MEGAZONEブログ

サーバーレスを考える / Thinking serverless
Pulisher : Enterprise Managed Service Group イ・ヒェイン Description : サーバーレスタイプのインフラを構成する際に考慮すべき点と、どのような構造で構成すべきかについての紹介セッション
はじめに
AWS Step Function, Amazon Simple Notification Service (SNS), Amazon EventBridge, Amazon Simple Queue Service (SQS), AWS Lambdaなどサーバーレスフレームワークで構築されたビジネスの継続性戦略を管理し、サーバーレスフレームワーク全体のワークロードをモニタリングする方法を確認するためにセッションに参加しました。
セッションの概略紹介
このセッションは、AWS Lambdaサービスをベースに様々な要件のUse caseをコードではなくArchitectureの形で説明するセッションです。

まず、一般的に定義されるサーバーの用途を考えてみましょう。ユーザーのほとんどはサーバーベースの領域を扱ってきたので、サーバーというものについて特定の方法で考える傾向があります。
通常、セッションやキャッシュのような状態管理のためにサーバーをよく使用し、サーバーの配布時に複数の機能をバンドルしたり、特定のサーバーに特定のバージョンのソフトウェアを置いたりします。 そのため、ユーザーはサーバーを原子単位で考えるようになることがあります。
しかし、このようなサーバーモデルにはいくつかの制限があります。
1. 拡張が非常に難しい場合があります。
1). 基本的にサーバーを使用する時、拡張ポリシーと戦略を手動で把握する必要があります。
2). また、サーバーの容量を100%使用しない場合、費用的な面で無駄になる可能性があります。
2. アプリケーションとは関係なく、管理しなければならないことがたくさんあります。
1). オペレーティングシステム、ネットワーク、セキュリティパッチがあり、これはサーバーの動作を維持する継続的な作業である可能性があります。
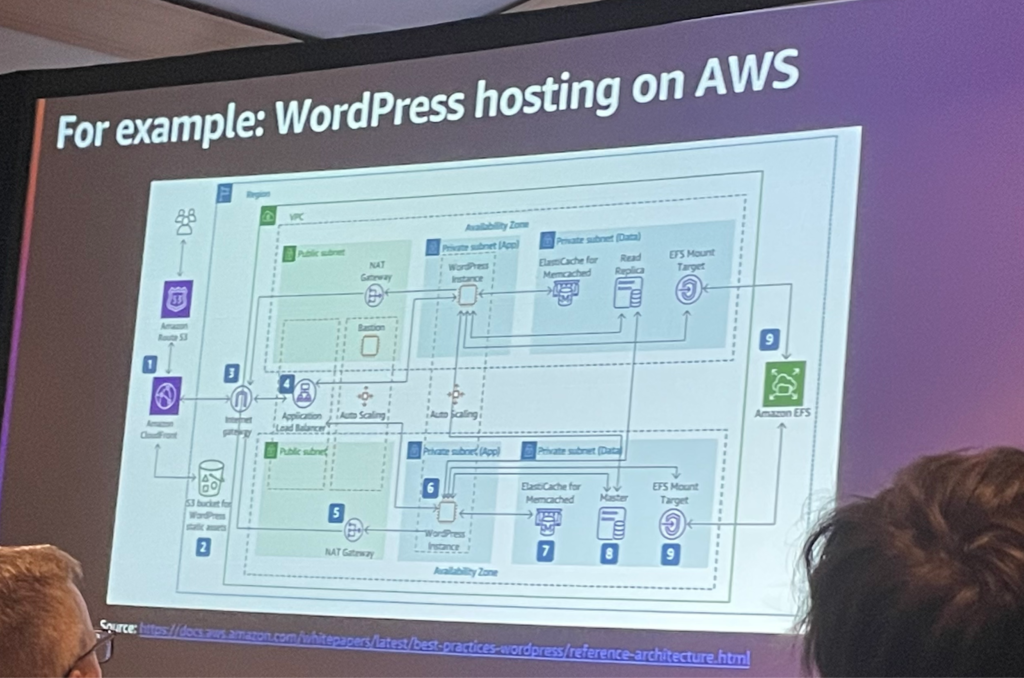
上の図はWordPressベースの制作ホームページのアーキテクチャ図です。 (スピーカーの方は、WordPressがまだインターネットで非常に大きな部分を占めているため、WordPressを選択したそうです。)
これを見ると、ウェブページのリクエストがあるたびに、ウェブサーバーがプラグインとテーマをロードするページの関係型データベースをクエリして、そのレンダリングされたページを訪問者に提供することがわかります。 そして、静的なウェブページである場合が多いので、作業が複雑です。
また、VPCやサブネット、セキュリティグループなどの作業も必要なので、これらの要素を含むサーバー管理をできるだけなくし、不要な時間をなくすことがメイン目標です。
これらの目標を達成するためにLambdaを活用することにしましたが、このLambdaはリクエスト時に実行されますが、常に実行されるわけではありません。

これまで様々な顧客が長年にわたって構築した内容を見ながら、アーキテクチャ構築を始めるときにいくつかのベストプラクティスを見ました。
その一つはlift & shiftを避けることです。
EC2インスタンスやサーバーにあるすべてのものをLambda関数に入れると、Lambdaのメリットを得られず、一つのサーバーが一つのLambda関数を持つ形でアプリケーションが分割されるからです。
また、作業に適したランタイムを指定することがよく見落とされることが多いですが、これも実際の使用用途とメンテナンスを考慮して設定する必要があります。

今日はchalk talkで使うサービスについて紹介します。大多数の人がサーバーレスというとLambdaを思い浮かべますが、他にも色んな関連サービスがあります。
1st Case

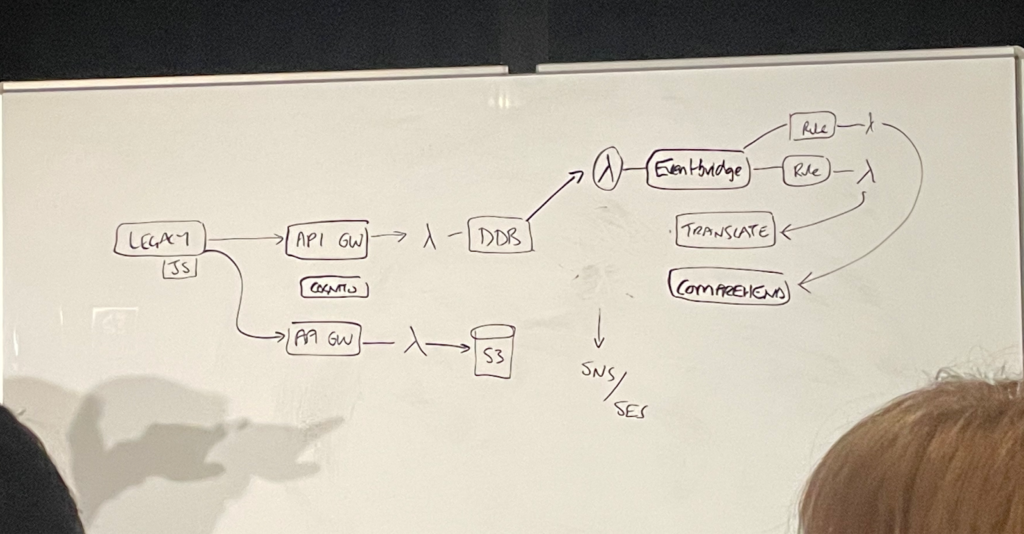
最初に実装するアーキテクチャはForm upload機能をするマイクロサービスです。
要件は下記の通りです。
1.受信応答は英語に翻訳
2.ユーザーが画像をアップロードできるようにする
3.否定的なコミュニティに即時メール送信
4.ログインしたユーザーだけレビューを投稿できるようにする
最初に作るのはLambda関数を呼び出してDynamo DBテーブルにレビューを保存するAPI Gateway Endpointです。
したがって、この3つのサービスは実際のサービスで非常に一般的です。
これにより、誰かがレビューを提出した時、レビューがこのAPI Gateway Endpointに渡され、Lambdaはこれをエンドポイントにプッシュします。
注目すべき部分は、この関数は基本的にデータ転送ではなく、特定の機能が入ったラムダ関数です。
ただデータを移動するのであれば、おそらくラムダ関数は必要ないでしょう。
API呼び出しで入ってくるパラメータをDynamo DBの所望の位置にマッピングして、この二つのサービスを一緒に接続します。このような構造は、低待機時間が必要なサービスがあったり、サービスを削除して待ち時間を減らすことができるので、規模のあるインフラにおすすめの方法です。
2nd Case

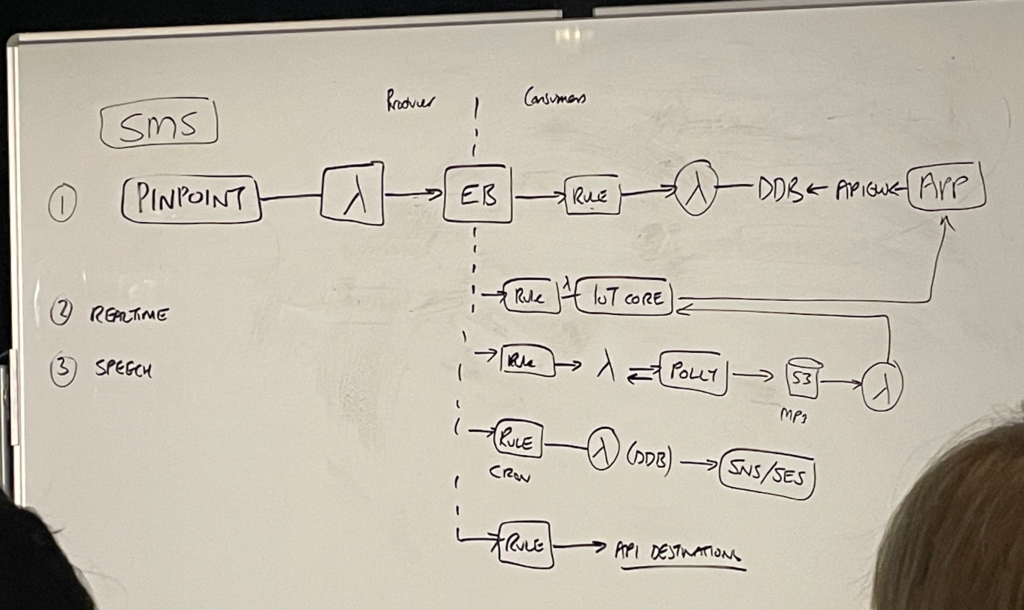
二つ目に実装するのはレストランの予約システムです。
顧客がSMSメッセージでテーブルを予約して、簡単にレストランにテキストを送ってテーブルを予約できるサービスアプリケーションを作ろうと思います。
要件は下記の通りです。
1.予定された予約をリアルタイムで表示するディスプレイを追加する。
2.テーブルに座る準備ができたらゲストの名前を言うこと
3.毎日の予約メールレポートを送信する
4.予約が完了すると、レガシーアプリケーションに通知を送信します。
アプリケーションでは、内容が変更されるとテキストメッセージを受け取る必要があります。 そこで、Pinpointというサービスを使おうと思います。Pinpointは電話番号を提供してテキストメッセージを受けることができ、テキストメッセージを受けると全てがイベントとして提供されます。
テキストメッセージを受信するとラムダ関数をトリガーしてSMSで配信するようにします。
一方、レストランで働く人は入ってくる予約リストを見ることができるような方法が必要でしょう。 予約が入るとLambda関数を呼び出してこれをDynamo DBテーブルに入れました。
もし、予約に変更があったらIoT Coreというサービスを利用してアプリを最新の状態に維持するようにしました。 したがって、アプリが起動したらIoT Coreのトピックを購読することになります。
テーブルが準備されたら、テキスト音声変換サービスであるPollyを使ってテキストを指定します。Pollyから生成されたMP3オーディオを準備したら、これをS3バケットに入れます。
セッションを終えて
様々なサーバーレス構築事例を通じて要件別に構成できるサービスと構造について知ることができるセッションであり、既存に運営されていたEC2 – アプリケーションの形のサービスも適切なAWSサービスを通じて転換して費用的、管理的な面で利点を得ることができそうです。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner