MEGAZONEブログ

Improve incident management with the right alarms and AIOps
適切なアラームとAIOpsでインシデント管理を改善
Pulisher : Enterprise Managed Service Group ミン・ジホ
Description : 指標とログ全体のアラート戦略を構築する方法について紹介したWorkshopセッション。
はじめに
指標、ログだけでなく、どのようなソースがアラーム発生の基準になるのか知りたいと思いました。
Amazon DevOps Guruサービスを通じてMTTRを減らすことが可能なのか、もし可能であれば現運用環境に適用可能なのか、どのように適用するのか考えてみたいと思い、セッションを申し込みました。
セッションの概要紹介
インシデント管理の基本は、よりスムーズな是正を保証するために適切なアラートを設定することです。
Amazon Cloudwatchやaws Managed Open Source Observability Serviceなどのaws Observability Servicesは、静的および複合アラートから異常検知やインジケータの洞察まで、アラートを提供します。このワークショップでは、インジケータとログ全体でアラート戦略を構築する方法に関する一般的なユースケースと推奨事項をご紹介します。

CloudWatch異常検知、CloudWatch Application InsightsおよびAmazon DevOps Guruを紹介し、根本原因を迅速に理解し、これらのサービスを活用してAWSで機械学習を活用したアラート戦略を構築する方法を紹介します。
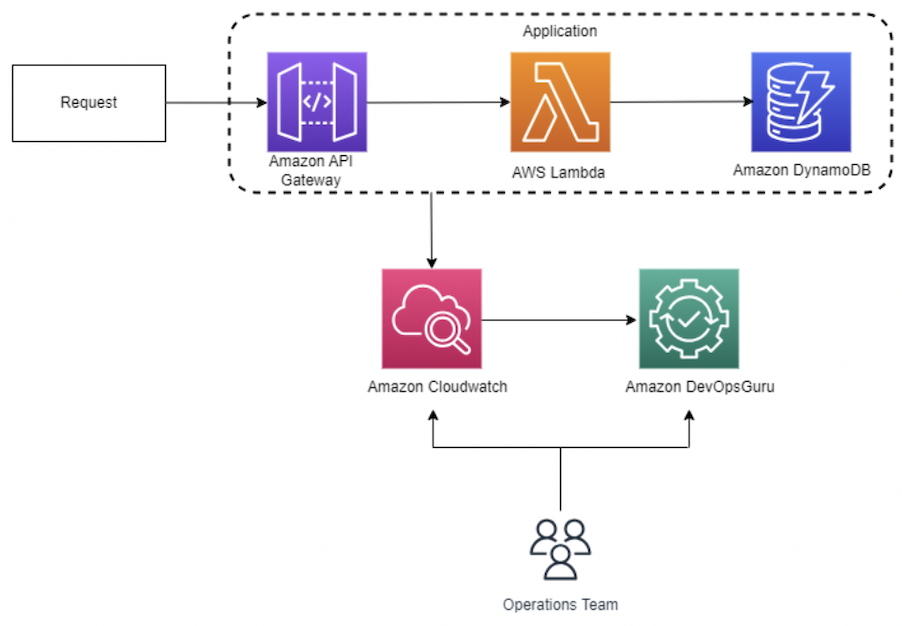
最初のシナリオのアーキテクチャです。
CloudWatch Anomaly Detection機能を有効にしたLambdaの同時実行指標をモニタリングする予定です。
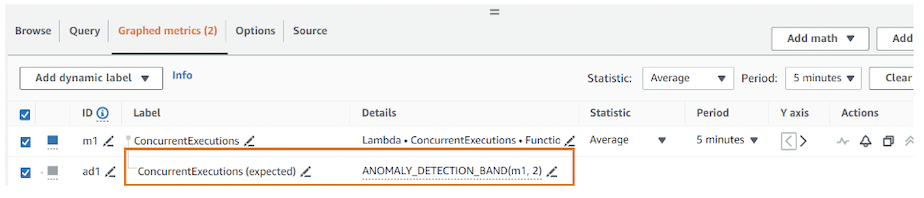
Anomaly Detection機能を有効にすると、下記のように指標が生成されます。
異常検出を有効にすることもできます。どのような値になったか、異常があると判断するか修正するためには標準偏差及び特定期間の過去データを基準から除外することで解決することができます。
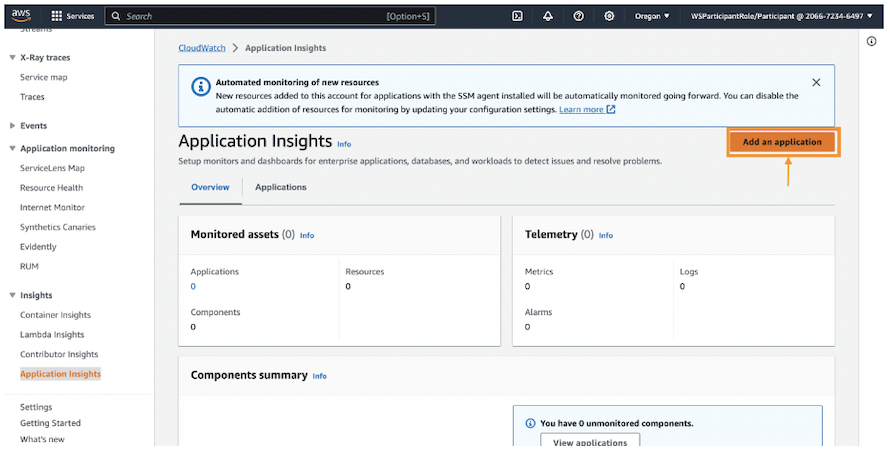
CloudWatch Application Insightsは、企業ユーザーが最小限の労力でAWSで統合された方法で統合された方法でアプリケーションを監視するのに役立ちます。
提供機能には、プラットフォーム、OSおよびその他のエージェントの指標、ログを収集・分析しエラーや異常動作が検出されると通知を生成します。
アプリケーションをCloudWatch Application Insightsにオンボーディングするには、まず、アプリケーションのアプリケーションスタックで使用するすべての関連AWSリソースのグループを作成する必要があります。
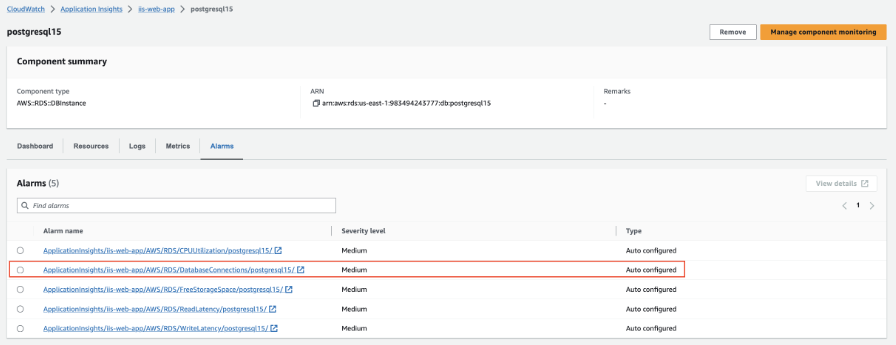
AWS Cloudwatch application insights機能により、リモート分析データ収集を自動的に管理し、主要なメトリックの自動アラートを生成します。
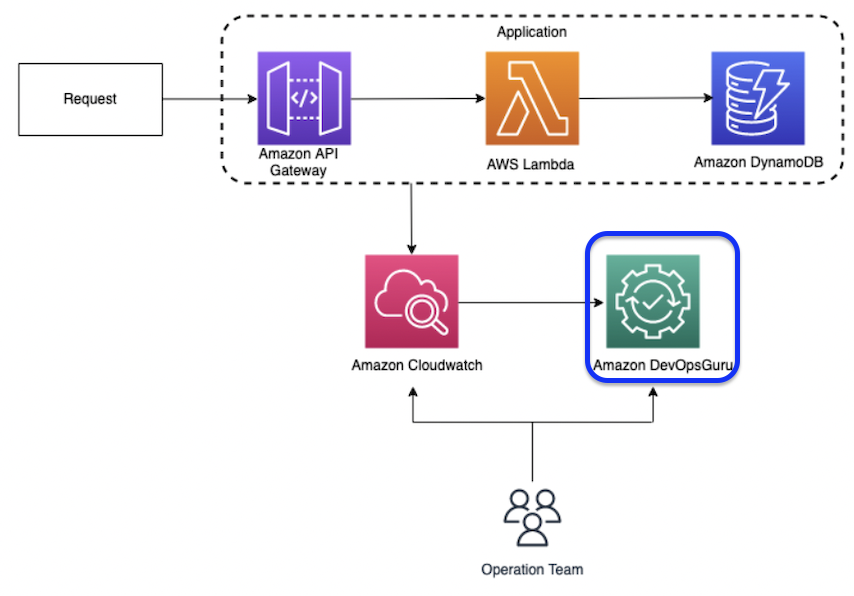
AWS DevOps Guruは、開発者とオペレータがアプリケーションの稼働時間を向上させ、運用問題を迅速に解決するための包括的なAIOpsプラットフォームサービスを提供します。
開発者やオペレーターがアプリケーションの稼働時間を向上させ、運用上の問題を迅速に解決できるように支援する包括的なAIOpsプラットフォームサービスを提供します。
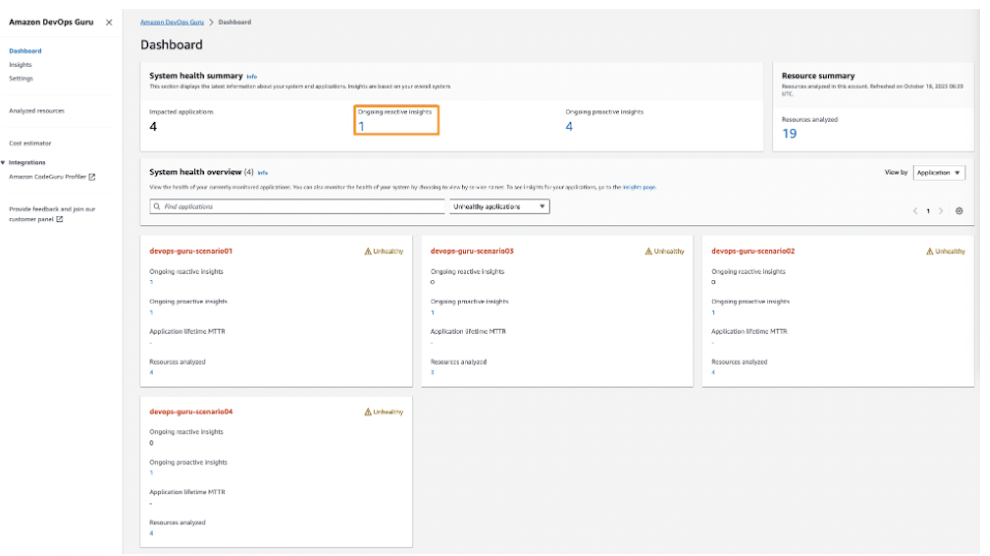
AWS DevOpsが管理するリソースに問題が発生した場合、反応型インサイトが生成されます。
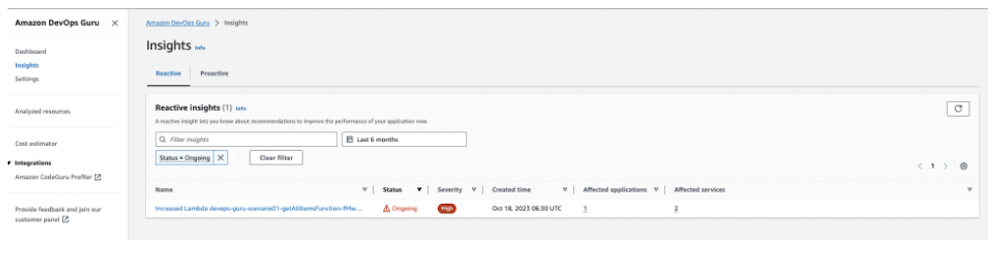
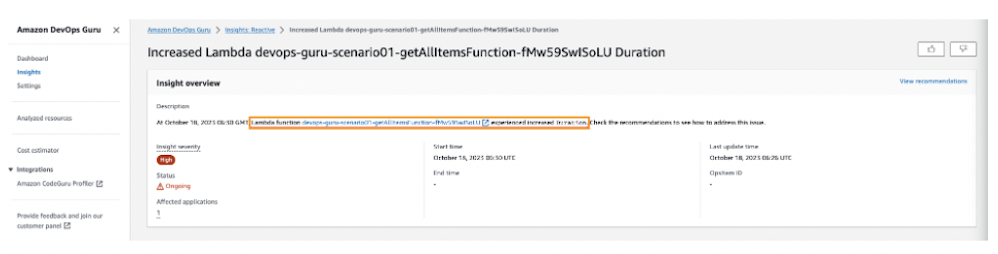
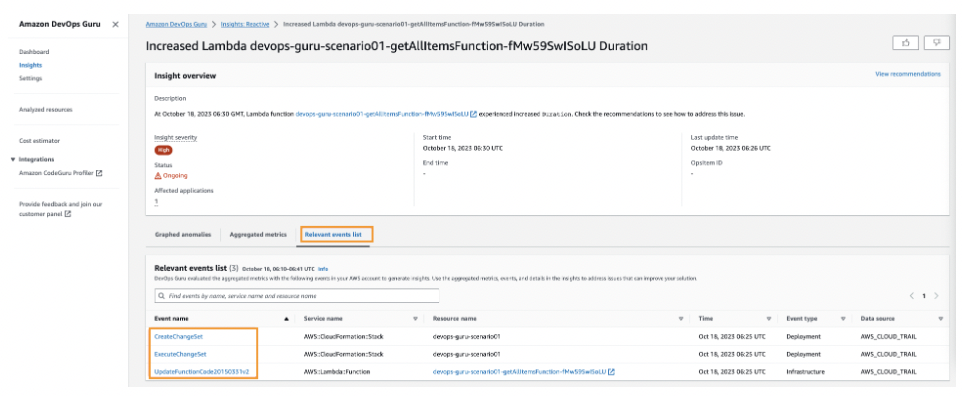
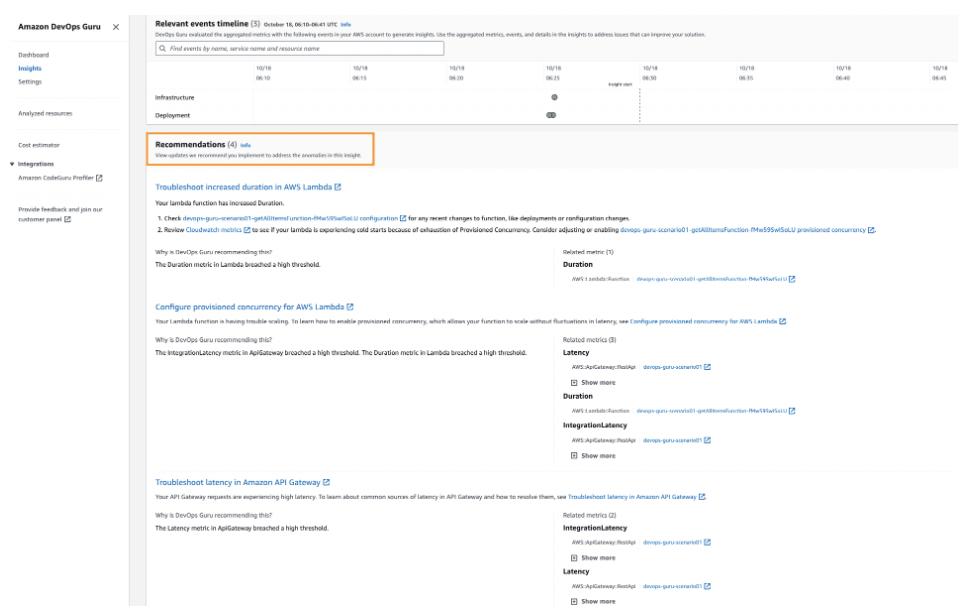
その問題が発生した原因を知らせ、どのように解決すべきかをガイドしてくれます。
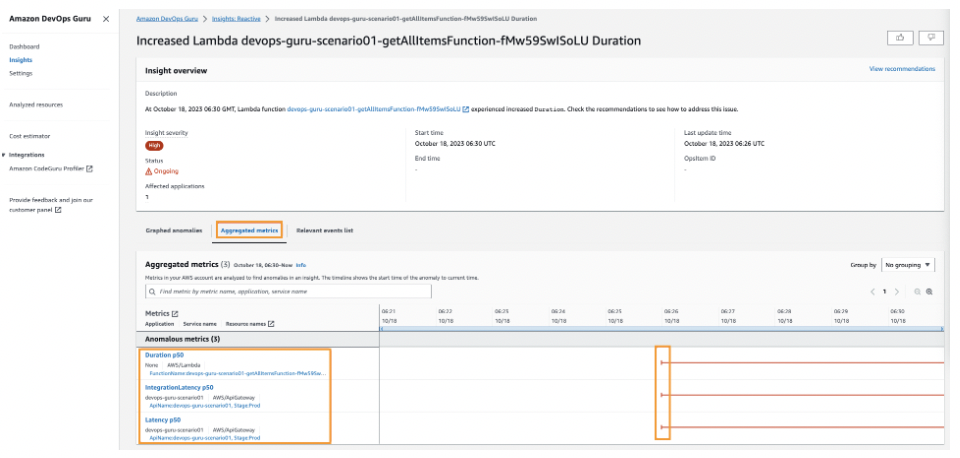
また、ルート原因と関連するリソースリソースの時間帯別の異常現象時間を見ることができ、トラブルシューティングに役立ちます。
セッションを終えて
AWS DevOps Guruを使うと、管理リソースに問題が発生すると知らせてくれて、問題のあるリソースは何なのか、情報を取得してオペレータが簡単に見れるようにします。
また、aggregate metricを通じて原因分析までサポートするのですが、現時点でDevOps Guruだけで運営できるのかどうかについて気になり、AWSの韓国エンジニアに問い合わせて意見を聞きました。
その答えは、現時点でDevOps Guruだけで運営するには無理があるとのことでした。
理由としては、オンボーディングできるリソースは多くないし、サポートするメトリックを除いてはモニタリングしないからだそうです。 そのため、AIと人が相互関係を持って運営をすると、より快適でより安全な運営ができるそうです。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner