています。しかし、現在のお客様の状況は、代理店の販売データはsnowflakeに、eコマースデータはBigQueryに、市場分析資料はAzure Data Lake Storage Gen2に保管されています。
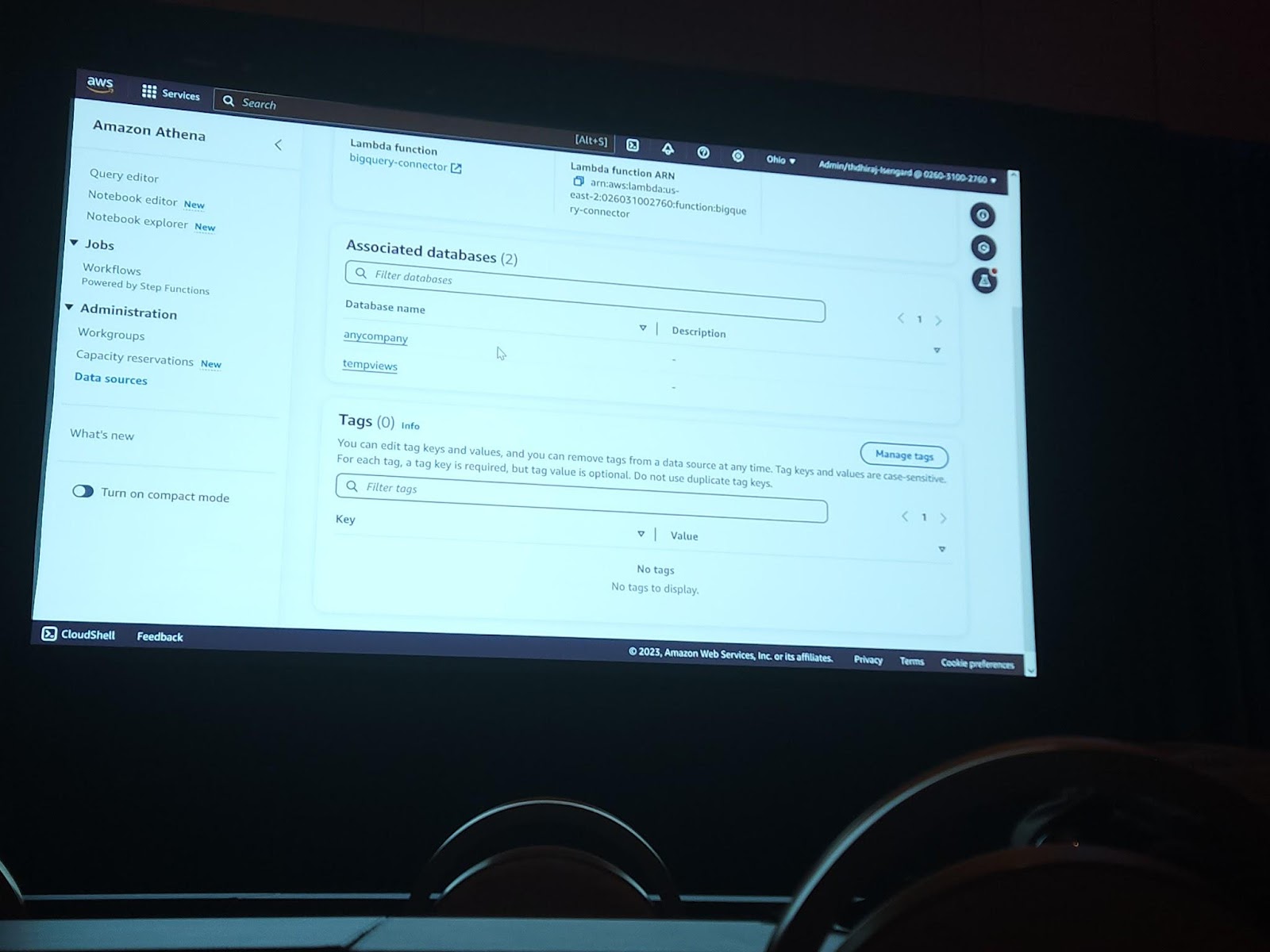
Athena > Data source タブでData connectionを生成することができます。生成されたconnectionを通じて接続されたデータベースに関する情報も写真のように確認することができます。
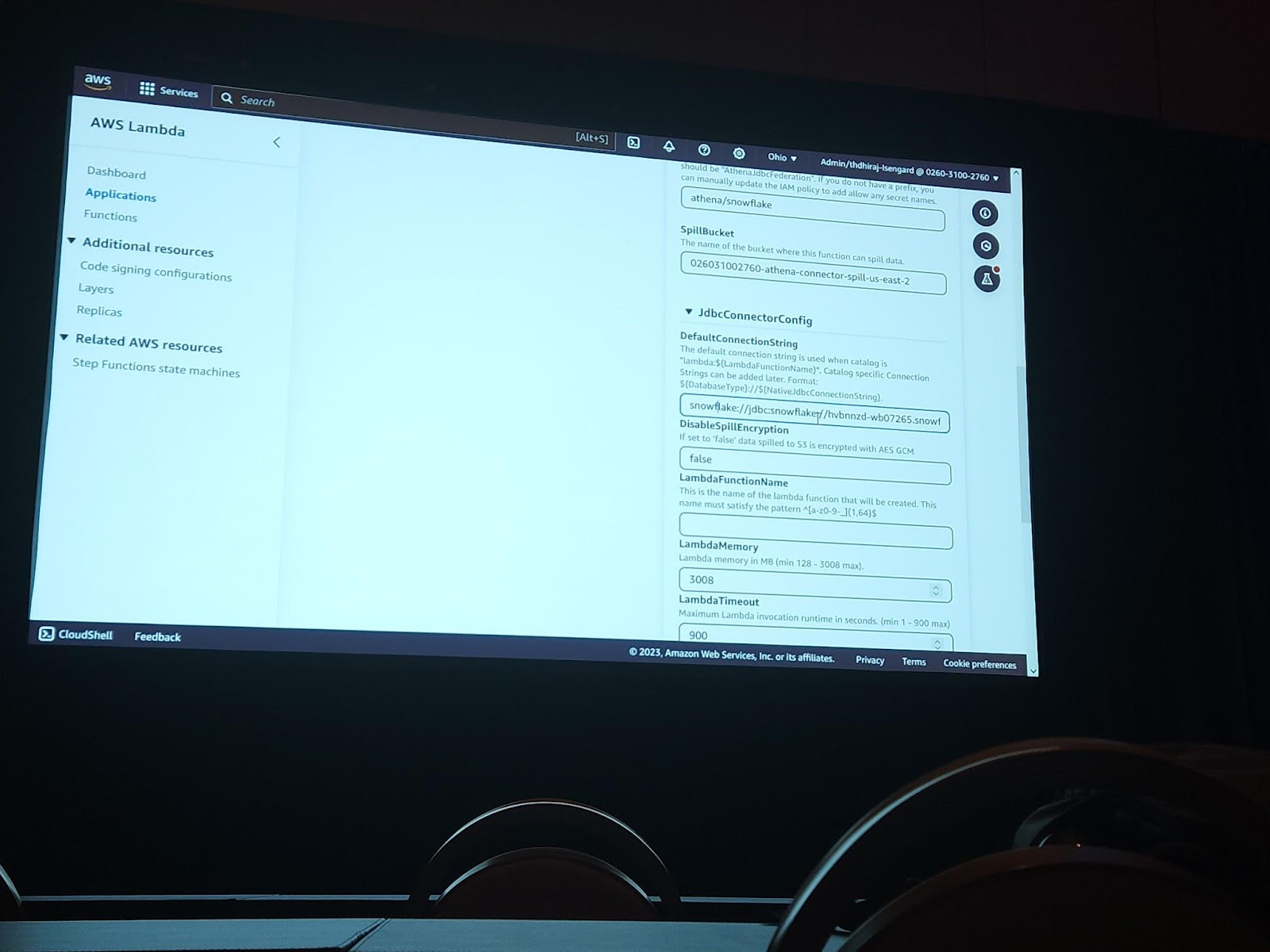
上の写真は実際にsnowflake <> Athena connectionを生成する過程の一部を撮影した写真です。 実際は、connectionごとに要求する情報や仕様が違うので、この部分は注意して設定する必要があります。
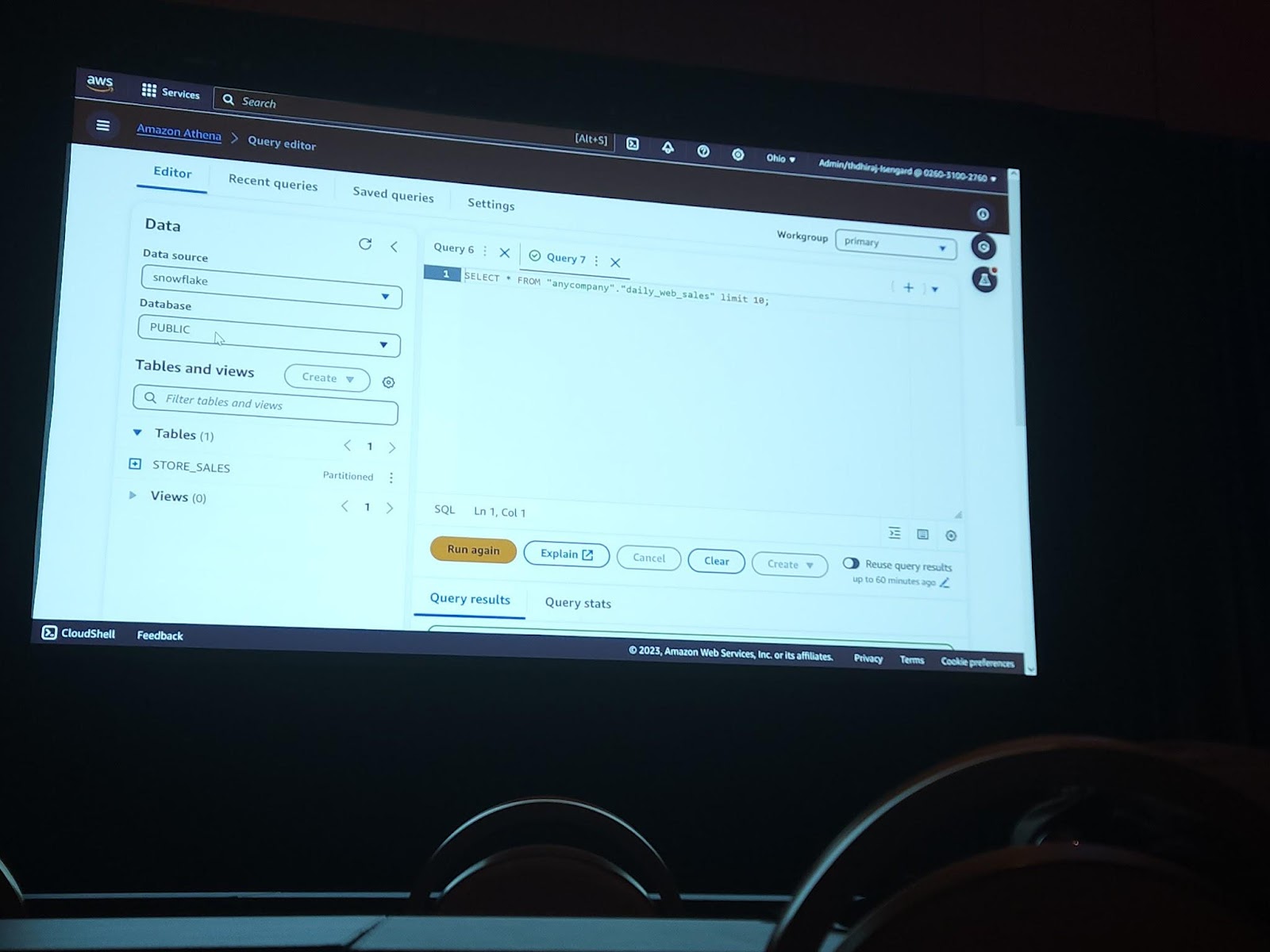
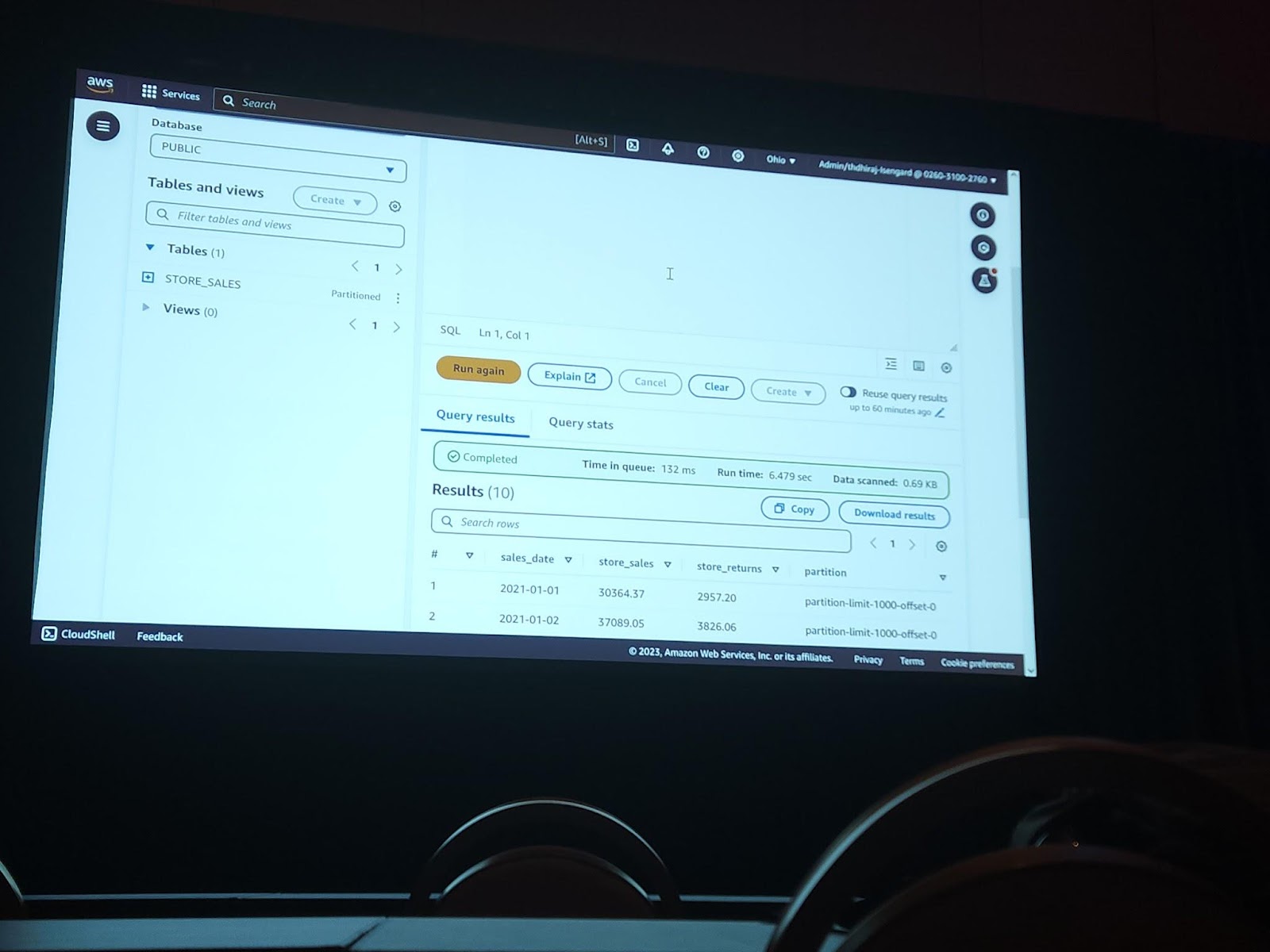
上の二つの写真は実際に接続されたsnowflake accountのデータをAthenaを使って検索するシーンです。バックグラウンドではAthenaが直接データを取得する構造ではなく、Cloudformationを通して生成されるLambdaが該当データベースやソースのデータやメタ情報を取得する方式で構成されてるので、Lambdaが持ってる多少の制約に従うことができます。ただ、データがLambdaのメモリサイズを超える場合は、S3にそのデータを一時的に保存して使います。
次はGlueを使ってそのデータを分析してみます。
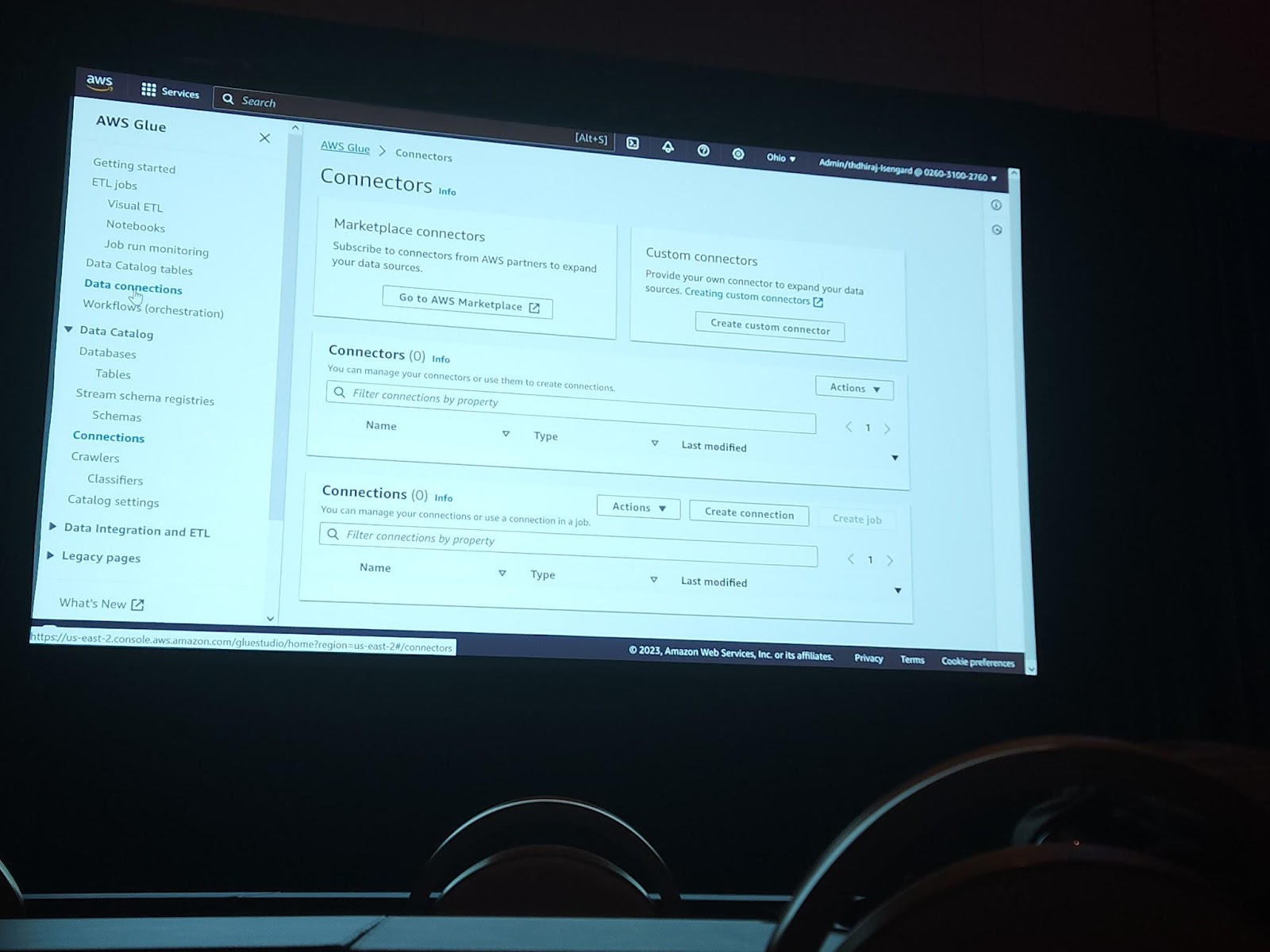
上記は、コネクタを作成するシーンの一部を写真に残したものです。
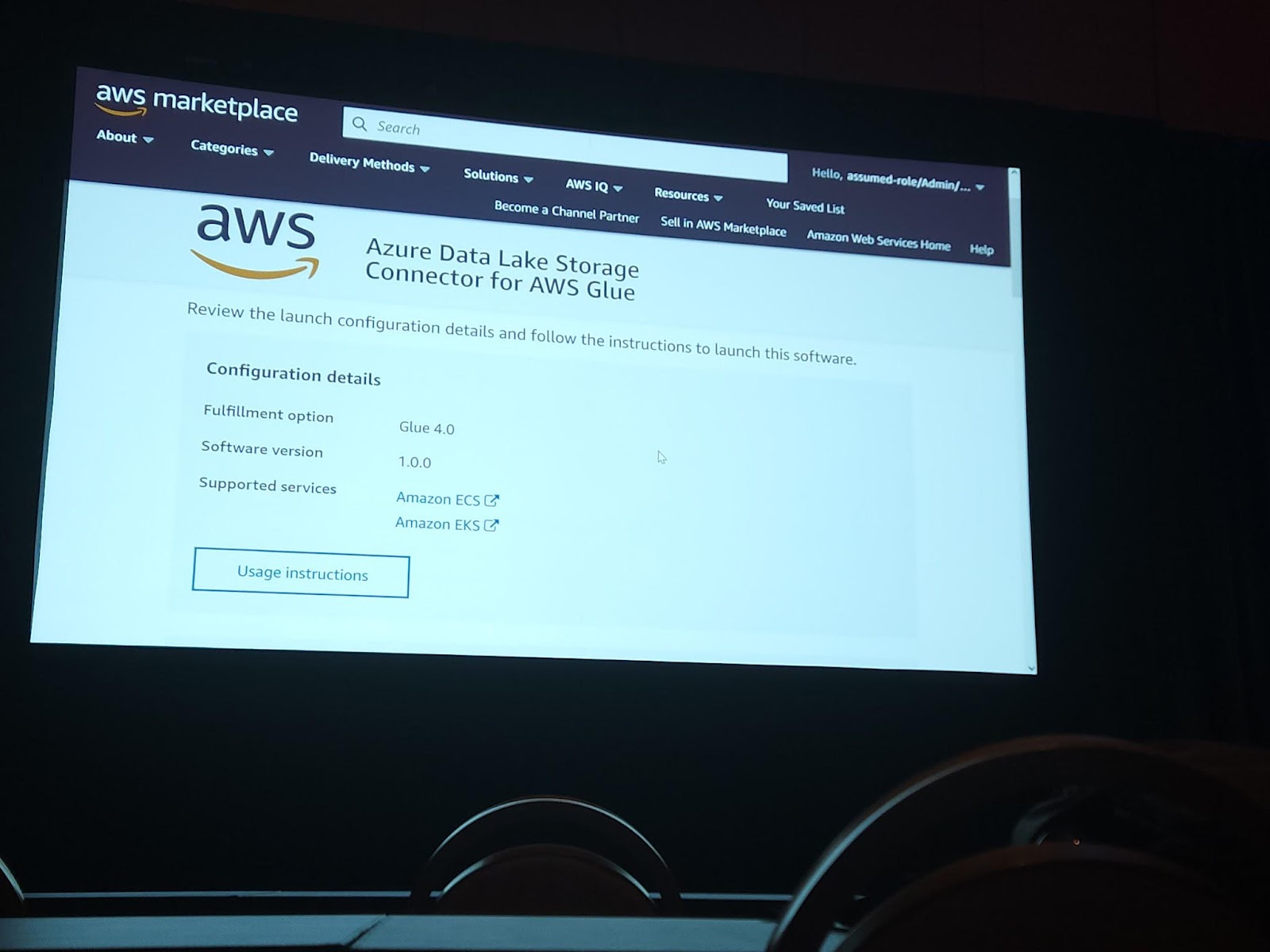
Snowflake、BigQueryのような既にGlueにconnectorが作成された場合を除いて、AWSでは様々なconnectorをMarket Placeで管理型でサポートします。私たちはGlueのバージョンに合うコネクタのバージョンをテストしたりググる必要なく簡単に選択して使うことができます。上の写真のようにAzure Data Lake Storage Connectorは基本的に提供されるコネクタではないので、マーケットプレイスで購入して登録して使う必要があります(価格は0$なので、心配しないでください)
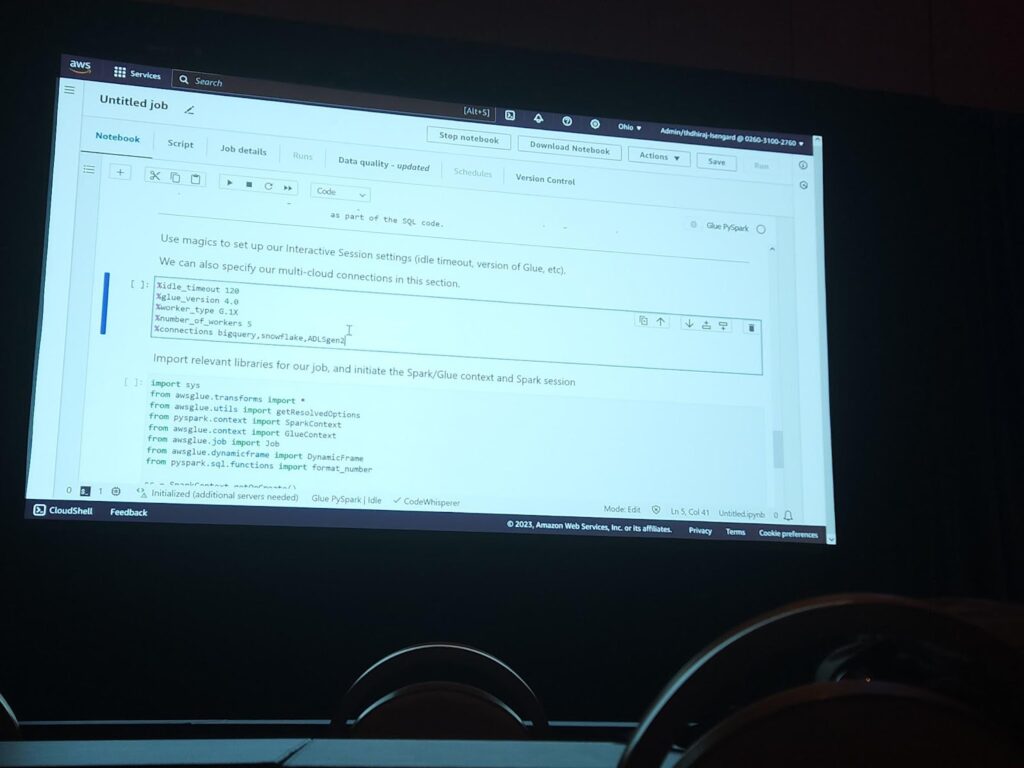
Glueにtimeout, glue version, worker type, number of workersを設定します。これはglue notebookで使うsparkクラスタ環境に対する設定を意味します。実際、上の画像のように設定すると、glue notebookではspark sessionが実行されるまでspark環境に対する費用が請求されません。 さらに、私たちは色んなソース環境でのデータ分析のため、3つのコネクタを生成して追加しました。
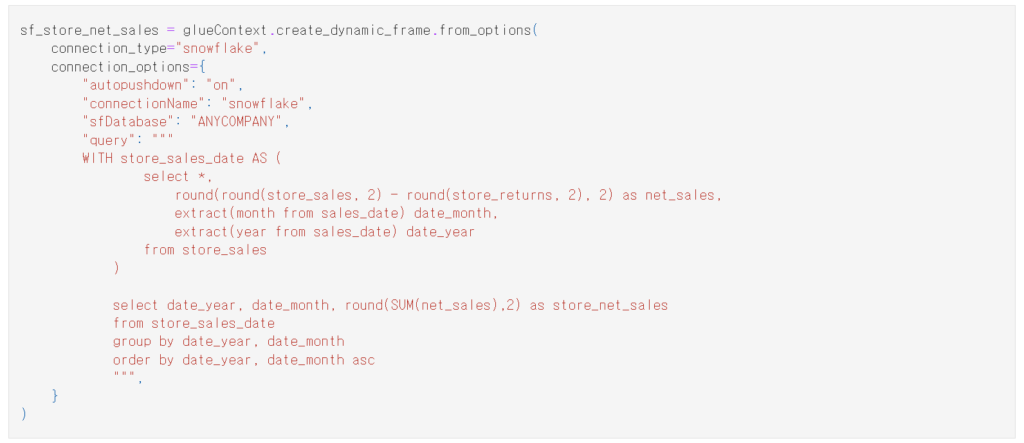
コネクションを使う方法は下記の通りです(例示の方法はsnowflakeでBigquery,DB2などソースによって使い方が変わることがあります。)次のコードを通してGlue環境で私たちは簡単にsnowflakeのデータソースを取得してglueで分析することができます。
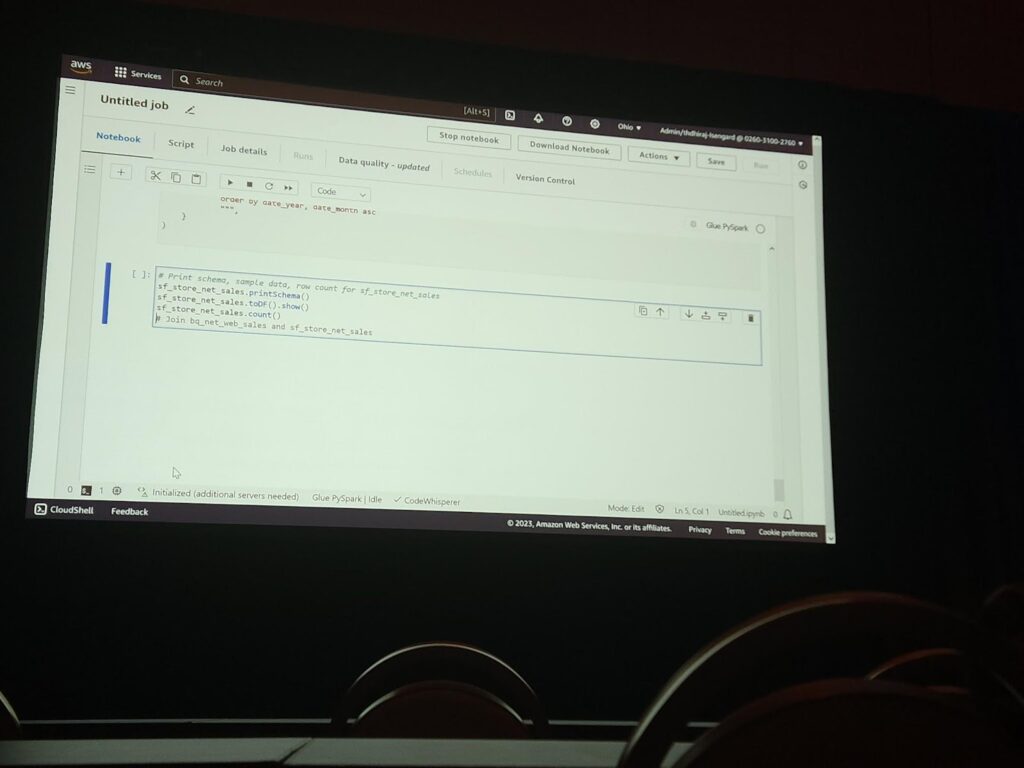
CodeWispererで追記されたコードでsnowflakeデータソースのデータを確認してみましょう。 注釈は”#Print schema, sample data, row count for sf_store_net_sales” のような方法で作成し、下記の3行のコードはなんとその注釈を使って作られたコードです!
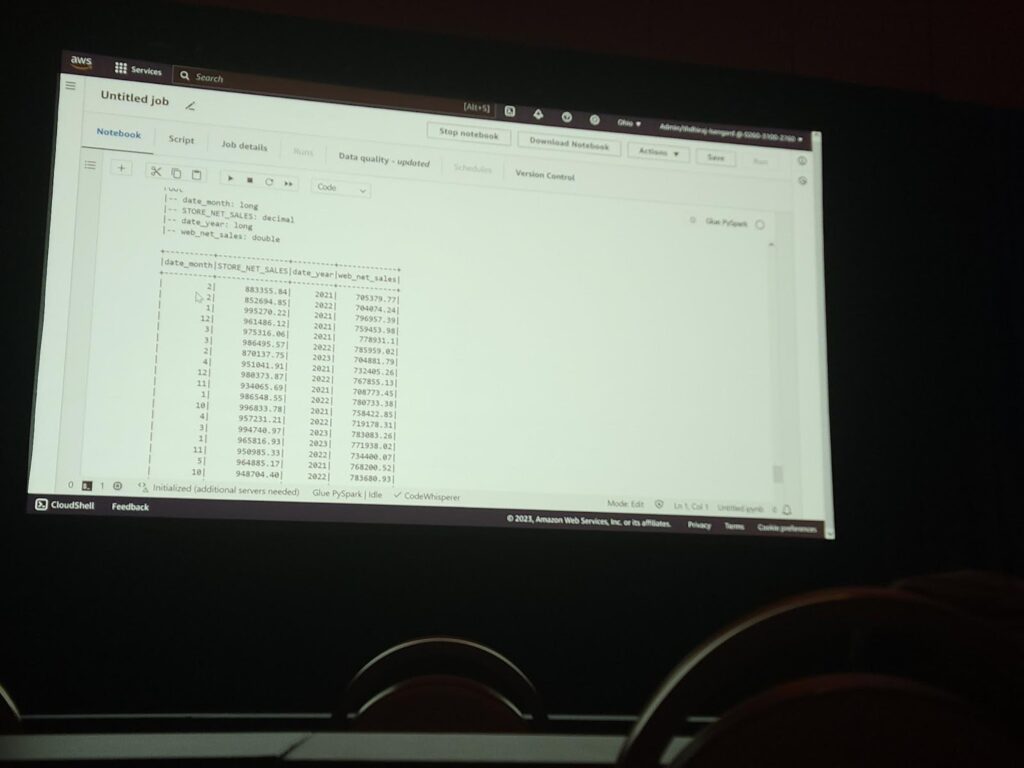
このコードを実行した時、下記のように正常なコードの結果値が出ることが確認できます。スキーマからカウント(切れて見えないですが)サンプルデータも普通にsnowflakeのデータが見えることが確認できます。
セッションを終えて
Athena、GlueはAWSの代表的な分析システムの一つです。一般的にはAWSのS3ベースのファイルデータを分析するためによく使われますが、今回のセッションを通じてAWS内部のサービスのデータだけでなく、外部の様々なソースのデータを簡単に分析できるように準備されていることも確認することができました。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner